
Optimizing fashions for video semantic search requires balancing accuracy, value, and latency. Quicker, smaller fashions lack routing intelligence, whereas bigger, correct fashions add important latency overhead. In Half 1 of this collection, we confirmed the way to construct a multimodal video semantic search system on AWS with clever intent routing utilizing the Anthropic Claude Haiku mannequin in Amazon Bedrock. Whereas the Haiku mannequin delivers robust accuracy for consumer search intent, it will increase end-to-end search time to 2-4 seconds. This contributes to 75% of the general latency.
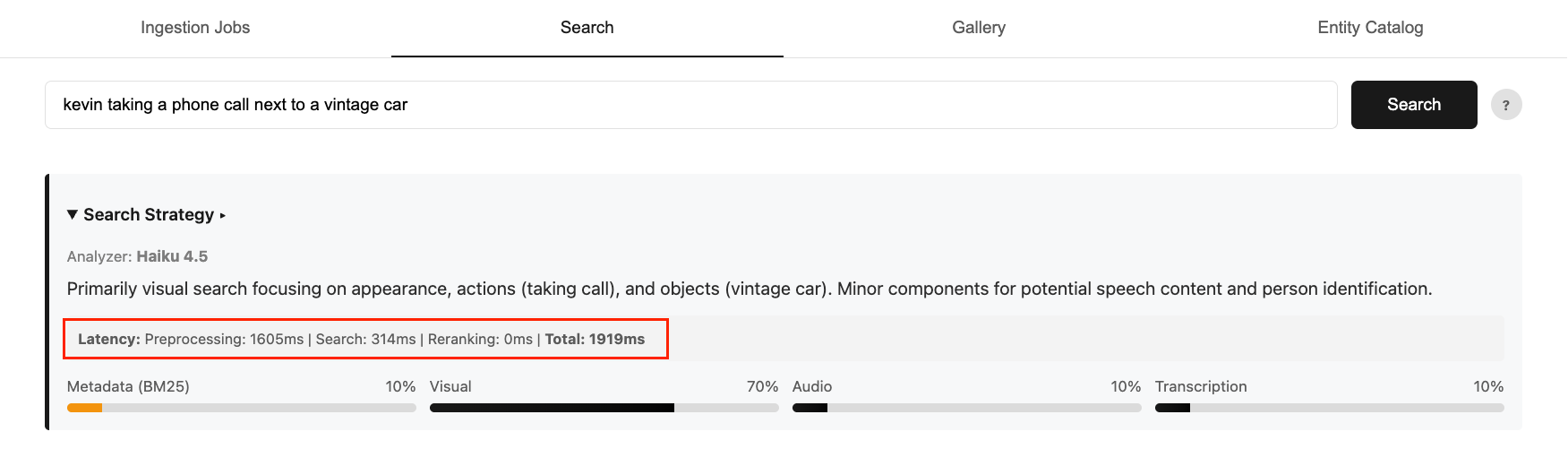
Determine 1: An instance end-to-end question latency breakdown
Now take into account what occurs because the routing logic grows extra advanced. Enterprise metadata might be much more advanced than the 5 attributes in our instance (title, caption, folks, style, and timestamp). Clients might think about digicam angles, temper and sentiment, licensing and rights home windows, and extra domain-specific taxonomies. Extra nuanced logic means a extra demanding immediate, and a extra demanding immediate results in costlier and slower responses. That is the place mannequin customization is available in. Slightly than selecting between a mannequin that’s quick however too easy or one which’s correct however too costly or too gradual, we are able to obtain all three by coaching a small mannequin to carry out the duty precisely at a lot decrease latency and price.
On this publish, we present you the way to use Mannequin Distillation, a mannequin customization approach on Amazon Bedrock, to switch routing intelligence from a big trainer mannequin (Amazon Nova Premier) right into a a lot smaller pupil mannequin (Amazon Nova Micro). This method cuts inference value by over 95% and reduces latency by 50% whereas sustaining the nuanced routing high quality that the duty calls for.
