
In the present day, we’re excited to announce the launch of Amazon SageMaker Giant Mannequin Inference (LMI) container v15, powered by vLLM 0.8.4 with assist for the vLLM V1 engine. This model now helps the most recent open-source fashions, reminiscent of Meta’s Llama 4 fashions Scout and Maverick, Google’s Gemma 3, Alibaba’s Qwen, Mistral AI, DeepSeek-R, and plenty of extra. Amazon SageMaker AI continues to evolve its generative AI inference capabilities to fulfill the rising calls for in efficiency and mannequin assist for basis fashions (FMs).
This launch introduces vital efficiency enhancements, expanded mannequin compatibility with multimodality (that’s, the power to grasp and analyze text-to-text, images-to-text, and text-to-images knowledge), and offers built-in integration with vLLM that can assist you seamlessly deploy and serve giant language fashions (LLMs) with the very best efficiency at scale.
What’s new?
LMI v15 brings a number of enhancements that enhance throughput, latency, and value:
- An async mode that straight integrates with vLLM’s AsyncLLMEngine for improved request dealing with. This mode creates a extra environment friendly background loop that constantly processes incoming requests, enabling it to deal with a number of concurrent requests and stream outputs with larger throughput than the earlier Rolling-Batch implementation in v14.
- Help for the vLLM V1 engine, which delivers as much as 111% larger throughput in comparison with the earlier V0 engine for smaller fashions at excessive concurrency. This efficiency enchancment comes from diminished CPU overhead, optimized execution paths, and extra environment friendly useful resource utilization within the V1 structure. LMI v15 helps each V1 and V0 engines, with V1 being the default. When you’ve got a necessity to make use of V0, you need to use the V0 engine by specifying
VLLM_USE_V1=0. vLLM V1’s engine additionally comes with a core re-architecture of the serving engine with simplified scheduling, zero-overhead prefix caching, clear tensor-parallel inference, environment friendly enter preparation, and superior optimizations with torch.compile and Flash Consideration 3. For extra info, see the vLLM Weblog. - Expanded API schema assist with three versatile choices to permit seamless integration with purposes constructed on well-liked API patterns:
- Message format appropriate with the OpenAI Chat Completions API.
- OpenAI Completions format.
- Textual content Era Inference (TGI) schema to assist backward compatibility with older fashions.
- Multimodal assist, with enhanced capabilities for vision-language fashions together with optimizations reminiscent of multimodal prefix caching
- Constructed-in assist for operate calling and gear calling, enabling subtle agent-based workflows.
Enhanced mannequin assist
LMI v15 helps an increasing roster of state-of-the-art fashions, together with the most recent releases from main mannequin suppliers. The container presents ready-to-deploy compatibility for however not restricted to:
- Llama 4 – Llama-4-Scout-17B-16E and Llama-4-Maverick-17B-128E-Instruct
- Gemma 3 – Google’s light-weight and environment friendly fashions, identified for his or her robust efficiency regardless of smaller dimension
- Qwen 2.5 – Alibaba’s superior fashions together with QwQ 2.5 and Qwen2-VL with multimodal capabilities
- Mistral AI fashions – Excessive-performance fashions from Mistral AI that provide environment friendly scaling and specialised capabilities
- DeepSeek-R1/V3 – State-of-the-art reasoning fashions
Every mannequin household may be deployed utilizing the LMI v15 container by specifying the suitable mannequin ID, for instance, meta-llama/Llama-4-Scout-17B-16E, and configuration parameters as setting variables, with out requiring customized code or optimization work.
