This weblog put up is co-written with Moran Beladev, Manos Stergiadis, and Ilya Gusev from Reserving.com.
Massive language fashions (LLMs) have revolutionized the sphere of pure language processing with their potential to know and generate humanlike textual content. Skilled on broad, generic datasets spanning a variety of subjects and domains, LLMs use their parametric information to carry out more and more complicated and versatile duties throughout a number of enterprise use circumstances. Moreover, corporations are more and more investing assets in customizing LLMs by means of few-shot studying and fine-tuning to optimize their efficiency for specialised purposes.
Nevertheless, the spectacular efficiency of LLMs comes at the price of important computational necessities, pushed by their massive variety of parameters and autoregressive decoding course of which is sequential in nature. This mixture makes reaching low latency a problem to be used circumstances reminiscent of real-time textual content completion, simultaneous translation, or conversational voice assistants, the place subsecond response instances are important.
Researchers developed Medusa, a framework to hurry up LLM inference by including further heads to foretell a number of tokens concurrently. This put up demonstrates the right way to use Medusa-1, the primary model of the framework, to hurry up an LLM by fine-tuning it on Amazon SageMaker AI and confirms the velocity up with deployment and a easy load take a look at. Medusa-1 achieves an inference speedup of round two instances with out sacrificing mannequin high quality, with the precise enchancment various based mostly on mannequin measurement and information used. On this put up, we exhibit its effectiveness with a 1.8 instances speedup noticed on a pattern dataset.
Introduction to Medusa and its advantages for LLM inference velocity
LLMs generate textual content in a sequential method, which includes autoregressive sampling, with every new token conditional on the earlier ones. Producing Ok tokens necessitates Ok sequential executions of the mannequin. This token-by-token processing introduces an inherent latency and computational overhead as a result of the mannequin must carry out a separate ahead go for every new token within the output sequence. The next diagram from Function-Play with Massive Language Fashions illustrates this stream.

Speculative decoding tackles this problem by utilizing a smaller, quicker draft mannequin to generate a number of potential token continuations in parallel, that are then verified by a bigger, extra correct goal mannequin. This parallelization hurries up textual content era whereas sustaining the standard of the goal mannequin as a result of the verification activity is quicker than autoregressive token era. For an in depth clarification of the idea, discuss with the paper Accelerating Massive Language Mannequin Decoding with Speculative Sampling. The speculative decoding approach will be applied utilizing the inference optimization toolkit on Amazon SageMaker Jumpstart.
The paper Medusa: Easy LLM Inference Acceleration Framework with A number of Decoding Heads launched Medusa as an alternative choice to speculative decoding. As a substitute of including a separate draft mannequin, it provides further decoding heads to the LLM that generate candidate continuations concurrently. These candidates are then evaluated in parallel utilizing a tree-based consideration mechanism. This parallel processing reduces the variety of sequential steps wanted, resulting in quicker inference instances. The primary benefit of Medusa over speculative decoding is that it eliminates the necessity to purchase and preserve a separate draft mannequin whereas reaching increased speedups. For instance, when examined on the MT-Bench dataset, the paper studies that Medusa-2 (the second model of Medusa) hurries up inference time by 2.8 instances. This outperforms speculative decoding, which solely manages to hurry up inference time by 1.5 instances on the identical dataset.
The Medusa framework presently helps Llama and Mistral fashions. Though it provides important velocity enhancements, it does include a reminiscence trade-off (just like speculative decoding). For example, including 5 Medusa heads to the 7-billion-parameter Mistral mannequin will increase the entire parameter rely by 750 million (150 million per head), which suggests these further parameters should be saved in GPU reminiscence, resulting in a better reminiscence requirement. Nevertheless, typically, this improve doesn’t necessitate switching to a better GPU reminiscence occasion. For instance, you possibly can nonetheless use an ml.g5.4xlarge occasion with 24 GB of GPU reminiscence to host your 7-billion-parameter Llama or Mistral mannequin with further Medusa heads.
Coaching Medusa heads requires further improvement time and computational assets, which must be factored into venture planning and useful resource allocation. One other vital limitation to say is that the present framework, when deployed on an Amazon SageMaker AI endpoint, solely helps a batch measurement of 1—a configuration sometimes used for low-latency purposes.
