In manufacturing generative AI functions, responsiveness is simply as essential because the intelligence behind the mannequin. Whether or not it’s customer support groups dealing with time-sensitive inquiries or builders needing instantaneous code recommendations, each second of delay, generally known as latency, can have a major affect. As companies more and more use massive language fashions (LLMs) for these important duties and processes, they face a elementary problem: preserve the short, responsive efficiency customers anticipate whereas delivering the high-quality outputs these refined fashions promise.
The affect of latency on consumer expertise extends past mere inconvenience. In interactive AI functions, delayed responses can break the pure circulate of dialog, diminish consumer engagement, and finally have an effect on the adoption of AI-powered options. This problem is compounded by the growing complexity of recent LLM functions, the place a number of LLM calls are sometimes wanted to resolve a single drawback, considerably growing complete processing instances.
Throughout re:Invent 2024, we launched latency-optimized inference for basis fashions (FMs) in Amazon Bedrock. This new inference characteristic gives lowered latency for Anthropic’s Claude 3.5 Haiku mannequin and Meta’s Llama 3.1 405B and 70B fashions in comparison with their customary variations. This characteristic is very useful for time-sensitive workloads the place speedy response is enterprise important.
On this publish, we discover how Amazon Bedrock latency-optimized inference may also help deal with the challenges of sustaining responsiveness in LLM functions. We’ll dive deep into methods for optimizing utility efficiency and enhancing consumer expertise. Whether or not you’re constructing a brand new AI utility or optimizing an present one, you’ll discover sensible steerage on each the technical features of latency optimization and real-world implementation approaches. We start by explaining latency in LLM functions.
Understanding latency in LLM functions
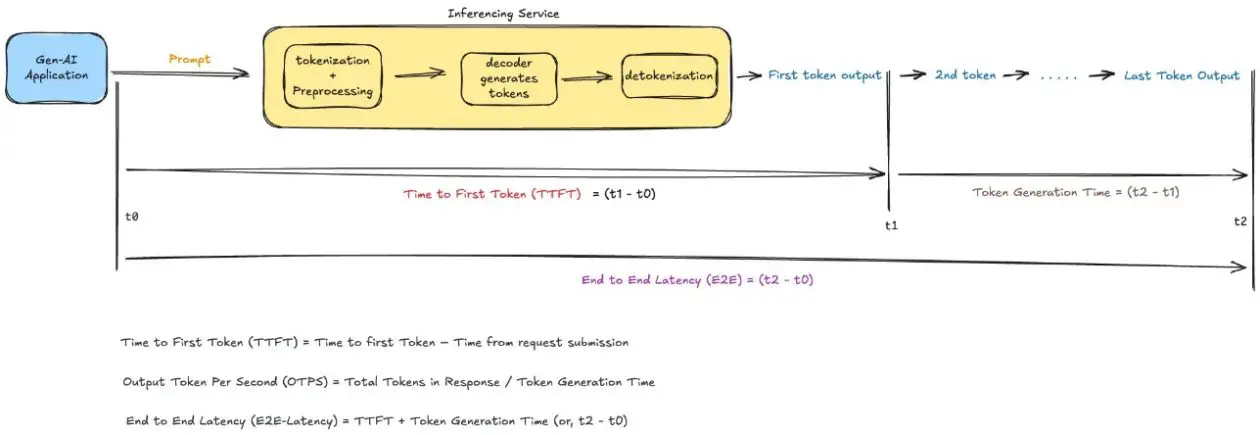
Latency in LLM functions is a multifaceted idea that goes past easy response instances. Whenever you work together with an LLM, you’ll be able to obtain responses in considered one of two methods: streaming or nonstreaming mode. In nonstreaming mode, you await the whole response earlier than receiving any output—like ready for somebody to complete writing a letter. In streaming mode, you obtain the response because it’s being generated—like watching somebody sort in actual time.
To successfully optimize AI functions for responsiveness, we have to perceive the important thing metrics that outline latency and the way they affect consumer expertise. These metrics differ between streaming and nonstreaming modes and understanding them is essential for constructing responsive AI functions.
Time to first token (TTFT) represents how rapidly your streaming utility begins responding. It’s the period of time from when a consumer submits a request till they obtain the start of a response (the primary phrase, token, or chunk). Consider it because the preliminary response time of your AI utility.
