
As firms of assorted sizes undertake graphic processing items (GPU)-based machine studying (ML) coaching, fine-tuning and inference workloads, the demand for GPU capability has outpaced industry-wide provide. This imbalance has made GPUs a scarce useful resource, making a problem for patrons who want dependable entry to GPU compute assets for his or her ML workloads.
Whenever you encounter GPU capability limitations, you may contemplate creating on-demand capability reservations (ODCRs). ODCRs apply to deliberate, steady-state workloads with well-understood utilization patterns. Quick-term ODCR availability for GPU situations, significantly P-type situations, is usually restricted. Moreover, with no long-term contract, ODCRs are billed at on-demand charges, providing no value benefit. This makes ODCRs unsuitable for brief or exploratory workloads reminiscent of testing, evaluations, or occasions. A guided method to safe short-term GPU capability turns into mandatory.
On this put up, you’ll learn to safe reserved GPU capability for short-term workloads utilizing Amazon Elastic Compute Cloud (Amazon EC2) Capability Blocks for ML and Amazon SageMaker coaching plans. These options can tackle GPU availability challenges whenever you want short-term capability for load testing, mannequin validation, time-bound workshops, or making ready inference capability forward of a launch.
Resolution overview and short-term GPU choices
There are a number of methods to entry GPU capability on AWS for short-term workloads:
On-demand GPU situations
On-demand situations are often the primary possibility for short-term GPU utilization. If capability is out there at launch time, you can begin utilizing GPU situations instantly with out prior dedication. This works nicely for advert hoc experiments, quick checks and growth duties.
On-demand GPU capability relies on regional provide and present demand, and availability can change rapidly. Should you cease or scale down an occasion, you won’t be capable to reacquire the identical capability when wanted once more. This uncertainty usually results in holding GPU situations working longer than wanted, which might improve value. Select on-demand situations when your workload can tolerate potential launch delays or when timing is versatile.
Spot GPU situations
Spot situations can scale back your GPU compute prices by as much as 90%, however they commerce value saving for availability certainty. Spot capability relies on unused capability within the AWS Area. Situations may be interrupted when Amazon EC2 wants the capability again, thus spot situations are appropriate just for workloads that may deal with interruption.
For ML workloads, spot situations work nicely when you possibly can checkpoint progress and restart. Advisable use instances embody distributed coaching jobs with periodic checkpoints, batch inference workloads that may be retried, and workshop environments which can be designed to tolerate partial capability.
Amazon EC2 Capability Blocks for ML
Amazon EC2 Capability Blocks for ML reserves GPU capability for a selected time window in order that the requested situations can be out there whenever you launch them throughout the reserved interval. In contrast to ODCRs, Capability Blocks are absolutely self-service and supply higher short-term availability for GPU situations with a 40-50% discounted charge. Every Capability Block represents a reservation of a selected variety of a specific occasion kind for an outlined period. You may:
Capability Blocks apply to workloads that run instantly on Amazon EC2, the place you handle the working system, networking, and orchestration layers your self.
Service stage settlement (SLA) and {hardware} failures: If {hardware} fails throughout your reservation, you possibly can terminate the affected occasion and manually launch a substitute into the identical Capability Blocks reservation. The system returns the reserved capability slot to your reservation after roughly 10 minutes of cleanup. Amazon EC2 maintains a buffer inside every Capability Block to help relaunching situations in case of {hardware} degradation, at no further value.
Notice: Capability Blocks have the next limitations:
Amazon SageMaker coaching plans
Amazon SageMaker coaching plans present entry to order GPU capability for ML workloads within the Amazon SageMaker AI managed setting, reminiscent of coaching jobs, Amazon SageMaker HyperPod clusters and inference. SageMaker coaching plans aren’t interchangeable with EC2 Capability Blocks. With SageMaker coaching plans, you possibly can:
- Schedule reservations for particular GPU-based situations and durations.
- Entry your capability with out managing underlying infrastructure.