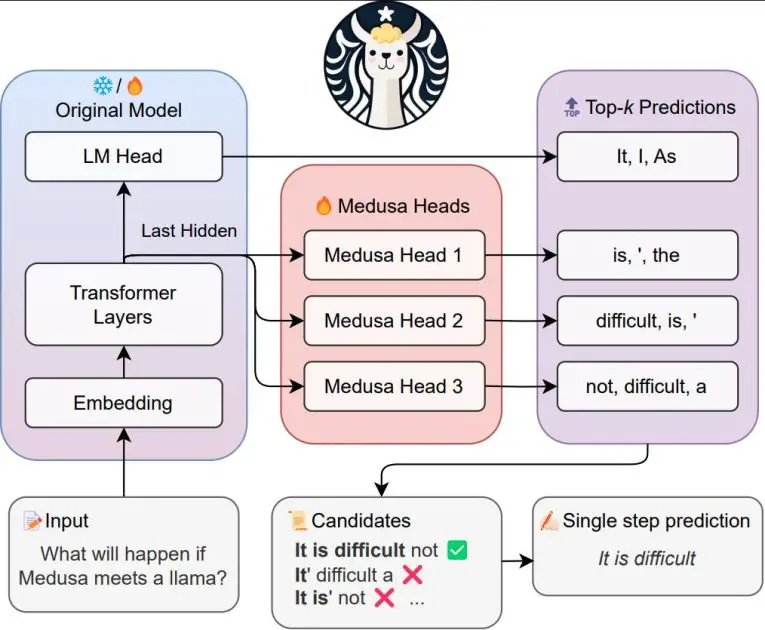
The next diagram from the unique Medusa paper authors’ FasterDecoding repository offers a visible Medusa framework overview.

There are two important variants of Medusa:
- Medusa-1 – Requires a two-stage strategy the place you first fine-tune your LLM after which add Medusa heads and practice them on high of your frozen fine-tuned LLM
- Medusa-2 – Launched later as an enchancment, fine-tunes each the extra heads and the spine LLM parameters collectively, enabling probably even additional latency speedups
The Medusa paper studies that throughout fashions of various sizes, you possibly can obtain inference speedups of round two instances for Medusa-1 and round 3 times for Medusa-2. With Medusa-1, the predictions are similar to these of the initially fine-tuned LLM. In distinction, with Medusa-2, we would observe barely totally different outcomes in comparison with easy fine-tuning of the LLM as a result of each the heads and the spine LLM parameters are up to date collectively. On this put up, we give attention to Medusa-1.
Resolution overview
We cowl the next steps in our resolution:
- Conditions
- Load and put together the dataset
- Fantastic-tune an LLM utilizing a SageMaker AI coaching job
- Practice Medusa heads on high of a frozen fine-tuned LLM utilizing a SageMaker AI coaching job
- Deploy the fine-tuned LLM with Medusa heads on a SageMaker AI endpoint
- Exhibit LLM inference speedup
By following this resolution, you possibly can speed up LLM inference in your purposes, resulting in quicker response instances and improved consumer expertise.
Conditions
To construct the answer your self, there are the next stipulations:
Load and put together the dataset
Now that you’ve got cloned the GitHub repository and opened the medusa_1_train.ipynb pocket book, you’ll load and put together the dataset within the pocket book. We encourage you to learn this put up whereas working the code within the pocket book. For this put up, we use a dataset referred to as sql-create-context, which accommodates samples of pure language directions, schema definitions and the corresponding SQL question. It accommodates 78,577 examples of pure language queries, SQL CREATE TABLE statements, and SQL queries answering the query utilizing the CREATE assertion as context. For demonstration functions, we choose 3,000 samples and break up them into practice, validation, and take a look at units.
You’ll want to run the “Load and put together the dataset” part of the medusa_1_train.ipynb to arrange the dataset for fine-tuning. We additionally included a knowledge exploration script to research the size of enter and output tokens. After information exploration, we put together the practice, validation, and take a look at units and add them to Amazon Easy Storage Service (Amazon S3).
Fantastic-tune an LLM utilizing SageMaker AI coaching job
We use the Zephyr 7B β mannequin as our spine LLM. Zephyr is a sequence of language fashions educated to behave as useful assistants, and Zephyr 7B β is a fine-tuned model of Mistral-7B-v0.1, educated on a mixture of publicly obtainable and artificial datasets utilizing Direct Choice Optimization.
