
Organizations are racing to deploy generative AI fashions into manufacturing to energy clever assistants, code era instruments, content material engines, and customer-facing purposes. However deploying these fashions to manufacturing stays a weeks-long means of navigating GPU configurations, optimization strategies, and handbook benchmarking, delaying the worth these fashions are constructed to ship.
As we speak, Amazon SageMaker AI helps optimized generative AI inference suggestions. By delivering validated, optimum deployment configurations with efficiency metrics, Amazon SageMaker AI retains your mannequin builders targeted on constructing correct fashions, not managing infrastructure.
We evaluated a number of benchmarking instruments and selected NVIDIA AIPerf, a modular element of NVIDIA Dynamo, as a result of it exposes detailed, constant metrics and helps numerous workloads out of the field. Its CLI, concurrency controls, and dataset choices give us the flexibleness to iterate shortly and take a look at throughout totally different eventualities with minimal setup.
“With the mixing of modular elements of the open supply NVIDIA Dynamo distributed inference framework instantly into Amazon SageMaker AI, AWS is making it simpler for enterprises to deploy generative AI fashions with confidence. AWS has been instrumental in advancing AIPerf by deep collaboration and technical contributions. The mixing of NVIDIA AIPerf demonstrates how standardized benchmarking can get rid of weeks of handbook testing and ship validated, deployment-ready configurations to finish customers.”
– Eliuth Triana, Developer Relations Supervisor of NVIDIA.
The problem: From mannequin to manufacturing takes weeks
Deploying fashions at scale requires manufacturing inference endpoints that fulfill clear efficiency objectives, whether or not that could be a latency service stage settlement (SLA), a throughput goal, or a value ceiling. Attaining that requires discovering the appropriate mixture of GPU occasion sort, serving container, parallelism technique, and optimization strategies, all tuned to the particular mannequin and visitors patterns.

Determine 1: The three core challenges groups face when deploying generative AI fashions to manufacturing
The choice house is impossibly giant. A single deployment includes selecting from over a dozen GPU occasion varieties, a number of serving containers, varied parallelism levels, and a rising set of optimization strategies resembling speculative decoding. These all work together with one another, and there’s no validated steering to slim the search. The one technique to discover the appropriate configuration is to check, and that’s the place the true price begins. Groups provision situations, deploy the mannequin, run load exams, analyze outcomes, and repeat. This cycle takes two to 3 weeks per mannequin and requires experience in GPU infrastructure, serving frameworks, and efficiency optimization that the majority groups don’t have in-house.
Many groups begin manually: they decide just a few occasion varieties, deploy the mannequin, run load exams, examine latency, throughput, and price, then repeat. Extra mature groups usually script elements of the method utilizing benchmarking instruments, deployment templates, or steady integration and steady supply (CI/CD) pipelines. Even when workloads are scripted, groups nonetheless face vital work. They should take a look at and validate their scripts, select which configurations to benchmark, arrange the benchmarking setting, interpret the outcomes, and stability trade-offs between latency, throughput, and price.
Groups are sometimes left making high-stakes infrastructure selections with out understanding whether or not a greater, more cost effective possibility exists. They default to over-provisioning, selecting dearer GPU infrastructure than they want and operating configurations that don’t totally use the compute assets they’re paying for. The chance of under-performing in manufacturing is way worse than overspending on compute. The result’s wasted GPU spend that compounds with each mannequin deployed and each month the endpoint runs.
How optimized generative AI inference suggestions work
You carry your personal generative AI mannequin, outline your anticipated visitors patterns, and specify a single efficiency purpose: optimize for price, decrease latency, or maximize throughput. From there, SageMaker AI takes over in three levels.
Stage 1: Slim the configuration house
SageMaker AI analyzes the mannequin’s structure, measurement, and reminiscence necessities to determine the occasion varieties and parallelism methods that may realistically meet your purpose. As a substitute of testing each doable mixture, it narrows the search to the configurations value evaluating, throughout the occasion varieties you choose (as much as three).
