Multimodal fine-tuning represents a strong method for customizing imaginative and prescient massive language fashions (LLMs) to excel at particular duties that contain each visible and textual data. Though base multimodal fashions provide spectacular common capabilities, they typically fall brief when confronted with specialised visible duties, domain-specific content material, or output formatting necessities. Advantageous-tuning addresses these limitations by adapting fashions to your particular knowledge and use circumstances, dramatically enhancing efficiency on duties that matter to your online business.
A standard use case is doc processing, which incorporates extracting structured data from advanced layouts together with invoices, buy orders, varieties, tables, or technical diagrams. Though off-shelf LLMs typically wrestle with specialised paperwork like tax varieties, invoices, and mortgage purposes, fine-tuned fashions can study from excessive knowledge variations and may ship considerably larger accuracy whereas decreasing processing prices.
This submit offers a complete hands-on information to fine-tune Amazon Nova Lite for doc processing duties, with a deal with tax type knowledge extraction. Utilizing our open-source GitHub repository code pattern, we exhibit the whole workflow from knowledge preparation to mannequin deployment. Since Amazon Bedrock offers on-demand inference with pay-per-token pricing for Amazon Nova, we will profit from the accuracy enchancment from mannequin customization and keep the pay-as-you-go price construction.
The doc processing problem
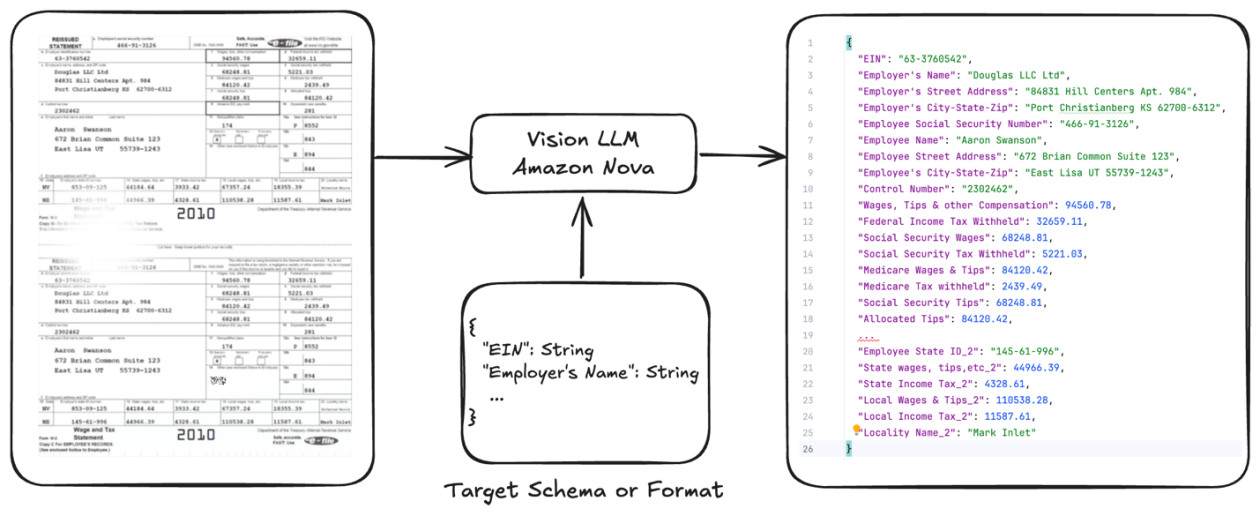
Given a single or multi-page doc, the aim is to extract or derive particular structured data from the doc in order that it may be used for downstream methods or further insights. The next diagram exhibits how a imaginative and prescient LLM can be utilized to derive the structured data primarily based on a mix of textual content and imaginative and prescient capabilities.