- Use a spread of accelerated computing choices, together with the newest NVIDIA GPUs and AWS Trainium accelerators.
Notice that G-type situations (besides G6 situations) aren’t presently supported by SageMaker coaching plans. Should you want G6 situations, contact your AWS account staff. For detailed details about the supported occasion sorts in a given AWS Area, period, and amount choices, see Supported occasion sorts, AWS Areas, and pricing.
Amazon SageMaker coaching plans apply to:
Select this feature whenever you need Amazon SageMaker AI to handle occasion provisioning, scaling, and lifecycle whereas nonetheless securing reserved capability throughout an outlined window.
Resolution framework: selecting the best possibility
When planning your short-term GPU technique, you need to consider choices based mostly on three key components:
- Availability: From on-demand to reserved capability.
- Price mannequin: On-demand pricing or upfront commitments with decrease than on-demand pricing.
- Workload setting: Amazon EC2 direct entry in comparison with Amazon SageMaker-managed workloads.
- From short-term to long-term capability planning: Whereas this put up focuses on securing short-term GPU capability, you may must plan for longer-term or recurring workloads. You may run assessments based mostly on historic information; or use short-term GPU assets to load check your workload and achieve higher understanding of the occasion quantity and kind wanted for manufacturing. For manufacturing deployments or large-scale occasions requiring vital GPU capability, begin planning not less than three weeks prematurely. Work along with your AWS account staff to evaluate your necessities and develop a capability technique that meets your timeline.
Price consideration
- Capability Blocks for ML require upfront fee and supply 40-50% decrease hourly charges in comparison with on-demand pricing. For instance in US East (N. Virginia), p5.48xlarge prices $34.608/hour with Capability Blocks versus $55.04/hour on-demand.
- SageMaker coaching plans are priced 70-75% beneath on-demand charges. You pay the worth up entrance on the time you schedule the reservation. AWS usually updates costs based mostly on tendencies in provide and demand. You pay the speed that’s present on the time that you simply make the reservation, even when the coaching plan begins later after the worth adjustments.
