This put up was written with Dominic Catalano from Anyscale.
Organizations constructing and deploying large-scale AI fashions usually face essential infrastructure challenges that may instantly impression their backside line: unstable coaching clusters that fail mid-job, inefficient useful resource utilization driving up prices, and sophisticated distributed computing frameworks requiring specialised experience. These elements can result in unused GPU hours, delayed tasks, and pissed off information science groups. This put up demonstrates how one can deal with these challenges by offering a resilient, environment friendly infrastructure for distributed AI workloads.
Amazon SageMaker HyperPod is a purpose-built persistent generative AI infrastructure optimized for machine studying (ML) workloads. It gives sturdy infrastructure for large-scale ML workloads with high-performance {hardware}, so organizations can construct heterogeneous clusters utilizing tens to hundreds of GPU accelerators. With nodes optimally co-located on a single backbone, SageMaker HyperPod reduces networking overhead for distributed coaching. It maintains operational stability by way of steady monitoring of node well being, routinely swapping defective nodes with wholesome ones and resuming coaching from essentially the most just lately saved checkpoint, all of which will help save as much as 40% of coaching time. For superior ML customers, SageMaker HyperPod permits SSH entry to the nodes within the cluster, enabling deep infrastructure management, and permits entry to SageMaker tooling, together with Amazon SageMaker Studio, MLflow, and SageMaker distributed coaching libraries, together with help for numerous open-source coaching libraries and frameworks. SageMaker Versatile Coaching Plans complement this by enabling GPU capability reservation as much as 8 weeks upfront for durations as much as 6 months.
The Anyscale platform integrates seamlessly with SageMaker HyperPod when utilizing Amazon Elastic Kubernetes Service (Amazon EKS) because the cluster orchestrator. Ray is the main AI compute engine, providing Python-based distributed computing capabilities to deal with AI workloads starting from multimodal AI, information processing, mannequin coaching, and mannequin serving. Anyscale unlocks the facility of Ray with complete tooling for developer agility, essential fault tolerance, and an optimized model known as RayTurbo, designed to ship main cost-efficiency. By a unified management aircraft, organizations profit from simplified administration of complicated distributed AI use instances with fine-grained management throughout {hardware}.
The mixed resolution gives in depth monitoring by way of SageMaker HyperPod real-time dashboards monitoring node well being, GPU utilization, and community visitors. Integration with Amazon CloudWatch Container Insights, Amazon Managed Service for Prometheus, and Amazon Managed Grafana delivers deep visibility into cluster efficiency, complemented by Anyscale’s monitoring framework, which gives built-in metrics for monitoring Ray clusters and the workloads that run on them.
This put up demonstrates tips on how to combine the Anyscale platform with SageMaker HyperPod. This mix can ship tangible enterprise outcomes: diminished time-to-market for AI initiatives, decrease whole value of possession by way of optimized useful resource utilization, and elevated information science productiveness by minimizing infrastructure administration overhead. It’s superb for Amazon EKS and Kubernetes-focused organizations, groups with large-scale distributed coaching wants, and people invested within the Ray ecosystem or SageMaker.
