
Should you’re constructing visible procuring, picture or doc understanding, or chart evaluation, you want a approach to confirm whether or not your mannequin’s response is definitely grounded within the supply picture. A text-only evaluator can not inform you whether or not a caption faithfully describes a picture, whether or not an extracted bill whole matches the doc, or whether or not a display screen abstract hallucinated a button that was by no means on the web page. Gartner predicts that by 2030, 80% of enterprise software program might be multimodal, up from lower than 10% in 2024. With out automated multimodal analysis, you’re caught between costly human evaluate and unreliable text-only proxies.
At the moment, we’re saying 4 new multimodal giant language mannequin (MLLM)-as-a-Choose evaluators for image-to-text duties in Strands Evals software program growth equipment (SDK): Total High quality, Correctness, Faithfulness, and Instruction Following. Every evaluator scores image-to-text outputs towards the supply picture. The evaluator sends the picture on to a multimodal choose mannequin, alongside the question, the response, and (optionally) a reference reply. The choose returns a rating grounded within the picture, along with a reasoning string you should use for debugging. You should use these evaluators as drop-in replacements for text-only judges in your present Strands Evals Case → Experiment → Report workflow, and plug them into steady integration (CI) to catch visible hallucinations, factual errors, and instruction violations robotically.
On this publish, you’ll discover ways to:
- Arrange the 4 multimodal evaluators and run them on an image-to-text activity.
- Swap between reference-based and reference-free analysis with the identical evaluator.
- Write a customized multimodal rubric for domain-specific standards.
- Select a choose mannequin on Amazon Bedrock that balances accuracy, price, and latency.
- Apply prompt-design decisions that improved judge-to-human alignment in our experiments.
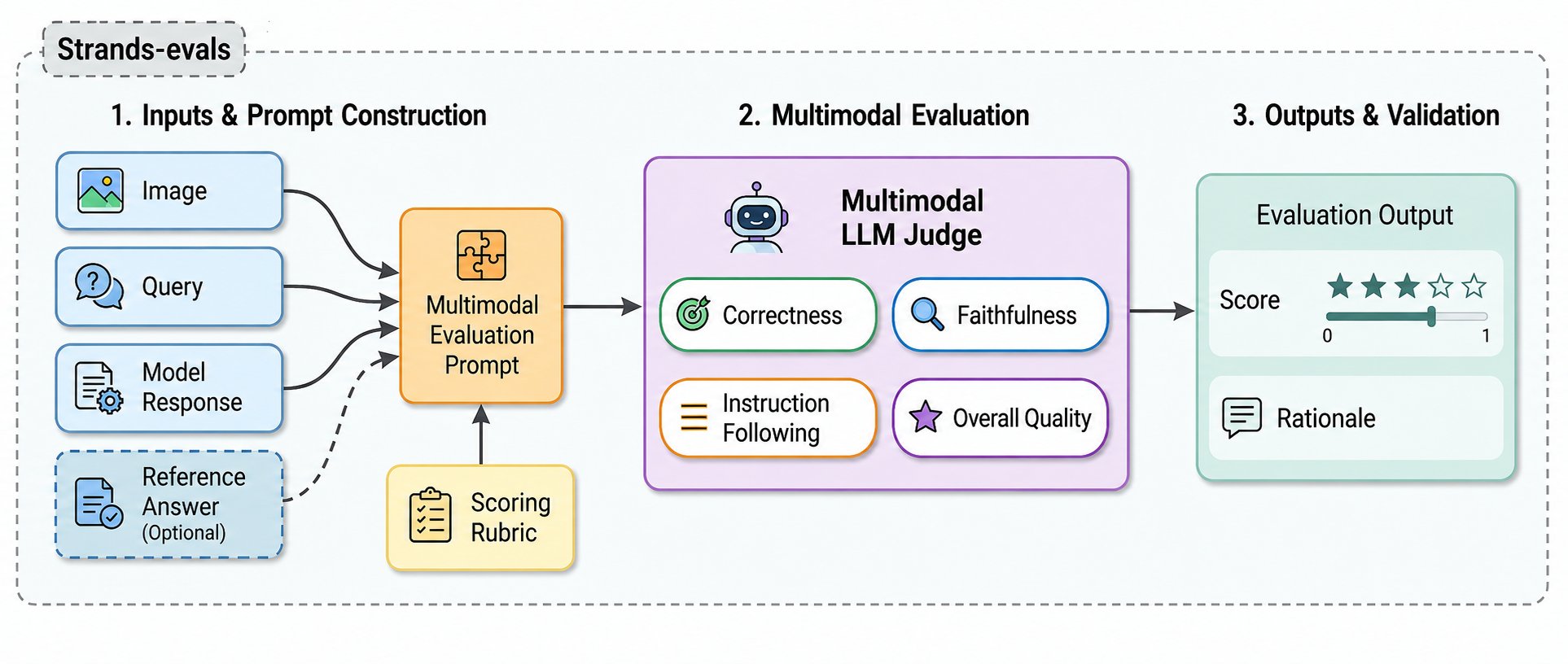
Determine 1: Overview of the multimodal choose framework. Given a picture (or doc picture), a textual question, and a model-generated response, the framework constructs a multimodal analysis immediate, applies an MLLM-based choose, and returns a rating (Likert 1-5 or binary) together with reasoning. The framework helps each reference-based and reference-free analysis, and integrates with Strands Evals for case administration and reporting.
Stipulations
To comply with the walkthrough on this publish, you want:
- Python 3.10 or later put in in your setting.
- pip set up
strands-agents-evalsfor the evaluators, and pip set upstrands-agentsfor the goal agent used within the walkthrough. - An AWS account with entry to Amazon Bedrock.
- AWS credentials configured regionally (for instance, through