TTFT is affected by a number of elements:
- Size of your enter immediate (longer prompts usually imply greater TTFT)
- Community circumstances and geographic location (if the immediate is getting processed in a special area, it is going to take longer)
Calculation: TTFT = Time to first chunk/token – Time from request submission
Interpretation: Decrease is healthier
Output tokens per second (OTPS) signifies how rapidly your mannequin generates new tokens after it begins responding. This metric is essential for understanding the precise throughput of your mannequin and the way it maintains its response pace all through longer generations.
OTPS is influenced by:
- Mannequin dimension and complexity
- Size of the generated response
- Complexity of the duty and immediate
- System load and useful resource availability
Calculation: OTPS = Complete variety of output tokens / Complete technology time
Interpretation: Larger is healthier
Finish-to-end latency (E2E) measures the entire time from request to finish response. As illustrated within the determine above, this encompasses your entire interplay.
Key elements affecting this metric embody:
- Enter immediate size
- Requested output size
- Mannequin processing pace
- Community circumstances
- Complexity of the duty and immediate
- Postprocessing necessities (for instance, utilizing Amazon Bedrock Guardrails or different high quality checks)
Calculation: E2E latency = Time at completion of request – Time from request submission
Interpretation: Decrease is healthier
Though these metrics present a strong basis for understanding latency, there are extra elements and issues that may affect the perceived efficiency of LLM functions. These metrics are proven within the following diagram.

The position of tokenization
An often-overlooked side of latency is how completely different fashions tokenize textual content in a different way. Every mannequin’s tokenization technique is outlined by its supplier throughout coaching and may’t be modified. For instance, a immediate that generates 100 tokens in a single mannequin may generate 150 tokens in one other. When evaluating mannequin efficiency, do not forget that these inherent tokenization variations can have an effect on perceived response instances, even when the fashions are equally environment friendly. Consciousness of this variation may also help you higher interpret latency variations between fashions and make extra knowledgeable choices when choosing fashions in your functions.
Understanding consumer expertise
The psychology of ready in AI functions reveals attention-grabbing patterns about consumer expectations and satisfaction. Customers are likely to understand response instances in a different way primarily based on the context and complexity of their requests. A slight delay in producing a posh evaluation may be acceptable, and even a small lag in a conversational alternate can really feel disruptive. This understanding helps us set applicable optimization priorities for several types of functions.
Consistency over pace
Constant response instances, even when barely slower, usually result in higher consumer satisfaction than extremely variable response instances with occasional fast replies. That is essential for streaming responses and implementing optimization methods.
Holding customers engaged
When processing instances are longer, easy indicators resembling “Processing your request” or “loading animations” messages assist hold customers engaged, particularly through the preliminary response time. In such eventualities, you need to optimize for TTFT.
Balancing pace, high quality, and price
Output high quality usually issues greater than pace. Customers favor correct responses over fast however much less dependable ones. Take into account benchmarking your consumer expertise to seek out the perfect latency in your use case, contemplating that almost all people can’t learn quicker than 225 phrases per minute and due to this fact extraordinarily quick response can hinder consumer expertise.
By understanding these nuances, you can also make extra knowledgeable choices to optimize your AI functions for higher consumer expertise.
Latency-optimized inference: A deep dive
Amazon Bedrock latency-optimized inference capabilities are designed to supply greater OTPS and faster TTFT, enabling functions to deal with workloads extra reliably. This optimization is accessible within the US East (Ohio) AWS Area for choose FMs, together with Anthropic’s Claude 3.5 Haiku and Meta’s Llama 3.1 fashions (each 405B and 70B variations). The optimization helps the next fashions:
- Larger OTPS – Quicker token technology after the mannequin begins responding
- Faster TTFT – Quicker preliminary response time
Implementation
To allow latency optimization, you might want to set the latency parameter to optimized in your API calls:
Benchmarking methodology and outcomes
To know the efficiency positive aspects each for TTFT and OTPS, we performed an offline experiment with round 1,600 API calls unfold throughout numerous hours of the day and throughout a number of days. We used a dummy dataset comprising completely different job varieties: sequence-counting, story-writing, summarization, and translation. The enter immediate ranged from 100 tokens to 100,000 tokens, and the output tokens ranged from 100 to 1,000 output tokens. These duties have been chosen to symbolize various complexity ranges and numerous mannequin output lengths. Our take a look at setup was hosted within the US West (Oregon) us-west-2 Area, and each the optimized and customary fashions have been hosted in US East (Ohio) us-east-2 Area. This cross-Area setup launched reasonable community variability, serving to us measure efficiency underneath circumstances just like real-world functions.
