GPUs are a treasured useful resource; they’re each quick in provide and way more expensive than conventional CPUs. They’re additionally extremely adaptable to many alternative use instances. Organizations constructing or adopting generative AI use GPUs to run simulations, run inference (each for inner or exterior utilization), construct agentic workloads, and run information scientists’ experiments. The workloads vary from ephemeral single-GPU experiments run by scientists to lengthy multi-node steady pre-training runs. Many organizations must share a centralized, high-performance GPU computing infrastructure throughout completely different groups, enterprise items, or accounts inside their group. With this infrastructure, they will maximize the utilization of costly accelerated computing sources like GPUs, reasonably than having siloed infrastructure that is perhaps underutilized. Organizations additionally use a number of AWS accounts for his or her customers. Bigger enterprises would possibly wish to separate completely different enterprise items, groups, or environments (manufacturing, staging, growth) into completely different AWS accounts. This supplies extra granular management and isolation between these completely different elements of the group. It additionally makes it easy to trace and allocate cloud prices to the suitable groups or enterprise items for higher monetary oversight.
The particular causes and setup can differ relying on the scale, construction, and necessities of the enterprise. However normally, a multi-account technique supplies larger flexibility, safety, and manageability for large-scale cloud deployments. On this submit, we focus on how an enterprise with a number of accounts can entry a shared Amazon SageMaker HyperPod cluster for working their heterogenous workloads. We use SageMaker HyperPod activity governance to allow this characteristic.
Resolution overview
SageMaker HyperPod activity governance streamlines useful resource allocation and supplies cluster directors the aptitude to arrange insurance policies to maximise compute utilization in a cluster. Job governance can be utilized to create distinct groups with their very own distinctive namespace, compute quotas, and borrowing limits. In a multi-account setting, you’ll be able to prohibit which accounts have entry to which workforce’s compute quota utilizing role-based entry management.
On this submit, we describe the settings required to arrange multi-account entry for SageMaker HyperPod clusters orchestrated by Amazon Elastic Kubernetes Service (Amazon EKS) and methods to use SageMaker HyperPod activity governance to allocate accelerated compute to a number of groups in numerous accounts.
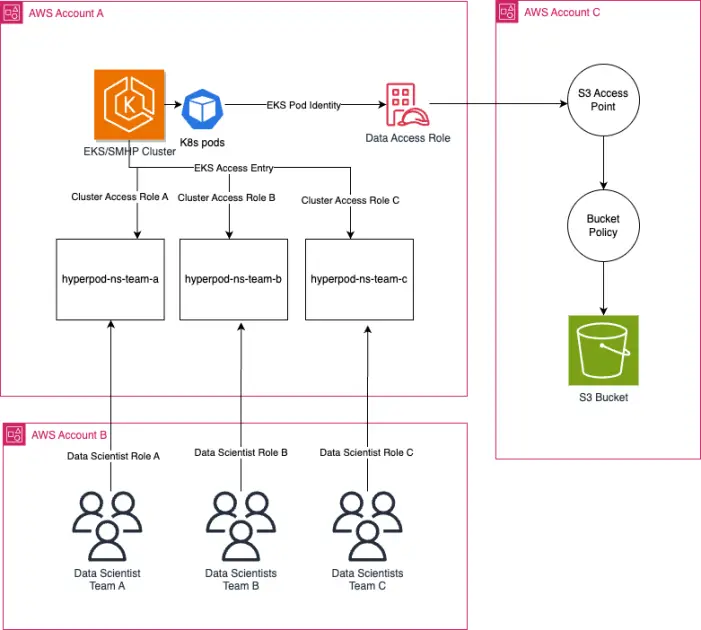
The next diagram illustrates the answer structure.

On this structure, one group is splitting sources throughout just a few accounts. Account A hosts the SageMaker HyperPod cluster. Account B is the place the info scientists reside. Account C is the place the info is ready and saved for coaching utilization. Within the following sections, we show methods to arrange multi-account entry in order that information scientists in Account B can prepare a mannequin on Account A’s SageMaker HyperPod and EKS cluster, utilizing the preprocessed information saved in Account C. We break down this setup in two sections: cross-account entry for information scientists and cross-account entry for ready information.
