revealed a demo of their newest Speech-to-Speech mannequin. A conversational AI agent who’s actually good at talking, they supply related solutions, they communicate with expressions, and actually, they’re simply very enjoyable and interactive to play with.
Notice {that a} technical paper will not be out but, however they do have a brief weblog put up that gives plenty of details about the strategies they used and former algorithms they constructed upon.
Fortunately, they supplied sufficient info for me to write down this text and make a YouTube video out of it. Learn on!
Coaching a Conversational Speech Mannequin
Sesame is a Conversational Speech Mannequin, or a CSM. It inputs each textual content and audio, and generates speech as audio. Whereas they haven’t revealed their coaching knowledge sources within the articles, we are able to nonetheless attempt to take a strong guess. The weblog put up closely cites one other CSM, 2024’s Moshi, and fortuitously, the creators of Moshi did reveal their knowledge sources of their paper. Moshi makes use of 7 million hours of unsupervised speech knowledge, 170 hours of pure and scripted conversations (for multi-stream coaching), and 2000 extra hours of phone conversations (The Fischer Dataset).

However what does it actually take to generate audio?
In uncooked type, audio is only a lengthy sequence of amplitude values — a waveform. For instance, in the event you’re sampling audio at 24 kHz, you’re capturing 24,000 float values each second.

In fact, it’s fairly resource-intensive to course of 24000 float values for only one second of knowledge, particularly as a result of transformer computations scale quadratically with sequence size. It might be nice if we might compress this sign and cut back the variety of samples required to course of the audio.
We are going to take a deep dive into the Mimi encoder and particularly Residual Vector Quantizers (RVQ), that are the spine of Audio/Speech modeling in Deep Studying at this time. We are going to finish the article by studying about how Sesame generates audio utilizing its particular dual-transformer structure.
Preprocessing audio
Compression and have extraction are the place convolution helps us. Sesame makes use of the Mimi speech encoder to course of audio. Mimi was launched within the aforementioned Moshi paper as nicely. Mimi is a self-supervised audio encoder-decoder mannequin that converts audio waveforms into discrete “latent” tokens first, after which reconstructs the unique sign. Sesame solely makes use of the encoder part of Mimi to tokenize the enter audio tokens. Let’s learn the way.
Mimi inputs the uncooked speech waveform at 24Khz, passes them by way of a number of strided convolution layers to downsample the sign, with a stride issue of 4, 5, 6, 8, and a pair of. Because of this the primary CNN block downsamples the audio by 4x, then 5x, then 6x, and so forth. Ultimately, it downsamples by an element of 1920, decreasing it to simply 12.5 frames per second.
The convolution blocks additionally mission the unique float values to an embedding dimension of 512. Every embedding aggregates the native options of the unique 1D waveform. 1 second of audio is now represented as round 12 vectors of dimension 512. This fashion, Mimi reduces the sequence size from 24000 to simply 12 and converts them into dense steady vectors.

What’s Audio Quantization?
Given the continual embeddings obtained after the convolution layer, we need to tokenize the enter speech. If we are able to signify speech as a sequence of tokens, we are able to apply customary language studying transformers to coach generative fashions.
Mimi makes use of a Residual Vector Quantizer or RVQ tokenizer to attain this. We are going to speak concerning the residual half quickly, however first, let’s take a look at what a easy vanilla Vector quantizer does.
Vector Quantization
The concept behind Vector Quantization is easy: you prepare a codebook , which is a set of, say, 1000 random vector codes all of dimension 512 (similar as your embedding dimension).

