This put up is co-written with Deepali Rajale from Karini AI.
Karini AI, a number one generative AI basis platform constructed on AWS, empowers prospects to rapidly construct safe, high-quality generative AI apps. GenAI isn’t just a know-how; it’s a transformational device that’s altering how companies use know-how. Relying on the place they’re within the adoption journey, the adoption of generative AI presents a major problem for enterprises. Whereas pilot tasks utilizing Generative AI can begin effortlessly, most enterprises need assistance progressing past this part. Based on Everest Analysis, greater than a staggering 50% of tasks don’t transfer past the pilots as they face hurdles as a result of absence of standardized or established GenAI operational practices.
Karini AI affords a sturdy, user-friendly GenAI basis platform that empowers enterprises to construct, handle, and deploy Generative AI functions. It permits learners and skilled practitioners to develop and deploy Gen AI functions for numerous use circumstances past easy chatbots, together with agentic, multi-agentic, Generative BI, and batch workflows. The no-code platform is right for fast experimentation, constructing PoCs, and fast transition to manufacturing with built-in guardrails for security and observability for troubleshooting. The platform consists of an offline and on-line high quality analysis framework to evaluate high quality throughout experimentation and constantly monitor functions post-deployment. Karini AI’s intuitive immediate playground permits authoring prompts, comparability with completely different fashions throughout suppliers, immediate administration, and immediate tuning. It helps iterative testing of extra easy, agentic, and multi-agentic prompts. For manufacturing deployment, the no-code recipes allow straightforward meeting of the info ingestion pipeline to create a data base and deployment of RAG or agentic chains. The platform homeowners can monitor prices and efficiency in real-time with detailed observability and seamlessly combine with Amazon Bedrock for LLM inference, benefiting from in depth enterprise connectors and information preprocessing strategies.
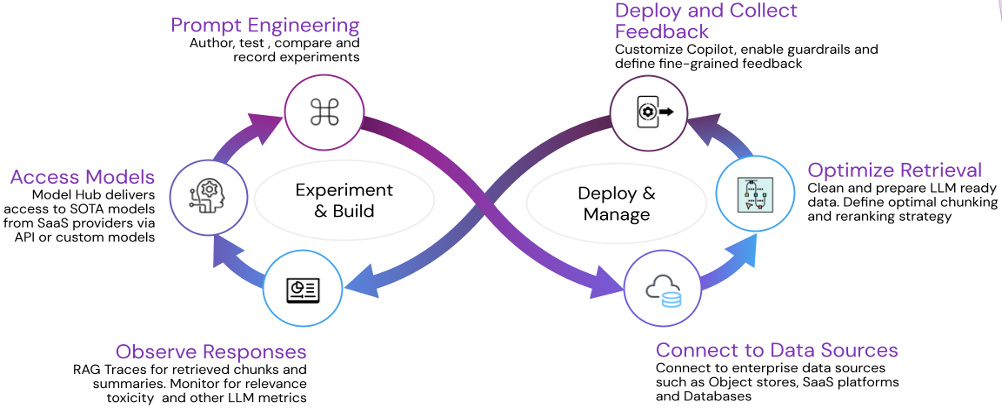
The next diagram illustrates how Karini AI delivers a complete Generative AI foundational platform encompassing the whole utility lifecycle. This platform delivers a holistic answer that hurries up time to market and optimizes useful resource utilization by offering a unified framework for growth, deployment, and administration.

On this put up, we share how Karini AI’s migration of vector embedding fashions from Kubernetes to Amazon SageMaker endpoints improved concurrency by 30% and saved over 23% in infrastructure prices.
Karini AI’s Knowledge Ingestion Pipeline for creating vector embeddings
Enriching giant language fashions (LLMs) with new information is essential to constructing sensible generative AI functions. That is the place Retrieval Augmented Technology (RAG) comes into play. RAG enhances LLMs’ capabilities by incorporating exterior information and producing state-of-the-art efficiency in knowledge-intensive duties. Karini AI affords no-code options for creating Generative AI functions utilizing RAG. These options embrace two major elements: an information ingestion pipeline for constructing a data base and a system for data retrieval and summarization. Collectively, these pipelines simplify the event course of, enabling the creation of highly effective AI functions with ease.
