Giant-scale AI mannequin coaching faces important challenges with failure restoration and monitoring. Conventional coaching requires full job restarts when even a single coaching course of fails, leading to extra downtime and elevated prices. As coaching clusters develop, figuring out and resolving essential points like stalled GPUs and numerical instabilities usually requires advanced customized monitoring code.
With Amazon SageMaker HyperPod you possibly can speed up AI mannequin improvement throughout lots of or hundreds of GPUs with built-in resiliency, lowering mannequin coaching time by as much as 40%. The Amazon SageMaker HyperPod coaching operator additional enhances coaching resilience for Kubernetes workloads via pinpoint restoration and customizable monitoring capabilities.
On this weblog submit, we present you the right way to deploy and handle machine studying coaching workloads utilizing the Amazon SageMaker HyperPod coaching operator, together with setup directions and an entire coaching instance.
Amazon SageMaker HyperPod coaching operator
The Amazon SageMaker HyperPod coaching operator helps you speed up generative AI mannequin improvement by effectively managing distributed coaching throughout giant GPU clusters. The Amazon SageMaker HyperPod coaching operator makes use of built-in fault resiliency elements, comes packaged as an Amazon Elastic Kubernetes Service (Amazon EKS) add-on, and deploys the mandatory customized useful resource definitions (CRDs) to the HyperPod cluster.
Answer overview
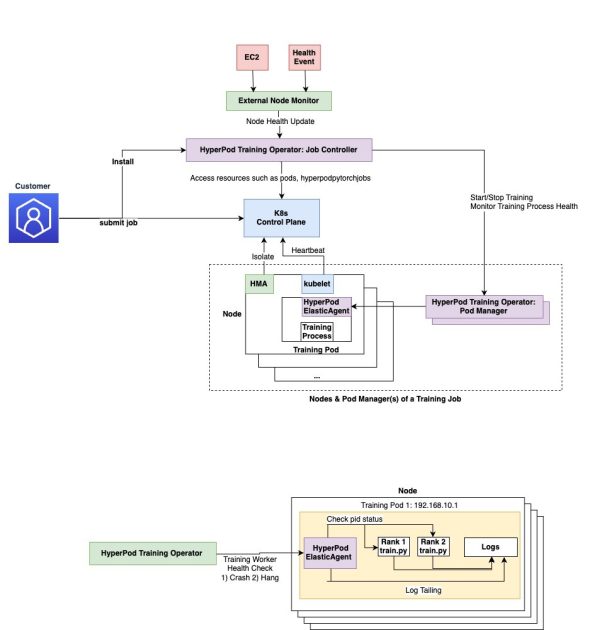
The next diagram depicts the structure of Amazon SageMaker HyperPod coaching operator.
The HyperPod coaching operator follows Kubernetes operator sample and has the next main elements:
- Customized Useful resource Definition (CRDs):
HyperPodPyTorchJobdefines the job specification (for instance, node depend, picture) and serves because the interface for patrons to submit jobs.apiVersion: sagemaker.amazonaws.com/v1type: HyperPodPyTorchJob - RBAC insurance policies: Defines the actions the controller is allowed to carry out, reminiscent of creating pods and managing
HyperPodPyTorchJobsources. - Job controller: Listens to job creation and fulfills requests by creating job pods and pod managers.
- Pod supervisor: Displays coaching course of well being on every pod. The variety of Pod Managers is set by the variety of pods required by the job. One Pod Supervisor presently controls a number of hundred pods.