When analyzing the outcomes, we targeted on the important thing latency metrics mentioned earlier: TTFT and OTPS. As a fast recap, decrease TTFT values point out quicker preliminary response instances, and better OTPS values symbolize quicker token technology speeds. We additionally appeared on the fiftieth percentile (P50) and ninetieth percentile (P90) values to know each typical efficiency and efficiency boundaries underneath difficult or higher certain circumstances. Following the central restrict theorem, we noticed that, with enough samples, our outcomes converged towards constant values, offering dependable efficiency indicators.
It’s essential to notice that these outcomes are from our particular take a look at surroundings and datasets. Your precise outcomes could range primarily based in your particular use case, immediate size, anticipated mannequin response size, community circumstances, consumer location, and different implementation parts. When conducting your individual benchmarks, be certain that your take a look at dataset represents your precise manufacturing workload traits, together with typical enter lengths and anticipated output patterns.
Benchmark outcomes
Our experiments with the latency-optimized fashions revealed substantial efficiency enhancements throughout each TTFT and OTPS metrics. The ends in the next desk present the comparability between customary and optimized variations of Anthropic’s Claude 3.5 Haiku and Meta’s Llama 3.1 70B fashions. For every mannequin, we ran a number of iterations of our take a look at eventualities to advertise dependable efficiency. The enhancements have been significantly notable in high-percentile measurements, suggesting extra constant efficiency even underneath difficult circumstances.
| Mannequin | Inference profile | TTFT P50 (in seconds) | TTFT P90 (in seconds) | OTPS P50 | OTPS P90 |
| us.anthropic.claude-3-5-haiku-20241022-v1:0 | Optimized | 0.6 | 1.4 | 85.9 | 152.0 |
| us.anthropic.claude-3-5-haiku-20241022-v1:0 | Normal | 1.1 | 2.9 | 48.4 | 67.4 |
| Enchancment | -42.20% | -51.70% | 77.34% | 125.50% | |
| us.meta.llama3-1-70b-instruct-v1:0 | Optimized | 0.4 | 1.2 | 137.0 | 203.7 |
| us.meta.llama3-1-70b-instruct-v1:0 | Normal | 0.9 | 42.8 | 30.2 | 32.4 |
| Enchancment | -51.65% | -97.10% | 353.84% | 529.33% |
These outcomes exhibit vital enhancements throughout all metrics for each fashions. For Anthropic’s Claude 3.5 Haiku mannequin, the optimized model achieved as much as 42.20% discount in TTFT P50 and as much as 51.70% discount in TTFT P90, indicating extra constant preliminary response instances. Moreover, the OTPS noticed enhancements of as much as 77.34% on the P50 stage and as much as 125.50% on the P90 stage, enabling quicker token technology.
The positive aspects for Meta’s Llama 3.1 70B mannequin are much more spectacular, with the optimized model attaining as much as 51.65% discount in TTFT P50 and as much as 97.10% discount in TTFT P90, offering persistently speedy preliminary responses. Moreover, the OTPS noticed a large increase, with enhancements of as much as 353.84% on the P50 stage and as much as 529.33% on the P90 stage, enabling as much as 5x quicker token technology in some eventualities.
Though these benchmark outcomes present the highly effective affect of latency-optimized inference, they symbolize only one piece of the optimization puzzle. To make greatest use of those efficiency enhancements and obtain the absolute best response instances in your particular use case, you’ll want to think about extra optimization methods past merely enabling the characteristic.
Complete information to LLM latency optimization
Despite the fact that Amazon Bedrock latency-optimized inference presents nice enhancements from the beginning, getting the perfect efficiency requires a well-rounded strategy to designing and implementing your utility. Within the subsequent part, we discover another methods and issues to make your utility as responsive as doable.
Immediate engineering for latency optimization
When optimizing LLM functions for latency, the best way you craft your prompts impacts each enter processing and output technology.
To optimize your enter prompts, comply with these suggestions:
- Maintain prompts concise – Lengthy enter prompts take extra time to course of and enhance TTFT. Create brief, targeted prompts that prioritize vital context and knowledge.
- Break down advanced duties – As an alternative of dealing with massive duties in a single request, break them into smaller, manageable chunks. This strategy helps preserve responsiveness no matter job complexity.
- Good context administration – For interactive functions resembling chatbots, embody solely related context as an alternative of whole dialog historical past.
- Token administration – Totally different fashions tokenize textual content in a different way, that means the identical enter may end up in completely different numbers of tokens. Monitor and optimize token utilization to maintain efficiency constant. Use token budgeting to stability context preservation with efficiency wants.
