
Tomofun, the Taiwan-headquartered pet-tech startup behind the Furbo Pet Digicam, is redefining how pet homeowners work together with their pets remotely. Furbo combines good cameras with AI to detect behaviors comparable to barking, working, or uncommon exercise, and alerts homeowners in actual time. On the core of this functionality are pc imaginative and prescient and vision-language fashions that interpret pet actions from the video streams.
Initially, Furbo’s inference workloads have been hosted on GPU-based Amazon Elastic Compute Cloud (Amazon EC2) situations. Whereas GPUs supplied excessive throughput, they have been additionally expensive as a result of the always-on inference wanted to help real-time pet exercise alerts at scale. To cut back prices and preserve accuracy, Tomofun turned to EC2 Inf2 situations powered by AWS Inferentia2, the Amazon purpose-built AI chips. On this submit, we stroll by the next sections intimately.
Problem: Lowering GPU inference value for real-time vision-language fashions at scale
Operating superior vision-language fashions like Bootstrapping Language-image Pre-Coaching (BLIP), detailed within the unique paper, have been hosted on GPU situations and proved much less cost-effective for always-on, real-time inference workloads at scale. The problem was twofold: Tomofun wanted to maintain value effectivity for practically steady pet conduct monitoring throughout tons of of 1000’s of units, whereas additionally sustaining mannequin constancy and throughput. Tomofun wanted to do that with out rewriting massive parts of the BLIP code base already optimized for PyTorch.
Resolution overview
Earlier than diving into the structure, the next diagram offers a high-level view of how the system processes pet conduct detection at scale throughout AWS companies.
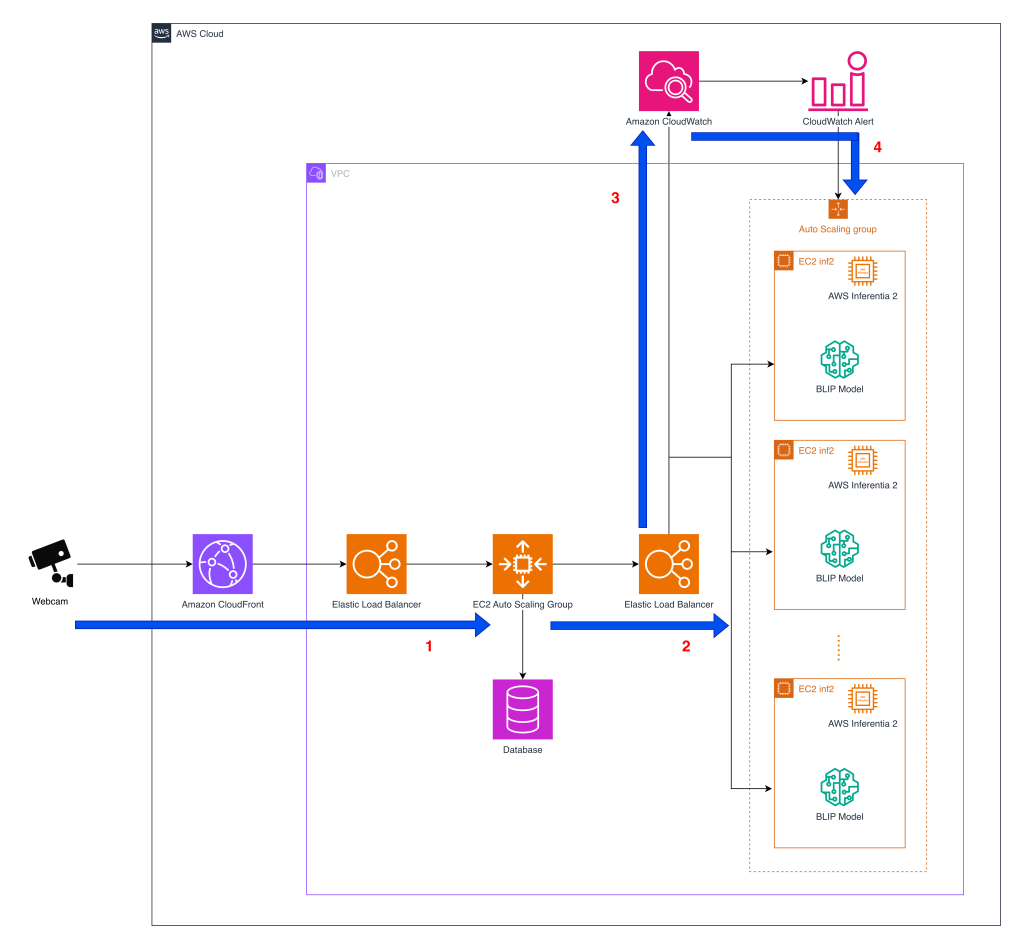
- Webcam interplay – Furbo’s API sits on the middle of Tomofun’s pet-behavior detection service, orchestrating picture streams from buyer’s pet cameras to inference endpoints in AWS. The diagram reveals the structure of Elastic Load Balancing (ELB) and Amazon EC2 Auto Scaling group carried out utilizing EC2 Inf2 situations offering scaling because the inference quantity grows in real-time. When a digicam captures a body, the info is routed by Amazon CloudFront and an ELB to the primary layer of the EC2 Auto Scaling group that hosts the pet-behavior detection API servers. After the API layer processes every request, it forwards the picture to a second-layer Auto Scaling group devoted to working mannequin inference.