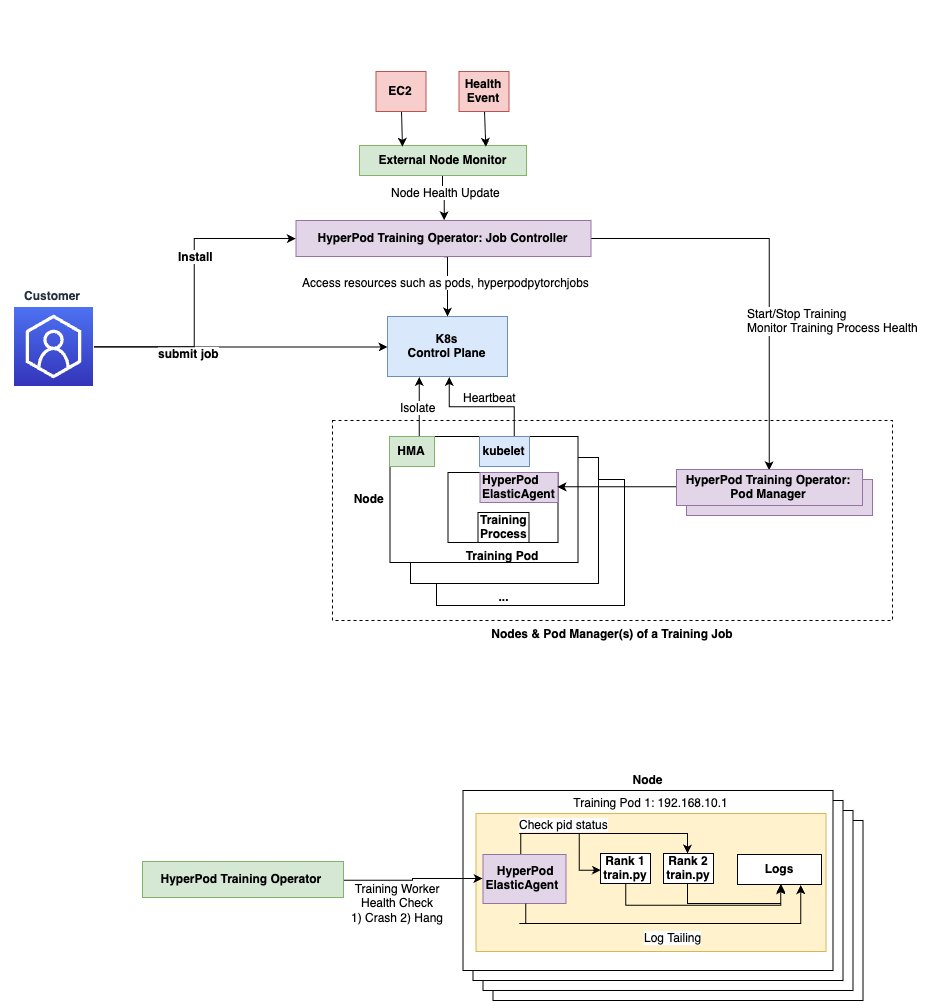
- HyperPod elastic agent: Clients set up the elastic agent into their coaching container. It orchestrates lifecycles of coaching employees on every container and communicates with the Amazon SageMaker HyperPod coaching operator. The HyperPod elastic agent is an extension of PyTorch’s ElasticAgent.
The job Controller makes use of fault detection elements such because the SageMaker HyperPod health-monitoring agent and node well being test mechanisms like AWS retirement notices to replace job state and restore faults. It additionally depends on the HyperPod elastic agent to test the standing of coaching processes for crashes and hung job detection.
When a HyperPodPyTorch job is submitted, the Amazon SageMaker HyperPod coaching operator spins up job pods together with pod supervisor pods that assist handle the coaching job lifecycle. The pod managers work together with the HyperPod elastic agent so that each one job pods preserve a wholesome state.
Advantages of utilizing the operator
The Amazon SageMaker HyperPod coaching operator might be put in as an EKS add-on in your cluster. The important thing advantages embrace:
- Centralized coaching course of monitoring and restart – The HyperPod coaching operator maintains a management airplane with a worldwide view of well being throughout all ranks. When one rank encounters a difficulty, it broadcasts a cease sign to all ranks to forestall different ranks from failing individually at totally different instances as a consequence of collective communication timeout. This helps extra environment friendly fault detection and restoration.
- Centralized environment friendly rank task – A separate HyperPod rendezvous backend permits the HyperPod coaching operator to assign ranks immediately. This reduces initialization overhead by eliminating the necessity for worker-to-worker discovery.
- Unhealthy coaching node detection and job restart – The HyperPod coaching operator is totally built-in with the HyperPod EKS cluster resiliency options, serving to restart jobs or coaching processes as a consequence of dangerous nodes and {hardware} points in ML workloads. This reduces the necessity to self-manage job restoration options.
- Granular course of restoration – Relatively than restarting whole jobs when failures happen, the operator exactly targets and restarts solely coaching processes, lowering restoration instances from tens of minutes to seconds. This makes HyperPod coaching operator job restoration time scale linearly as cluster dimension grows.
- Hanging job detection and efficiency degradation detection – Based mostly on coaching script log monitoring, the HyperPod coaching operator helps overcome problematic coaching eventualities together with stalled coaching batches, non-numeric loss values, and efficiency degradation via easy YAML configurations. For extra data see, Utilizing the coaching operator to run jobs within the Amazon SageMaker AI Developer Information.