To launch a SageMaker AI coaching job, we have to use the PyTorch or Hugging Face estimator. SageMaker AI begins and manages all the mandatory Amazon Elastic Compute Cloud (Amazon EC2) situations for us, provides the suitable containers, downloads information from our S3 bucket to the container and uploads and runs the required coaching script, in our case fine_tune_llm.py. We choose the hyperparameters based mostly on the QLoRA paper, however we encourage you to experiment with your personal mixtures. To expedite the execution of this code, we set the variety of epochs to 1. Nevertheless, for higher outcomes, it’s typically advisable to set the variety of epochs to not less than 2 or 3.
When our coaching job has accomplished efficiently after roughly 1 hour, we are able to use the fine-tuned mannequin artifact for the following step, coaching the Medusa heads on high of it. To visualise the coaching metrics in Tensorboard, you possibly can observe the steering on this documentation: Load and visualize output tensors utilizing the TensorBoard utility
Practice Medusa heads on high of frozen fine-tuned LLM utilizing a SageMaker AI coaching job
For coaching Medusa heads, we are able to reuse the capabilities beforehand talked about to launch the coaching job. We chosen hyperparameters based mostly on a mixture of what the Medusa paper reported and what we discovered to be finest performing after a number of experiments. We set the variety of Medusa heads to five and used the 8-bit AdamW optimizer, as advisable by the paper. For simplicity, we maintained a continuing studying charge of 1e-4 with a continuing scheduler, just like the earlier fine-tuning step. Though the paper recommends an elevated studying charge and a cosine scheduler, we discovered that our chosen mixture of hyperparameters carried out properly on this dataset. Nevertheless, we encourage you to experiment with your personal hyperparameter settings to probably obtain even higher outcomes.
We discovered that after 3 epochs, the analysis lack of Medusa heads was converging, which will be noticed within the TensorBoard graph within the following picture.

Moreover the hyperparameters, the primary distinction is that we go train_medusa_heads.py because the coaching entrypoint, the place we first add Medusa heads, then freeze the fine-tuned LLM, and we create customized MedusaSFTTrainer class, which is a subclass of the transformers SFTTrainer.
Within the add_medusa_heads() perform, we add the residual blocks of the Medusa heads, and likewise override the ahead go for our mannequin to verify to not practice the frozen spine LLM:
After the mannequin coaching is completed (which takes 1 hour), we put together the mannequin artefacts for deployment and add it to Amazon S3. Your closing mannequin artifact accommodates each the unique fine-tuned mannequin from the earlier step below the base-model prefix and the educated Medusa heads in a file named medusa_heads.safetensors.
Deploy the fine-tuned LLM with Medusa heads on a SageMaker AI endpoint
The Medusa framework is supported by the Textual content Era Inference (TGI) server. After coaching the LLM with Medusa heads, we deploy it to a SageMaker AI real-time endpoint utilizing the Hugging Face Inference Container arrange with TGI.
First, we create a SageMaker AI HuggingFaceModel object after which deploy the mannequin to an endpoint with the next perform:
We deploy three LLMs on three SageMaker AI endpoints:
- Base LLM which isn’t fine-tuned
- The LLM that we fine-tuned
- The fine-tuned LLM that additionally has educated Medusa heads
You possibly can deploy the three fashions in parallel by utilizing a perform that we included within the pocket book, or you possibly can deploy the fashions one after the other by working the code under:
After the standing for every endpoint turns into InService, which ought to take round quarter-hour, we are able to invoke them for inference. We ship the next enter:
We are able to observe the next responses:
- The bottom LLM response accommodates further phrases that aren’t wanted:
- The fine-tuned LLM response is improved considerably, and accommodates solely the required output:
- The fine-tuned LLM with educated Medusa heads supplies the very same response because the fine-tuned mannequin, demonstrating that Medusa-1, by design, maintains the output (high quality) of the unique mannequin:
Exhibit LLM inference speedup
To measure the inference velocity enhancements, we evaluate the response instances of the deployed fine-tuned LLM and the fine-tuned LLM with Medusa heads on 450 take a look at observations with the next code:
First, we run predictions utilizing the fine-tuned LLM:
Then, we run predictions utilizing the fine-tuned LLM with Medusa heads:
The prediction runs ought to take round 8 and 4 minutes respectively. We are able to observe that the common latency decreased from 950 to 530 milliseconds, which is an enchancment of 1.8 instances. You possibly can obtain even increased enhancements in case your dataset accommodates longer inputs and outputs. In our dataset, we solely had a mean of 18 enter tokens and 30 output tokens.