aws configureor an AWS Id and Entry Administration (AWS IAM) position) with Amazon BedrockInvokeModelpermission for the choose mannequin. - Familiarity with the Strands Evals
Case→Experiment→Reportworkflow. If you’re new to Strands Evals, see the Strands Evals launch weblog publish for a fast tour.
Why text-only judges miss image-grounded failures
Suppose you’ve shipped a mannequin that reads invoices, summarizes dashboards, or narrates screenshots. Working a text-only LLM-as-a-Choose over the response will get you some sign (the writing is fluent, the construction is clear), nevertheless it misses precisely the failures that matter:
- The mannequin confidently names a chart pattern that the chart doesn’t truly present.
- It hallucinates a product, a label, or an individual who isn’t within the image.
- It solutions the mistaken query, or solutions the precise one within the mistaken format.
A text-only choose reads the output and approves it with out verifying the picture. The bottom reality lives within the picture, and the choose by no means sees it.
Even while you do get a low rating from a holistic “fee total high quality” choose, the rating alone doesn’t inform you what broke. The failure might be a factual error, an invented element, or an ignored instruction. These three failure modes require three totally different fixes, so collapsing them into one rating makes debugging tougher than it must be.
4 evaluators for image-to-text duties
The 4 evaluators goal essentially the most broadly used multimodal class. The enter is a picture (or doc picture) along with textual content, and the output is textual content. This class covers picture captioning, visible query answering, chart and infographic interpretation, doc area extraction, OCR, and screenshot summarization. The desk beneath summarizes what every of the 4 new evaluators catches.
| Evaluator | Rating | Core query | What it catches | |
| 1 | Total High quality | Likert 1-5 | How good is the response total? | Poor relevance, inaccuracy, shallow solutions, lack of comprehensiveness |
| 2 | Correctness | Binary | Is the response factually right and full given the picture and question? | Factual errors, mistaken attributes, counts, positions, omissions |
| 3 | Faithfulness | Binary | Is the response grounded within the picture with out hallucinations? | Invented objects, unsupported inferences, external-knowledge leakage |
| 4 | Instruction Following | Binary | Does the response adhere to the question’s constraints? | Format violations, mistaken counts, off-topic content material, ignored scope |
Each evaluator helps two modes. Reference-based mode compares the response towards a gold reply and is helpful when you have got labeled take a look at units. Reference-free mode judges from the picture alone and is the one possibility when the system runs on reside photos with no floor reality accessible.
