
Generative AI is quickly reshaping the music trade, empowering creators—no matter ability—to create studio-quality tracks with basis fashions (FMs) that personalize compositions in actual time. As demand for distinctive, immediately generated content material grows and creators search smarter, sooner instruments, Splash Music collaborated with AWS to develop and scale music era FMs, making skilled music creation accessible to tens of millions.
On this submit, we present how Splash Music is setting a brand new normal for AI-powered music creation through the use of its superior HummingLM mannequin with AWS Trainium on Amazon SageMaker HyperPod. As a particular startup within the 2024 AWS Generative AI Accelerator, Splash Music collaborated carefully with AWS Startups and the AWS Generative AI Innovation Middle (GenAIIC) to fast-track innovation and speed up their music era FM growth lifecycle.
Problem: Scaling music era
Splash Music has empowered a brand new era of creators to make music, and has already pushed over 600 million streams worldwide. By giving customers instruments that adapt to their evolving tastes and types, the service makes music manufacturing accessible, enjoyable, and related to how followers truly wish to create. Nevertheless, constructing the know-how to unlock this inventive freedom, particularly the fashions that energy it, meant overcoming a number of key challenges:
- Mannequin complexity and scale – Splash Music developed HummingLM—a cutting-edge, multi-billion-parameter mannequin tailor-made for generative music to ship its mission of constructing music creation really accessible. HummingLM is engineered to seize the subtlety of human buzzing, changing inventive concepts into music tracks. Assembly these excessive requirements of constancy meant Splash needed to scale up computing energy and storage considerably, so the mannequin might ship studio-quality music.
- Fast tempo of change – The tempo of trade and technological change, pushed by fast AI development, means Splash Music should frequently adapt, practice, fine-tune, and deploy new fashions to fulfill consumer expectations for recent, related options.
- Infrastructure scaling – Managing and scaling giant clusters within the generative AI mannequin growth lifecycle introduced unpredictable prices, frequent interruptions, and time-consuming guide administration. Previous to AWS, Splash Music relied on externally managed GPU clusters, which concerned unpredictable latency, further troubleshooting, and administration complexity that hindered their capability to experiment and scale as rapidly as wanted.
The service wanted a scalable, automated, and cost-effective infrastructure.
Overview of HummingLM: Splash Music’s basis mannequin
HummingLM is Splash Music’s proprietary, multi-modal generative mannequin, developed in shut collaboration with the GenAIIC. It represents an enchancment in how AI can interpret and generate music. The mannequin’s structure is constructed round a transformer-based giant language mannequin (LLM) coupled with a specialised music encoder upsampler:
- HummingLM makes use of Descript-Audio-Codec (DAC) audio encoding to acquire compressed audio representations that seize each frequency and timbre traits
- The system transforms hummed melodies into skilled instrumental performances with out express timbre illustration studying
The innovation lies in how HummingLM fuses these token streams. Utilizing a transformer-based spine, the mannequin learns to mix the melodic intent from buzzing with the stylistic and structural cues from instrument sound (for instance, to make the buzzing sound like a guitar, piano, flute, or totally different synthesized sound). Customers can hum a tune, add an instrument management sign, and obtain a completely organized, high-fidelity monitor in return. HummingLM’s structure is designed for each effectivity and expressiveness. By utilizing discrete token representations, the mannequin achieves sooner convergence and diminished computational overhead in comparison with conventional waveform-based approaches. This makes it potential to coach on numerous, large-scale datasets and adapt rapidly to new genres or consumer preferences.