- In case your situations don’t run constantly all through the reservation interval, the overall value of creating reservations may exceed on-demand value. Consider based mostly in your workload’s precise runtime wants.
- Disclaimer: All pricing figures referenced on this part are based mostly on publicly out there AWS pricing as of the date of publication and are topic to vary. For probably the most present pricing, check with Amazon EC2 pricing and SageMaker AI pricing.
Resolution course of
Begin with the least restrictive possibility and transfer towards reserved capability when availability or timing turns into crucial.
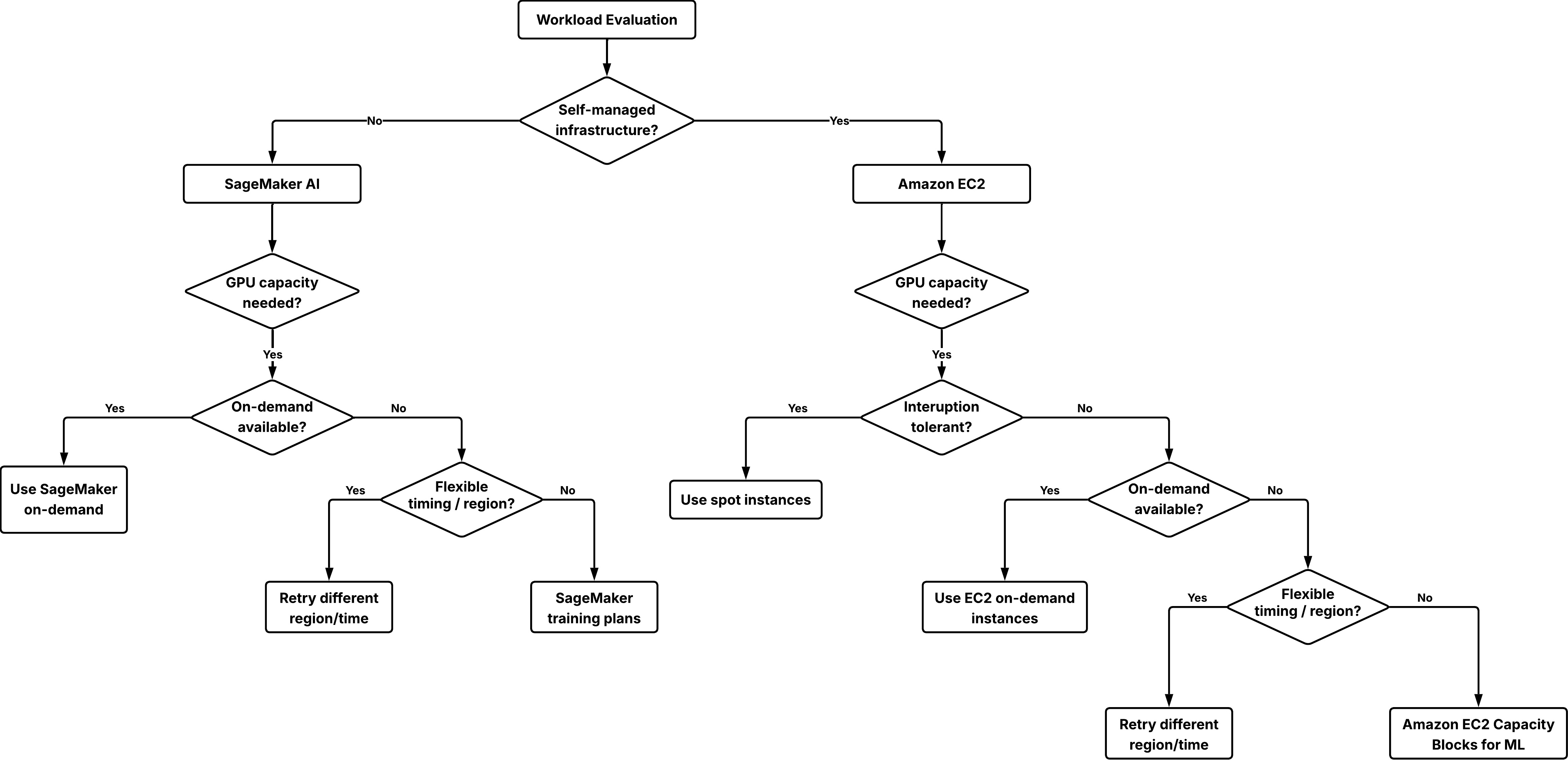
Resolution tree to decide on the suitable possibility for securing GPU capability.
Step 1: Decide your infrastructure administration mannequin
- Should you want full management over the working system, networking, and orchestration, use Amazon EC2 and use on-demand situations, spot situations, or Capability Blocks.
- If you need a managed service that handles infrastructure provisioning and operations for you, use Amazon SageMaker AI and use SageMaker on-demand or SageMaker coaching plans for ml.* occasion sorts.
Step 2: Strive on-demand capability first
For each Amazon EC2 and Amazon SageMaker AI workloads, begin with on-demand capability. This method:
- Requires no prior dedication.
- Permits fast begin if capability is out there.
If an preliminary launch fails, strive these flexibility choices:
- Strive a distinct AWS Area the place capability is perhaps out there.
- Alter the beginning time to off-hours when demand is usually decrease.
- Use spot situations as a complement on workloads that may tolerate interruption.
Step 3: Use reserved capability when certainty is required
In case your workload should begin at a selected time or your supply timeline relies on reserved GPU entry, reserving capability turns into the suitable selection:
- For Amazon EC2 workloads, use Capability Blocks for ML.
- For Amazon SageMaker AI workloads, use Amazon SageMaker coaching plans for both coaching jobs, HyperPod clusters, or inference workloads.