Finish-to-end walkthrough: evaluating a chart-reading activity
To make the API concrete, you’ll stroll by a single Case. The enter is a bar chart of common income per paying streaming membership by area (U.S./Canada, EMEA, Asia Pacific, Latin America). The system below take a look at is an easy imaginative and prescient agent that solutions a slim query in regards to the chart. You run the 4 multimodal evaluators in the identical Experiment. They share a standard MultimodalOutputEvaluator base class and settle for photos by ImageData.
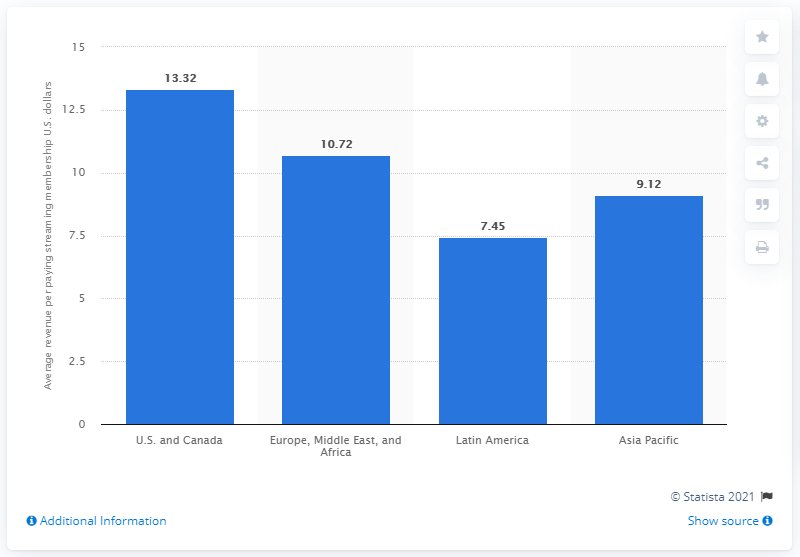
Determine 2: Common income per paying streaming membership, by area (Statista). The system below take a look at is requested to reply a grounded query about this chart.
Step 1. Outline the Case and evaluators. The Case wraps the picture and instruction in a MultimodalInput, and offering expected_output prompts reference-based judging for the evaluators that help it.
Step 2. Wire up the duty and run the experiment. The activity operate receives every Case, runs the imaginative and prescient mannequin on the picture plus instruction, and returns the response string to be evaluated.
As a result of every Case above carries a MultimodalInput with media, the 4 evaluators embrace the picture within the choose immediate. To ablate whether or not the picture modality is contributing meaningfully by yourself knowledge, swap the MultimodalInput for a plain-string enter (for instance, a textual content description of the picture) and rerun. The identical evaluator scores from textual content alone.
Step 3. Examine the Report. Every Report comprises per-case scores, test_passes, and causes:
Working on the chart above produces the next transcript:
Two issues to note. First, each evaluator returns a motive string along with a rating, which is important for debugging. When a run fails in CI, you may see why with out re-running. Second, the identical Case was scored by 4 unbiased judges (one Likert, three binary) in a single Experiment, so your workflow is an identical to single-evaluator runs in text-only Strands Evals.
Customized rubrics. For domain-specific standards, the bottom class accepts an arbitrary rubric string:
What we discovered: three design questions
Q1. Does the choose have to see the picture?