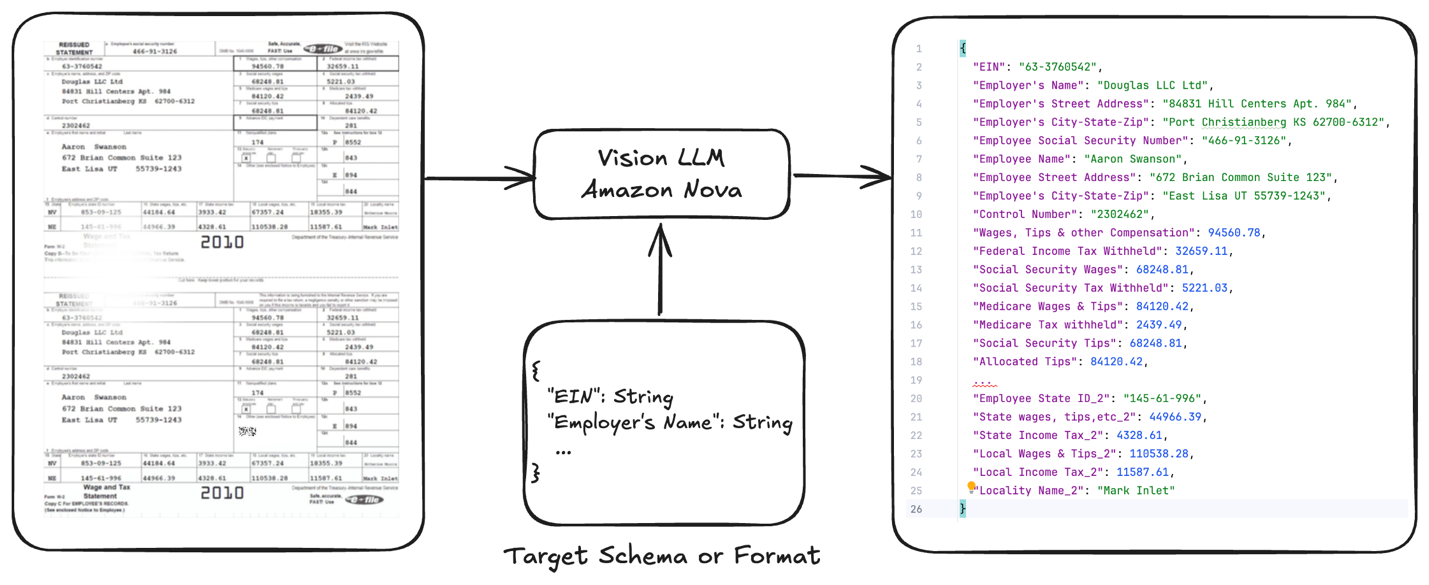
The important thing challenges for enterprises in workflow automation when processing paperwork, like invoices or W2 tax varieties, are the next:
- Advanced layouts: Specialised varieties include a number of sections with particular fields organized in a structured format.
- Variability of doc sorts: Many various doc sorts exist (invoices, contracts, varieties).
- Variability inside a single doc kind: Every vendor can ship a unique bill format and magnificence or kind.
- Information high quality variations: Scanned paperwork range in high quality, orientation, and completeness.
- Language limitations: Paperwork might be in a number of languages.
- Vital accuracy necessities: Tax-related knowledge extraction calls for extraordinarily excessive accuracy.
- Structured output wants: Extracted knowledge should be formatted persistently for downstream processing.
- Scalability and integration: Develop with enterprise wants and combine with current methods; for instance, Enterprise Useful resource Planning (ERP) methods.
Approaches for clever doc processing that use LLMs or imaginative and prescient LLMs fall into three essential classes:
- Zero-shot prompting: An LLM or imaginative and prescient LLM is used to derive the structured data primarily based on the enter doc, directions, and the goal schema.
- Few-shot prompting: A method used with LLMs or imaginative and prescient LLMs the place a couple of of different further examples (doc + goal output) are supplied inside the immediate to information the mannequin in finishing a selected job. In contrast to zero-shot prompting, which depends solely on pure language directions, few-shot prompting can enhance accuracy and consistency by demonstrating the specified input-output habits by means of a set of examples.
- Advantageous-tuning: Customise or fine-tune the weights of a given LLM or imaginative and prescient LLM by offering bigger quantities of annotated paperwork (enter/output pairs), to show the mannequin precisely tips on how to extract or interpret related data.