Knowledge Ingestion Pipeline
Ingesting information from numerous sources is important for executing Retrieval Augmented Technology (RAG). Karini AI’s information ingestion pipeline permits connection to a number of information sources, together with Amazon S3, Amazon Redshift, Amazon Relational Database Service (RDS), web sites and Confluence, dealing with structured and unstructured information. This supply information is pre-processed, chunked, and remodeled into vector embeddings earlier than being saved in a vector database for retrieval. Karini AI’s platform offers flexibility by providing a spread of embedding fashions from their mannequin hub, simplifying the creation of vector embeddings for superior AI functions.
Here’s a screenshot of Karini AI’s no-code information ingestion pipeline.

Karini AI’s mannequin hub streamlines including fashions by integrating with main basis mannequin suppliers reminiscent of Amazon Bedrock and self-managed serving platforms.
Infrastructure challenges
As prospects discover complicated use circumstances and datasets develop in measurement and complexity, Karini AI scales the info ingestion course of effectively to offer excessive concurrency for creating vector embeddings utilizing state-of-the-art embedding fashions, reminiscent of these listed within the MTEB leaderboard, that are quickly evolving and unavailable on managed platforms.
Earlier than migrating to Amazon SageMaker, we deployed our fashions on self-managed Kubernetes(K8s) on EC2 situations. Kubernetes supplied vital flexibility to deploy fashions from HuggingFace rapidly, however quickly, our engineering needed to handle many facets of scaling and deployment. We confronted the next challenges with our current setup that should be addressed to enhance effectivity and efficiency.
- Maintaining with SOTA(State-Of-The-Artwork) fashions: We managed completely different deployment manifests for every mannequin sort (reminiscent of classifiers, embeddings, and autocomplete), which was time-consuming and error-prone. We additionally needed to preserve the logic to find out the reminiscence allocation for various mannequin sorts.
- Managing dynamic concurrency was arduous: A major problem with utilizing fashions hosted on Kubernetes was reaching the very best dynamic concurrency degree. We aimed to maximise endpoint efficiency to realize goal transactions per second (TPS) whereas assembly strict latency necessities.
- Greater Prices: Whereas Kubernetes (K8s) offers strong capabilities, it has turn into extra pricey as a result of dynamic nature of knowledge ingestion pipelines, which leads to under-utilized situations and better prices.
Our seek for an inference platform led us to Amazon SageMaker, an answer that effectively manages our fashions for increased concurrency, meets buyer SLAs, and scales down serving when not wanted. The reliability of SageMaker’s efficiency gave us confidence in its capabilities.
Selecting Amazon SageMaker was a strategic choice for Karini AI. It balanced the necessity for increased concurrencies at a decrease price, offering a cheap answer for our wants. SageMaker’s potential to scale and maximize concurrency whereas making certain sub-second latency addresses numerous generative AI use circumstances making it a long-lasting funding for our platform.
Amazon SageMaker is a totally managed service that permits builders and information scientists to rapidly construct, practice, and deploy machine studying (ML) fashions. With SageMaker, you may deploy your ML fashions on hosted endpoints and get real-time inference outcomes. You may simply view the efficiency metrics on your endpoints in Amazon CloudWatch, routinely scale endpoints based mostly on site visitors, and replace your fashions in manufacturing with out shedding any availability.
Karini AI’s information ingestion pipeline structure with Amazon SageMaker Mannequin endpoint is right here.

Benefits of utilizing SageMaker internet hosting
Amazon SageMaker supplied our Gen AI ingestion pipeline many direct and oblique advantages.