Answer overview
We’ll stroll by the complete distillation pipeline finish to finish in a Jupyter pocket book. At a excessive degree, the pocket book incorporates the next steps:
- Put together coaching information — 10,000 artificial labeled examples utilizing Nova Premier and add the dataset to Amazon Easy Storage Service (Amazon S3) in Bedrock distillation format
- Run distillation coaching job — Configure the job with trainer and pupil mannequin identifiers and submit through Amazon Bedrock
- Deploy the distilled mannequin — Deploy the customized mannequin utilizing on-demand inference for versatile, pay-per-use entry
- Consider the distilled mannequin — Evaluate routing high quality towards the bottom Nova Micro and the unique Claude Haiku baseline utilizing Amazon Bedrock Mannequin Analysis
The entire pocket book, coaching information technology script, and analysis utilities can be found within the GitHub repository.
Put together coaching information
One of many key causes we selected mannequin distillation over different customization methods like supervised fine-tuning (SFT) is that it doesn’t require a totally labeled dataset. With SFT, each coaching instance wants a human-generated response as floor fact. With distillation, you solely want prompts. Amazon Bedrock mechanically invokes the trainer mannequin to generate high-quality responses. It applies information synthesis and augmentation methods behind the scenes to supply a various coaching dataset of as much as 15,000 prompt-response pairs.
That stated, you’ll be able to optionally present a labeled dataset if you would like extra management over the coaching sign. Every report within the JSONL file follows the bedrock-conversation-2024 schema, the place the consumer function (the enter immediate) is required, and the assistant function (the specified response) is non-obligatory. See the next examples, and reference Put together your coaching datasets for distillation for extra element:
For this publish, we ready 10,000 artificial labeled examples utilizing Nova Premier, the biggest and most succesful mannequin within the Nova household. The info was generated with a balanced distribution throughout visible, audio, transcription, and metadata sign queries, The examples cowl the complete vary of anticipated search inputs, signify completely different issue ranges, embody edge instances and variations, and forestall overfitting to slim question patterns. The next chart reveals the load distribution throughout the 4 modality channels.
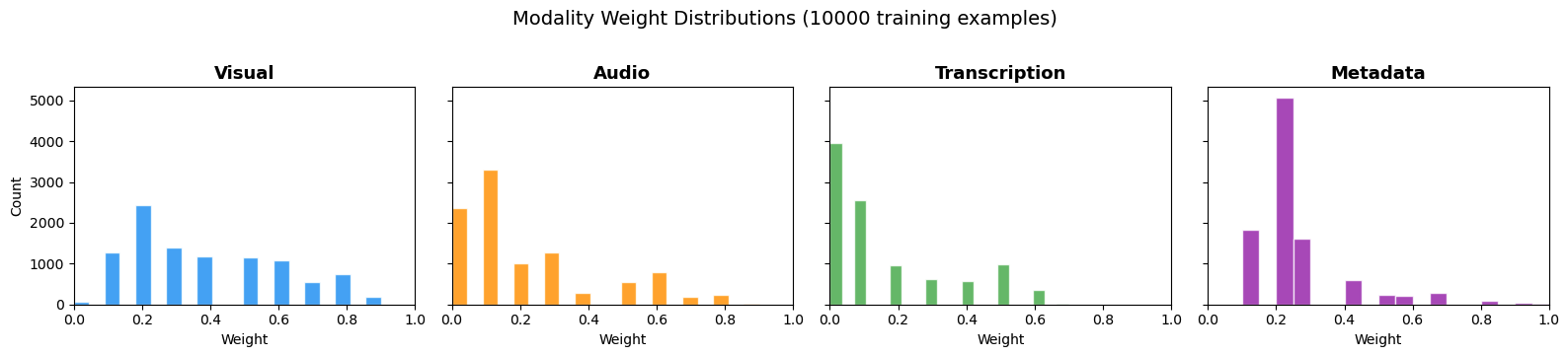
Determine 2: The burden distribution throughout the ten,000 coaching examples
If you happen to want further examples or need to adapt the question distribution to your individual content material area, the supplied generate_training_data.py script can be utilized to synthetically generate extra coaching information utilizing Nova Premier.
