I be one of the attention-grabbing discoveries (and matters) in synthetic intelligence, leaving apart the controversy about whether or not that is intelligence in any respect or not.
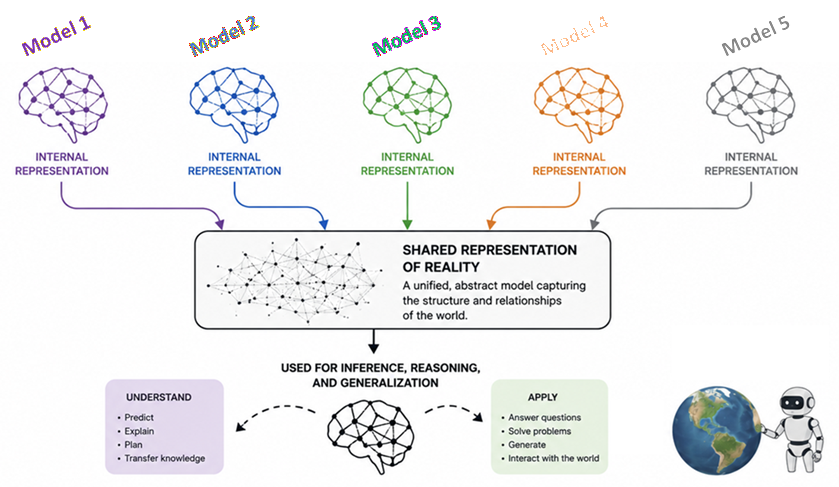
We (I no less than!) assume that should you skilled one AI mannequin purely on, say, photos and one other purely on textual content, they’d develop solely other ways of “considering” — not coming into the dialogue about what this precisely means. Our notion can be that they use fully totally different architectures and course of fully totally different knowledge, so they need to, by all logic, have fully totally different “brains”, even when they each are good at their duties with photos and textual content.
However in accordance with some thrilling analysis from varied teams, that isn’t the case in any respect!
Already in 2024, MIT offered strong proof that each main AI mannequin is secretly converging to the identical “considering core” (or mind, or no matter you need to name it). As these fashions get larger and extra highly effective, they’re all arriving at the very same conclusion about how the world is structured. Possibly this wasn’t apparent with the early fashions, as a result of they have been unhealthy at reasoning; however it turns into increasingly evident as they get higher. And allegedly, I might say, the explanation for that’s that if they’re all right then they MUST be creating a really comparable illustration of actuality.
The allegory of the (AI) cave
To grasp why that is taking place, some researchers regarded again 2,400 years to Plato’s “Allegory of the Cave” — leading to some attention-grabbing preprint titles containing concepts such because the “Platonic Illustration Speculation”. Basically, Plato believed that we people are like prisoners in a cave, watching shadows flicker on a wall. We expect the shadows (our perceptions) are “actuality”, however they’re really simply projections of a deeper, hidden, extra complicated actuality current exterior the cave.
One of many many papers I learn to arrange this (hyperlinks on the finish) argues that AI fashions are doing the very same factor, and that in doing in order that they converge to the identical mannequin of how the world works in an effort to perceive the enter shadows.
The billions of strains of textual content, the trillions of pixels in photos, the infinite audio recordsdata used for coaching of our fashionable AI fashions are simply their notion (“shadows”) of our world. These highly effective fashions are these totally different shadows of human knowledge and, fully independently, they’re discovering the very same underlying construction of the universe to make sense of it.
Completely different eyes, identical imaginative and prescient
Right here is the mind-blowing half, to me no less than: A mannequin that solely “sees” photos and a mannequin that solely “reads” textual content are measuring the space between ideas in the very same manner (if they’re each adequate).
In case you ask a imaginative and prescient mannequin to map the “distance” between an image of a “canine” and a “wolf”, after which ask a language mannequin to map the space between the phrase “canine” and the phrase “wolf”, the mathematical buildings they construct have gotten increasingly comparable as they will higher distinguish the 2 animals.
In different phrases, it looks as if as these fashions scale up and change into higher, they cease being a multitude of random connections. Analysis exhibits that they have an inclination to align, and specifically that as imaginative and prescient fashions and language fashions get bigger, the way in which they characterize knowledge turns into increasingly alike. So wonderful, don’t you suppose!