To engineer for temporary outputs, comply with these suggestions:
- Engineer for brevity – Embrace express size constraints in your prompts (for instance, “reply in 50 phrases or much less”)
- Use system messages – Set response size constraints by way of system messages
- Stability high quality and size – Make sure that response constraints don’t compromise output high quality
Among the best methods to make your AI utility really feel quicker is to make use of streaming. As an alternative of ready for the whole response, streaming exhibits the response because it’s being generated—like watching somebody sort in real-time. Streaming the response is without doubt one of the simplest methods to enhance perceived efficiency in LLM functions sustaining consumer engagement.
These strategies can considerably cut back token utilization and technology time, enhancing each latency and cost-efficiency.
Constructing production-ready AI functions
Though particular person optimizations are essential, manufacturing functions require a holistic strategy to latency administration. On this part, we discover how completely different system parts and architectural choices affect total utility responsiveness.
System structure and end-to-end latency issues
In manufacturing environments, total system latency extends far past mannequin inference time. Every element in your AI utility stack contributes to the entire latency skilled by customers. As an illustration, when implementing accountable AI practices by way of Amazon Bedrock Guardrails, you may discover a small extra latency overhead. Related issues apply when integrating content material filtering, consumer authentication, or enter validation layers. Though every element serves an important objective, their cumulative affect on latency requires cautious consideration throughout system design.
Geographic distribution performs a major position in utility efficiency. Mannequin invocation latency can range significantly relying on whether or not calls originate from completely different Areas, native machines, or completely different cloud suppliers. This variation stems from information journey time throughout networks and geographic distances. When designing your utility structure, contemplate elements such because the bodily distance between your utility and mannequin endpoints, cross-Area information switch instances, and community reliability in several Areas. Information residency necessities may also affect these architectural decisions, probably necessitating particular Regional deployments.
Integration patterns considerably affect how customers understand utility efficiency. Synchronous processing, though less complicated to implement, won’t all the time present the perfect consumer expertise. Take into account implementing asynchronous patterns the place applicable, resembling pre-fetching doubtless responses primarily based on consumer habits patterns or processing noncritical parts within the background. Request batching for bulk operations also can assist optimize total system throughput, although it requires cautious stability with response time necessities.
As functions scale, extra infrastructure parts turn into vital however can affect latency. Load balancers, queue techniques, cache layers, and monitoring techniques all contribute to the general latency funds. Understanding these parts’ affect helps in making knowledgeable choices about infrastructure design and optimization methods.
Complicated duties usually require orchestrating a number of mannequin calls or breaking down issues into subtasks. Take into account a content material technology system that first makes use of a quick mannequin to generate a top level view, then processes completely different sections in parallel, and at last makes use of one other mannequin for coherence checking and refinement. This orchestration strategy requires cautious consideration to cumulative latency affect whereas sustaining output high quality. Every step wants applicable timeouts and fallback mechanisms to supply dependable efficiency underneath numerous circumstances.
Immediate caching for enhanced efficiency
Though our focus is on latency-optimized inference, it’s value noting that Amazon Bedrock additionally presents immediate caching (in preview) to optimize for each value and latency. This characteristic is especially worthwhile for functions that ceaselessly reuse context, resembling document-based chat assistants or functions with repetitive question patterns. When mixed with latency-optimized inference, immediate caching can present extra efficiency advantages by decreasing the processing overhead for ceaselessly used contexts.
Immediate routing for clever mannequin choice
Just like immediate caching, Amazon Bedrock Clever Immediate Routing (in preview) is one other highly effective optimization characteristic. This functionality mechanically directs requests to completely different fashions throughout the similar mannequin household primarily based on the complexity of every immediate. For instance, easy queries may be routed to quicker, more cost effective fashions, and sophisticated requests that require deeper understanding are directed to extra refined fashions. This automated routing helps optimize each efficiency and price with out requiring guide intervention.
Architectural issues and caching
Utility structure performs an important position in total latency optimization. Take into account implementing a multitiered caching technique that features response caching for ceaselessly requested data and sensible context administration for historic data. This isn’t solely about storing actual matches—contemplate implementing semantic caching that may establish and serve responses to related queries.
Balancing mannequin sophistication, latency, and price
In AI functions, there’s a continuing balancing act between mannequin sophistication, latency, and price, as illustrated within the diagram. Though extra superior fashions usually present greater high quality outputs, they won’t all the time meet strict latency necessities. In such instances, utilizing a much less refined however quicker mannequin may be the higher selection. As an illustration, in functions requiring near-instantaneous responses, choosing a smaller, extra environment friendly mannequin could possibly be vital to fulfill latency objectives, even when it means a slight trade-off in output high quality. This strategy aligns with the broader have to optimize the interaction between value, pace, and high quality in AI techniques.