Coaching operator setup
This part walks via putting in the Amazon SageMaker HyperPod coaching operator as an Amazon EKS add-on.
Estimated Setup Time: 30-45 minutes
Conditions
Earlier than getting began, confirm that you’ve the next sources and permissions.
Required AWS sources:
Required IAM permissions:
Required software program:
Set up directions
Earlier than operating the set up steps under, you’ll have to first create a HyperPod cluster. For those who haven’t executed this one already please comply with the directions to create an EKS-orchestrated SageMaker HyperPod cluster to get began. Be sure to put in eks-pod-identity-agent add-on on the EKS cluster, by following the Arrange the Amazon EKS Pod Id Agent directions.
Set up cert-manager
First, set up the cert-manager add-on which is required for the HyperPod coaching operator:
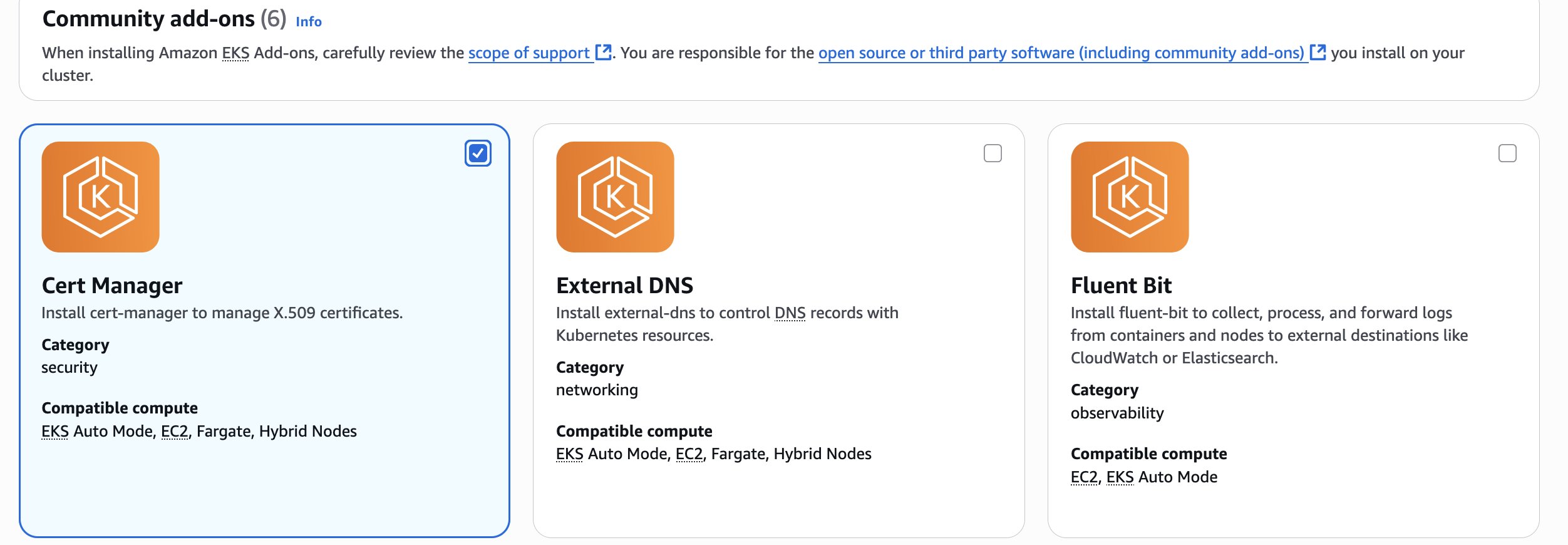
- Open the Amazon EKS console
- Navigate to your EKS cluster and go to the Add-ons web page
- On the Add-ons web page, find Get extra add-ons and navigate to the Group add-ons part
- Discover the Cert Supervisor add-on, choose it, and select Subsequent
- On the add-on configuration web page, proceed with default settings and select Subsequent
- Preview all choices for the Cert Supervisor add-on and select Create
- Look forward to the add-on standing to vary to Lively earlier than continuing
Set up the HyperPod coaching operator add-on
As soon as cert-manager is energetic, set up the Amazon SageMaker HyperPod coaching operator:
- Open the Amazon SageMaker console
- Navigate to your cluster’s particulars web page
- On the Dashboard tab, find Amazon SageMaker HyperPod coaching operator and select Set up
Throughout set up, SageMaker creates an IAM execution function with permissions much like the AmazonSageMakerHyperPodTrainingOperatorAccess managed coverage and creates a pod identification affiliation between your Amazon EKS cluster and the brand new execution function.

