
Because the demand for generative AI continues to develop, builders and enterprises search extra versatile, cost-effective, and highly effective accelerators to satisfy their wants. As we speak, we’re thrilled to announce the supply of G7e cases powered by NVIDIA RTX PRO 6000 Blackwell Server Version GPUs on Amazon SageMaker AI.
You’ll be able to provision nodes with 1, 2, 4, and eight RTX PRO 6000 GPU cases, with every GPU offering 96 GB of GDDR7 reminiscence. This launch offers the potential to make use of a single-node GPU, G7e.2xlarge occasion to host highly effective open supply basis fashions (FMs) like GPT-OSS-120B, Nemotron-3-Tremendous-120B-A12B (NVFP4 variant), and Qwen3.5-35B-A3B, providing organizations an economical and high-performing choice. This makes it effectively suited to these trying to enhance prices whereas sustaining excessive efficiency for inference workloads. The important thing highlights for G7e cases embrace:
- Twice the GPU reminiscence in comparison with G6e cases, enabling deployment of huge language fashions (LLMs) in FP16 as much as:
- 35B parameter mannequin on a single GPU node (G7e.2xlarge)
- 150B parameter mannequin on a 4 GPU node (G7e.24xlarge)
- 300B parameter mannequin on an 8 GPU node (G7e.48xlarge)
- As much as 1600 Gbps of networking throughput
- As much as 768 GB GPU Reminiscence on G7e.48xlarge
Amazon Elastic Compute Cloud (Amazon EC2) G7e cases symbolize a major leap in GPU-accelerated inference on the cloud. They ship as much as 2.3x inference efficiency in comparison with the previous-generation G6e cases. Every G7e GPU offers 1,597 GB/s bandwidth, doubling the per-GPU reminiscence of G6e and quadrupling that of G5. Networking scales to 1,600 Gbps with EFA on the most important G7e measurement—a 4x leap over G6e and 16x over G5—unlocking low-latency multi-node inference and fine-tuning situations that have been beforehand impractical on G-series cases. The next desk summarizes the generational development on the 8-GPU tier:
| Spec | G5 (g5.48xlarge) | G6e (g6e.48xlarge) | G7e (g7e.48xlarge) |
| GPU | 8x NVIDIA A10G | 8x NVIDIA L40S | 8x NVIDIA RTX PRO 6000 Blackwell |
| GPU Reminiscence per GPU | 24 GB GDDR6 | 48 GB GDDR6 | 96 GB GDDR7 |
| Complete GPU Reminiscence | 192 GB | 384 GB | 768 GB |
| GPU Reminiscence Bandwidth | 600 GB/s per GPU | 864 GB/s per GPU | 1,597 GB/s per GPU |
| vCPUs | 192 | 192 | 192 |
| System Reminiscence | 768 GiB | 1,536 GiB | 2,048 GiB |
| Community Bandwidth | 100 Gbps | 400 Gbps | 1,600 Gbps (EFA) |
| Native NVMe Storage | 7.6 TB | 7.6 TB | 15.2 TB |
| Inference vs. G6e | Baseline | ~1x | As much as 2.3x |
With 768 GB of combination GPU reminiscence on a single occasion, G7e can host fashions that beforehand required multi-node setups on G5 or G6e, lowering operational complexity and inter-node latency. Mixed with help for FP4 precision utilizing fifth-generation Tensor Cores and NVIDIA GPUDirect RDMA over EFAv4, G7e cases are positioned because the go-to alternative for deploying LLMs, multimodal AI, and agentic inference workloads on AWS.
Use circumstances effectively suited to G7e
G7e’s mixture of reminiscence density, bandwidth, and networking capabilities makes it effectively suited to a broad vary of contemporary generative AI workloads:
- Chatbots and conversational AI – G7e’s low TTFT and excessive throughput hold interactive experiences responsive even below heavy concurrent load.
- Agentic and tool-calling workflows – The 4x enchancment in CPU-to-GPU bandwidth makes G7e notably efficient for Retrieval Augmented Era (RAG) pipelines and agentic workflows the place quick context injection from retrieval shops is important.
- Textual content era, summarization, and long-context inference – G7e’s 96 GB per-GPU reminiscence accommodates massive KV caches for prolonged doc contexts—lowering truncation and enabling richer reasoning over lengthy inputs.