Answer overview
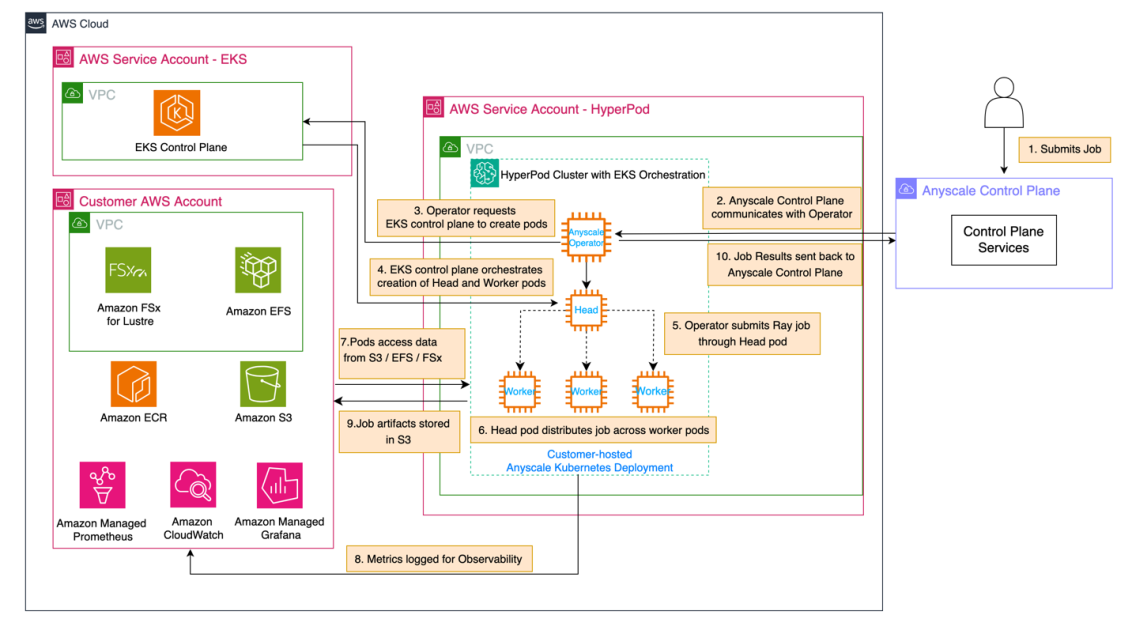
The next structure diagram illustrates SageMaker HyperPod with Amazon EKS orchestration and Anyscale.
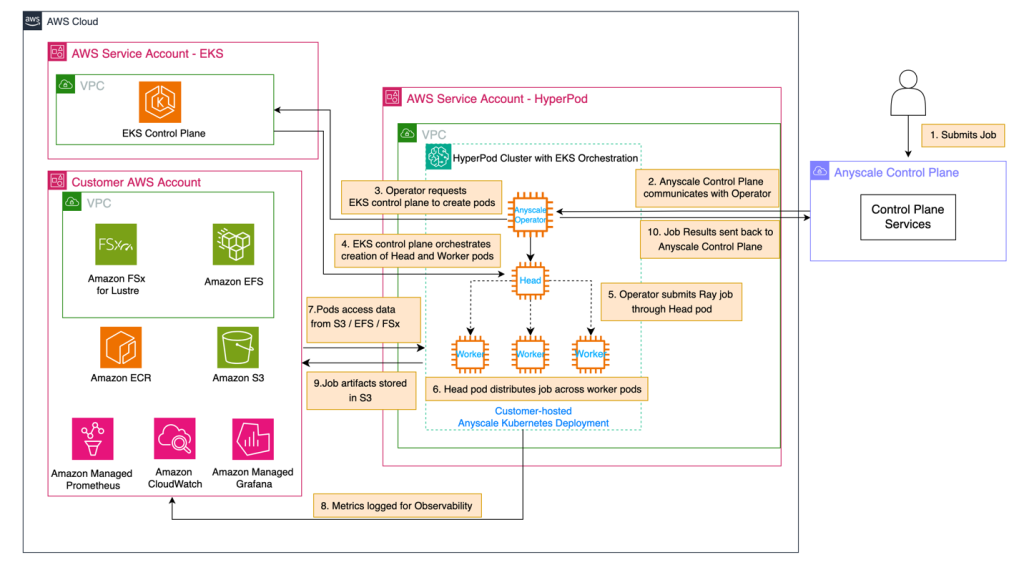
The sequence of occasions on this structure is as follows:
- A person submits a job to the Anyscale Management Aircraft, which is the principle user-facing endpoint.
- The Anyscale Management Aircraft communicates this job to the Anyscale Operator throughout the SageMaker HyperPod cluster within the SageMaker HyperPod digital personal cloud (VPC).
- The Anyscale Operator, upon receiving the job, initiates the method of making the mandatory pods by reaching out to the EKS management aircraft.
- The EKS management aircraft orchestrates creation of a Ray head pod and employee pods. These pods signify a Ray cluster, operating on SageMaker HyperPod with Amazon EKS.
- The Anyscale Operator submits the job by way of the pinnacle pod, which serves as the first coordinator for the distributed workload.
- The top pod distributes the workload throughout a number of employee pods, as proven within the hierarchical construction within the SageMaker HyperPod EKS cluster.
- Employee pods execute their assigned duties, probably accessing required information from the storage providers – akin to Amazon Easy Storage Service (Amazon S3), Amazon Elastic File System (Amazon EFS), or Amazon FSx for Lustre – within the person VPC.
