
This publish is cowritten with Abdullahi Olaoye, Akshit Arora and Eliuth Triana Isaza at NVIDIA.
As enterprises proceed to push the boundaries of generative AI, scalable and environment friendly mannequin coaching frameworks are important. The NVIDIA NeMo Framework supplies a strong, end-to-end resolution for growing, customizing, and deploying large-scale AI fashions, whereas Amazon SageMaker HyperPod delivers the distributed infrastructure wanted to deal with multi-GPU, multi-node workloads seamlessly.
On this weblog publish, we discover find out how to combine NeMo 2.0 with SageMaker HyperPod to allow environment friendly coaching of huge language fashions (LLMs). We cowl the setup course of and supply a step-by-step information to working a NeMo job on a SageMaker HyperPod cluster.
NVIDIA NeMo Framework Overview
The NVIDIA NeMo Framework is an end-to-end resolution for growing innovative generative AI fashions corresponding to LLMs, imaginative and prescient language fashions (VLMs), video and speech fashions, and others.
At its core, NeMo Framework supplies mannequin builders with:
- Complete growth instruments: An entire ecosystem of instruments, scripts, and confirmed recipes that information customers by means of each section of the LLM lifecycle, from preliminary knowledge preparation to ultimate deployment.
- Superior customization: Versatile customization choices that groups can use to tailor fashions to their particular use instances whereas sustaining peak efficiency.
- Optimized infrastructure: Subtle multi-GPU and multi-node configurations that maximize computational effectivity for each language and picture purposes.
- Enterprise-grade options with built-in capabilities together with:
- Superior parallelism methods
- Reminiscence optimization methods
- Distributed checkpointing
- Streamlined deployment pipelines
By consolidating these highly effective options right into a unified framework, NeMo considerably reduces the complexity and price related to generative AI growth. NeMo Framework 2.0 is a versatile, IDE-independent Python-based framework that allows versatile integration in every developer’s workflow. The framework supplies capabilities corresponding to code completion, sort checking and programmatic extensions and configuration customization. The NeMo Framework contains NeMo-Run, a library designed to that streamline the configuration, execution, and administration of machine studying experiments throughout numerous computing environments.
The tip-to-end NeMo Framework contains the next key options that streamline and speed up AI growth:
- Knowledge curation: NeMo Curator is a Python library that features a suite of modules for data-mining and artificial knowledge technology. They’re scalable and optimized for GPUs, making them ideally suited for curating pure language knowledge to coach or fine-tune LLMs. With NeMo Curator, you may effectively extract high-quality textual content from intensive uncooked internet knowledge sources.
- Coaching and customization: NeMo Framework supplies instruments for environment friendly coaching and customization of LLMs and multimodal fashions. It contains default configurations for compute cluster setup, knowledge downloading, and mannequin hyperparameters autotuning, which could be adjusted to coach on new datasets and fashions. Along with pre-training, NeMo helps each supervised fine-tuning (SFT) and parameter-efficient fine-tuning (PEFT) methods corresponding to LoRA, Ptuning, and extra.
- Alignment: NeMo Aligner is a scalable toolkit for environment friendly mannequin alignment. The toolkit helps state-of-the-art mannequin alignment algorithms corresponding to SteerLM, DPO, reinforcement studying from human suggestions (RLHF), and way more. Through the use of these algorithms, you may align language fashions to be safer, extra innocent, and extra useful.
Answer overview
On this publish, we present you find out how to effectively practice large-scale generative AI fashions with NVIDIA NeMo Framework 2.0 utilizing SageMaker HyperPod, a managed distributed coaching service designed for high-performance workloads. This resolution integrates NeMo Framework 2.0 with the scalable infrastructure of SageMaker HyperPod, creating seamless orchestration of multi-node, multi-GPU clusters.
The important thing steps to deploying this resolution embrace:
- Organising SageMaker HyperPod conditions: Configuring networking, storage, and permissions administration (AWS Identification and Entry Administration (IAM) roles).
- Launching the SageMaker HyperPod cluster: Utilizing lifecycle scripts and a predefined cluster configuration to deploy compute assets.
- Configuring the atmosphere: Organising NeMo Framework and putting in the required dependencies.
- Constructing a customized container: Making a Docker picture that packages NeMo Framework and installs the required AWS networking dependencies.
- Working NeMo mannequin coaching: Utilizing NeMo-Run with a Slurm-based execution setup to coach an instance LLaMA (180M) mannequin effectively.
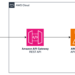
Structure diagram