- Picture era and imaginative and prescient fashions – The place earlier cases encounter out-of-memory errors on bigger multimodal fashions, G7e’s doubled reminiscence resolves these limitations cleanly.
- Bodily AI and scientific computing – G7e’s Blackwell-generation compute, FP4 help, and spatial computing capabilities (DLSS 4.0, 4th-gen RT cores) prolong its applicability to digital twins, 3D simulation, and bodily AI mannequin inference.
Deployment walkthrough
Stipulations
To do this resolution utilizing SageMaker AI, you want the next stipulations:
Deployment
You’ll be able to clone the repository and use the pattern pocket book supplied right here.
Efficiency benchmarks
To quantify the generational enchancment, we benchmarked Qwen3-32B (BF16) on each G6e and G7e cases utilizing the identical workload: ~1,000 enter tokens and ~560 output tokens per request. That is consultant of doc summarization or correction duties. Each configurations use the native vLLM container with prefix caching enabled.
The benchmarking suite used to supply these outcomes is out there within the pattern Jupyter pocket book. It follows a three-step course of: (1) deploy the mannequin on a SageMaker AI endpoint utilizing the native vLLM container, (2) load check at concurrency ranges from 1–32 simultaneous requests, and (3) analyze the outcomes to supply the next efficiency tables.
G6e Baseline: ml.g6e.12xlarge [4x L40S, $13.12/hr]
With 4x L40S GPUs and tensor parallelism diploma 4, G6e delivers robust per-request throughput: 37.1 tok/s at single concurrency and 21.5 tok/s at C=32.
| C | Success | p50 (s) | p99 (s) | tok/s | RPS | Agg tok/s | $/M tokens |
|---|---|---|---|---|---|---|---|
| 1 | 100% | 16.1 | 16.3 | 37.1 | 0.07 | 37 | $38.09 |
| 8 | 100% | 19.8 | 20.2 | 30.3 | 0.42 | 242 | $5.85 |
| 16 | 100% | 23.1 | 23.5 | 26.0 | 0.73 | 416 | $3.41 |
| 32 | 100% | 26.0 | 29.2 | 21.5 | 1.21 | 686 | $2.06 |
G7e: ml.g7e.2xlarge [1x RTX PRO 6000 Blackwell, $4.20/hr]
G7e runs the identical 32B-parameter mannequin on a single GPU with tensor parallelism diploma 1. Whereas per-request tok/s is decrease than G6e’s 4-GPU configuration, the price story is dramatically totally different.
| C | Success | p50 (s) | p99 (s) | tok/s | RPS | Agg tok/s | $/M tokens |
|---|---|---|---|---|---|---|---|
| 1 | 100% | 27.2 | 27.5 | 22.0 | 0.04 | 22 | $21.32 |
| 8 | 100% | 28.7 | 28.9 | 20.9 | 0.28 | 167 | $2.81 |
| 16 | 100% | 30.3 | 30.6 | 19.9 | 0.53 | 318 | $1.48 |
| 32 | 100% | 33.2 | 33.3 | 18.5 | 0.99 | 592 | $0.79 |
What the numbers inform us
At manufacturing concurrency (C=32), G7e achieves $0.79 per million output tokens, a 2.6x price discount in comparison with G6e’s $2.06. That is pushed by two components: G7e’s considerably decrease hourly fee ($4.20 vs $13.12) and its capacity to take care of constant throughput below load.G7e’s single-GPU structure additionally scales extra gracefully. Latency will increase 22% from C=1 to C=32 (27.2s to 33.2s), in comparison with 62% for G6e (16.1s to 26.0s). With tensor parallelism diploma 1, there may be:
- No inter-GPU synchronization overhead
- No all-reduce operations at each transformer layer
- No cross-GPU KV cache fragmentation
- No NVLink communication bottleneck
As concurrency rises and the GPU turns into extra saturated, this absence of coordination overhead retains latency predictable. For latency-sensitive workloads at low concurrency, G6e’s 4-GPU parallelism nonetheless delivers quicker particular person responses. For manufacturing deployments optimizing for price per token at scale, G7e is the clear alternative, and as we present within the subsequent part, combining G7e with EAGLE (Extrapolation Algorithm for Better Language-model Effectivity) speculative decoding pushes the benefit even additional.