Cross-account entry for information scientists
Whenever you create a compute allocation with SageMaker HyperPod activity governance, your EKS cluster creates a singular Kubernetes namespace per workforce. For this walkthrough, we create an AWS Identification and Entry Administration (IAM) function per workforce, referred to as cluster entry roles, which can be then scoped entry solely to the workforce’s activity governance-generated namespace within the shared EKS cluster. Position-based entry management is how we make sure that the info science members of Group A will be unable to submit duties on behalf of Group B.
To entry Account A’s EKS cluster as a person in Account B, you will want to imagine a cluster entry function in Account A. The cluster entry function may have solely the wanted permissions for information scientists to entry the EKS cluster. For an instance of IAM roles for information scientists utilizing SageMaker HyperPod, see IAM customers for scientists.
Subsequent, you will want to imagine the cluster entry function from a task in Account B. The cluster entry function in Account A will then must have a belief coverage for the info scientist function in Account B. The info scientist function is the function in account B that might be used to imagine the cluster entry function in Account A. The next code is an instance of the coverage assertion for the info scientist function in order that it will possibly assume the cluster entry function in Account A:
The next code is an instance of the belief coverage for the cluster entry function in order that it permits the info scientist function to imagine it:
The ultimate step is to create an entry entry for the workforce’s cluster entry function within the EKS cluster. This entry entry also needs to have an entry coverage, reminiscent of EKSEditPolicy, that’s scoped to the namespace of the workforce. This makes positive that Group A customers in Account B can’t launch duties outdoors of their assigned namespace. You can even optionally arrange customized role-based entry management; see Organising Kubernetes role-based entry management for extra info.
For customers in Account B, you’ll be able to repeat the identical setup for every workforce. You could create a singular cluster entry function for every workforce to align the entry function for the workforce with their related namespace. To summarize, we use two completely different IAM roles:
- Knowledge scientist function – The function in Account B used to imagine the cluster entry function in Account A. This function simply wants to have the ability to assume the cluster entry function.
- Cluster entry function – The function in Account A used to offer entry to the EKS cluster. For an instance, see IAM function for SageMaker HyperPod.
Cross-account entry to ready information
On this part, we show methods to arrange EKS Pod Identification and S3 Entry Factors in order that pods working coaching duties in Account A’s EKS cluster have entry to information saved in Account C. EKS Pod Identification mean you can map an IAM function to a service account in a namespace. If a pod makes use of the service account that has this affiliation, then Amazon EKS will set the setting variables within the containers of the pod.
S3 Entry Factors are named community endpoints that simplify information entry for shared datasets in S3 buckets. They act as a strategy to grant fine-grained entry management to particular customers or purposes accessing a shared dataset inside an S3 bucket, with out requiring these customers or purposes to have full entry to the whole bucket. Permissions to the entry level is granted by S3 entry level insurance policies. Every S3 Entry Level is configured with an entry coverage particular to a use case or utility. For the reason that HyperPod cluster on this weblog submit can be utilized by a number of groups, every workforce may have its personal S3 entry level and entry level coverage.
Earlier than following these steps, guarantee you might have the EKS Pod Identification Add-on put in in your EKS cluster.
- In Account A, create an IAM Position that comprises S3 permissions (reminiscent of
s3:ListBucketands3:GetObjectto the entry level useful resource) and has a belief relationship with Pod Identification; this might be your Knowledge Entry Position. Under is an instance of a belief coverage.
{
"Model": "2012-10-17",
"Assertion": [
{
"Sid": "AllowEksAuthToAssumeRoleForPodIdentity",
"Effect": "Allow",
"Principal": {
"Service": "pods.eks.amazonaws.com"
},
"Action": [
"sts:AssumeRole",
"sts:TagSession"
]
}
]
}
- In Account C, create an S3 entry level by following the steps right here.
- Subsequent, configure your S3 entry level to permit entry to the function created in step 1. That is an instance entry level coverage that offers Account A permission to entry factors in account C.
{
"Model": "2012-10-17",
"Assertion": [
{
"Effect": "Allow",
"Principal": {
"AWS": "arn:aws:iam:::role/"
},
"Action": [
"s3:ListBucket",
"s3:GetObject"
],
"Useful resource": [
"arn:aws:s3:::accesspoint/",
"arn:aws:s3:::accesspoint//object/*"
]
}
]
}
- Guarantee your S3 bucket coverage is up to date to permit Account A entry. That is an instance S3 bucket coverage:
{
"Model": "2012-10-17",
"Assertion": [
{
"Effect": "Allow",
"Principal": "*",
"Action": [
"s3:GetObject",
"s3:ListBucket"
],
"Useful resource": [
"arn:aws:s3:::",
"arn:aws:s3:::/*"
],
"Situation": {
"StringEquals": {
"s3:DataAccessPointAccount": ""
}
}
}
]
}
- In Account A, create a pod id affiliation on your EKS cluster utilizing the AWS CLI.