- Mannequin inference – After processing, the photographs are forwarded to a second layer EC2 Auto Scaling group containing inference situations. Inside this group, containers host the BLIP mannequin, which may run on Inferentia2-based EC2 Inf2 situations. The BLIP mannequin parts compiled utilizing the Neuron SDK are loaded into containers on Inf2 situations. Within the early implementation, Furbo’s API routed inference calls solely to GPU containers, however now it might probably additionally direct requests to Inf2-based containers with out altering the upstream API or downstream alert logic. This structure permits Tomofun to direct inference requests to and change between GPU and Inferentia2 backends in real-time. This maintains excessive availability and provides them the pliability to scale cost-efficient inference whereas preserving the identical API floor for Furbo customers.
- Metrics assortment – Amazon CloudWatch displays key operational metrics throughout the inference fleet, together with latency, throughput, and error charges. These indicators present the observability wanted to detect efficiency degradation early and be certain that service-level targets are met as site visitors patterns shift all through the day.
- Scaling with Demand – The ELB dispatches requests to the accessible situations throughout the Auto Scaling group, which manages the scale of the occasion pool dimension based mostly on the incoming request depend because the CloudWatch metric. This metric-driven strategy is adopted as a result of the throughput benchmarks for every occasion kind have already been established by stress testing, so scaling selections may be pushed instantly by the quantity of picture requests. The result’s an structure that scales cost-efficient inference capability in actual time, sustaining excessive availability as demand grows.
Enhancing BLIP on Inferentia2
Earlier than diving into the mannequin particulars, the next diagram offers a high-level overview of the BLIP structure and the way its core parts work together.
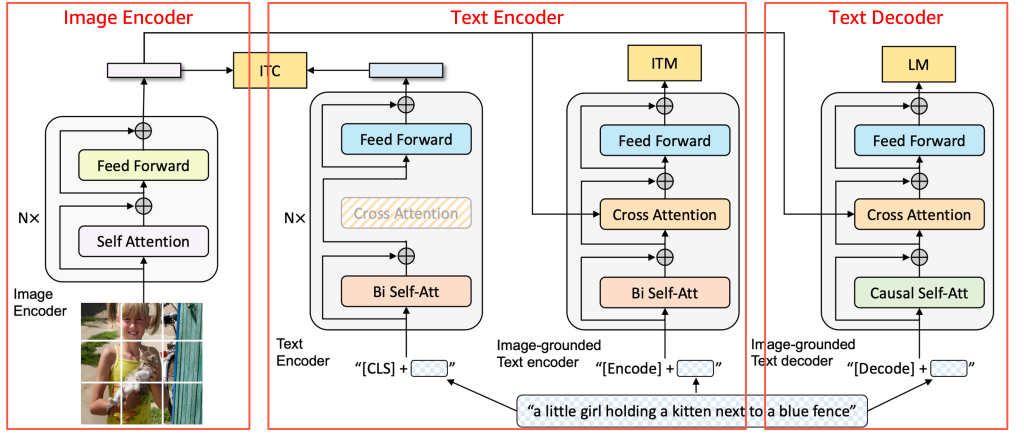
Supply: BLIP: Bootstrapping Language-Picture Pre-training for Unified Imaginative and prescient-Language Understanding and Technology, 2022 https://arxiv.org/pdf/2201.12086
BLIP consists of three parts—the Picture Encoder, Textual content Encoder, and Textual content Decoder, as proven within the picture. For help on Inferentia2, fashions may be damaged into parts and wrapped to suit enter and output shapes. Tomofun utilized this technique to BLIP, creating light-weight wrappers for every of the three parts of the BLIP mannequin so the unique structure remained unchanged. Every element was compiled independently with torch_neuronx after which mixed into the inference pipeline, permitting inputs to movement sequentially. This modular strategy maintained compatibility with Inferentia2 with out altering BLIP’s pretrained logic.