Confirm set up
We now have now efficiently setup of the Amazon SageMaker HyperPod coaching operator. You may verify that the pods are operating through the use of the next command:
Your output ought to comprise the coaching operator controller as proven under:
Arrange coaching job
Let’s run a PyTorch-based coaching instance on a Llama mannequin. We start by trying out the next code base:
These scripts present a simple approach to get began with multinode FSDP coaching on EKS. It’s designed to be so simple as doable, requires no information preparation, and makes use of a container picture.
Subsequent, construct the docker container picture.
The above command works with linux primarily based environments, in case you are on a Mac, use buildx to focus on linux/amd64 structure:
Push the picture to Amazon ECR:
Notice: Pushing the picture could take a while relying in your community bandwidth.
Knowledge
For this instance, we’ll be utilizing the allenai/c4 dataset. As a substitute of downloading the entire thing, the create_streaming_dataloaders perform will stream the dataset from HuggingFace, so there’s no information prep required for operating this coaching.
For those who’d prefer to as a substitute use your personal dataset, you are able to do so by formatting it as a HuggingFace dataset, and passing its location to the --dataset_path argument.
For the dataset, you will have a Hugging Face entry token. First, create a Hugging Face account. Then generate your entry token with learn permissions.
We are going to reference this token within the subsequent step by setting it as an surroundings variable.
This instance makes use of envsubst to generate a Kubernetes manifest file from a template file and parameters. For those who don’t have envsubst in your improvement surroundings, set up it by following the set up directions.
Launch Llama 3.1 8B coaching job
Subsequent, we generate the Kubernetes manifest and apply it to the cluster. Let’s navigate to the FSDP supply repo:
Right here, we begin by creating surroundings variables which are utilized in our coaching job. Fill out the placeholders as per your cluster dimension.
When you fill in env_vars after which supply variables:
You may apply yaml to submit the coaching job:
You can too regulate the coaching parameters within the TRAINING_ARGS part of the llama3_1_8b-fsdp-hpto.yaml. Extra parameters might be discovered underneath mannequin/arguments.py. Notice that we use the identical listing for each --checkpoint_dir and --resume_from_checkpoint. If there are a number of checkpoints, --resume_from_checkpoint will mechanically choose the newest one. This manner if our coaching is interrupted for any cause, it is going to mechanically choose up the newest checkpoint.
Moreover, you may as well put together and submit your jobs appropriate with the Amazon SageMaker HyperPod coaching operator via the HyperPod CLI and SDK capabilities which have been just lately introduced, extra studying data on the right way to use it’s obtainable in this improvement information.
Monitor coaching job
To see the standing of your job, use the next command:
Use the next command to record the roles ran utilizing HyperPod coaching operator:
Use the next command to record all of the pods for the coaching jobs:
To test the pod logs run the under command to constantly stream the logs to stdout, use the next command:
Configure log monitoring
With Amazon SageMaker HyperPod coaching operators customers can configure log patterns that the operator constantly displays. The HyperPod operator constantly seems to be for the configured regex sample and stops the coaching job if it finds a violation. The llama3_1_13b-fsdp-hpto.yaml file that we used beforehand comprises log monitoring configurations for monitoring Job begin hangs, hold detection throughout coaching, and checkpoint creation failures as proven under:
And the corresponding code recordsdata in /src/prepare.py have the mandatory log statements.
Any time these metrics exhibit deviation from their anticipated values, the operator will detect it as a fault, and set off a restoration course of to re-execute the job, as much as a user-specified most variety of retries.
Moreover, the HyperPod coaching operator additionally helps integration with Amazon SageMaker Process Governance.
Integration with HyperPod Observability
SageMaker HyperPod presents a managed observability expertise via the newly launched the HyperPod Monitoring and Observability EKS add-on. The observability add-on mechanically populates Kubeflow Coaching metrics in Grafana dashboards out of the field, however for HyperPod PyTorch job metrics, you would need to activate the superior coaching metrics which leverage the HyperPod coaching operator to indicate data round job downtime, job restoration and faults, and downtime.
To get these superior metrics, you possibly can confer with Establishing the SageMaker HyperPod observability add-on. This helps to streamline the method of manually organising a scraper and constructing dashboards.