- Pods accessing cross-account S3 buckets will want the service account title referenced of their pod specification.
You’ll be able to check cross-account information entry by spinning up a check pod and the executing into the pod to run Amazon S3 instructions:
This instance reveals making a single information entry function for a single workforce. For a number of groups, use a namespace-specific ServiceAccount with its personal information entry function to assist forestall overlapping useful resource entry throughout groups. You can even configure cross-account Amazon S3 entry for an Amazon FSx for Lustre file system in Account A, as described in Use Amazon FSx for Lustre to share Amazon S3 information throughout accounts. FSx for Lustre and Amazon S3 will must be in the identical AWS Area, and the FSx for Lustre file system will must be in the identical Availability Zone as your SageMaker HyperPod cluster.
Conclusion
On this submit, we offered steering on methods to arrange cross-account entry to information scientists accessing a centralized SageMaker HyperPod cluster orchestrated by Amazon EKS. As well as, we coated methods to present Amazon S3 information entry from one account to an EKS cluster in one other account. With SageMaker HyperPod activity governance, you’ll be able to prohibit entry and compute allocation to particular groups. This structure can be utilized at scale by organizations desirous to share a big compute cluster throughout accounts inside their group. To get began with SageMaker HyperPod activity governance, check with the Amazon EKS Help in Amazon SageMaker HyperPod workshop and SageMaker HyperPod activity governance documentation.
Concerning the Authors

Nisha Nadkarni is a Senior GenAI Specialist Options Architect at AWS, the place she guides corporations by greatest practices when deploying massive scale distributed coaching and inference on AWS. Previous to her present function, she spent a number of years at AWS targeted on serving to rising GenAI startups develop fashions from ideation to manufacturing.
 Anoop Saha is a Sr GTM Specialist at Amazon Internet Providers (AWS) specializing in generative AI mannequin coaching and inference. He companions with high frontier mannequin builders, strategic clients, and AWS service groups to allow distributed coaching and inference at scale on AWS and lead joint GTM motions. Earlier than AWS, Anoop held a number of management roles at startups and huge firms, primarily specializing in silicon and system structure of AI infrastructure.
Anoop Saha is a Sr GTM Specialist at Amazon Internet Providers (AWS) specializing in generative AI mannequin coaching and inference. He companions with high frontier mannequin builders, strategic clients, and AWS service groups to allow distributed coaching and inference at scale on AWS and lead joint GTM motions. Earlier than AWS, Anoop held a number of management roles at startups and huge firms, primarily specializing in silicon and system structure of AI infrastructure.
 Kareem Syed-Mohammed is a Product Supervisor at AWS. He’s targeted on compute optimization and price governance. Previous to this, at Amazon QuickSight, he led embedded analytics, and developer expertise. Along with QuickSight, he has been with AWS Market and Amazon retail as a Product Supervisor. Kareem began his profession as a developer for name heart applied sciences, Native Skilled and Advertisements for Expedia, and administration marketing consultant at McKinsey.
Kareem Syed-Mohammed is a Product Supervisor at AWS. He’s targeted on compute optimization and price governance. Previous to this, at Amazon QuickSight, he led embedded analytics, and developer expertise. Along with QuickSight, he has been with AWS Market and Amazon retail as a Product Supervisor. Kareem began his profession as a developer for name heart applied sciences, Native Skilled and Advertisements for Expedia, and administration marketing consultant at McKinsey.
 Rajesh Ramchander is a Principal ML Engineer in Skilled Providers at AWS. He helps clients at varied levels of their AI/ML and GenAI journey, from these which can be simply getting began all the way in which to those who are main their enterprise with an AI-first technique.
Rajesh Ramchander is a Principal ML Engineer in Skilled Providers at AWS. He helps clients at varied levels of their AI/ML and GenAI journey, from these which can be simply getting began all the way in which to those who are main their enterprise with an AI-first technique.



{kind=link}