For the primary two approaches, discuss with the amazon-nova-samples repository, which comprises pattern code on tips on how to use the Amazon Bedrock Converse API for structured output through the use of instrument calling.
Off-shelf LLMs excel at common doc understanding, however they won’t optimally deal with domain-specific challenges. A fine-tuned Nova mannequin can improve efficiency by:
- Studying document-specific layouts and area relationships
- Adapting to widespread high quality variations in your doc dataset
- Offering constant, structured outputs
- Sustaining excessive accuracy throughout completely different doc variations. For instance, bill paperwork can have lots of of various distributors, every with completely different codecs, layouts and even completely different languages.
Creating the annotated dataset and deciding on the customization method
Whereas there are numerous strategies for personalization of Amazon Nova fashions obtainable, essentially the most related for doc processing are the next:
- Advantageous-tune for particular duties: Adapt Nova fashions for particular duties utilizing supervised fine-tuning (SFT). Select between Parameter-Environment friendly Advantageous-Tuning (PEFT) for lightweight adaptation with restricted knowledge, or full fine-tuning when you’ve got in depth coaching datasets to replace all parameters of the mannequin.
- Distill to create smaller, sooner fashions: Use data distillation to switch data from a bigger, extra clever mannequin, like Nova Premier (trainer) to a smaller, sooner, extra cost-efficient mannequin (pupil), superb for while you don’t have sufficient annotated coaching datasets and the trainer mannequin offers the accuracy that meets your requirement.
To have the ability to study from earlier examples, you must both have an annotated dataset from which we will study or a mannequin that’s ok on your job so as to use it as a trainer mannequin.
- Automated dataset annotation with historic knowledge from Enterprise Useful resource Planning (ERP) methods, reminiscent of SAP: Many shoppers have already historic paperwork which have been manually processed and consumed by downstream methods, like ERP or buyer relationship administration (CRM) methods. Discover current downstream methods like SAP and the information they include. This knowledge can typically be mapped again to the unique supply doc it has been derived from and lets you bootstrap an annotated dataset in a short time.
- Handbook dataset annotation: Determine essentially the most related paperwork and codecs, and annotate them utilizing human annotators, so that you’ve doc/JSON pairs the place the JSON comprises the goal data that you simply need to extract or derive out of your supply paperwork.
- Annotate with the trainer mannequin: Discover if a bigger mannequin like Nova Premier can present correct sufficient outcomes utilizing immediate engineering. If that’s the case, you too can use distillation.
For the primary and second choices, we advocate supervised mannequin fine-tuning. For the third, mannequin distillation is the precise method.
Amazon Bedrock at the moment offers each fine-tuning and distillation methods, in order that anybody with a primary knowledge science skillset can very simply submit jobs. They run on compute fully managed by Amazon, so that you don’t have fear about occasion sizes or capability limits.
Nova customization can also be obtainable with Amazon SageMaker with extra choices and controls. For instance, you probably have adequate high-quality labeled knowledge and also you need deeper customization on your use case, full rank fine-tuning would possibly produce larger accuracy. Full rank superb tuning is supported with SageMaker coaching jobs and SageMaker HyperPod.
Information preparation finest practices
The standard and construction of your coaching knowledge basically decide the success of fine-tuning. Listed below are key steps and concerns for getting ready efficient multimodal datasets and configuring your fine-tuning job:
Dataset evaluation and base mannequin analysis
Our demonstration makes use of an artificial dataset of W2 tax varieties: the Faux W-2 (US Tax Kind) Dataset. This public dataset contains simulated US tax returns (W-2 statements for years 2016-19), together with noisy pictures that mimic low-quality scanned W2 tax varieties.
Earlier than fine-tuning, it’s essential to:
- Analyze dataset traits (picture high quality, area completeness, class distribution), outline use-case-specific analysis metrics, and set up baseline mannequin efficiency.
- Examine every predicted area worth towards the bottom reality, calculating precision, recall, and F1 scores for particular person fields and general efficiency.
