In the present day, we’re excited to announce a brand new functionality of Amazon SageMaker HyperPod process governance that can assist you optimize coaching effectivity and community latency of your AI workloads. SageMaker HyperPod process governance streamlines useful resource allocation and facilitates environment friendly compute useful resource utilization throughout groups and initiatives on Amazon Elastic Kubernetes Service (Amazon EKS) clusters. Directors can govern accelerated compute allocation and implement process precedence insurance policies, bettering useful resource utilization. This helps organizations concentrate on accelerating generative AI innovation and lowering time to market, fairly than coordinating useful resource allocation and replanning duties. Seek advice from Greatest practices for Amazon SageMaker HyperPod process governance for extra info.
Generative AI workloads usually demand intensive community communication throughout Amazon Elastic Compute Cloud (Amazon EC2) cases, the place community bandwidth impacts each workload runtime and processing latency. The community latency of those communications will depend on the bodily placement of cases inside a knowledge middle’s hierarchical infrastructure. Knowledge facilities could be organized into nested organizational models equivalent to community nodes and node units, with a number of cases per community node and a number of community nodes per node set. For instance, cases inside the identical organizational unit expertise quicker processing time in comparison with these throughout totally different models. This implies fewer community hops between cases ends in decrease communication.
To optimize the position of your generative AI workloads in your SageMaker HyperPod clusters by contemplating the bodily and logical association of assets, you need to use EC2 community topology info throughout your job submissions. An EC2 occasion’s topology is described by a set of nodes, with one node in every layer of the community. Seek advice from How Amazon EC2 occasion topology works for particulars on how EC2 topology is organized. Community topology labels supply the next key advantages:
- Diminished latency by minimizing community hops and routing visitors to close by cases
- Improved coaching effectivity by optimizing workload placement throughout community assets
With topology-aware scheduling for SageMaker HyperPod process governance, you need to use topology community labels to schedule your jobs with optimized community communication, thereby bettering process effectivity and useful resource utilization on your AI workloads.
On this put up, we introduce topology-aware scheduling with SageMaker HyperPod process governance by submitting jobs that characterize hierarchical community info. We offer particulars about use SageMaker HyperPod process governance to optimize your job effectivity.
Answer overview
Knowledge scientists work together with SageMaker HyperPod clusters. Knowledge scientists are chargeable for the coaching, fine-tuning, and deployment of fashions on accelerated compute cases. It’s essential to verify knowledge scientists have the required capability and permissions when interacting with clusters of GPUs.
To implement topology-aware scheduling, you first verify the topology info for all nodes in your cluster, then run a script that tells you which of them cases are on the identical community nodes, and eventually schedule a topology-aware coaching process in your cluster. This workflow facilitates larger visibility and management over the position of your coaching cases.
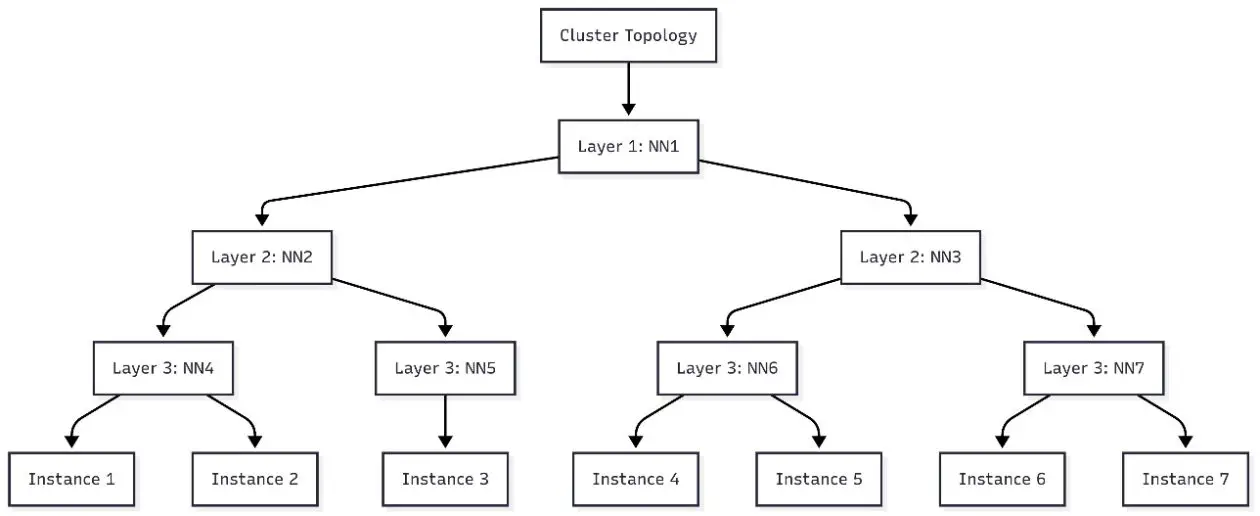
On this put up, we stroll via viewing node topology info and submitting topology-aware duties to your cluster. For reference, NetworkNodes describes the community node set of an occasion. In every community node set, three layers comprise the hierarchical view of the topology for every occasion. Cases which are closest to one another will share the identical layer 3 community node. If there are not any widespread community nodes within the backside layer (layer 3), then see if there may be commonality at layer 2.