Stage 2: Apply goal-aligned optimizations
Primarily based in your chosen efficiency purpose, SageMaker AI applies the optimization strategies to every candidate configuration resembling:
- For throughput objectives, it trains speculative decoding fashions (resembling EAGLE 3.0) that enable the mannequin to generate a number of tokens per ahead cross, considerably rising tokens per second.
- For latency objectives, it tunes compute kernels to scale back per-token processing time, reducing time to first token.
- Tensor parallelism is utilized primarily based on mannequin measurement and occasion functionality, distributing the mannequin throughout accessible GPUs to deal with fashions that exceed single-GPU reminiscence.
You do not want to know which method is true on your purpose. SageMaker AI selects and applies the optimizations routinely.
Stage 3: Benchmark and return ranked suggestions
SageMaker AI benchmarks every optimized configuration on actual GPU infrastructure utilizing NVIDIA AIPerf, measuring time to first token, inter-token latency, P50/P90/P99 request latency, throughput, and price. The result’s a set of ranked, deployment-ready suggestions with validated metrics for every configuration and occasion sort. Here’s what the workflow appears to be like like out of your perspective utilizing SageMaker AI APIs.
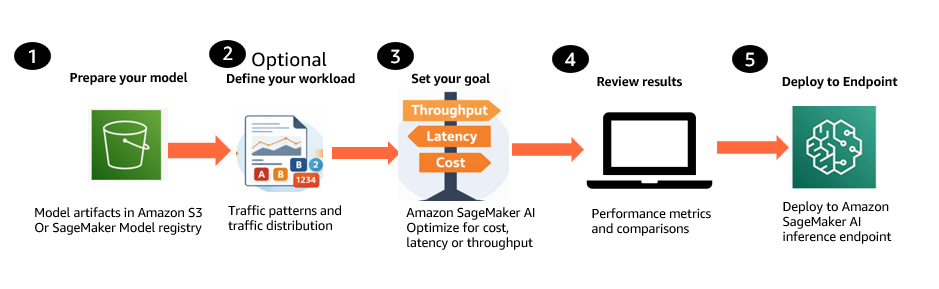
Determine 2: Generative AI inference suggestions workflow
- Put together your mannequin. Convey your generative AI mannequin from Amazon Easy Storage Service (Amazon S3) or the SageMaker Mannequin Registry, together with Hugging Face checkpoint codecs with SafeTensor weights, base fashions, and customized or fine-tuned fashions educated by yourself knowledge.
- Outline your workload (elective). Describe anticipated visitors patterns, together with enter and output token distributions and concurrency ranges. You’ll be able to present these inline or use a consultant dataset from Amazon S3.
- Set your optimization purpose. Select a single goal: optimize for price, decrease latency, or maximize throughput. Choose as much as three occasion varieties to match.
- Evaluate ranked suggestions. SageMaker AI returns deployment-ready configurations with validated metrics resembling Time to First Token, inter-token latency, P50/P90/P99 request latency, throughput, and price projections. Evaluate the suggestions and choose the very best match.
- Deploy the chosen configuration. Deploy the chosen configuration to a SageMaker inference endpoint programmatically by the API.
Extra choices: You can too benchmark present manufacturing endpoints to validate present efficiency or examine them towards new configurations. SageMaker AI can use present machine studying (ML) Reservations (Versatile Coaching Plans) at no extra compute price, or use on-demand compute provisioned routinely.
Pricing
There is no such thing as a extra prices for producing optimized generative AI inference suggestions. Clients incur normal compute prices for the optimization jobs that generate optimized configurations and for the endpoints provisioned throughout benchmarking. Clients with present ML Reservations (Versatile Coaching Plans) can run benchmarking on their reserved capability at no extra price, which means the one price is the optimization job itself.
Getting began with optimized generative AI inference suggestions requires just a few API calls with SageMaker AI.
For detailed API walkthroughs, code examples, and pattern notebooks, see the SageMaker AI documentation and the pattern notebooks on GitHub.