Unique mannequin code
Step one is to isolate the unique BLIP Textual content Encoder so it may be compiled with out modifying its inner logic. The TextEncoder class is a skinny wrapper across the unique submodule (mannequin.text_encoder.mannequin) that standardizes the ahead output by returning solely the first tensor. This makes the element easy to hint and compile with Neuron whereas preserving the unique structure.
In the course of the compilation part, the unique mannequin (mannequin.text_encoder.mannequin) is handed instantly into torch_neuronx.hint() and compiled right into a Neuron-optimized TorchScript artifact, with out modifying the pretrained BLIP logic.
Wrapper code
A wrapper is required as a result of the torch_neuronx.hint() API expects a tensor tuple of tensors as enter and output. To keep away from rewriting the mannequin, light-weight wrappers act as an adapter layer that reformats inputs and outputs whereas maintaining the unique structure unchanged. This strategy minimizes code modifications and permits the compiled parts to combine seamlessly into the prevailing inference pipeline.
The wrapper is used solely at deployment to load the compiled mannequin and format I/O, so it suits the prevailing BLIP pipeline.
- Compile: use the unique mannequin (
mannequin.text_encoder.mannequin) - Deploy: use
TextEncoderWrapperto run the compiled mannequin
This retains the unique code unchanged whereas making the compiled mannequin straightforward to plug into manufacturing.
Mannequin compilation for Inferentia2
Within the following code snippet, mannequin.text_encoder.mannequin represents the unmodified Textual content Encoder submodule, which is compiled right into a Neuron-optimized TorchScript format.
To compile BLIP parts for Inferentia2, Tomofun outlined a hint operate that automates the conversion of GPU-trained PyTorch fashions into Inferentia-optimized artifacts. The method begins by getting ready pseudo enter tensors that characterize the anticipated shapes and information sorts of the mannequin’s inputs, which guides the tracing course of. After the inputs are outlined, the operate calls torch_neuronx.hint() to compile the BLIP sub-model for Inferentia execution, producing a Neuron-optimized model of the unique code. Lastly, the compiled artifact is saved with torch.jit.save, making it prepared for deployment on Inf2 situations. This three-step movement—loading the wrapper, offering pseudo enter information, and compiling with Neuron—makes certain that Tomofun can migrate BLIP’s TextDecoder and different parts with out altering the unique mannequin code.
Mannequin deployment on Inferentia2
Within the deployment part, the compiled submodules are loaded by wrapper lessons to assemble the ultimate BLIP inference pipeline. This separation creates a transparent workflow the place the unique mannequin parts are used instantly for Neuron enchancment throughout compilation, whereas the wrapper lessons deal with enter and output formatting throughout inference to make sure compatibility with Inferentia2. The deployment part code is as following:
fashions.text_encoder = TextEncoderWrapper.from_model(
torch.jit.load(os.path.be part of(listing, 'text_encoder.pt')))
This design preserved the unique BLIP structure with out modification whereas assembly the Neuron SDK’s I/O interface necessities by light-weight wrapper lessons. It additionally enabled a modular, component-level workflow for each compilation and deployment, permitting every BLIP submodule to be compiled and managed independently. Consequently, using mannequin.text_encoder.mannequin is crucial in the course of the compilation part for direct Neuron optimization, whereas the wrapper lessons deal with enter and output formatting throughout inference to make sure clean execution on Inferentia2.
Stress testing
To validate efficiency at scale, Tomofun carried out stress checks simulating real-world Furbo digicam workloads. Every video stream triggered motion detection queries comparable to “Is the canine barking?”, “Is the canine taking part in?”, or “Is the canine chewing furnishings?”. These checks confirmed that Inf2 situations (one Inferentia2 chip, 32 GB reminiscence) might maintain the required throughput whereas sustaining low latency. Along with accuracy, the checks highlighted that the Inf2 deployment might deal with simultaneous requests throughout tons of of 1000’s of units, making it well-suited for Furbo’s always-on international buyer base. Importantly, the comparability baseline was working GPU-based situations with an on-demand pricing mannequin, which mirrored the fee Tomofun was paying earlier than migration to Inf2. By migrating from these GPU on-demand deployments to Inf2.xlarge situations with Inferentia2, Tomofun achieved 83% value discount with out compromising efficiency.