Immediate optimization
Crafting an efficient immediate is important for aligning the mannequin with job necessities. Our system contains two key parts:
- System immediate: Defines the duty, offers detailed directions for every area to be extracted, and specifies the output format.
- Person immediate: Follows Nova imaginative and prescient understanding finest practices, using the
{media_file}-then-{textual content}construction as outlined within the Amazon Nova mannequin consumer information.
Iterate in your prompts utilizing the bottom mannequin to optimize efficiency earlier than fine-tuning.
Dataset preparation
Put together your dataset in JSONL format and break up it into coaching, validation, and check units:
- Coaching set: 70-80% of information
- Validation set: 10-20% of information
- Check set: 10-20% of information
Advantageous-tuning job configuration and monitoring
As soon as the dataset is ready and uploaded to an Amazon Easy Storage Service (Amazon S3) bucket, we will configure and submit the fine-tuning job on Bedrock. When configuring your fine-tuning job on Amazon Bedrock, key parameters embrace:
| Parameter | Definition | Function |
|---|---|---|
| Epochs | Variety of full passes by means of the coaching dataset | Determines what number of occasions the mannequin sees your entire dataset throughout coaching |
| Studying charge | Step measurement for gradient descent optimization | Controls how a lot mannequin weights are adjusted in response to estimated error |
| Studying charge warmup steps | Variety of steps to steadily enhance the training charge | Prevents instability by slowly ramping up the training charge from a small worth to the goal charge |
Amazon Bedrock customization offers validation loss metrics all through the coaching course of. Monitor these metrics to:
- Assess mannequin convergence
- Detect potential overfitting
- Achieve early insights into mannequin efficiency on unseen knowledge
The next graph exhibits an instance metric evaluation:
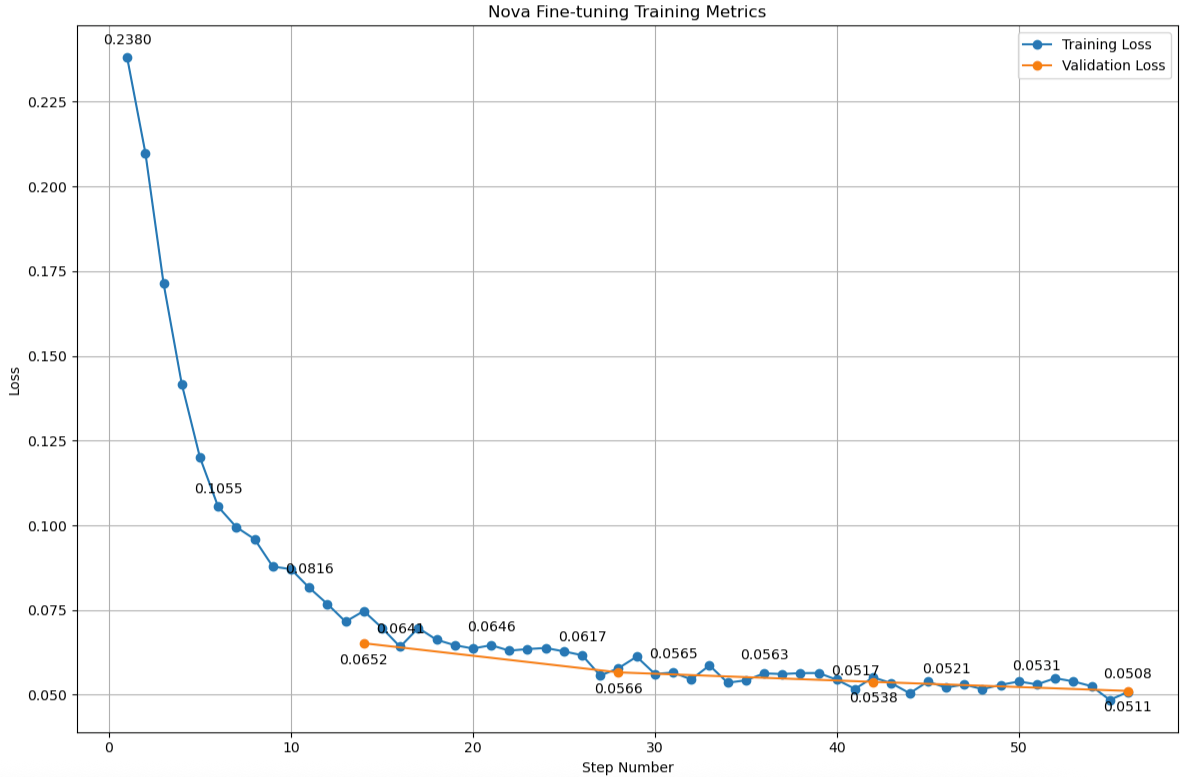
When analyzing the coaching and validation loss curves, the relative habits between these metrics offers essential insights into the mannequin’s studying dynamics. Optimum studying patterns might be noticed as:
- Each coaching and validation losses lower steadily over time
- The curves keep comparatively parallel trajectories
- The hole between coaching and validation loss stays steady
- Ultimate loss values converge to comparable ranges
Mannequin inference choices for custom-made fashions
As soon as your customized mannequin has been created in Bedrock, you’ve got two essential methods to make inferences to that mannequin: use on-demand customized mannequin inference (ODI) deployments, or use Provisioned Throughput endpoints. Let’s speak about why and when to decide on one over the opposite.