Then, given the enter vector, we’ll map it to the closest vector in our codebook — principally snapping some extent to its nearest cluster middle. This implies we now have successfully created a hard and fast vocabulary of tokens to signify every audio body, as a result of regardless of the enter body embedding could also be, we’ll signify it with the closest cluster centroid. If you wish to be taught extra about Vector Quantization, try my video on this subject the place I’m going a lot deeper with this.
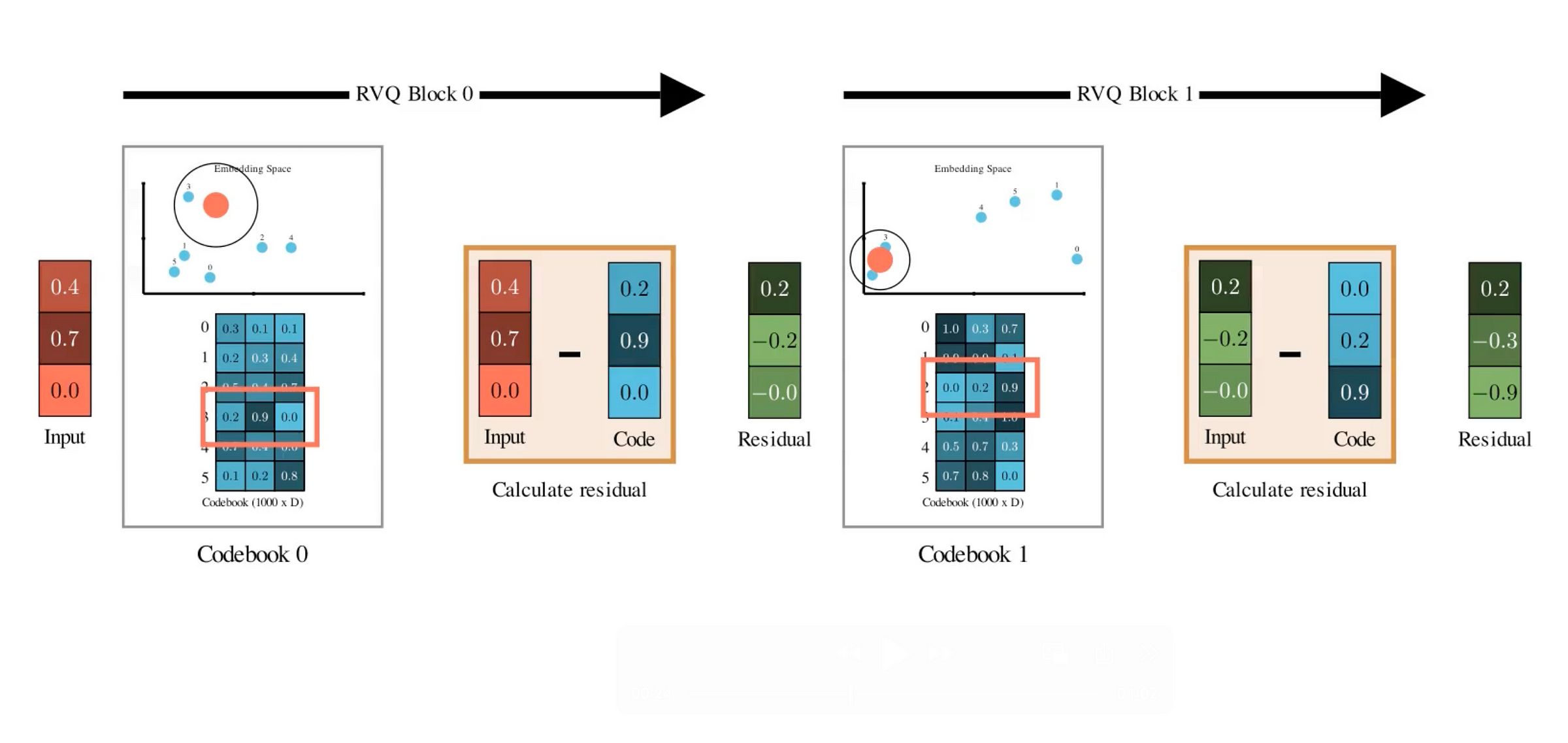
Residual Vector Quantization
The issue with easy vector quantization is that the lack of info could also be too excessive as a result of we’re mapping every vector to its cluster’s centroid. This “snap” is never excellent, so there may be at all times an error between the unique embedding and the closest codebook.
The large concept of Residual Vector Quantization is that it doesn’t cease at having only one codebook. As a substitute, it tries to make use of a number of codebooks to signify the enter vector.
- First, you quantize the unique vector utilizing the primary codebook.
- Then, you subtract that centroid out of your authentic vector. What you’re left with is the residual — the error that wasn’t captured within the first quantization.
- Now take this residual, and quantize it once more, utilizing a second codebook full of brand name new code vectors — once more by snapping it to the closest centroid.
- Subtract that too, and also you get a smaller residual. Quantize once more with a 3rd codebook… and you’ll hold doing this for as many codebooks as you need.