The next diagram illustrates how HummingLM is educated and the inference course of to generate high-quality music:
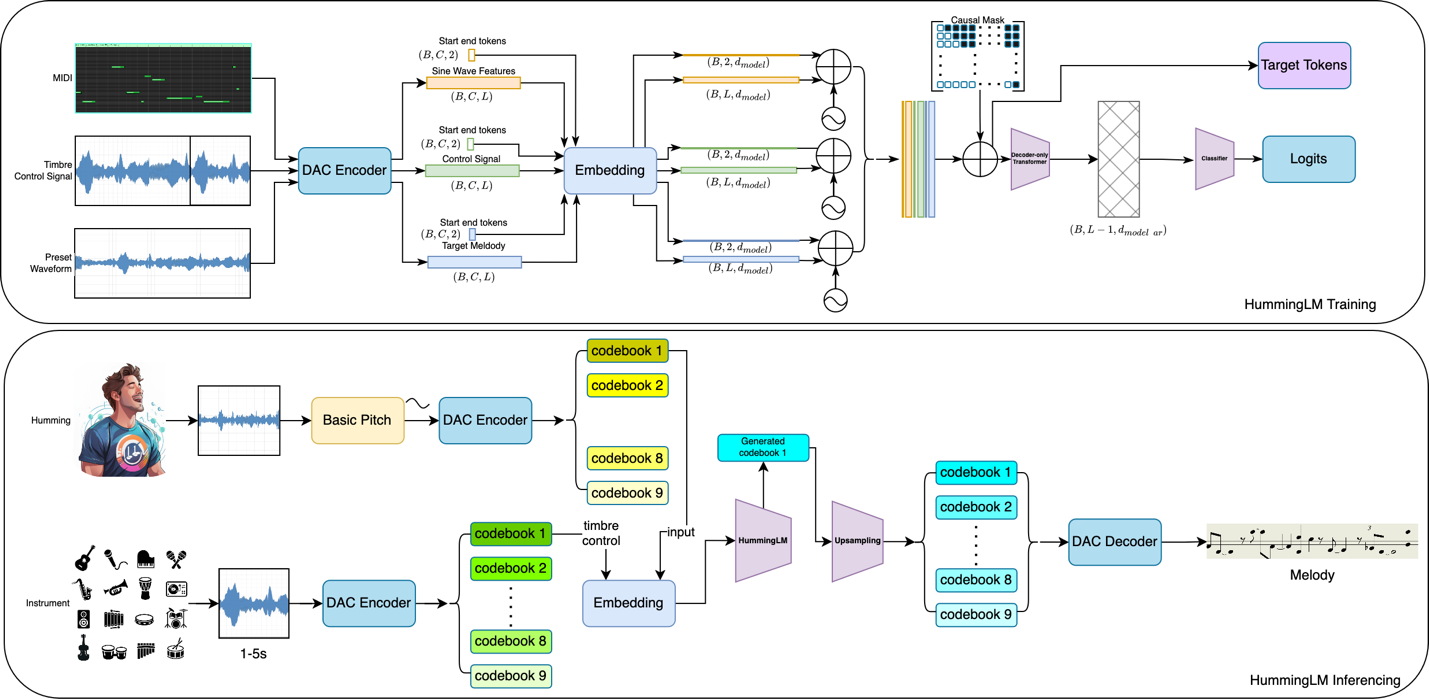
Resolution overview: Accelerating mannequin growth with AWS Trainium on Amazon SageMaker HyperPod
Splash Music collaborated with the GenAIIC to advance its HummingLM basis mannequin, utilizing the mixed capabilities of Amazon SageMaker HyperPod and AWS Trainium chips for mannequin coaching.
Splash Music’s structure follows SageMaker HyperPod best-practices utilizing Amazon Elastic Kubernetes Service (EKS) because the orchestrator, FSx for Lustre for storage to retailer over 2 PB of knowledge, and AWS Trainium EC2 cases for acceleration. The next diagram illustrates the answer structure.