On-demand customized mannequin deployments present a versatile and cost-effective approach to leverage your customized Bedrock fashions. With on-demand deployments, you solely pay for the compute assets you utilize, primarily based on the variety of tokens processed throughout inference. This makes on-demand an important selection for workloads with variable or unpredictable utilization patterns, the place you need to keep away from over-provisioning assets. The on-demand method additionally provides computerized scaling, so that you don’t have to fret about managing infrastructure capability. Bedrock will routinely provision the mandatory compute energy to deal with your requests in close to actual time. This self-service, serverless expertise can simplify your operations and deployment workflows.
Alternatively, Provisioned Throughput endpoints are beneficial for workloads with regular visitors patterns and constant high-volume necessities, providing predictable efficiency and price advantages over on-demand scaling.
This instance makes use of the ODI choice to leverage per-token primarily based pricing; the next code snippet is how one can create an ODI endpoint on your customized mannequin:
Analysis: Accuracy enchancment with fine-tuning
Our analysis of the bottom mannequin and the fine-tuned Nova mannequin exhibits important enhancements throughout all area classes. Let’s break down the efficiency good points:
| Discipline class | Metric | Base mannequin | Advantageous-tuned mannequin | Enchancment |
| Worker data | Accuracy | 58% | 82.33% | 24.33% |
| Precision | 57.05% | 82.33% | 25.28% | |
| Recall | 100% | 100% | 0% | |
| F1 rating | 72.65% | 90.31% | 17.66% | |
| Employer data | Accuracy | 58.67% | 92.67% | 34% |
| Precision | 53.66% | 92.67% | 39.01% | |
| Recall | 100% | 100% | 0% | |
| F1 rating | 69.84% | 96.19% | 26.35% | |
| Earnings | Accuracy | 62.71% | 85.57% | 22.86% |
| Precision | 60.97% | 85.57% | 24.60% | |
| Recall | 99.55% | 100% | 0.45% | |
| F1 rating | 75.62% | 92.22% | 16.60% | |
| Advantages | Accuracy | 45.50% | 60% | 14.50% |
| Precision | 45.50% | 60% | 14.50% | |
| Recall | 93.81% | 100% | 6.19% | |
| F1 rating | 61.28% | 75% | 13.72% | |
| Multi-state employment | Accuracy | 58.29% | 94.19% | 35.90% |
| Precision | 52.14% | 91.83% | 39.69% | |
| Recall | 99.42% | 100% | 0.58% | |
| F1 rating | 68.41% | 95.74% | 27.33% |
The next graphic exhibits a bar chart evaluating the F1 scores of the bottom mannequin and fine-tuned mannequin for every area class, with the advance share proven within the earlier desk:
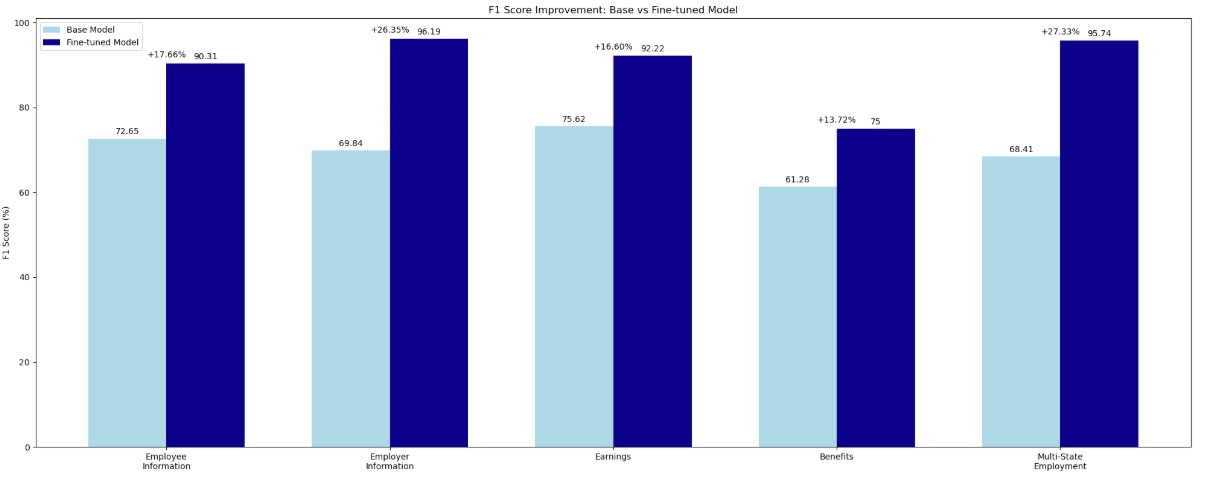