Mixed benchmarks: G7e + EAGLE speculative decoding
The {hardware} enhancements from G7e are important on their very own however combining them with EAGLE speculative decoding produces compounding positive factors. EAGLE accelerates LLM decoding by predicting a number of future tokens from the mannequin’s personal hidden representations, then verifying them in a single ahead cross. This produces similar output high quality whereas producing a number of tokens per step. For an in depth walkthrough of EAGLE on SageMaker AI, together with optimization job setup and the Base vs Skilled EAGLE workflow, see Amazon SageMaker AI introduces EAGLE based mostly adaptive speculative decoding to speed up generative AI inference.
On this part, we measure the stacked enchancment from baseline via G7e + EAGLE3 utilizing Qwen3-32B in BF16. The benchmark workload makes use of ~1,000 enter tokens and ~560 output tokens per request, consultant of doc summarization or correction duties. EAGLE3 is enabled utilizing a community-trained speculator (~1.56 GB) with num_speculative_tokens=4.
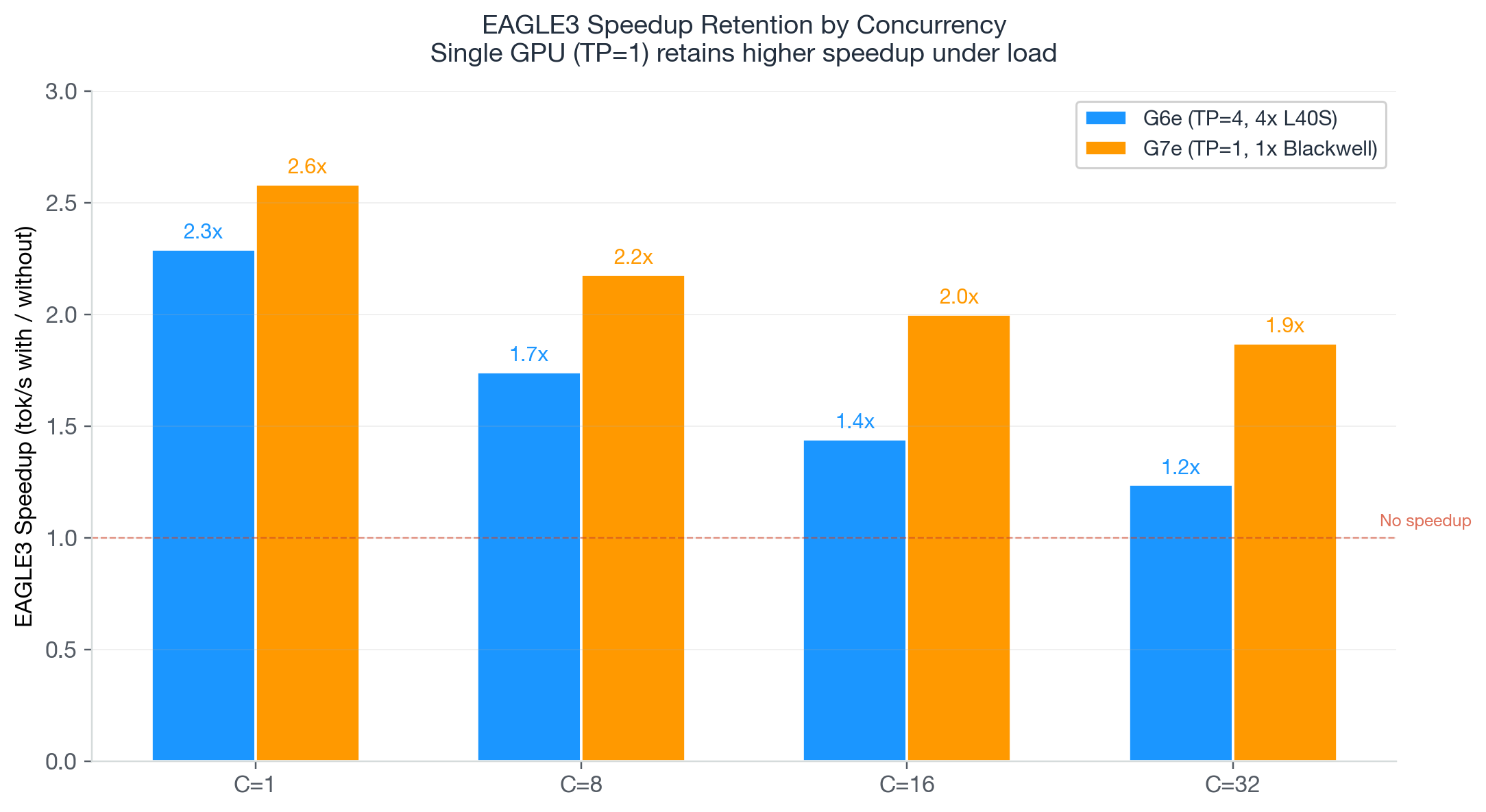
G7e + EAGLE3 delivers a 2.4x throughput enchancment and 75% price discount over the previous-generation baseline. At $0.41 per million output tokens, it’s also 4x cheaper than G6e + EAGLE3 ($1.72) regardless of providing larger throughput.