A pure query: can a text-only LLM choose, given an in depth auto-generated picture description rather than the picture, substitute for a multimodal choose? We in contrast MLLM-as-a-Choose (picture plus textual content) towards LLM-as-a-Choose with lengthy and quick picture descriptions feeding into the identical immediate.
Takeaway: the multimodal choose aligned extra carefully with human scores than both text-only variant. When you depend the additional LLM name to generate the picture description, the text-only route shouldn’t be meaningfully cheaper or sooner both. You probably have a multimodal choose accessible, use it immediately.
Q2. Which mannequin on Amazon Bedrock to make use of because the choose?
We evaluated a number of MLLMs accessible on Amazon Bedrock as judges and used alignment with human scores, per-query price, and latency to choose a default. Anthropic Claude Sonnet 4.6 on Amazon Bedrock provided the perfect accuracy-to-cost trade-off throughout our runs, and we use it because the default choose mannequin for the multimodal evaluators. Two broader observations additionally held up persistently throughout the fashions we tried. First, bigger reasoning-capable fashions have been extra dependable as judges than smaller ones. Second, inside the succesful tier, premium-priced fashions didn’t acquire measurable accuracy over mid-tier ones for this activity.
Advisable default: Anthropic Claude Sonnet 4.6.
Q3. Which prompt-design decisions truly matter?
We ablated a number of prompt-design axes towards our remaining advisable immediate. The takeaways that generalized throughout our runs:
- Ask the choose to motive earlier than scoring. This was the one most impactful selection we measured. Rating-only output is cheaper and extra self-consistent, however alignment with human scores drops noticeably. Should you solely keep in mind one factor, it’s this.
- Embody a number of various calibration examples. Alignment improved monotonically as we moved from zero-shot to a handful of examples.
- Use a fine-grained, multi-dimensional rubric (e.g., visible accuracy, instruction adherence, completeness, coherence) as an alternative of a single holistic immediate. Separating dimensions prevents a single imprecise rating from absorbing distinct failure modes.
Bonus: reference-based vs. reference-free
Injecting a gold reference reply into the choose immediate helps content-grounded evaluators. Total High quality, Correctness, and Faithfulness aligned extra carefully with human judgment when a reference was accessible. Instruction Following went the opposite means. Including reference content material distracted the choose from checking structural constraints (format, scope, order, depend) which might be decided by the question and response alone.
As a normal guideline: use references for content-grounded metrics, and skip them for structural metrics like instruction following.
Greatest practices
Primarily based on our experiments and integration work, we advocate:
- Default to
MultimodalOverallQualityEvaluatorfor fast sanity checks, then add focused binary evaluators (Correctness, Faithfulness, Instruction Following) as you diagnose particular failure modes. - Begin with Claude Sonnet 4.6 because the choose, and drop to smaller reasoning-capable MLLMs on Amazon Bedrock provided that price or latency dominates your constraints. Keep away from small fashions for judgment.
- Maintain the rationale+rating output format. Rating-only is tempting for price, however alignment with human scores drops noticeably.
- Use references for correctness, faithfulness, and total high quality if accessible. Skip them for instruction following.
Conclusion
The 4 new MLLM-as-a-Choose evaluators in Strands Evals transfer image-to-text analysis from costly human evaluate or unreliable text-only proxies to automated, image-grounded scoring. Total High quality, Correctness, Faithfulness, and Instruction Following every goal a definite failure mode, help each reference-based and reference-free analysis, and return diagnostic reasoning alongside each rating. On our held-out validation break up, the 4 evaluators aligned effectively with human judgment throughout various picture domains. This is step one towards broader multimodal analysis in Strands Evals. Future work consists of step-level analysis for multimodal device use and agent trajectories, and extra modality combos reminiscent of text-to-image, video-to-text, and audio-to-text.
Begin evaluating your image-to-text brokers at this time. Set up Strands Evals with the next command:
Then discover the assets beneath:
Concerning the authors



{kind=link}