
The AWS DeepRacer League is the world’s first autonomous racing league, open to anybody. Introduced at re:Invent 2018, it places machine studying within the palms of each developer by the enjoyable and pleasure of growing and racing self-driving distant management automobiles. By the previous 7 years, over 560 thousand builders of all talent ranges have competed within the league at 1000’s of Amazon and buyer occasions globally. Whereas the ultimate championships concluded at re:Invent 2024, that very same occasion performed host to a model new AI competitors, ushering in a brand new period of gamified studying within the age of generative AI.
In December 2024, AWS launched the AWS Giant Language Mannequin League (AWS LLM League) throughout re:Invent 2024. This inaugural occasion marked a major milestone in democratizing machine studying, bringing collectively over 200 enthusiastic attendees from various backgrounds to have interaction in hands-on technical workshops and a aggressive basis mannequin fine-tuning problem. Utilizing learnings from DeepRacer, the first goal of the occasion was to simplify mannequin customization studying whereas fostering a collaborative group round generative AI innovation by a gamified competitors format.
AWS LLM League construction and outcomes
The AWS LLM League was designed to decrease the boundaries to entry in generative AI mannequin customization by offering an expertise the place individuals, no matter their prior information science expertise, might interact in fine-tuning LLMs. Utilizing Amazon SageMaker JumpStart, attendees have been guided by the method of customizing LLMs to deal with actual enterprise challenges adaptable to their area.

As proven within the previous determine, the problem started with a workshop, the place individuals launched into a aggressive journey to develop extremely efficient fine-tuned LLMs. Rivals have been tasked with customizing Meta’s Llama 3.2 3B base mannequin for a particular area, making use of the instruments and strategies they discovered. The submitted mannequin can be in contrast in opposition to a much bigger 90B reference mannequin with the standard of the responses determined utilizing an LLM-as-a-Decide strategy. Members rating a win for every query the place the LLM decide deemed the fine-tuned mannequin’s response to be extra correct and complete than that of the bigger mannequin.

Within the preliminary rounds, individuals submitted lots of of distinctive fine-tuned fashions to the competitors leaderboard, every striving to outperform the baseline mannequin. These submissions have been evaluated primarily based on accuracy, coherence, and domain-specific adaptability. After rigorous assessments, the highest 5 finalists have been shortlisted, with the perfect fashions reaching win charges above 55% in opposition to the big reference fashions (as proven within the previous determine). Demonstrating {that a} smaller mannequin can obtain aggressive efficiency highlights important advantages in compute effectivity at scale. Utilizing a 3B mannequin as an alternative of a 90B mannequin reduces operational prices, permits sooner inference, and makes superior AI extra accessible throughout varied industries and use instances.
The competitors culminates within the Grand Finale, the place finalists showcase their fashions in a ultimate spherical of analysis to find out the final word winner.
The fine-tuning journey
This journey was rigorously designed to information individuals by every vital stage of fine-tuning a big language mannequin—from dataset creation to mannequin analysis—utilizing a set of no-code AWS instruments. Whether or not they have been newcomers or skilled builders, individuals gained hands-on expertise in customizing a basis mannequin by a structured, accessible course of. Let’s take a more in-depth take a look at how the problem unfolded, beginning with how individuals ready their datasets.
Stage 1: Making ready the dataset with PartyRock
Through the workshop, individuals discovered tips on how to generate artificial information utilizing an Amazon PartyRock playground (as proven within the following determine). PartyRock provides entry to a wide range of prime basis fashions by Amazon Bedrock at no further price. This enabled individuals to make use of a no-code AI generated app for creating artificial coaching information that have been used for fine-tuning.

Members started by defining the goal area for his or her fine-tuning job, equivalent to finance, healthcare, or authorized compliance. Utilizing PartyRock’s intuitive interface, they generated instruction-response pairs that mimicked real-world interactions. To boost dataset high quality, they used PartyRock’s skill to refine responses iteratively, ensuring that the generated information was each contextually related and aligned with the competitors’s goals.
This section was essential as a result of the standard of artificial information straight impacted the mannequin’s skill to outperform a bigger baseline mannequin. Some individuals additional enhanced their datasets by using exterior validation strategies, equivalent to human-in-the-loop assessment or reinforcement learning-based filtering.
Stage 2: Advantageous-tuning with SageMaker JumpStart
After the datasets have been ready, individuals moved to SageMaker JumpStart, a totally managed machine studying hub that simplifies the fine-tuning course of. Utilizing a pre-trained Meta Llama 3.2 3B mannequin as the bottom, they custom-made it with their curated datasets, adjusting hyperparameters (proven within the following determine) equivalent to:
- Epochs: Figuring out what number of occasions the mannequin iterates over the dataset.
- Studying price: Controlling how a lot the mannequin weights alter with every iteration.
- LoRA parameters: Optimizing effectivity with low-rank adaptation (LoRA) strategies.