Technical implementation: Reserving GPU capability for inference with SageMaker coaching plans
This part reveals you learn how to reserve and use GPU capability for inference workloads managed by Amazon SageMaker coaching plans. Notice that SageMaker coaching plans reservations are particular to the chosen goal useful resource. A plan bought for inference can’t be used for Coaching Jobs or HyperPod clusters, or the reverse.
For different situations:
Stipulations
Earlier than you start, verify that you’ve got:
{
"Model": "2012-10-17",
"Assertion": [
{
"Effect": "Allow",
"Action": [
"sagemaker:CreateEndpointConfig",
"sagemaker:CreateEndpoint",
"sagemaker:DescribeEndpoint",
"sagemaker:DeleteEndpoint",
"sagemaker:DeleteEndpointConfig"
],
"Useful resource": [
"arn:aws:sagemaker:*:*:endpoint/*",
"arn:aws:sagemaker:*:*:endpoint-config/*"
]
}
]
}Create a coaching plan
To get began, go to the Amazon SageMaker AI console, select Coaching plans within the left navigation pane, and select Create coaching plan.
The Coaching plans web page within the Amazon SageMaker AI console.
For instance, select your most popular coaching date and period (1 day), occasion kind and depend (1 ml.trn1.32xlarge) for Inference Endpoint, and select Discover coaching plan.