Why scale modifications every part
In response to the analysis accessible, this all appears to be fairly common and taking place with fashionable fashions from all corporations and skilled with totally different sources, so long as the mannequin itself is succesful sufficient. The truth is, as a mannequin will get bigger, no matter it’s, it undergoes a “section change” of their inner considering. Analysis appears to point that these fashions cease merely memorizing their particular duties and relatively begin to construct up a statistical mannequin of actuality itself.
And apparently, this occurs due to some “selective stress” appearing on the fashions:
- Activity generality: In order for you an AI to be good at every part, there is just one “finest” solution to characterize the world such that it doesn’t overfit but will be predicted. Since there’s solely ONE finest manner, they need to all get to it!
- Capability: Massive fashions have the “room” to search out probably the most elegant, easy resolution. However having ample room by way of structure of variety of parameters have to be balanced with avoiding overfitting.
- Simplicity bias: Deep networks really want easy options over complicated ones, once more particularly if overfitting is prevented.
One essential factor is that the totally different AI fashions may adapt to those items of selective stress at totally different speeds (or with totally different ranges of effectivity); however they’re definitely all heading towards the identical last state of maximal understanding achieved via the identical inner illustration of how the world works.
Essentially the most fashionable analysis on “information mechanisms”
If I have been 25 years youthful and needed to selected a profession now, I might in all probability selected one thing like laptop sciences combined with psychology. As a result of to me, right here’s the place probably the most thrilling a part of the AI world is. Learn why!
A current survey on “information mechanisms” in LLMs provides one other layer to all this described above. It means that information in these fashions isn’t simply scattered randomly; relatively, it evolves from easy memorization to complicated “comprehension and software”. There would then be some form of “dynamic intelligence” at play. The pattern that information and functionality are likely to converge into the identical illustration areas appears to occur throughout the total synthetic neural mannequin group, no matter knowledge, modality, or goal. Even information that we people haven’t fairly grasped but (or that solely domain-specific specialists grasp, say, the best way to construct up music for a composer or why and the way photons can entangle for a physicist) is being mapped by these fashions as they discover patterns (following the instance, say in music or quantum physics) that our organic brains can’t course of as rapidly.
Why that is so cool, and an analogy with how we people study
That is a type of uncommon moments the place math, laptop science, and philosophy collide. It appears to me just like the fashions are constructing a unified notion of actuality in the one manner they will ingest it: as phrases, photos, and sounds. Not likely that totally different to how infants study, maybe although in a special order and including extra inputs together with bodily ones (robust, bumps, and so on.), and naturally coupled to bodily outputs (crying, laughing, shifting limbs, strolling, …)
Inside our brains, in spite of everything, multimodality can be all built-in and works beneath the identical international understanding (which, sure, will be tricked with illusions, however that’s for one more day!). In different phrases, our brains additionally map every part to a single actuality, which is our private interpretation of how the world works. If I take a photograph of an apple, if I write the phrase “apple”, if I file the sound of somebody biting an apple, these are three totally different “shadows” however they’re all projected from the identical precise, bodily actuality of the apple. Even when the apple is one coloration of the opposite, even artificially painted, or if I write the phrase in different languages, “manzana” or “pomme” will, if I communicate Spanish and French respectively, mirror form of the identical shadow.
International illustration of actuality + bodily inputs + bodily outputs –> robots
The entire thing above, together with the analogy with infants and people, can then be extrapolated increasingly. Or no less than I prefer to suppose that.
Add capabilities for bodily inputs and outputs to a worldwide, well-working AI mannequin of actuality, and we’ve got a robotic that may study to interpret and work together with the world. Onerous-wire into it an “intuition” to outlive, and properly… who is aware of the place this could go. However we aren’t too totally different from that building, don’t you suppose?
I’ll depart this right here, to not enter that debate, however please alternate with me about it!
Let’s drop it right here with the clear, research-based proof that we’re now not simply constructing instruments to assist us write emails, summarize a factor, write code, or edit or generate images. We’re constructing digital mirrors of the universe. And we’re watching, in real-time, as silicon and code independently uncover the interior workings of the world we reside in.
References
To write down this put up I went intimately via these two super-interesting works: a research offered as a preprint in 2024, and a more moderen evaluate about information mechanisms in LLMs:
The Platonic Illustration Speculation: https://arxiv.org/html/2405.07987v5
Information Mechanisms in Massive Language Fashions: A Survey and Perspective: https://aclanthology.org/2024.findings-emnlp.416/



{kind=link}