- All through the job execution, metrics and logs are revealed to Amazon CloudWatch and Amazon Managed Service for Prometheus or Amazon Managed Grafana for observability.
- When the Ray job is full, the job artifacts (closing mannequin weights, inference outcomes, and so forth) are saved to the designated storage service.
- Job outcomes (standing, metrics, logs) are despatched by way of the Anyscale Operator again to the Anyscale Management Aircraft.
This circulation exhibits distribution and execution of user-submitted jobs throughout the obtainable computing sources, whereas sustaining monitoring and information accessibility all through the method.
Conditions
Earlier than you start, you have to have the next sources:
Arrange Anyscale Operator
Full the next steps to arrange the Anyscale Operator:
- In your workspace, obtain the aws-do-ray repository:
This repository has the instructions wanted to deploy the Anyscale Operator on a SageMaker HyperPod cluster. The aws-do-ray mission goals to simplify the deployment and scaling of distributed Python software utilizing Ray on Amazon EKS or SageMaker HyperPod. The
aws-do-raycontainer shell is provided with intuitive motion scripts and comes preconfigured with handy shortcuts, which save in depth typing and enhance productiveness. You may optionally use these options by constructing and opening a bash shell within the container with the directions within theaws-do-rayREADME, or you’ll be able to proceed with the next steps. - In the event you proceed with these steps, make sure that your setting is correctly arrange:
- Confirm your connection to the HyperPod cluster:
- Acquire the identify of the EKS cluster on the SageMaker HyperPod console. In your cluster particulars, you will notice your EKS cluster orchestrator.
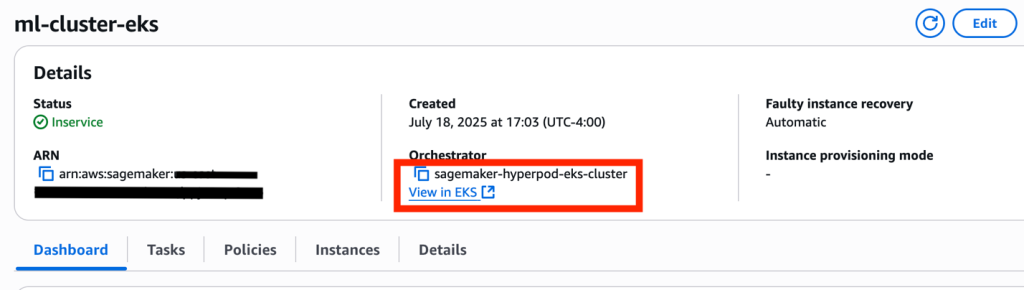
- Replace
kubeconfigto connect with the EKS cluster:The next screenshot exhibits an instance output.

If the output signifies InProgress as a substitute of Handed, look ahead to the deep well being checks to complete.

- Acquire the identify of the EKS cluster on the SageMaker HyperPod console. In your cluster particulars, you will notice your EKS cluster orchestrator.
- Evaluate the
env_varsfile. Replace the variableAWS_EKS_HYPERPOD_CLUSTER. You may depart the values as default or make desired modifications. - Deploy your necessities:
This creates the
anyscalenamespace, installs Anyscale dependencies, configures login to your Anyscale account (this step will immediate you for added verification as proven within the following screenshot), provides the anyscale helm chart, installs the ingress-nginx controller, and at last labels and taints SageMaker HyperPod nodes for the Anyscale employee pods.
- Create an EFS file system:
Amazon EFS serves because the shared cluster storage for the Anyscale pods.