Stipulations
To get began with topology-aware scheduling, you have to have the next stipulations:
- An EKS cluster
- A SageMaker HyperPod cluster with cases enabled for topology info
- The SageMaker HyperPod process governance add-on put in (model 1.2.2 or later)
- Kubectl put in
- (Optionally available) The SageMaker HyperPod CLI put in
Get node topology info
Run the next command to point out node labels in your cluster. This command gives community topology info for every occasion.
Cases with the identical community node layer 3 are as shut as doable, following EC2 topology hierarchy. You must see an inventory of node labels that appear to be the next:topology.k8s.aws/network-node-layer-3: nn-33333exampleRun the next script to point out the nodes in your cluster which are on the identical layers 1, 2, and three community nodes:
The output of this script will print a circulate chart that you need to use in a circulate diagram editor equivalent to Mermaid.js.org to visualise the node topology of your cluster. The next determine is an instance of the cluster topology for a seven-instance cluster.
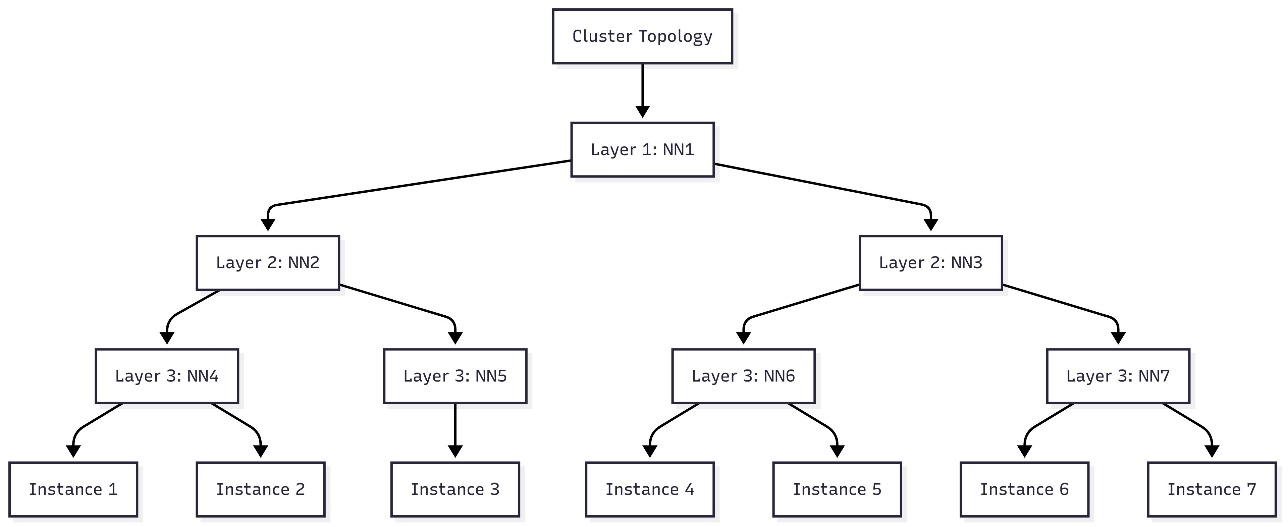
Submit duties
SageMaker HyperPod process governance presents two methods to submit duties utilizing topology consciousness. On this part, we focus on these two choices and a 3rd various choice to process governance.