Benchmarking rigor inbuilt
Each suggestion from SageMaker AI is grounded in actual measurements, not estimates or simulations. Underneath the hood, SageMaker AI benchmarks each configuration on actual GPU infrastructure utilizing NVIDIA AIPerf, an open-source benchmarking device that measures key inference metrics together with time to first token, inter-token latency, throughput, and requests per second.
AWS has contributed to AIPerf to strengthen the statistical basis of benchmarking outcomes. These contributions embrace multi-run confidence reporting, enabling you to measure variance throughout repeated benchmark trials and quantify end result high quality with statistically grounded confidence intervals. This strikes you past fragile single-run numbers towards benchmark outcomes you’ll be able to belief when making selections about mannequin choice, infrastructure sizing, and efficiency regressions. AWS additionally contributed adaptive convergence and early stopping, permitting benchmarks to cease as soon as metrics have stabilized as an alternative of at all times operating a set variety of trials. This implies decrease benchmarking price and sooner time to outcomes with out sacrificing rigor. For the broader inference neighborhood, it raises the standard of benchmarking methodology by specializing in repeatability, statistical confidence, and distribution-aware evaluation fairly than headline numbers from a single trial.
Optimizations in motion
To see what these goal-aligned optimizations appear to be in follow, take into account an actual instance. A buyer deploying GPT-OSS-20B on a single ml.p5en.48xlarge (H100) occasion selects maximize throughput as their efficiency purpose. SageMaker AI identifies speculative decoding as the appropriate optimization for this purpose, trains an EAGLE 3.0 draft mannequin, applies it to the serving configuration, and benchmarks each the baseline and the optimized configuration on actual GPU infrastructure.
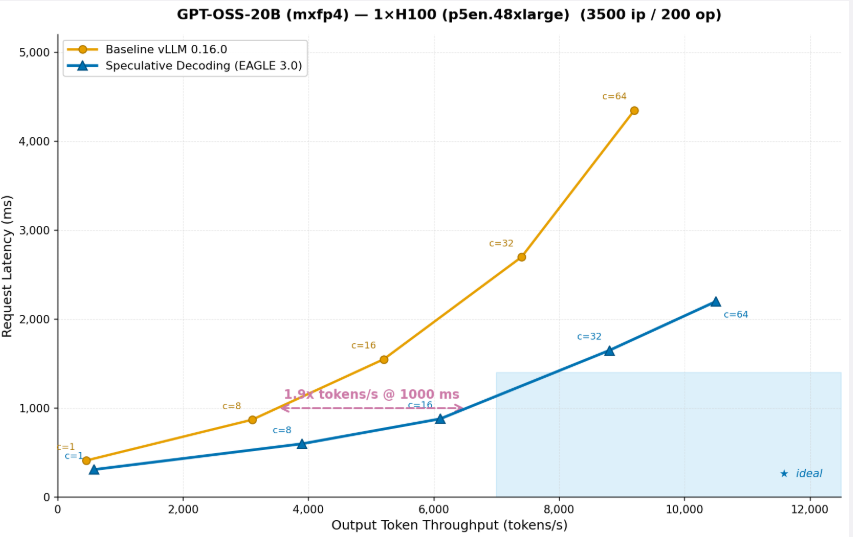
Determine 3: GPT-OSS-20B (mxfp4) on 1x H100 (p5en.48xlarge) (3500 ip / 200 op)
The graph exhibits that after operating throughput optimization on the OSS-20B mannequin, the identical occasion can serve 2x extra tokens on the identical request latency. After throughput optimization, the identical occasion delivers 2x extra tokens/s at 1,000ms latency means you’ll be able to serve twice as many customers on the identical {hardware}, successfully chopping inference price per token in half. That is precisely the sort of optimization that SageMaker AI applies routinely when you choose a throughput purpose. You do not want to know that speculative decoding is the appropriate method, or how you can prepare a draft mannequin, or how you can configure it on your particular mannequin and {hardware}. SageMaker AI handles it finish to finish and returns the validated outcomes as a part of the ranked suggestions.