One of many key benefits of SageMaker JumpStart is that it gives a no-code UI, proven within the following determine, permitting individuals to fine-tune fashions without having to jot down code. This accessibility enabled even these with minimal machine studying expertise to have interaction in mannequin customization successfully.
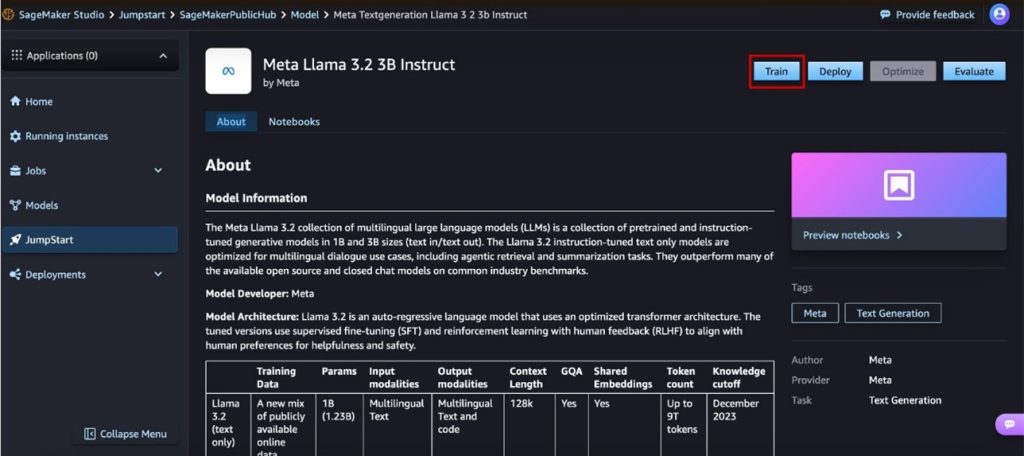
Through the use of the distributed coaching capabilities of SageMaker, individuals have been in a position to run a number of experiments in parallel, optimizing their fashions for accuracy and response high quality. The iterative fine-tuning course of allowed them to discover totally different configurations to maximise efficiency.
Stage 3: Analysis with Sagemaker Make clear
To ensure that their fashions weren’t solely correct but in addition unbiased, individuals had the choice to make use of Amazon SageMaker Make clear for analysis, proven within the following determine.

This section included:
- Bias detection: Figuring out skewed response patterns that may favor particular viewpoints.
- Explainability metrics: Understanding why the mannequin made sure predictions.
- Efficiency scoring: Evaluating mannequin output in opposition to floor fact labels.
Whereas not necessary, the mixing of SageMaker Make clear supplied an extra layer of assurance for individuals who wished to validate their fashions additional, verifying that their outputs have been dependable and performant.
Stage 4: Submission and analysis utilizing LLM-as-a-Decide from Amazon Bedrock
After fine-tuned fashions have been prepared, they have been submitted to the competitors leaderboard for analysis utilizing the Amazon Bedrock Evaluations LLM-as-a-Decide strategy. This automated analysis system compares the fine-tuned fashions in opposition to the reference 90B mannequin utilizing predefined benchmarks, as proven within the following determine.

Every response was scored primarily based on:
- Relevance: How effectively the response addressed the query.
- Depth: The extent of element and perception supplied.
- Coherence: Logical stream and consistency of the reply.
Members’ fashions earned a rating every time their response outperformed the 90B mannequin in a head-to-head comparability. The leaderboard dynamically up to date as new submissions have been evaluated, fostering a aggressive but collaborative studying atmosphere.
Grand Finale showcase
The Grand Finale of the AWS LLM League was an electrifying showdown, the place the highest 5 finalists, handpicked from lots of of submissions, competed in a high-stakes stay occasion. Amongst them was Ray, a decided contender whose fine-tuned mannequin had persistently delivered sturdy outcomes all through the competitors. Every finalist needed to show not simply the technical superiority of their fine-tuned fashions, but in addition their skill to adapt and refine responses in real-time.