Run distillation coaching job
With the coaching information uploaded to Amazon S3, the subsequent step is to submit the distillation job. Mannequin distillation works through the use of your prompts to first generate responses from the trainer mannequin. It then makes use of these prompt-response pairs to fine-tune the pupil mannequin. On this challenge, the trainer is Amazon Nova Premier and the coed is Amazon Nova Micro, a quick, cost-efficient mannequin optimized for high-throughput inference. The trainer’s routing selections change into the coaching sign that shapes the coed’s conduct.
Amazon Bedrock manages the complete coaching orchestration and infrastructure mechanically. There isn’t any cluster provisioning, no hyperparameter tuning, and no teacher-to-student mannequin pipeline setup required. You specify the trainer mannequin, the coed mannequin, the S3 path to your coaching information, and an AWS Identification and Entry Administration (IAM) function with the mandatory permissions. Bedrock handles the remaining. The next is an instance code snippet to set off the distillation coaching job:
The job runs asynchronously. You possibly can monitor progress within the Amazon Bedrock console beneath Basis fashions > Customized fashions, or programmatically:
standing = bedrock_client.get_model_customization_job(
jobIdentifier=job_arn)['status']
print(f"Job standing: {standing}") # Coaching, Full, or FailedCoaching time varies relying on the dataset dimension and the coed mannequin chosen. For 10,000 labeled examples with Nova Micro, anticipate the job to finish inside just a few hours.
Deploy the distilled mannequin
As soon as the distillation job is full, the customized mannequin is out there in your Amazon Bedrock account and able to deploy. Amazon Bedrock affords two deployment choices for customized fashions: Provisioned Throughput for predictable, high-volume workloads, and On-Demand Inference for versatile, pay-per-use entry with no upfront dedication.
For many groups getting began, on-demand inference is the beneficial path. There isn’t any endpoint to provision, no hourly dedication, and no minimal utilization requirement. The next is the deployment code:
As soon as the standing reveals InService, you can invoke the distilled mannequin precisely as you’d every other base mannequin utilizing the usual InvokeModel or Converse API. You pay just for the tokens you eat at Nova Micro inference charges: $0.000035 per 1,000 enter tokens and $0.000140 per 1,000 output tokens.
Consider the distilled mannequin
Earlier than evaluating towards the unique router, it’s price validating that distillation improved the bottom mannequin’s means to observe the routing activity. The next desk reveals the identical immediate run by base Nova Micro and the distilled Nova Micro facet by facet.
| Question | Distilled Nova Micro | Base Nova Micro |
"CEO discussing quarterly earnings " |
{"visible": 0.2, "audio": 0.3, "transcription": 0.4, "metadata": 0.1, "reasoning": "The question focuses on spoken content material (transcription) about earnings, however visible cues (CEO's look) and audio (tone/readability) are additionally vital..."} |
Right here’s a JSON illustration of the data you requested for a video search question a couple of CEO discussing quarterly earnings:
|
"sundown over mountains" |
{"visible": 0.8, "audio": 0.0, "transcription": 0.0, "metadata": 0.2, "reasoning": "The question focuses on a visible scene (sundown over mountains), with no audio or transcription parts. Metadata may embody location or time-related tags."} |
Right here’s a JSON illustration for a video search question “sundown over mountains” that features visible, audio, transcription, metadata weights (sum=1.0), and reasoning:
|
The base model struggles with both instructions and output format consistency. It produces free-text responses, incomplete JSON, and non-numeric weight values. The distilled model consistently returns well-formed JSON with four numeric weights that sum to 1.0, matching the schema required by the routing pipeline.
Comparing against the original Claude Haiku router, both models are evaluated against a held-out set of 100 labeled examples generated by Nova Premier. We use Amazon Bedrock Model Evaluation to run the comparison in a structured, managed workflow. To assess routing quality beyond standard metrics, we defined a custom OverallQuality rubric (see the following code block) that instructs Claude Sonnet to score each prediction on two dimensions: weight accuracy against ground truth and reasoning quality. Each dimension maps to a concrete 5-point threshold, so the rubric penalizes both numerical drift and generic boilerplate reasoning.