On the time of writing, Amazon EFS and S3FS are the supported file system choices when utilizing Anyscale and SageMaker HyperPod setups with Ray on AWS. Though FSx for Lustre just isn’t supported with this setup, you should utilize it with KubeRay on SageMaker HyperPod EKS. - Register an Anyscale Cloud:
This registers a self-hosted Anyscale Cloud into your SageMaker HyperPod cluster. By default, it makes use of the worth of ANYSCALE_CLOUD_NAME within the
env_varsfile. You may modify this discipline as wanted. At this level, it is possible for you to to see your registered cloud on the Anyscale console. - Deploy the Kubernetes Anyscale Operator:
This command installs the Anyscale Operator within the
anyscalenamespace. The Operator will begin posting well being checks to the Anyscale Management Aircraft.To see the Anyscale Operator pod, run the next command:
kubectl get pods -n anyscale
Submit coaching job
This part walks by way of a easy coaching job submission. The instance implements distributed coaching of a neural community for Vogue MNIST classification utilizing the Ray Prepare framework on SageMaker HyperPod with Amazon EKS orchestration, demonstrating tips on how to use the AWS managed ML infrastructure mixed with Ray’s distributed computing capabilities for scalable mannequin coaching.Full the next steps:
- Navigate to the
jobslisting. This incorporates folders for obtainable instance jobs you’ll be able to run. For this walkthrough, go to thedt-pytorchlisting containing the coaching job. - Configure the required setting variables:
- Create Anyscale compute configuration:
./1.create-compute-config.sh - Submit the coaching job:
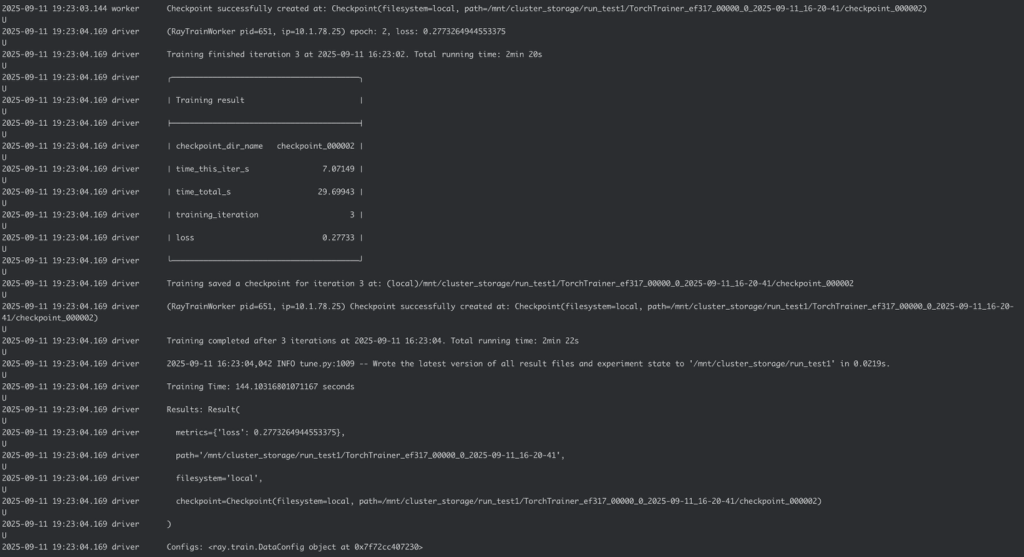
./2.submit-dt-pytorch.shThis makes use of the job configuration laid out in job_config.yaml. For extra info on the job config, discuss with JobConfig. - Monitor the deployment. You will notice the newly created head and employee pods within the
anyscalenamespace.kubectl get pods -n anyscale - View the job standing and logs on the Anyscale console to observe your submitted job’s progress and output.
Clear up
To scrub up your Anyscale cloud, run the next command:
To delete your SageMaker HyperPod cluster and related sources, delete the CloudFormation stack if that is the way you created the cluster and its sources.
Conclusion
This put up demonstrated tips on how to arrange and deploy the Anyscale Operator on SageMaker HyperPod utilizing Amazon EKS for orchestration.SageMaker HyperPod and Anyscale RayTurbo present a extremely environment friendly, resilient resolution for large-scale distributed AI workloads: SageMaker HyperPod delivers sturdy, automated infrastructure administration and fault restoration for GPU clusters, and RayTurbo accelerates distributed computing and optimizes useful resource utilization with no code modifications required. By combining the high-throughput, fault-tolerant setting of SageMaker HyperPod with RayTurbo’s sooner information processing and smarter scheduling, organizations can practice and serve fashions at scale with improved reliability and vital value financial savings, making this stack superb for demanding duties like massive language mannequin pre-training and batch inference.
For extra examples of utilizing SageMaker HyperPod, discuss with the Amazon EKS Assist in Amazon SageMaker HyperPod workshop and the Amazon SageMaker HyperPod Developer Information. For info on how clients are utilizing RayTurbo, discuss with RayTurbo.