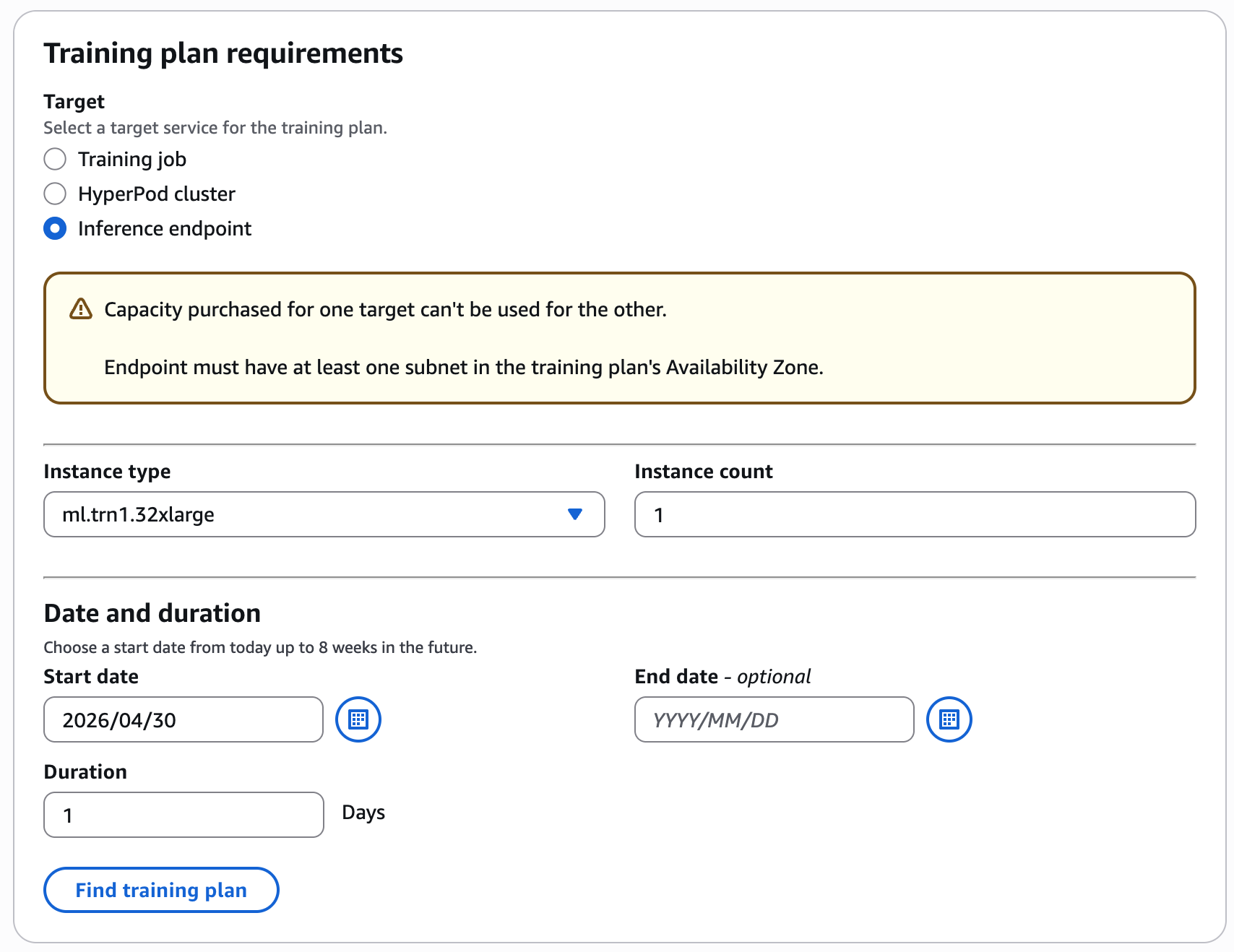
Configure your coaching plan by choosing the occasion kind, occasion depend, date and period on your inference workload.
The console shows out there plans with the overall value.
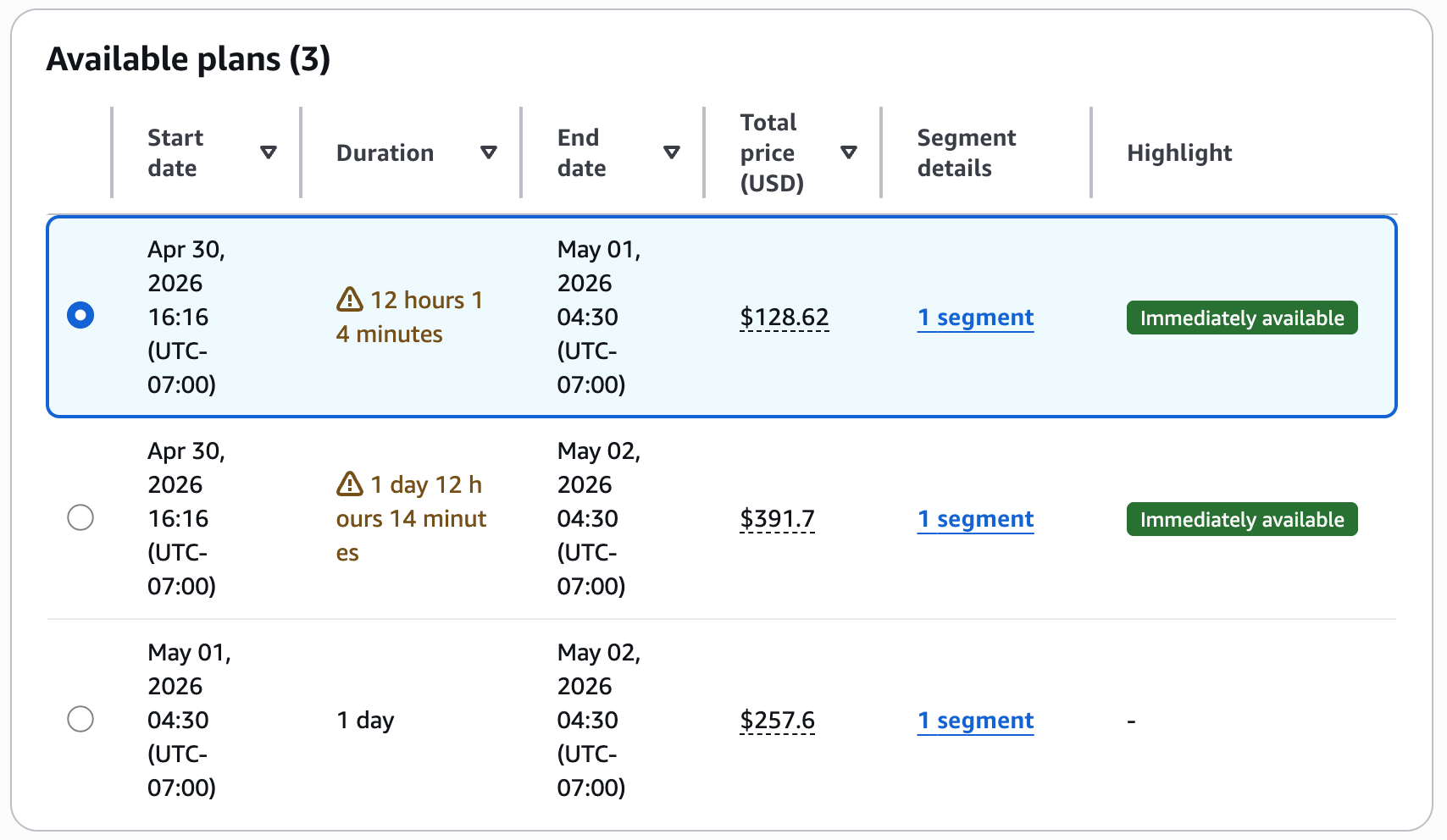
Overview the urged plans with upfront pricing earlier than accepting the reservation.
Should you settle for this coaching plan, add your coaching particulars within the subsequent step and select Create your plan.
Notice: SageMaker coaching plans can’t be canceled after buy. The reservation will expire robotically on the finish of the reserved interval.
To observe coaching plan standing
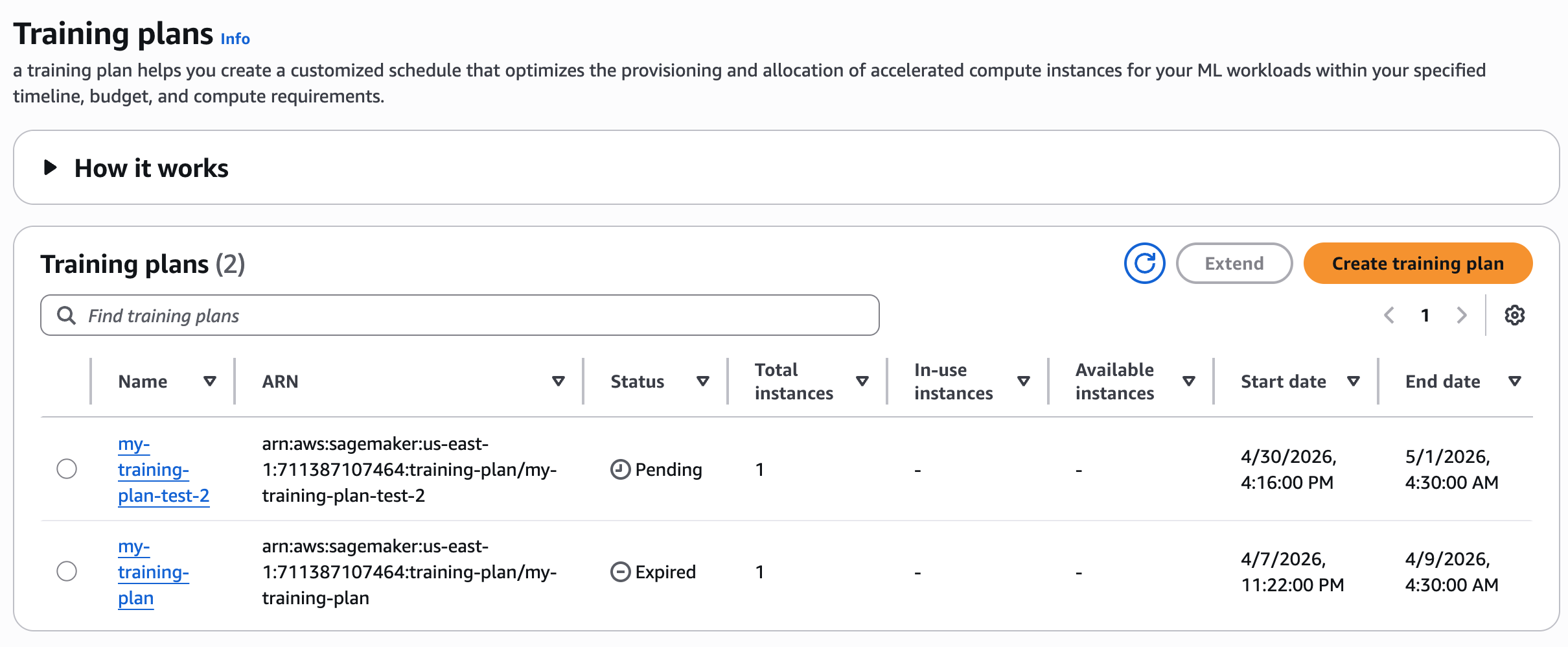
Overview your coaching plan standing within the console.
After creating your coaching plan, you possibly can see the checklist of coaching plans. The plan initially enters a Pending state, awaiting fee. You pay the complete value of a coaching plan up entrance. After AWS completes fee processing, the plan will transition to the Scheduled state. On the plan’s begin date, it turns into Energetic, and the system allocates assets on your use.
To confirm coaching plan standing with AWS CLI
Use the next command to test the coaching plan standing:
aws sagemaker describe-training-plan
--training-plan-name your-training-plan-name
--region your-regionWhen the response reveals "Standing": "Energetic", you can begin working your inference duties. Confirm that the TargetResources area reveals endpoint to substantiate the plan is configured for inference workloads.
To create endpoint configuration
Use the next command to generate an endpoint configuration that makes use of the coaching plan assets:
aws sagemaker create-endpoint-config
--endpoint-config-name your-endpoint-config-name
--production-variants '[
{
"VariantName": "your-variant-name",
"ModelName": "your-model-name",
"InitialInstanceCount": 1,
"InstanceType": "ml.trn1.32xlarge",
"CapacityReservationConfig": {
"MlReservationArn": "your-training-plan-arn",
"CapacityReservationPreference": "capacity-reservations-only"
}
}
]'To deploy the endpoint
Create your endpoint useful resource by specifying the endpoint configuration from the earlier step:
aws sagemaker create-endpoint
--endpoint-name your-endpoint-name
--endpoint-config-name your-endpoint-config-nameTo confirm endpoint standing
Examine your endpoint standing and coaching plan capability reservation standing:
aws sagemaker describe-endpoint
--endpoint-name your-endpoint-name
--region your-regionClear up assets
To keep away from incurring ongoing fees, delete the assets that you simply created:
Delete the endpoint:
aws sagemaker delete-endpoint --endpoint-name your-endpoint-nameDelete the endpoint configuration:
aws sagemaker delete-endpoint-config --endpoint-config-name your-endpoint-config-nameConclusion
Securing GPU capability for transient workloads requires a distinct method than planning long-term, steady-state utilization. On this put up, you discovered learn how to method short-term GPU capability planning by:
- Beginning with on-demand capability and growing flexibility when attainable.
- Distinguishing between Amazon EC2–based mostly workloads and Amazon SageMaker AI managed workloads.
- Reserving capability utilizing Capability Blocks or SageMaker coaching plans when availability and certainty are required.
You additionally discovered learn how to use SageMaker coaching plans to order GPU capability forward of time. This functionality helps scale back operational friction when making ready inference capability for deliberate evaluations, releases, or anticipated visitors will increase.
To be taught extra, check with the next assets:
Concerning the authors



{kind=link}