Benchmarks
Our benchmarks exhibit the efficiency benefits of LMI v15’s V1 engine in comparison with earlier variations:
| Mannequin | Batch dimension | Occasion sort | LMI v14 throughput [tokens/s] (V0 engine) | LMI v15 throughput [tokens/s] (V1 engine) | Enchancment | |
| 1 | deepseek-ai/DeepSeek-R1-Distill-Llama-70B | 128 | p4d.24xlarge | 1768 | 2198 | 24% |
| 2 | meta-llama/Llama-3.1-8B-Instruct | 64 | ml.g6e.2xlarge | 1548 | 2128 | 37% |
| 3 | mistralai/Mistral-7B-Instruct-v0.3 | 64 | ml.g6e.2xlarge | 942 | 1988 | 111% |
DeepSeek-R1 Llama 70B for numerous ranges of concurrency

Llama 3.1 8B Instruct for numerous degree of concurrency
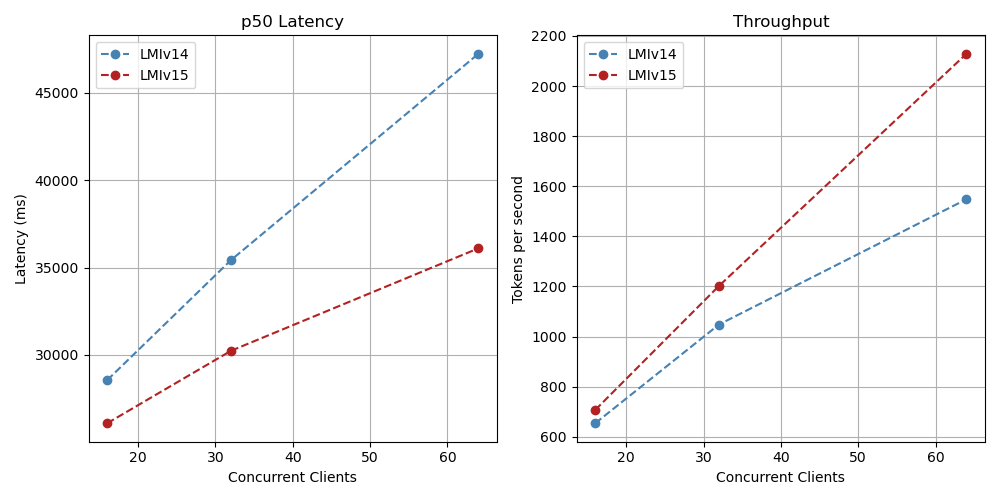
Mistral 7B for numerous ranges of concurrency

The async engine in LMI v15 reveals energy in high-concurrency eventualities, the place a number of simultaneous requests profit from the optimized request dealing with. These benchmarks spotlight that the V1 engine in async mode delivers between 24% and 111% larger throughput in comparison with LMI v14 utilizing rolling batch within the fashions examined in excessive concurrency eventualities for batch dimension of 64 and 128. We propose to bear in mind the next concerns for optimum efficiency:
- Increased batch sizes enhance concurrency however include a pure tradeoff by way of latency
- Batch sizes of 4 and eight present the most effective latency for many use instances
- Batch sizes as much as 64 and 128 obtain most throughput with acceptable latency trade-offs
API codecs
LMI v15 helps three API schemas: OpenAI Chat Completions, OpenAI Completions, and TGI.
- Chat Completions – Message format is appropriate with OpenAI Chat Completions API. Use this schema for device calling, reasoning, and multimodal use instances. Here’s a pattern of the invocation with the Messages API:
- OpenAI Completions format – The Completions API endpoint is now not receiving updates:
- TGI – Helps backward compatibility with older fashions:
Getting began with LMI v15
Getting began with LMI v15 is seamless, and you may deploy with LMI v15 in just a few strains of code. The container is accessible by way of Amazon Elastic Container Registry (Amazon ECR), and deployments may be managed by way of SageMaker AI endpoints. To deploy fashions, that you must specify the Hugging Face mannequin ID, occasion sort, and configuration choices as setting variables.
For optimum efficiency, we advocate the next situations:
- Llama 4 Scout: ml.p5.48xlarge
- DeepSeek R1/V3: ml.p5e.48xlarge
- Qwen 2.5 VL-32B: ml.g5.12xlarge
- Qwen QwQ 32B: ml.g5.12xlarge
- Mistral Giant: ml.g6e.48xlarge
- Gemma3-27B: ml.g5.12xlarge
- Llama 3.3-70B: ml.p4d.24xlarge
To deploy with LMI v15, comply with these steps:
- Clone the pocket book to your Amazon SageMaker Studio pocket book or to Visible Studio Code (VS Code). You’ll be able to then run the pocket book to do the preliminary setup and deploy the mannequin from the Hugging Face repository to the SageMaker AI endpoint. We stroll by way of the important thing blocks right here.
- LMI v15 maintains the identical configuration sample as earlier variations, utilizing setting variables within the type
OPTION_. This constant method makes it simple for customers acquainted with earlier LMI variations emigrate to v15.HF_MODEL_IDunits the mannequin id from Hugging Face. It’s also possible to obtain mannequin from Amazon Easy Storage Service (Amazon S3).HF_TOKENunits the token to obtain the mannequin. That is required for gated fashions like Llama-4OPTION_MAX_MODEL_LEN. That is the max mannequin context size.OPTION_MAX_ROLLING_BATCH_SIZEunits the batch dimension for the mannequin.OPTION_MODEL_LOADING_TIMEOUTunits the timeout worth for SageMaker to load the mannequin and run well being checks.SERVING_FAIL_FAST=true. We advocate setting this flag as a result of it permits SageMaker to gracefully restart the container when an unrecoverable engine error happens.OPTION_ROLLING_BATCH= disabledisables the rolling batch implementation of LMI, which was the default providing in LMI V14. We advocate utilizing async as a substitute as this newest implementation and offers higher efficiencyOPTION_ASYNC_MODE=truepermits async mode.OPTION_ENTRYPOINToffers the entrypoint for vLLM’s async integrations
- Set the most recent container (on this instance we used
0.33.0-lmi15.0.0-cu128), AWS Area (us-east-1), and create a mannequin artifact with all of the configurations. To assessment the most recent out there container model, see Obtainable Deep Studying Containers Photos. - Deploy the mannequin to the endpoint utilizing
mannequin.deploy(). - Invoke the mannequin, SageMaker inference offers two APIs to invoke the model-
InvokeEndpointandInvokeEndpointWithResponseStream. You’ll be able to select both possibility based mostly in your wants.