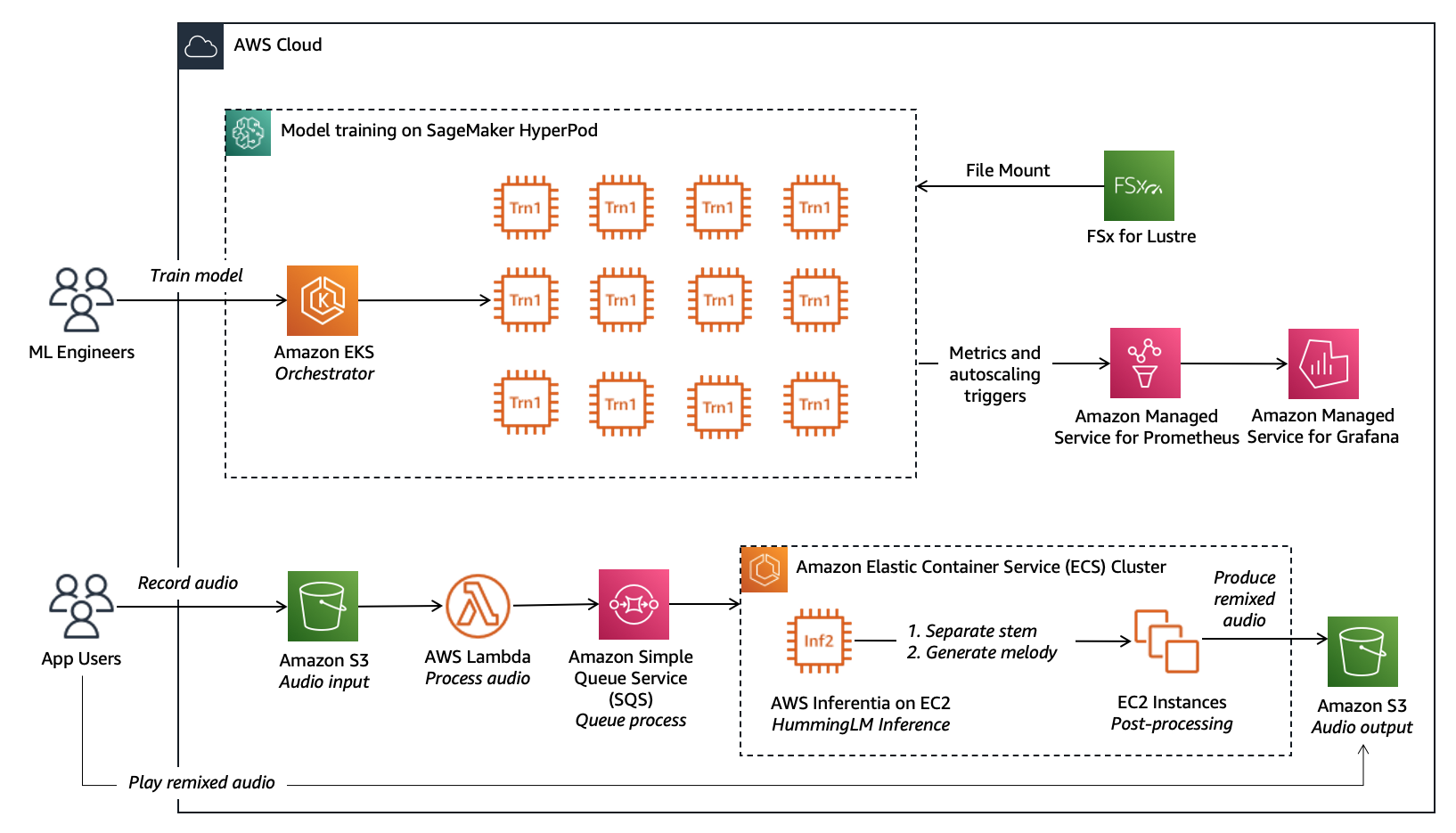
Within the following sections, we stroll by means of every step of the mannequin growth lifecycle, from dataset preparation to compilation for optimized inference.
Dataset preparation
Environment friendly preparation and processing of large-scale audio datasets is crucial for growing controllable music era fashions:
- Function extraction pipeline – Splash Music constructed a characteristic extraction pipeline for environment friendly, scalable processing of huge volumes of audio information, producing high-quality options for mannequin coaching. It begins by retrieving audio in batches from a centralized database, minimizing I/O overhead and supporting large-scale operations.
- Audio processing – Every audio file is resampled from 44,100 Hz to 22,050 Hz to standardize inputs and cut back computational load. A mono reference sign can be created by averaging the stereo channels from a reference audio file, serving as a constant benchmark for evaluation. In parallel, a Fundamental Pitch Extractor generates an artificial, MIDI-like model of the audio, offering a symbolic illustration of pitch and rhythm that enhances the richness of extracted options.