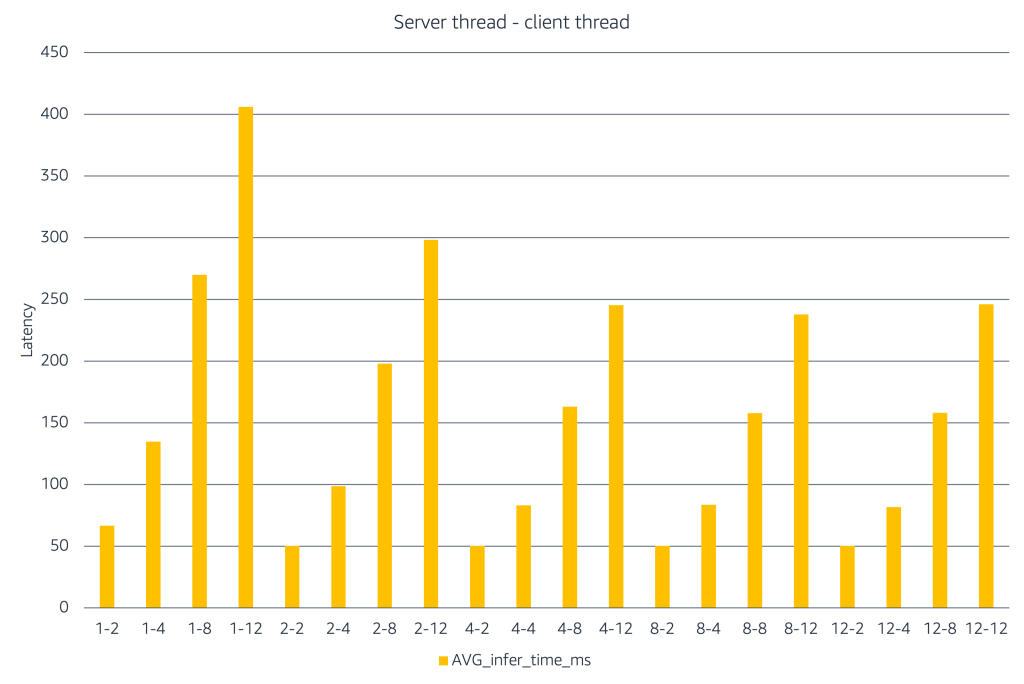
The chart illustrates how inference latency modifications as server and shopper concurrency enhance. The X-axis represents combos of the labels characterize #server threads – #shopper threads to simulate efficiency underneath totally different load eventualities. When only some server threads can be found, including extra shopper threads causes latency to rise rapidly. Rising the variety of server threads helps soak up this load and retains latency decrease. At larger concurrency ranges, latency will increase and positive aspects stage off, indicating saturation. This experiment reveals that groups ought to use load testing to establish the correct stability between shopper concurrency and server capability, after which restrict concurrency to that vary to realize the correct latency–value tradeoff in manufacturing.
Conclusion
By migrating BLIP inference on AWS Inferentia-based EC2 Inf2 situations, Tomofun decreased their Furbo utility deployment prices by 83%. The transition from GPU to Inferentia2 was seamless, because the migration required solely light-weight wrapper lessons and left BLIP’s core logic untouched. Testing confirmed that utilizing Inferentia2 not solely decreased the deployment prices, but in addition maintained excessive throughput for real-time inference at scale. Tomofun plans emigrate extra workloads to Inferentia2 because it helps workloads past vision-language fashions, comparable to audio occasion detection for barking recognition and potential future integration with massive language fashions to reinforce pet-owner interactions. Moreover, the adoption of AWS Deep Studying Containers (DLCs) has been scheduled into the roadmap as a subsequent step, utilizing pre-built, improved container photos to simplify dependency administration and streamline inference workflows.
To discover ways to implement comparable enhancements, discover the AWS Neuron documentation and examples you’ll be able to reference AWS Neuron Doc. You can even go to Furbo web site to discover Furbo’s AI-powered options and see how the Furbo ecosystem retains your pets protected.
Concerning the authors


{kind=link}