The structure, proven within the previous diagram exhibits an Amazon SageMaker HyperPod Cluster.
Stipulations
First, you deploy a SageMaker HyperPod cluster earlier than working the job. However to deploy the cluster, you have to create some prerequisite assets.
Be aware that there’s a price related to working a SageMaker HyperPod cluster, see the Amazon SageMaker AI Pricing (HyperPod pricing in On-demand pricing) for extra info.
The next prerequisite steps are tailored from the Amazon SageMaker HyperPod workshop, which you’ll be able to go to for added info.
Use the next steps to deploy the prerequisite assets.
- Sign up to the AWS Administration Console utilizing the AWS account you wish to deploy the SageMaker HyperPod cluster in. You’ll create a VPC, subnets, an FSx Lustre quantity, an Amazon Easy Storage Service (Amazon S3) bucket, and IAM function as pre-requisites; so ensure that your IAM function or person for console entry has permissions to create these assets.
- Use the CloudFormation template to go to your AWS CloudFormation console and launch the answer template.
- Template parameters:
- Change the Availability Zone to match the AWS Area the place you’re deploying the template. See Availability Zone IDs for the AZ ID on your Area.
- All different parameters could be left as default or modified as wanted on your use case.
- Choose the acknowledgement field within the Capabilities part and create the stack.
It takes about 10 minutes for the CloudFormation stack creation to finish. The next determine exhibits the deployment timeline of the CloudFormation stack deployment for the prerequisite infrastructure parts.

Launch the coaching job
With the prerequisite infrastructure deployed in your AWS account, you subsequent deploy the SageMaker HyperPod cluster that you just’ll use for the mannequin coaching instance. For the mannequin coaching job, you’ll use the NeMo Framework to launch coaching jobs effectively.
Step 1: Arrange a SageMaker HyperPod cluster
After the prerequisite assets are efficiently deployed, create a SageMaker HyperPod cluster.
The deployment steps are tailored from the SageMaker HyperPod workshop, which you’ll be able to overview for added info.
- Set up and configure the AWS Command Line Interface (AWS CLI). If you have already got it put in, confirm that the model is at the least 2.17.1 by working the next command:
- Configure the atmosphere variables that utilizing outputs from the CloudFormation stack deployed earlier.
- Obtain the lifecycle scripts and add them to the S3 bucket created within the conditions. SageMaker HyperPod makes use of lifecycle scripts to bootstrap a cluster. Examples of actions the lifecycle script manages embrace establishing Slurm and mounting the FSx Lustre filesystem.
- Create a cluster config file for establishing the cluster. The next is an instance of making a cluster config from a template. The instance cluster config is for g5.48xlarge compute nodes accelerated by 8 x NVIDIA A10G GPUs. See Create Cluster for cluster config examples of extra Amazon Elastic Compute Cloud (Amazon EC2) occasion sorts. A cluster config file comprises the next info:
- Cluster identify
- It defines three occasion teams
- Login-group: Acts because the entry level for customers and directors. Usually used for managing jobs, monitoring and debugging.
- Controller-machine: That is the pinnacle node for the Hyperpod Slurm cluster. It manages the general orchestration of the distributed coaching course of and handles job scheduling and communication inside nodes.
- Employee-group: The group of nodes that executes the precise mannequin coaching workload
- VPC configuration
- Create a config file based mostly on the next instance with the cluster provisioning parameters and add it to the S3 bucket.
- Create the SageMaker HyperPod cluster
- Use the next code or the console to test the standing of the cluster. The standing needs to be Creating. Watch for the cluster standing to be InService continuing
The next screenshot exhibits the outcomes of the –output desk command displaying the cluster standing as Creating.

The next screenshot exhibits the Cluster Administration web page and standing of the cluster within the Amazon SageMaker AI console.

The next screenshot exhibits the outcomes of the –output desk command displaying the cluster standing as InService.

Step 2: SSH into the cluster
After the cluster is prepared (that’s, has a standing of InService), you may connect with it utilizing the AWS Techniques Supervisor Session Supervisor and an SSH helper script. See SSH into Cluster for extra info
- Set up the AWS SSM Session Supervisor Plugin.
- Create a neighborhood key pair that may be added to the cluster by the helper script for simpler SSH entry and run the next SSH helper script.
Step 3: Work together with the cluster and clone the repository
After connecting to the cluster, you may validate that the command is correctly configured by working a number of instructions. See Get to know your Cluster for extra info.
- View the present partition and nodes per partition
- Listing the roles which can be within the queue or working.
- SSH to the compute nodes.
- Clone the code pattern GitHub repository onto the cluster controller node (head node).
Now, you’re able to run your NeMo Framework Jobs on the SageMaker HyperPod cluster.
Step 4: Construct the job container
The subsequent step is to construct the job container. Through the use of a container, you may create a constant, transportable, and reproducible atmosphere, serving to to make sure that all dependencies, configurations, and optimizations stay intact. That is significantly necessary for high-performance computing (HPC) and AI workloads, the place variations within the software program stack can impression efficiency and compatibility.
To have a completely functioning and optimized atmosphere, you have to add AWS-specific networking dependencies (EFA, OFI plugin, replace NCCL, and NCCL checks) to the NeMo Framework container from NVIDIA GPU Cloud (NGC) Catalog. After constructing the Docker picture, you’ll use Enroot to create a squash file from it. A squash file is a compressed, read-only file system that encapsulates the container picture in a light-weight format. It helps cut back space for storing, accelerates loading occasions, and improves effectivity when deploying the container throughout a number of nodes in a cluster. By changing the Docker picture right into a squash file, you may obtain a extra optimized and performant execution atmosphere, particularly in distributed coaching eventualities.
Just remember to have a registered account with NVIDIA and might entry NGC. Retrieve the NGC API key following the directions from NVIDIA. Use the next command to configure NGC. When prompted, use $oauthtoken for the login username and the API key from NGC for the password.
You need to use the next command to construct the Docker file and create a SquashFS picture.
Step 5: Arrange NeMo-Run and different dependencies on the pinnacle node
Earlier than persevering with:
- NeMo-Run requires python3.10, confirm that that is put in on the pinnacle node earlier than continuing.
- You need to use the next steps to arrange Nemo-Run dependencies utilizing a digital atmosphere. The steps create and activate a digital atmosphere then execute the venv.sh script to put in the dependencies. Dependencies being put in embrace the NeMo toolkit, NeMo-Run, PyTorch, Megatron-LM, and others.
- To organize for the pre-training of the LLaMA mannequin in an offline mode and to assist guarantee constant tokenization, use the extensively adopted GPT-2 vocabulary and merges information. This strategy helps keep away from potential points associated to downloading tokenizer information throughout coaching:
Step 6: Launch the pretraining job utilizing NeMo-Run
Run the coaching script to begin the LLaMA pretraining job. The coaching script run.py defines the configuration for a LLaMA 180M parameter mannequin, defines a Slurm executor, defines the experiment, and launches the experiment.
The next operate defines the mannequin configuration.
The next operate defines the Slurm executor.
The next operate runs the experiment.