- Descript Audio Codec (DAC) extractor – The pipeline processes three audio streams: the stereo channels from the unique audio, the mono reference, and the artificial MIDI sign. This multi-stream strategy captures numerous elements of the audio sign, producing a strong set of options. Extracted information is organized into two important units: audio-feature, which incorporates options from the unique stereo channels, and sine-audio-feature, which accommodates options from the MIDI and mono reference audio. This construction streamlines downstream mannequin coaching.
- Parallel processing: To maximise efficiency, the pipeline makes use of parallel processing for concurrent characteristic extraction and information importing. This considerably boosts effectivity, ensuring the system handles giant datasets with velocity and consistency.
As well as, the answer makes use of a sophisticated stem separation system that isolates songs into six distinct audio stems: drums, bass, vocals, lead, chordal, and different devices:
- Stem Preparation: Splash Music creates high-quality coaching information by getting ready separate stems for every musical component. Lead and chordal stems are generated utilizing a synthesizer device and a various dataset of music tracks. This wealthy dataset covers a number of genres and types. This supplies a powerful basis for the mannequin to be taught exact element separation.
By streamlining information dealing with from the outset, we make it possible for the following mannequin coaching phases have entry to scrub, well-structured options.
Mannequin structure and optimization
HummingLM employs a dual-component structure:
- LLM for coarse token era – A 385 M parameter transformer-based language mannequin (24 layers, 1024 embedding dimension, 16 consideration heads) that generates foundational musical construction
- Upsampling element – A specialised element that expands the coarse illustration into full, high-fidelity audio.
This division of labor is essential to HummingLM’s effectiveness: the LLM captures high-level musical intent, and the upsampling element handles acoustic particulars. Along with the GenAIIC, Splash collaborated on analysis to optimize the HummingLM mannequin to facilitate optimum efficiency:
- Versatile management sign design – The mannequin accepts management alerts of various durations (1-5 seconds), a major enchancment over fixed-window approaches.
- Zero-shot functionality – Not like techniques requiring express timbre embedding studying, HummingLM can generalize to unseen instrument presets with out further coaching.
- Non-autoregressive era – The upsampling element makes use of parallel token prediction for considerably sooner inference in comparison with conventional autoregressive approaches.
Our analysis demonstrated HummingLM’s superior first codebook prediction capabilities – a crucial think about residual quantization techniques the place the primary codebook accommodates most acoustic data. The mannequin persistently outperformed baseline approaches like VALL-E throughout a number of high quality metrics. The analysis revealed a number of necessary findings:
- HummingLM demonstrates important enhancements over baseline approaches in sign constancy (57.93% higher SI-SDR)
- The mannequin maintains strong efficiency throughout numerous musical situations, with explicit energy within the Aeolian mode
- Zero-shot efficiency on unseen instrument presets is similar to seen presets, confirming robust generalization capabilities
- Information augmentation methods present substantial advantages (27.70% enchancment in SI-SDR)
Total, HummingLM achieves state-of-the-art controllable music era by considerably bettering sign constancy, generalizing nicely to unseen devices, and delivering robust efficiency throughout numerous musical types, boosted additional by efficient information augmentation methods.