Buyer worth
Price effectivity and transparency: Clear price-performance comparisons throughout occasion sorts of your alternative allow right-sizing as an alternative of defaulting to the most costly possibility. As a substitute of over-provisioning since you can’t afford to danger under-performing, you’ll be able to choose the configuration that delivers the efficiency you want on the proper price. Financial savings compound with each mannequin deployed and each month the endpoint runs.
Pace to manufacturing: Groups iterate sooner, take a look at extra configurations, and get to manufacturing sooner. Day by day saved in deployment is a day your generative AI funding is delivering worth to prospects.
Confidence in manufacturing: Each suggestion is backed by actual measurements on actual GPU infrastructure utilizing NVIDIA AIPerf, not estimates or simulations. Deploy understanding your configuration has been validated towards your particular mannequin and workload, at percentile-level precision that matches manufacturing situations.
Use circumstances
- Pre-deployment validation: Optimize and benchmark a brand new mannequin earlier than committing to a manufacturing deployment. Know precisely the way it will carry out earlier than you spend money on scaling it.
- Regression testing after updates: Validate efficiency after a container replace, framework improve, or serving library launch. Affirm that your configuration remains to be optimum earlier than pushing to manufacturing.
- Proper-sizing when situations change: When visitors patterns shift or new occasion varieties grow to be accessible, re-run optimized generative AI inference suggestions in hours fairly than restarting a weeks-long handbook course of.
- Mannequin comparability: Evaluate the efficiency and price of various mannequin variants throughout occasion varieties to make an knowledgeable choice earlier than manufacturing deployment.
- Price optimization: Benchmark present manufacturing endpoints to determine over-provisioned infrastructure. Use the outcomes to right-size and cut back recurring inference spend.
Benchmark inference endpoints
An AI benchmark job runs efficiency benchmarks towards your SageMaker AI inference endpoints utilizing a predefined workload configuration. Use benchmark jobs to measure the efficiency of your generative AI inference infrastructure earlier than and after optimization. When the benchmark job is accomplished, the outcomes are saved within the Amazon S3 output location that you just specified. As soon as the benchmark job completes, all outcomes are written to your S3 output path in output folder as proven under screenshot:
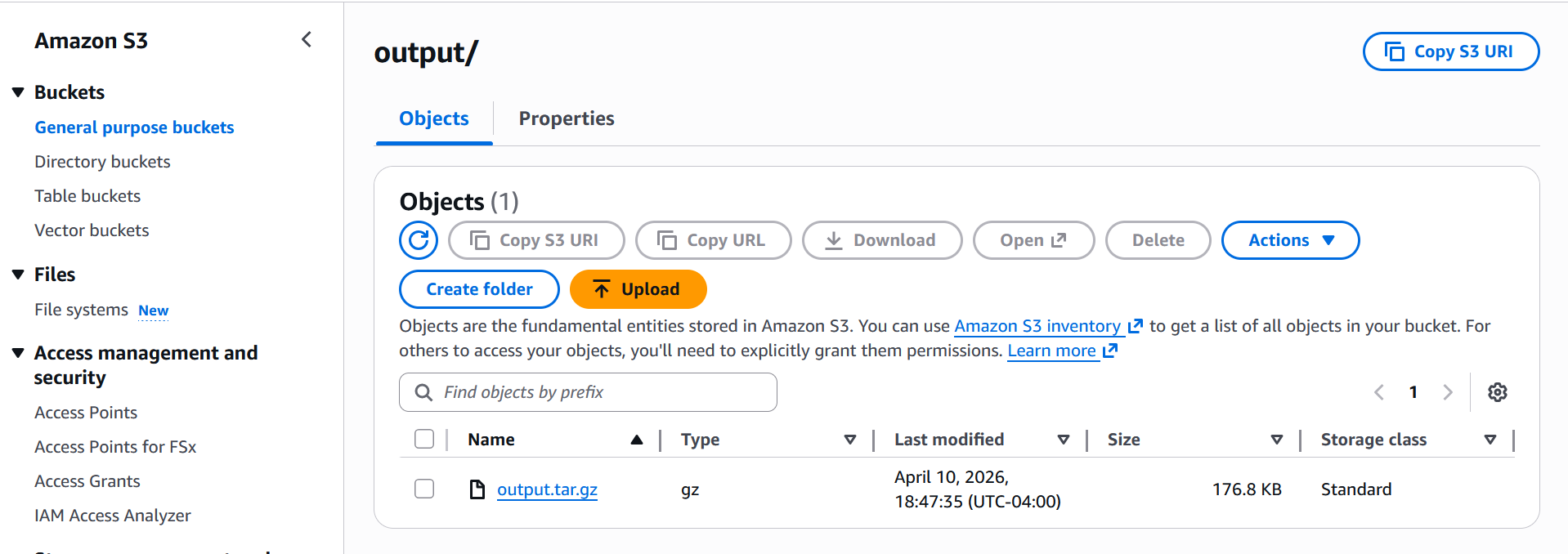
When you obtain and extract the zip output file, you’ll get under information