- Technical Debt Mitigation: Amazon SageMaker, being a managed service, allowed us to free our ML engineers from the burden of inference, enabling them to focus extra on our core platform options—this aid from technical debt is a major benefit of utilizing SageMaker, reassuring us of its effectivity.
- Meet buyer SLAs: Knowledgebase creation is a dynamic process that will require increased concurrencies throughout vector embedding era and minuscule load throughout question time. Primarily based on buyer SLAs and information quantity, we will select batch inference, real-time internet hosting with auto-scaling, or serverless internet hosting. Amazon SageMaker additionally offers suggestions as an example sorts appropriate for embedding fashions.
- Diminished Infrastructure price: SageMaker is a pay-as-you-go service that means that you can create batch or real-time endpoints when there’s demand and destroy them when work is full. This strategy diminished our infrastructure price by greater than 23% over the Kubernetes (K8s) platform.
- SageMaker Jumpstart: SageMaker Jumpstart offers entry to SOTA (State-Of-The-Artwork) fashions and optimized inference containers, making it ultimate for creating new fashions which can be accessible to our prospects.
- Amazon Bedrock compatibility: Karini AI integrates with Amazon Bedrock for LLM (Giant Language Mannequin) inference. The customized mannequin import function permits us to reuse the mannequin weights utilized in SageMaker mannequin internet hosting in Amazon Bedrock to keep up a joint code base and interchange serving between Bedrock and SageMaker as per the workload.
Conclusion
Karini AI considerably improved, reaching excessive efficiency and decreasing mannequin internet hosting prices by migrating to Amazon SageMaker. We will deploy customized third-party fashions to SageMaker and rapidly make them obtainable to Karini’s mannequin hub for information ingestion pipelines. We will optimize our infrastructure configuration for mannequin internet hosting as wanted, relying on mannequin measurement and our anticipated TPS. Utilizing Amazon SagaMaker for mannequin inference enabled Karini AI to deal with rising information complexities effectively and meet concurrency wants whereas optimizing prices. Furthermore, Amazon SageMaker permits straightforward integration and swapping of latest fashions, making certain that our prospects can constantly leverage the most recent developments in AI know-how with out compromising efficiency or incurring pointless incremental prices.
Amazon SageMaker and Karini.ai provide a robust platform to construct, practice, and deploy machine studying fashions at scale. By leveraging these instruments, you may:
- Speed up growth:Construct and practice fashions sooner with pre-built algorithms and frameworks.
- Improve accuracy: Profit from superior algorithms and strategies for improved mannequin efficiency.
- Scale effortlessly:Deploy fashions to manufacturing with ease and deal with rising workloads.
- Scale back prices:Optimize useful resource utilization and reduce operational overhead.
Don’t miss out on this chance to achieve a aggressive edge.
About Authors
 Deepali Rajale is the founding father of Karini AI, which is on a mission to democratize generative AI throughout enterprises. She enjoys running a blog about Generative AI and training prospects to optimize Generative AI follow. In her spare time, she enjoys touring, in search of new experiences, and maintaining with the most recent know-how traits. You will discover her on LinkedIn.
Deepali Rajale is the founding father of Karini AI, which is on a mission to democratize generative AI throughout enterprises. She enjoys running a blog about Generative AI and training prospects to optimize Generative AI follow. In her spare time, she enjoys touring, in search of new experiences, and maintaining with the most recent know-how traits. You will discover her on LinkedIn.
 Ravindra Gupta is the Worldwide GTM lead for SageMaker and with a ardour to assist prospects undertake SageMaker for his or her Machine Studying/ GenAI workloads. Ravi is keen on studying new applied sciences, and luxuriate in mentoring startups on their Machine Studying follow. You will discover him on Linkedin
Ravindra Gupta is the Worldwide GTM lead for SageMaker and with a ardour to assist prospects undertake SageMaker for his or her Machine Studying/ GenAI workloads. Ravi is keen on studying new applied sciences, and luxuriate in mentoring startups on their Machine Studying follow. You will discover him on Linkedin



{kind=link}