Environment friendly distributed coaching by means of parallelism, reminiscence, and AWS Neuron optimization
Splash Music compiled and optimized its mannequin for AWS Neuron, accelerating its mannequin growth lifecycle and deployment on AWS Trainium chips. The workforce thought-about scalability, parallelization, and reminiscence effectivity and designed a system for supporting fashions scaling from 2B to over 10B parameters. This contains:
- Allow distributed coaching with sequence parallelism (SP), tensor parallelism (TP), and information parallelism (DP), scaling as much as 64 trn1.32xlarge cases
- Implement ZeRO-1 reminiscence optimization with selective checkpoint re-computation
- Combine Neuron Kernel Interface (NKI) to deploy Flash Consideration, accelerating dense consideration layers and streamlining causal masks administration
- Decompose the mannequin into core subcomponents (token processors, transformer layers, MLPs) and optimize every for Neuron execution
- Implement mixed-precision coaching (bfloat16 and float32)
When optimizations on the Neuron stage had been full, optimizing the orchestration layer was necessary as nicely. Orchestrated by SageMaker HyperPod, Splash Music developed a strong, Slurm-integrated pipeline that streamlines multi-node coaching, balances parallelism, and makes use of activation checkpointing for superior reminiscence effectivity. The pipeline processes information by means of a number of crucial phases:
- Tokenization – Audio inputs are processed by means of a Descript Audio Codec (DAC) encoder to generate a number of codebook representations
- Conditional era – The mannequin learns to foretell codebooks given hummed melodies and timbre management alerts
- Loss capabilities – The answer makes use of a specialised cross-entropy loss perform to optimize each token prediction and audio reconstruction high quality
Mannequin Inference on AWS Inferentia on Amazon Elastic Container Service (ECS)
After coaching, the mannequin is deployed on an Amazon Elastic Container Service (Amazon ECS) cluster with AWS Inferentia cases. The audio is uploaded to Amazon Easy Storage Service (Amazon S3) to deal with giant volumes of user-submitted recordings, which regularly range in high quality. Every add triggers an AWS Lambda perform, which queues the file in Amazon Easy Queue Service (Amazon SQS) for supply to the ECS cluster the place inference runs. On the cluster, HummingLM performs two key steps: stem separation to isolate and clear vocals, and audio-to-melody conversion to extract musical construction. Lastly, the pipeline recombines the cleaned vocals by means of a post-processing step with backing tracks, producing the totally processed remixed audio.
Outcomes and influence
Splash Music’s analysis and growth groups now depend on a unified infrastructure constructed on Amazon SageMaker HyperPod and AWS Trainium chips. The answer has yielded the next advantages:
- Automated, resilient and scalable coaching – SageMaker HyperPod provisions clusters of AWS Trainium EC2 cases at scale, managing orchestration, useful resource allocation, and fault restoration routinely. This removes weeks of guide setup and facilitates dependable, repeatable coaching runs. SageMaker HyperPod constantly displays cluster well being, routinely rerouting jobs and repairing failed nodes, minimizing downtime and maximizing useful resource utilization. With SageMaker HyperPod, Splash Music lower operational downtime to close zero, enabling weekly mannequin refreshes and sooner deployment of recent options.
- AWS Trainium diminished Splash’s coaching prices by over 54% – Splash Music realized over twofold positive factors in coaching velocity and lower coaching prices by 54% utilizing AWS Trainium based mostly cases over conventional GPU-based options used with their earlier cloud supplier. With this leap in effectivity, Splash Music can practice bigger fashions, launch updates extra continuously, and speed up innovation throughout their generative music service. The acceleration additionally delivers sooner mannequin iteration, with 8% enchancment in throughput, and elevated its most batch dimension from 70 to 512 for a extra environment friendly use of compute assets and better throughput per coaching run.
Splash achieved important throughput enhancements over typical architectures, to course of expansive datasets, supporting the mannequin’s advanced multimodal nature. The answer supplies a strong basis for future development as information and fashions proceed to scale.
“AWS Trainium and SageMaker HyperPod took the friction out of our workflow at Splash Music.” says Daniel Hatadi, Software program Engineer, Splash Music. “We changed brittle GPU clusters with automated, self-healing distributed coaching that scales seamlessly. Coaching instances are practically 50% sooner, and coaching prices have dropped by 54%. By counting on AWS AI chips and SageMaker HyperPod and collaborating with the AWS Generative AI Innovation Middle, we had been capable of give attention to mannequin design and music-specific analysis, as an alternative of cluster upkeep. This collaboration has made it simpler for us to iterate rapidly, run extra experiments, practice bigger fashions, and preserve delivery enhancements while not having a much bigger workforce.”
Splash Music additionally featured within the AWS Summit Sydney 2025 keynote:
Conclusion and Subsequent Steps
Splash Music is redefining how creators carry their musical concepts to life, making it potential for anybody to generate recent, personalised tracks that resonate with tens of millions of listeners worldwide. To help this imaginative and prescient at scale, Splash constructed its HummingLM FM in shut collaboration with AWS Startups and the GenAIIC, utilizing providers akin to SageMaker HyperPod and AWS Trainium. These options present the infrastructure and efficiency wanted to maintain tempo, serving to Splash to create much more intuitive and galvanizing experiences for creators.