In regards to the authors
 Sindhura Palakodety is a Senior Options Architect at AWS and Single-Threaded Chief (STL) for ISV Generative AI, the place she is devoted to empowering clients in creating enterprise-scale, Nicely-Architected options. She makes a speciality of generative AI and information analytics domains, serving to organizations use revolutionary applied sciences for transformative enterprise outcomes.
Sindhura Palakodety is a Senior Options Architect at AWS and Single-Threaded Chief (STL) for ISV Generative AI, the place she is devoted to empowering clients in creating enterprise-scale, Nicely-Architected options. She makes a speciality of generative AI and information analytics domains, serving to organizations use revolutionary applied sciences for transformative enterprise outcomes.
 Mark Vinciguerra is an Affiliate Specialist Options Architect at AWS based mostly in New York. He focuses on generative AI coaching and inference, with the purpose of serving to clients architect, optimize, and scale their workloads throughout numerous AWS providers. Previous to AWS, he went to Boston College and graduated with a level in Pc Engineering.
Mark Vinciguerra is an Affiliate Specialist Options Architect at AWS based mostly in New York. He focuses on generative AI coaching and inference, with the purpose of serving to clients architect, optimize, and scale their workloads throughout numerous AWS providers. Previous to AWS, he went to Boston College and graduated with a level in Pc Engineering.
 Florian Gauter is a Worldwide Specialist Options Architect at AWS, based mostly in Hamburg, Germany. He makes a speciality of AI/ML and generative AI options, serving to clients optimize and scale their AI/ML workloads on AWS. With a background as a Information Scientist, Florian brings deep technical experience to assist organizations design and implement subtle ML options. He works intently with clients worldwide to rework their AI initiatives and maximize the worth of their ML investments on AWS.
Florian Gauter is a Worldwide Specialist Options Architect at AWS, based mostly in Hamburg, Germany. He makes a speciality of AI/ML and generative AI options, serving to clients optimize and scale their AI/ML workloads on AWS. With a background as a Information Scientist, Florian brings deep technical experience to assist organizations design and implement subtle ML options. He works intently with clients worldwide to rework their AI initiatives and maximize the worth of their ML investments on AWS.
 Alex Iankoulski is a Principal Options Architect within the Worldwide Specialist Group at AWS. He focuses on orchestration of AI/ML workloads utilizing containers. Alex is the writer of the do-framework and a Docker captain who loves making use of container applied sciences to speed up the tempo of innovation whereas fixing the world’s largest challenges. Over the previous 10 years, Alex has labored on serving to clients do extra on AWS, democratizing AI and ML, combating local weather change, and making journey safer, healthcare higher, and vitality smarter.
Alex Iankoulski is a Principal Options Architect within the Worldwide Specialist Group at AWS. He focuses on orchestration of AI/ML workloads utilizing containers. Alex is the writer of the do-framework and a Docker captain who loves making use of container applied sciences to speed up the tempo of innovation whereas fixing the world’s largest challenges. Over the previous 10 years, Alex has labored on serving to clients do extra on AWS, democratizing AI and ML, combating local weather change, and making journey safer, healthcare higher, and vitality smarter.
 Anoop Saha is a Senior GTM Specialist at AWS specializing in generative AI mannequin coaching and inference. He’s partnering with high basis mannequin builders, strategic clients, and AWS service groups to allow distributed coaching and inference at scale on AWS and lead joint GTM motions. Earlier than AWS, Anoop has held a number of management roles at startups and enormous firms, primarily specializing in silicon and system structure of AI infrastructure.
Anoop Saha is a Senior GTM Specialist at AWS specializing in generative AI mannequin coaching and inference. He’s partnering with high basis mannequin builders, strategic clients, and AWS service groups to allow distributed coaching and inference at scale on AWS and lead joint GTM motions. Earlier than AWS, Anoop has held a number of management roles at startups and enormous firms, primarily specializing in silicon and system structure of AI infrastructure.
 Dominic Catalano is a Group Product Supervisor at Anyscale, the place he leads product growth throughout AI/ML infrastructure, developer productiveness, and enterprise safety. His work focuses on distributed methods, Kubernetes, and serving to groups run AI workloads at scale.
Dominic Catalano is a Group Product Supervisor at Anyscale, the place he leads product growth throughout AI/ML infrastructure, developer productiveness, and enterprise safety. His work focuses on distributed methods, Kubernetes, and serving to groups run AI workloads at scale.



{kind=link}