We need to as soon as once more spotlight that, with this system, the output high quality is totally maintained, and all of the prediction outputs are the identical. The mannequin responses for the take a look at set of 450 observations are the identical for each with Medusa heads and with out Medusa heads:
You may discover in your run that a number of observations aren’t precisely matching, and also you may get a 99% match resulting from small errors in floating level operations attributable to optimizations on GPUs.
Cleanup
On the finish of this experiment, don’t overlook to delete the SageMaker AI endpoints you created:
Conclusion
On this put up, we demonstrated the right way to fine-tune and deploy an LLM with Medusa heads utilizing the Medusa-1 approach on Amazon SageMaker AI to speed up LLM inference. Through the use of this framework and SageMaker AI scalable infrastructure, we confirmed the right way to obtain as much as twofold speedups in LLM inference whereas sustaining mannequin high quality. This resolution is especially helpful for purposes requiring low-latency textual content era, reminiscent of customer support chat assistants, content material creation, and advice programs.
As a subsequent step, you possibly can discover fine-tuning your personal LLM with Medusa heads by yourself dataset and benchmark the outcomes in your particular use case, utilizing the offered GitHub repository.
Concerning the authors
 Daniel Zagyva is a Senior ML Engineer at AWS Skilled Companies. He focuses on growing scalable, production-grade machine studying options for AWS prospects. His expertise extends throughout totally different areas, together with pure language processing, generative AI and machine studying operations.
Daniel Zagyva is a Senior ML Engineer at AWS Skilled Companies. He focuses on growing scalable, production-grade machine studying options for AWS prospects. His expertise extends throughout totally different areas, together with pure language processing, generative AI and machine studying operations.
 Aleksandra Dokic is a Senior Information Scientist at AWS Skilled Companies. She enjoys supporting prospects to construct progressive AI/ML options on AWS and she or he is happy about enterprise transformations by means of the ability of information.
Aleksandra Dokic is a Senior Information Scientist at AWS Skilled Companies. She enjoys supporting prospects to construct progressive AI/ML options on AWS and she or he is happy about enterprise transformations by means of the ability of information.
 Moran Beladev is a Senior ML Supervisor at Reserving.com. She is main the content material intelligence monitor which is concentrated on constructing, coaching and deploying content material fashions (pc imaginative and prescient, NLP and generative AI) utilizing probably the most superior applied sciences and fashions. Moran can also be a PhD candidate, researching making use of NLP fashions on social graphs.
Moran Beladev is a Senior ML Supervisor at Reserving.com. She is main the content material intelligence monitor which is concentrated on constructing, coaching and deploying content material fashions (pc imaginative and prescient, NLP and generative AI) utilizing probably the most superior applied sciences and fashions. Moran can also be a PhD candidate, researching making use of NLP fashions on social graphs.
 Manos Stergiadis is a Senior ML Scientist at Reserving.com. He focuses on generative NLP and has expertise researching, implementing and deploying massive deep studying fashions at scale.
Manos Stergiadis is a Senior ML Scientist at Reserving.com. He focuses on generative NLP and has expertise researching, implementing and deploying massive deep studying fashions at scale.
 Ilya Gusev is a Senior Machine Studying Engineer at Reserving.com. He leads the event of the a number of LLM programs inside Reserving.com. His work focuses on constructing manufacturing ML programs that assist thousands and thousands of vacationers plan their journeys successfully.
Ilya Gusev is a Senior Machine Studying Engineer at Reserving.com. He leads the event of the a number of LLM programs inside Reserving.com. His work focuses on constructing manufacturing ML programs that assist thousands and thousands of vacationers plan their journeys successfully.
 Laurens van der Maas is a Machine Studying Engineer at AWS Skilled Companies. He works intently with prospects constructing their machine studying options on AWS, focuses on pure language processing, experimentation and accountable AI, and is captivated with utilizing machine studying to drive significant change on the planet.
Laurens van der Maas is a Machine Studying Engineer at AWS Skilled Companies. He works intently with prospects constructing their machine studying options on AWS, focuses on pure language processing, experimentation and accountable AI, and is captivated with utilizing machine studying to drive significant change on the planet.



{kind=link}