Clear up
To keep away from incurring pointless expenses, clear up the sources created on this walkthrough.
Delete coaching jobs
Take away all HyperPod coaching jobs:
Confirm jobs are deleted:
Take away container pictures
Delete the ECR repository and pictures:
Take away add-ons:
Take away the next add-ons:
Take away the Amazon SageMaker HyperPod coaching operator add-on:
- Open the Amazon SageMaker console
- Navigate to your cluster’s particulars web page
- On the Add-ons tab, choose the Amazon SageMaker HyperPod coaching operator
- Select Take away
Take away the cert supervisor add-on:
- Open the Amazon EKS console
- Navigate to your EKS cluster’s Add-ons web page
- Choose Cert Supervisor and select Take away
Extra clear up
Contemplate eradicating these sources if not wanted:
- Any persistent volumes created throughout coaching
- CloudWatch log teams (if you wish to retain logs, go away these)
- Customized IAM roles created particularly for this instance
- The HyperPod cluster itself (if not wanted).
Conclusion
As organizations proceed to push the boundaries of AI mannequin improvement, instruments just like the Amazon SageMaker HyperPod coaching operator can be utilized to take care of effectivity and reliability at scale. Amazon SageMaker HyperPod coaching operator presents a sturdy answer to widespread challenges in giant mannequin coaching. Key takeaways embrace:
- One-click set up via AWS SageMaker HyperPod cluster console user-interface.
- Customized rendezvous backend eliminates initialization and employee synchronization overhead which ends up in sooner job begins and restoration.
- Course of degree restarts maximize restoration effectivity when runtime faults happen.
- Customizable hold job detection throughout coaching.
- Complete monitoring for early detection of coaching points.
- Out-of-box integration with current HyperPod resiliency options.
To get began with the Amazon SageMaker HyperPod coaching operator, comply with the setup directions supplied on this submit and discover the instance coaching job to know the way it can profit your particular use case. For extra data and finest practices, go to the Amazon SageMaker documentation.
Concerning the authors
 Arun Kumar Lokanatha is a Senior ML Options Architect with the Amazon SageMaker AI. He holds a Grasp’s diploma from UIUC with a specialization in Knowledge science. He focuses on Generative AI workloads, serving to clients construct and deploy LLM’s utilizing SageMaker HyperPod, SageMaker coaching jobs, and SageMaker distributed coaching. Outdoors of labor, he enjoys operating, climbing, and cooking.
Arun Kumar Lokanatha is a Senior ML Options Architect with the Amazon SageMaker AI. He holds a Grasp’s diploma from UIUC with a specialization in Knowledge science. He focuses on Generative AI workloads, serving to clients construct and deploy LLM’s utilizing SageMaker HyperPod, SageMaker coaching jobs, and SageMaker distributed coaching. Outdoors of labor, he enjoys operating, climbing, and cooking.
 Haard Mehta is a Software program Engineer with Amazon’s SageMaker AI crew and holds a Grasp’s diploma in Laptop Science with a specialization in massive information methods from Arizona State College. He has in depth expertise constructing managed machine studying companies at scale, with a give attention to {hardware} resiliency and enabling clients to reach their AI use circumstances with out advanced infrastructure administration. Haard enjoys exploring new locations, pictures, cooking, and highway journeys.
Haard Mehta is a Software program Engineer with Amazon’s SageMaker AI crew and holds a Grasp’s diploma in Laptop Science with a specialization in massive information methods from Arizona State College. He has in depth expertise constructing managed machine studying companies at scale, with a give attention to {hardware} resiliency and enabling clients to reach their AI use circumstances with out advanced infrastructure administration. Haard enjoys exploring new locations, pictures, cooking, and highway journeys.
 Anirudh Viswanathan is a Sr Product Supervisor, Technical – Exterior Providers with the SageMaker AI Coaching crew. He holds a Masters in Robotics from Carnegie Mellon College, an MBA from the Wharton Faculty of Enterprise, and is called inventor on over 40 patents. He enjoys long-distance operating, visiting artwork galleries, and Broadway reveals.
Anirudh Viswanathan is a Sr Product Supervisor, Technical – Exterior Providers with the SageMaker AI Coaching crew. He holds a Masters in Robotics from Carnegie Mellon College, an MBA from the Wharton Faculty of Enterprise, and is called inventor on over 40 patents. He enjoys long-distance operating, visiting artwork galleries, and Broadway reveals.



{kind=link}