The principle output is profile_export_aiperf.json and its CSV counterpart profile_export_aiperf.csv each comprise the identical aggregated metrics: latency percentiles (p50, p90, p99), output token throughput, time-to-first-token (TTFT), and inter-token latency (ITL). These are the numbers you’d use to judge how the mannequin carried out below the simulated load.
Alongside that, profile_export.jsonl offers you the uncooked per-request knowledge each particular person request logged with its personal latency, token counts, and timestamp. That is helpful if you wish to do your personal evaluation or spot outliers that the aggregated stats would possibly cover.
We’ve created a pattern pocket book in Github which benchmarks openai/gpt-oss-20b deployed on a ml.g6.12xlarge occasion (4× NVIDIA L40S GPUs), served by way of the vLLM container as an Inference Part. It simulates a sensible workload utilizing artificial prompts: 300 requests at 10 concurrent customers, with ~500 enter and ~150 output tokens per request, to measure how the mannequin performs below that load.
Deploying mannequin from suggestions
After the AI Advice Job completes, the output is a SageMaker Mannequin Bundle which is a versioned useful resource that bundles all instance-specific deployment configurations right into a single artifact.
To deploy, you first convert the Mannequin Bundle right into a Deployable Mannequin by calling CreateModel with the ModelPackageName and the InferenceSpecificationName for the occasion you wish to goal, then create an endpoint configuration and deploy as a typical SageMaker real-time endpoint or Inference Part.
- Decide the advice you wish to deploy
- Convert Mannequin Bundle → Deployable Mannequin
- Create endpoint config
- Deploy and wait
Alternatively, if you wish to use Inference Elements as an alternative of a single-model endpoint, You’ll be able to comply with the pocket book for particulars. This design means a single Advice Job produces one Mannequin Bundle with a number of InferenceSpecifications, one per evaluated occasion sort. So you’ll be able to decide the configuration that matches your latency, throughput, or price goal and deploy it instantly with out re-running the job.
Getting began
This functionality is accessible right this moment in seven AWS Areas: US East (N. Virginia), US West (Oregon), US East (Ohio), Asia Pacific (Tokyo), Europe (Eire), Asia Pacific (Singapore), and Europe (Frankfurt). Entry it by the SageMaker AI APIs.
Conclusion
On this submit, we confirmed how optimized generative AI inference suggestions in Amazon SageMaker AI cut back deployment time from weeks to hours. With this functionality, you’ll be able to give attention to constructing correct fashions and the merchandise that matter to your prospects, not on infrastructure tuning. Each configuration is validated on actual GPU infrastructure towards your particular mannequin and workload, so you’ll be able to deploy with confidence and right-size with readability.
To study extra, go to the SageMaker AI documentation and take a look at the pattern notebooks on GitHub.
Concerning the authors



{kind=link}