The distilled Nova Micro mannequin achieved a big language mannequin (LLM)-as-judge rating of 4.0 out of 5, near-identical routing high quality to Claude 4.5 Haiku at roughly half the latency (833ms vs. 1,741ms). The price benefit is equally important. Switching to the distilled Nova Micro mannequin reduces inference prices by over 95% on each enter and output tokens, with no upfront commitments beneath on-demand pricing. Observe: LLM-as-judge analysis is non-deterministic. Scores might differ barely throughout runs.
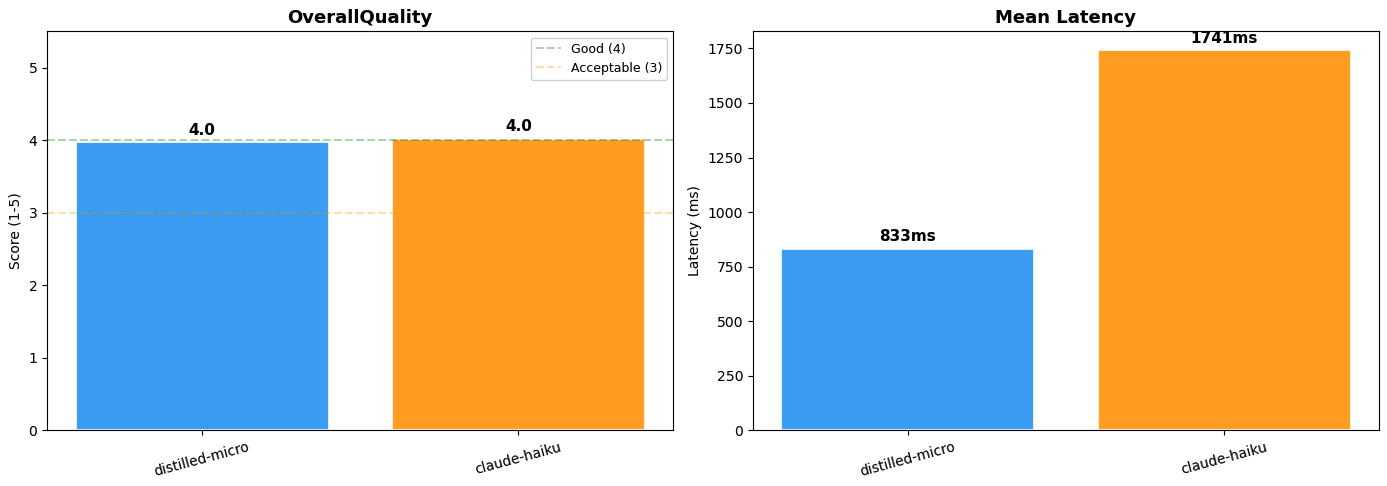
Determine 3: Mannequin efficiency comparability (Distilled Nova Micro vs. Claude 4.5 Haiku)
The next is a desk abstract of side-by-side outcomes:
| Metric | Distilled Nova Micro | Claude 4.5 Haiku |
| LLM-as-judge Rating | 4.0 / 5 | 4.0 / 5 |
| Imply Latency | 833ms | 1,741ms |
| Enter Token Price | $0.000035 / 1K | $0.80–$1.00 / 1K |
| Output Token Price | $0.000140 / 1K | $4.00–$5.00 / 1K |
| Output Format | Constant JSON | Inconsistent |
Clear up
To keep away from ongoing prices, run the cleanup part of the pocket book to take away any provisioned assets, together with deployed mannequin endpoints and any information saved in Amazon S3.
Conclusion
This publish is the second a part of a two-part collection. Constructing on Half 1, this publish focuses on making use of mannequin distillation to optimize the intent routing layer constructed within the video semantic search resolution. The methods mentioned assist deal with actual manufacturing tradeoffs, akin to balancing routing intelligence with latency and price at scale whereas sustaining search accuracy. By distilling Amazon Nova Premier’s routing conduct into Amazon Nova Micro utilizing Amazon Bedrock Mannequin Distillation, we decreased inference value by over 95% and minimize preprocessing latency in half whereas preserving the nuanced routing high quality that the duty calls for. In case you are working multimodal video search at scale, mannequin distillation is a sensible path to production-grade value effectivity with out sacrificing search accuracy. To discover the complete implementation, go to the GitHub repository and check out the answer your self.
Concerning the authors



{kind=link}