Modify your Kubernetes manifest file
First, you may modify your present Kubernetes manifest file to incorporate one in every of two annotation choices:
- kueue.x-k8s.io/podset-required-topology – Use this feature in the event you should have all pods scheduled on nodes on the identical community node layer with a purpose to start the job
- kueue.x-k8s.io/podset-preferred-topology – Use this feature in the event you ideally need all pods scheduled on nodes in the identical community node layer, however you’ve got flexibility
The next code is an instance of a pattern job that makes use of the kueue.x-k8s.io/podset-required-topology setting to schedule pods that share the identical layer 3 community node:
To confirm which nodes your pods are operating on, use the next command to view node IDs per pod:kubectl get pods -n hyperpod-ns-team-a -o broad
Use the SageMaker HyperPod CLI
The second method to submit a job is thru the SageMaker HyperPod CLI. Make sure you set up the newest model (model pending) to make use of topology-aware scheduling. To make use of topology-aware scheduling with the SageMaker HyperPod CLI, you may embrace both the --preferred-topology parameter or the --required-topology parameter in your create job command.
The next code is an instance command to begin a topology-aware mnist coaching job utilizing the SageMaker HyperPod CLI, exchange XXXXXXXXXXXX together with your AWS account ID:
Clear up
In case you deployed new assets whereas following this put up, seek advice from the Clear Up part within the SageMaker HyperPod EKS workshop to be sure you don’t accrue undesirable prices.
Conclusion
Throughout giant language mannequin (LLM) coaching, pod-to-pod communication distributes the mannequin throughout a number of cases, requiring frequent knowledge trade between these cases. On this put up, we mentioned how SageMaker HyperPod process governance helps schedule workloads to allow job effectivity by optimizing throughput and latency. We additionally walked via schedule jobs utilizing SageMaker HyperPod topology community info to optimize community communication latency on your AI duties.
We encourage you to check out this resolution and share your suggestions within the feedback part.
In regards to the authors
 Nisha Nadkarni is a Senior GenAI Specialist Options Architect at AWS, the place she guides firms via finest practices when deploying giant scale distributed coaching and inference on AWS. Previous to her present function, she spent a number of years at AWS centered on serving to rising GenAI startups develop fashions from ideation to manufacturing.
Nisha Nadkarni is a Senior GenAI Specialist Options Architect at AWS, the place she guides firms via finest practices when deploying giant scale distributed coaching and inference on AWS. Previous to her present function, she spent a number of years at AWS centered on serving to rising GenAI startups develop fashions from ideation to manufacturing.
 Siamak Nariman is a Senior Product Supervisor at AWS. He’s centered on AI/ML expertise, ML mannequin administration, and ML governance to enhance total organizational effectivity and productiveness. He has intensive expertise automating processes and deploying numerous applied sciences.
Siamak Nariman is a Senior Product Supervisor at AWS. He’s centered on AI/ML expertise, ML mannequin administration, and ML governance to enhance total organizational effectivity and productiveness. He has intensive expertise automating processes and deploying numerous applied sciences.
 Zican Li is a Senior Software program Engineer at Amazon Net Providers (AWS), the place he leads software program improvement for Activity Governance on SageMaker HyperPod. In his function, he focuses on empowering clients with superior AI capabilities whereas fostering an atmosphere that maximizes engineering staff effectivity and productiveness.
Zican Li is a Senior Software program Engineer at Amazon Net Providers (AWS), the place he leads software program improvement for Activity Governance on SageMaker HyperPod. In his function, he focuses on empowering clients with superior AI capabilities whereas fostering an atmosphere that maximizes engineering staff effectivity and productiveness.
 Anoop Saha is a Sr GTM Specialist at Amazon Net Providers (AWS) specializing in generative AI mannequin coaching and inference. He companions with high frontier mannequin builders, strategic clients, and AWS service groups to allow distributed coaching and inference at scale on AWS and lead joint GTM motions. Earlier than AWS, Anoop held a number of management roles at startups and huge firms, primarily specializing in silicon and system structure of AI infrastructure.
Anoop Saha is a Sr GTM Specialist at Amazon Net Providers (AWS) specializing in generative AI mannequin coaching and inference. He companions with high frontier mannequin builders, strategic clients, and AWS service groups to allow distributed coaching and inference at scale on AWS and lead joint GTM motions. Earlier than AWS, Anoop held a number of management roles at startups and huge firms, primarily specializing in silicon and system structure of AI infrastructure.



{kind=link}