To run multi-modal inference with Llama-4 Scout, see the pocket book for the complete code pattern to run inference requests with photos.
Conclusion
Amazon SageMaker LMI container v15 represents a big step ahead in giant mannequin inference capabilities. With the brand new vLLM V1 engine, async working mode, expanded mannequin assist, and optimized efficiency, you’ll be able to deploy cutting-edge LLMs with better efficiency and suppleness. The container’s configurable choices provide the flexibility to fine-tune deployments in your particular wants, whether or not optimizing for latency, throughput, or value.
We encourage you to discover this launch for deploying your generative AI fashions.
Take a look at the offered instance notebooks to begin deploying fashions with LMI v15.
In regards to the authors
 Vivek Gangasani is a Lead Specialist Options Architect for Inference at AWS. He helps rising generative AI firms construct modern options utilizing AWS companies and accelerated compute. Presently, he’s targeted on creating methods for fine-tuning and optimizing the inference efficiency of enormous language fashions. In his free time, Vivek enjoys mountaineering, watching motion pictures, and attempting completely different cuisines.
Vivek Gangasani is a Lead Specialist Options Architect for Inference at AWS. He helps rising generative AI firms construct modern options utilizing AWS companies and accelerated compute. Presently, he’s targeted on creating methods for fine-tuning and optimizing the inference efficiency of enormous language fashions. In his free time, Vivek enjoys mountaineering, watching motion pictures, and attempting completely different cuisines.
 Siddharth Venkatesan is a Software program Engineer in AWS Deep Studying. He presently focusses on constructing options for giant mannequin inference. Previous to AWS he labored within the Amazon Grocery org constructing new cost options for purchasers world-wide. Outdoors of labor, he enjoys snowboarding, the outside, and watching sports activities.
Siddharth Venkatesan is a Software program Engineer in AWS Deep Studying. He presently focusses on constructing options for giant mannequin inference. Previous to AWS he labored within the Amazon Grocery org constructing new cost options for purchasers world-wide. Outdoors of labor, he enjoys snowboarding, the outside, and watching sports activities.
 Felipe Lopez is a Senior AI/ML Specialist Options Architect at AWS. Previous to becoming a member of AWS, Felipe labored with GE Digital and SLB, the place he targeted on modeling and optimization merchandise for industrial purposes.
Felipe Lopez is a Senior AI/ML Specialist Options Architect at AWS. Previous to becoming a member of AWS, Felipe labored with GE Digital and SLB, the place he targeted on modeling and optimization merchandise for industrial purposes.
 Banu Nagasundaram leads product, engineering, and strategic partnerships for Amazon SageMaker JumpStart, the SageMaker machine studying and generative AI hub. She is keen about constructing options that assist clients speed up their AI journey and unlock enterprise worth.
Banu Nagasundaram leads product, engineering, and strategic partnerships for Amazon SageMaker JumpStart, the SageMaker machine studying and generative AI hub. She is keen about constructing options that assist clients speed up their AI journey and unlock enterprise worth.
 Dmitry Soldatkin is a Senior AI/ML Options Architect at Amazon Internet Companies (AWS), serving to clients design and construct AI/ML options. Dmitry’s work covers a variety of ML use instances, with a major curiosity in Generative AI, deep studying, and scaling ML throughout the enterprise. He has helped firms in lots of industries, together with insurance coverage, monetary companies, utilities, and telecommunications. You’ll be able to join with Dmitry on LinkedIn.
Dmitry Soldatkin is a Senior AI/ML Options Architect at Amazon Internet Companies (AWS), serving to clients design and construct AI/ML options. Dmitry’s work covers a variety of ML use instances, with a major curiosity in Generative AI, deep studying, and scaling ML throughout the enterprise. He has helped firms in lots of industries, together with insurance coverage, monetary companies, utilities, and telecommunications. You’ll be able to join with Dmitry on LinkedIn.



{kind=link}