Enabling EAGLE3
For manufacturing deployments with fine-tuned fashions, the SageMaker AI EAGLE optimization toolkit can practice customized EAGLE heads by yourself knowledge, additional enhancing the speculative acceptance fee and throughput past what group speculators present.
Pricing
G7e cases on Amazon SageMaker AI are billed at normal SageMaker AI inference pricing for the chosen occasion sort and utilization length. There is no such thing as a further per-token or per-request payment for serving on G7e.
EAGLE optimization jobs run on SageMaker AI coaching cases and are billed at the usual SageMaker coaching occasion fee for the job length. The ensuing improved mannequin artifacts are saved in Amazon Easy Storage Service (Amazon S3) at normal storage charges. There is no such thing as a further cost for EAGLE-accelerated inference after the improved mannequin is deployed. You solely pay the usual endpoint occasion price.
The next desk reveals on-demand pricing for key G7e, G6e, and G5 occasion sizes in US East (N. Virginia) for reference. G7e rows are highlighted.
| Occasion | GPUs | GPU Reminiscence | Typical Use Case |
| ml.g5.2xlarge | 1 | 24 GB | Small LLMs (≤7B FP16); dev and check |
| ml.g5.48xlarge | 8 | 192 GB | Giant multi-GPU LLM serving on G5 |
| ml.g6e.2xlarge | 1 | 48 GB | Mid-size LLMs (≤14B FP16) |
| ml.g6e.12xlarge | 2 | 96 GB | Giant LLMs (≤36B FP16); earlier gen baseline |
| ml.g6e.48xlarge | 8 | 384 GB | Very massive LLMs (≤90B FP16) |
| ml.g7e.2xlarge | 1 | 96 GB | Giant LLMs (≤70B FP8) on a single GPU |
| ml.g7e.24xlarge | 4 | 384 GB | Very massive LLMs; high-throughput serving |
| ml.g7e.48xlarge | 8 | 768 GB | Most throughput; largest fashions |
You too can scale back inference prices with Amazon SageMaker Financial savings Plans, which supply reductions of as much as 64% in trade for a dedication to a constant utilization quantity. These are effectively suited to manufacturing inference endpoints with predictable visitors.
Clear up
To keep away from incurring pointless expenses after finishing your testing, delete the SageMaker endpoints created through the walkthrough. You are able to do this via the SageMaker AI console or with the Python SDK as proven within the Amazon SageMaker AI Developer Information.
In the event you ran an EAGLE optimization job, additionally delete the output artifacts from Amazon S3 to keep away from ongoing storage expenses.
Conclusion
G7e cases on Amazon SageMaker AI symbolize the following important leap in cost-effective generative AI inference. The Blackwell GPU structure delivers 2x reminiscence per GPU, 1.85x reminiscence bandwidth, and as much as 2.3x inference efficiency over G6e. This permits beforehand multi-GPU workloads to run effectively on a single GPU and elevating the throughput ceiling for each GPU configuration. Mixed with the EAGLE speculative decoding of SageMaker AI, the enhancements compound additional. EAGLE’s memory-bandwidth-bound acceleration advantages straight from G7e’s elevated bandwidth, whereas G7e’s bigger reminiscence capability permits EAGLE draft heads to co-exist with bigger fashions with out reminiscence strain. Collectively, the {hardware} and software program enhancements ship throughput positive factors that translate straight into decrease price per output token at scale.
The development from G5 to G6e to G7e, layered with EAGLE optimization, represents a virtually steady hardware-software co-optimization path, one which retains enhancing as fashions evolve, and manufacturing visitors knowledge is captured and fed again into EAGLE retraining.
Concerning the authors



{kind=link}