Options resembling Amazon Bedrock Clever Immediate Routing assist handle this stability successfully. By mechanically dealing with mannequin choice primarily based on request complexity, you’ll be able to optimize for all three elements—high quality, pace, and price—with out requiring builders to decide to a single mannequin for all requests.
As we’ve explored all through this publish, optimizing LLM utility latency entails a number of methods, from utilizing latency-optimized inference and immediate caching to implementing clever routing and cautious immediate engineering. The hot button is to mix these approaches in a approach that most accurately fits your particular use case and necessities.
Conclusion
Making your AI utility quick and responsive isn’t a one-time job, it’s an ongoing strategy of testing and enchancment. Amazon Bedrock latency-optimized inference offers you an awesome place to begin, and also you’ll discover vital enhancements if you mix it with the methods we’ve mentioned.
Able to get began? Right here’s what to do subsequent:
- Attempt our pattern pocket book to benchmark latency in your particular use case
- Allow latency-optimized inference in your utility code
- Arrange Amazon CloudWatch metrics to watch your utility’s efficiency
Bear in mind, in as we speak’s AI functions, being sensible isn’t sufficient, being responsive is simply as essential. Begin implementing these optimization methods as we speak and watch your utility’s efficiency enhance.
In regards to the Authors
 Ishan Singh is a Generative AI Information Scientist at Amazon Net Companies, the place he helps clients construct progressive and accountable generative AI options and merchandise. With a powerful background in AI/ML, Ishan makes a speciality of constructing Generative AI options that drive enterprise worth. Outdoors of labor, he enjoys enjoying volleyball, exploring native bike trails, and spending time along with his spouse and canine, Beau.
Ishan Singh is a Generative AI Information Scientist at Amazon Net Companies, the place he helps clients construct progressive and accountable generative AI options and merchandise. With a powerful background in AI/ML, Ishan makes a speciality of constructing Generative AI options that drive enterprise worth. Outdoors of labor, he enjoys enjoying volleyball, exploring native bike trails, and spending time along with his spouse and canine, Beau.
 Yanyan Zhang is a Senior Generative AI Information Scientist at Amazon Net Companies, the place she has been engaged on cutting-edge AI/ML applied sciences as a Generative AI Specialist, serving to clients use generative AI to attain their desired outcomes. Yanyan graduated from Texas A&M College with a PhD in Electrical Engineering. Outdoors of labor, she loves touring, figuring out, and exploring new issues.
Yanyan Zhang is a Senior Generative AI Information Scientist at Amazon Net Companies, the place she has been engaged on cutting-edge AI/ML applied sciences as a Generative AI Specialist, serving to clients use generative AI to attain their desired outcomes. Yanyan graduated from Texas A&M College with a PhD in Electrical Engineering. Outdoors of labor, she loves touring, figuring out, and exploring new issues.
 Rupinder Grewal is a Senior AI/ML Specialist Options Architect with AWS. He presently focuses on serving of fashions and MLOps on Amazon SageMaker. Previous to this position, he labored as a Machine Studying Engineer constructing and internet hosting fashions. Outdoors of labor, he enjoys enjoying tennis and biking on mountain trails.
Rupinder Grewal is a Senior AI/ML Specialist Options Architect with AWS. He presently focuses on serving of fashions and MLOps on Amazon SageMaker. Previous to this position, he labored as a Machine Studying Engineer constructing and internet hosting fashions. Outdoors of labor, he enjoys enjoying tennis and biking on mountain trails.
 Vivek Singh is a Senior Supervisor, Product Administration at AWS AI Language Companies crew. He leads the Amazon Transcribe product crew. Previous to becoming a member of AWS, he held product administration roles throughout numerous different Amazon organizations resembling client funds and retail. Vivek lives in Seattle, WA and enjoys working, and mountain climbing.
Vivek Singh is a Senior Supervisor, Product Administration at AWS AI Language Companies crew. He leads the Amazon Transcribe product crew. Previous to becoming a member of AWS, he held product administration roles throughout numerous different Amazon organizations resembling client funds and retail. Vivek lives in Seattle, WA and enjoys working, and mountain climbing.
 Ankur Desai is a Principal Product Supervisor throughout the AWS AI Companies crew.
Ankur Desai is a Principal Product Supervisor throughout the AWS AI Companies crew.



{kind=link}