“With SageMaker HyperPod and Trainium, our researchers experiment as quick as our group creates.” says Randeep Bhatia, Chief Know-how Officer, Splash Music. “We’re not simply maintaining with music tendencies—we’re setting them.”
Trying ahead, Splash Music plans to increase its coaching datasets tenfold, discover multimodal audio/video era, and moreover collaborate with the GenAIIC on further R&D and its subsequent model of HummingLM FM.
Attempt creating your personal music utilizing Splash Music, and be taught extra about Amazon SageMaker HyperPod and AWS Trainium.
In regards to the authors
 Sheldon Liu is an Senior Utilized Scientist, ANZ Tech Lead on the AWS Generative AI Innovation Middle. He companions with AWS clients throughout numerous industries to develop and implement progressive generative AI options, accelerating their AI adoption journey whereas driving important enterprise outcomes.
Sheldon Liu is an Senior Utilized Scientist, ANZ Tech Lead on the AWS Generative AI Innovation Middle. He companions with AWS clients throughout numerous industries to develop and implement progressive generative AI options, accelerating their AI adoption journey whereas driving important enterprise outcomes.
 Mahsa Paknezhad is a Deep Studying Architect and a key member of the AWS Generative AI Innovation Middle. She works carefully with enterprise purchasers to design, implement, and optimize cutting-edge generative AI options. With a give attention to scalability and manufacturing readiness, Mahsa helps organizations throughout numerous industries harness superior Generative AI fashions to attain significant enterprise outcomes.
Mahsa Paknezhad is a Deep Studying Architect and a key member of the AWS Generative AI Innovation Middle. She works carefully with enterprise purchasers to design, implement, and optimize cutting-edge generative AI options. With a give attention to scalability and manufacturing readiness, Mahsa helps organizations throughout numerous industries harness superior Generative AI fashions to attain significant enterprise outcomes.
 Xiaoning Wang is a machine studying engineer on the AWS Generative AI Innovation Middle. He focuses on giant language mannequin coaching and optimization on AWS Trainium and Inferentia, with expertise in distributed coaching, RAG, and low-latency inference. He works with enterprise clients to construct scalable generative AI options that drive actual enterprise influence.
Xiaoning Wang is a machine studying engineer on the AWS Generative AI Innovation Middle. He focuses on giant language mannequin coaching and optimization on AWS Trainium and Inferentia, with expertise in distributed coaching, RAG, and low-latency inference. He works with enterprise clients to construct scalable generative AI options that drive actual enterprise influence.
 Tianyu Liu is an utilized scientist on the AWS Generative AI Innovation Middle. He companions with enterprise clients to design, implement, and optimize cutting-edge generative AI fashions, advancing innovation and serving to organizations obtain transformative outcomes with scalable, production-ready AI options.
Tianyu Liu is an utilized scientist on the AWS Generative AI Innovation Middle. He companions with enterprise clients to design, implement, and optimize cutting-edge generative AI fashions, advancing innovation and serving to organizations obtain transformative outcomes with scalable, production-ready AI options.
 Xuefeng Liu leads a science workforce on the AWS Generative AI Innovation Middle within the Asia Pacific areas. His workforce companions with AWS clients on generative AI initiatives, with the purpose of accelerating clients’ adoption of generative AI.
Xuefeng Liu leads a science workforce on the AWS Generative AI Innovation Middle within the Asia Pacific areas. His workforce companions with AWS clients on generative AI initiatives, with the purpose of accelerating clients’ adoption of generative AI.
 Daniel Wirjo is a Options Architect at AWS, targeted on AI and SaaS startups. As a former startup CTO, he enjoys collaborating with founders and engineering leaders to drive development and innovation on AWS. Exterior of labor, Daniel enjoys taking walks with a espresso in hand, appreciating nature, and studying new concepts.
Daniel Wirjo is a Options Architect at AWS, targeted on AI and SaaS startups. As a former startup CTO, he enjoys collaborating with founders and engineering leaders to drive development and innovation on AWS. Exterior of labor, Daniel enjoys taking walks with a espresso in hand, appreciating nature, and studying new concepts.



{kind=link}