Key observations:
- Substantial enhancements throughout all classes, with essentially the most important good points in employer data and multi-state employment
- Constant 100% recall maintained or achieved within the fine-tuned mannequin, indicating complete area extraction
- Notable precision enhancements, notably in classes that had been difficult for the bottom mannequin
Clear up
To keep away from incurring pointless prices while you’re now not utilizing your customized mannequin, it’s essential to correctly clear up the assets. Observe these steps to take away each the deployment and the customized mannequin:
Price evaluation
In our instance, we selected to make use of Bedrock fine-tuning job which is PEFT and ODI is offered. PEFT superb tuning Nova Lite paired with on-demand inference capabilities provides an economical and scalable answer for enhanced doc processing. The price construction is easy and clear:
One-time price:
- Mannequin coaching: $0.002 per 1,000 tokens × variety of epochs
Ongoing prices:
- Storage: $1.95 per thirty days per customized mannequin
- On-demand Inference: Identical per-token pricing as the bottom mannequin
- Instance 1 web page from above dataset: 1895 tokens/1000 * $0.00006 + 411 tokens/1000 * $0.00024 = $0.00021
On-demand inference means that you can run your customized Nova fashions with out sustaining provisioned endpoints, enabling pay-as-you-go pricing primarily based on precise token utilization. This method eliminates the necessity for capability planning whereas making certain cost-efficient scaling.
Conclusion
On this submit, we’ve demonstrated how fine-tuning Amazon Nova Lite can rework doc processing accuracy whereas sustaining price effectivity. Our analysis exhibits important efficiency good points, with as much as 39% enchancment in precision for essential fields and excellent recall throughout key doc classes. Whereas our implementation didn’t require constrained decoding, instrument calling with Nova can present further reliability for extra advanced structured outputs, particularly when working with intricate JSON schemas. Please discuss with the useful resource on structured output with instrument calling for additional data.
The versatile deployment choices, together with on-demand inference with pay-per-use pricing, remove infrastructure overhead whereas sustaining the identical inference prices as the bottom mannequin. With the dataset we used for this instance, runtime inference per web page price was $0.00021, making it an economical answer. Via sensible examples and step-by-step guides, we’ve proven tips on how to put together coaching knowledge, fine-tune fashions, and consider efficiency with clear metrics.