Every step hierarchically captures slightly extra element that was missed within the earlier spherical. If you happen to repeat this for, let’s say, N codebooks, you get a set of N discrete tokens from every stage of quantization to signify one audio body.
The good factor about RVQs is that they’re designed to have a excessive inductive bias in the direction of capturing probably the most important content material within the very first quantizer. Within the subsequent quantizers, they be taught an increasing number of fine-grained options.
If you happen to’re aware of PCA, you may consider the primary codebook as containing the first principal elements, capturing probably the most vital info. The following codebooks signify higher-order elements, containing info that provides extra particulars.

Acoustic vs Semantic Codebooks
Since Mimi is educated on the duty of audio reconstruction, the encoder compresses the sign to the discretized latent house, and the decoder reconstructs it again from the latent house. When optimizing for this process, the RVQ codebooks be taught to seize the important acoustic content material of the enter audio contained in the compressed latent house.
Mimi additionally individually trains a single codebook (vanilla VQ) that solely focuses on embedding the semantic content material of the audio. For this reason Mimi is named a split-RVQ tokenizer – it divides the quantization course of into two impartial parallel paths: one for semantic info and one other for acoustic info.

To coach semantic representations, Mimi used data distillation with an present speech mannequin known as WavLM as a semantic trainer. Mainly, Mimi introduces a further loss perform that decreases the cosine distance between the semantic RVQ code and the WavLM-generated embedding.
Audio Decoder
Given a dialog containing textual content and audio, we first convert them right into a sequence of token embeddings utilizing the textual content and audio tokenizers. This token sequence is then enter right into a transformer mannequin as a time sequence. Within the weblog put up, this mannequin is known as the Autoregressive Spine Transformer. Its process is to course of this time sequence and output the “zeroth” codebook token.
A lighterweight transformer known as the audio decoder then reconstructs the following codebook tokens conditioned on this zeroth code generated by the spine transformer. Notice that the zeroth code already incorporates plenty of details about the historical past of the dialog because the spine transformer has visibility of the whole previous sequence. The light-weight audio decoder solely operates on the zeroth token and generates the opposite N-1 codes. These codes are generated by utilizing N-1 distinct linear layers that output the chance of selecting every code from their corresponding codebooks.
You may think about this course of as predicting a textual content token from the vocabulary in a text-only LLM. Simply {that a} text-based LLM has a single vocabulary, however the RVQ-tokenizer has a number of vocabularies within the type of the N codebooks, so you might want to prepare a separate linear layer to mannequin the codes for every.

Lastly, after the codewords are all generated, we combination them to type the mixed steady audio embedding. The ultimate job is to transform this audio again to a waveform. For this, we apply transposed convolutional layers to upscale the embedding again from 12.5 Hz again to KHz waveform audio. Mainly, reversing the transforms we had utilized initially throughout audio preprocessing.
In Abstract
So, right here is the general abstract of the Sesame mannequin in some bullet factors.
- Sesame is constructed on a multimodal Dialog Speech Mannequin or a CSM.
- Textual content and audio are tokenized collectively to type a sequence of tokens and enter into the spine transformer that autoregressively processes the sequence.
- Whereas the textual content is processed like another text-based LLM, the audio is processed immediately from its waveform illustration. They use the Mimi encoder to transform the waveform into latent codes utilizing a cut up RVQ tokenizer.
- The multimodal spine transformers eat a sequence of tokens and predict the following zeroth codeword.
- One other light-weight transformer known as the Audio Decoder predicts the following codewords from the zeroth codeword.
- The ultimate audio body illustration is generated from combining all of the generated codewords and upsampled again to the waveform illustration.
Thanks for studying!
References and Should-read papers
Related papers:
Moshi: https://arxiv.org/abs/2410.00037
SoundStream: https://arxiv.org/abs/2107.03312
HuBert: https://arxiv.org/abs/2106.07447
Speech Tokenizer: https://arxiv.org/abs/2308.16692


{kind=link}