 Abdullahi Olaoye is a Senior AI Options Architect at NVIDIA, specializing in integrating NVIDIA AI libraries, frameworks, and merchandise with cloud AI providers and open-source instruments to optimize AI mannequin deployment, inference, and generative AI workflows. He collaborates with AWS to reinforce AI workload efficiency and drive adoption of NVIDIA-powered AI and generative AI options.
Abdullahi Olaoye is a Senior AI Options Architect at NVIDIA, specializing in integrating NVIDIA AI libraries, frameworks, and merchandise with cloud AI providers and open-source instruments to optimize AI mannequin deployment, inference, and generative AI workflows. He collaborates with AWS to reinforce AI workload efficiency and drive adoption of NVIDIA-powered AI and generative AI options. Greeshma Nallapareddy is a Sr. Enterprise Improvement Supervisor at AWS working with NVIDIA on go-to-market technique to speed up AI options for purchasers at scale. Her expertise contains main options structure groups targeted on working with startups.
Greeshma Nallapareddy is a Sr. Enterprise Improvement Supervisor at AWS working with NVIDIA on go-to-market technique to speed up AI options for purchasers at scale. Her expertise contains main options structure groups targeted on working with startups. Akshit Arora is a senior knowledge scientist at NVIDIA, the place he works on deploying conversational AI fashions on GPUs at scale. He’s a graduate of College of Colorado at Boulder, the place he utilized deep studying to enhance information monitoring on a Okay-12 on-line tutoring service. His work spans multilingual text-to-speech, time collection classification, ed-tech, and sensible purposes of deep studying.
Akshit Arora is a senior knowledge scientist at NVIDIA, the place he works on deploying conversational AI fashions on GPUs at scale. He’s a graduate of College of Colorado at Boulder, the place he utilized deep studying to enhance information monitoring on a Okay-12 on-line tutoring service. His work spans multilingual text-to-speech, time collection classification, ed-tech, and sensible purposes of deep studying. Ankur Srivastava is a Sr. Options Architect within the ML Frameworks Workforce. He focuses on serving to prospects with self-managed distributed coaching and inference at scale on AWS. His expertise contains industrial predictive upkeep, digital twins, probabilistic design optimization and has accomplished his doctoral research from Mechanical Engineering at Rice College and post-doctoral analysis from Massachusetts Institute of Expertise.
Ankur Srivastava is a Sr. Options Architect within the ML Frameworks Workforce. He focuses on serving to prospects with self-managed distributed coaching and inference at scale on AWS. His expertise contains industrial predictive upkeep, digital twins, probabilistic design optimization and has accomplished his doctoral research from Mechanical Engineering at Rice College and post-doctoral analysis from Massachusetts Institute of Expertise. Eliuth Triana Isaza is a Developer Relations Supervisor at NVIDIA empowering Amazon AI MLOps, DevOps, Scientists, and AWS technical specialists to grasp the NVIDIA computing stack for accelerating and optimizing generative AI basis fashions spanning from knowledge curation, GPU coaching, mannequin inference, and manufacturing deployment on AWS GPU situations. As well as, Eliuth is a passionate mountain biker, skier, tennis and poker participant.
Eliuth Triana Isaza is a Developer Relations Supervisor at NVIDIA empowering Amazon AI MLOps, DevOps, Scientists, and AWS technical specialists to grasp the NVIDIA computing stack for accelerating and optimizing generative AI basis fashions spanning from knowledge curation, GPU coaching, mannequin inference, and manufacturing deployment on AWS GPU situations. As well as, Eliuth is a passionate mountain biker, skier, tennis and poker participant.


{kind=link}