The competitors was intense from the outset, with every participant bringing distinctive methods to the desk. Ray’s skill to tweak prompts dynamically set him aside early on, offering optimum responses to a variety of domain-specific questions. The vitality within the room was palpable as finalists’ AI-generated solutions have been judged by a hybrid analysis system—40% by an LLM, 40% by skilled panelists from Meta AI and AWS, and 20% by an enthusiastic stay viewers in opposition to the next rubric:
- Generalization skill: How effectively the fine-tuned mannequin tailored to beforehand unseen questions.
- Response high quality: Depth, accuracy, and contextual understanding.
- Effectivity: The mannequin’s skill to offer complete solutions with minimal latency.
One of the vital gripping moments got here when contestants encountered the notorious Strawberry Drawback, a deceptively easy letter-counting problem that uncovered an inherent weak spot in LLMs. Ray’s mannequin delivered the right reply, however the AI decide misclassified it, sparking a debate among the many human judges and viewers. This pivotal second underscored the significance of human-in-the-loop analysis, highlighting how AI and human judgment should complement one another for truthful and correct assessments.
As the ultimate spherical concluded, Ray’s mannequin persistently outperformed expectations, securing him the title of AWS LLM League Champion. The Grand Finale was not only a check of AI—it was a showcase of innovation, technique, and the evolving synergy between synthetic intelligence and human ingenuity.

Conclusion and looking out forward
The inaugural AWS LLM League competitors efficiently demonstrated how massive language mannequin fine-tuning may be gamified to drive innovation and engagement. By offering hands-on expertise with cutting-edge AWS AI and machine studying (ML) companies, the competitors not solely demystified the fine-tuning course of, but in addition impressed a brand new wave of AI fanatics to experiment and innovate on this house.
Because the AWS LLM League strikes ahead, future iterations will increase on these learnings, incorporating extra superior challenges, bigger datasets, and deeper mannequin customization alternatives. Whether or not you’re a seasoned AI practitioner or a newcomer to machine studying, the AWS LLM League provides an thrilling and accessible solution to develop real-world AI experience.
Keep tuned for upcoming AWS LLM League occasions and prepare to place your fine-tuning expertise to the check!
In regards to the authors
 Vincent Oh is the Senior Specialist Options Architect in AWS for AI & Innovation. He works with public sector prospects throughout ASEAN, proudly owning technical engagements and serving to them design scalable cloud options throughout varied innovation tasks. He created the LLM League within the midst of serving to prospects harness the ability of AI of their use instances by gamified studying. He additionally serves as an Adjunct Professor in Singapore Administration College (SMU), instructing pc science modules underneath Faculty of Laptop & Info Methods (SCIS). Previous to becoming a member of Amazon, he labored as Senior Principal Digital Architect at Accenture and Cloud Engineering Follow Lead at UST.
Vincent Oh is the Senior Specialist Options Architect in AWS for AI & Innovation. He works with public sector prospects throughout ASEAN, proudly owning technical engagements and serving to them design scalable cloud options throughout varied innovation tasks. He created the LLM League within the midst of serving to prospects harness the ability of AI of their use instances by gamified studying. He additionally serves as an Adjunct Professor in Singapore Administration College (SMU), instructing pc science modules underneath Faculty of Laptop & Info Methods (SCIS). Previous to becoming a member of Amazon, he labored as Senior Principal Digital Architect at Accenture and Cloud Engineering Follow Lead at UST.
 Natasya Ok. Idries is the Product Advertising Supervisor for AWS AI/ML Gamified Studying Applications. She is keen about democratizing AI/ML expertise by participating and hands-on instructional initiatives that bridge the hole between superior expertise and sensible enterprise implementation. Her experience in constructing studying communities and driving digital innovation continues to form her strategy to creating impactful AI teaching programs. Outdoors of labor, Natasya enjoys touring, cooking Southeast Asian cuisines and exploring nature trails.
Natasya Ok. Idries is the Product Advertising Supervisor for AWS AI/ML Gamified Studying Applications. She is keen about democratizing AI/ML expertise by participating and hands-on instructional initiatives that bridge the hole between superior expertise and sensible enterprise implementation. Her experience in constructing studying communities and driving digital innovation continues to form her strategy to creating impactful AI teaching programs. Outdoors of labor, Natasya enjoys touring, cooking Southeast Asian cuisines and exploring nature trails.



{kind=link}