To get began with your individual implementation, go to our GitHub repository for full code samples and detailed documentation.
In regards to the authors
 Sharon Li is an AI/ML Specialist Options Architect at Amazon Internet Companies (AWS) primarily based in Boston, Massachusetts. With a ardour for leveraging cutting-edge know-how, Sharon is on the forefront of growing and deploying revolutionary generative AI options on the AWS cloud platform.
Sharon Li is an AI/ML Specialist Options Architect at Amazon Internet Companies (AWS) primarily based in Boston, Massachusetts. With a ardour for leveraging cutting-edge know-how, Sharon is on the forefront of growing and deploying revolutionary generative AI options on the AWS cloud platform.
 Arlind Nocaj is a GTM Specialist Options Architect for AI/ML and Generative AI for europe central primarily based in AWS Zurich Workplace, who guides enterprise clients by means of their digital transformation journeys. With a PhD in community analytics and visualization (Graph Drawing) and over a decade of expertise as a analysis scientist and software program engineer, he brings a novel mix of educational rigor and sensible experience to his function. His major focus lies in utilizing the total potential of information, algorithms, and cloud applied sciences to drive innovation and effectivity. His areas of experience embrace Machine Studying, Generative AI and specifically Agentic methods with Multi-modal LLMs for doc processing and structured insights.
Arlind Nocaj is a GTM Specialist Options Architect for AI/ML and Generative AI for europe central primarily based in AWS Zurich Workplace, who guides enterprise clients by means of their digital transformation journeys. With a PhD in community analytics and visualization (Graph Drawing) and over a decade of expertise as a analysis scientist and software program engineer, he brings a novel mix of educational rigor and sensible experience to his function. His major focus lies in utilizing the total potential of information, algorithms, and cloud applied sciences to drive innovation and effectivity. His areas of experience embrace Machine Studying, Generative AI and specifically Agentic methods with Multi-modal LLMs for doc processing and structured insights.
 Pat Reilly is a Sr. Specialist Options Architect on the Amazon Bedrock Go-to-Market crew. Pat has spent the final 15 years in analytics and machine studying as a marketing consultant. When he’s not constructing on AWS, you’ll find him fumbling round with wooden tasks.
Pat Reilly is a Sr. Specialist Options Architect on the Amazon Bedrock Go-to-Market crew. Pat has spent the final 15 years in analytics and machine studying as a marketing consultant. When he’s not constructing on AWS, you’ll find him fumbling round with wooden tasks.
 Malte Reimann is a Options Architect primarily based in Zurich, working with clients throughout Switzerland and Austria on their cloud initiatives. His focus lies in sensible machine studying purposes—from immediate optimization to fine-tuning imaginative and prescient language fashions for doc processing. The latest instance, working in a small crew to offer deployment choices for Apertus on AWS. An lively member of the ML group, Malte balances his technical work with a disciplined method to health, preferring early morning gymnasium periods when it’s empty. Throughout summer time weekends, he explores the Swiss Alps on foot and having fun with time in nature. His method to each know-how and life is easy: constant enchancment by means of deliberate follow, whether or not that’s optimizing a buyer’s cloud deployment or getting ready for the following hike within the clouds.
Malte Reimann is a Options Architect primarily based in Zurich, working with clients throughout Switzerland and Austria on their cloud initiatives. His focus lies in sensible machine studying purposes—from immediate optimization to fine-tuning imaginative and prescient language fashions for doc processing. The latest instance, working in a small crew to offer deployment choices for Apertus on AWS. An lively member of the ML group, Malte balances his technical work with a disciplined method to health, preferring early morning gymnasium periods when it’s empty. Throughout summer time weekends, he explores the Swiss Alps on foot and having fun with time in nature. His method to each know-how and life is easy: constant enchancment by means of deliberate follow, whether or not that’s optimizing a buyer’s cloud deployment or getting ready for the following hike within the clouds.



{kind=link}