The subject of combination of regressions was analyzed deeply within the article https://medium.com/towards-data-science/introduction-to-the-finite-normal-mixtures-in-regression-with-6a884810a692. I’ve introduced a completely reproducible outcomes to reinforce the normal linear regression by accounting for nonlinear relationships and unobserved heterogeneity in information.
Finite combination fashions assume the information is generated by a mix of a number of subpopulations, every modeled by its personal regression part. Utilizing R and Bayesian strategies, I’ve demonstrated easy methods to simulate and match such fashions by Markov Chain Monte Carlo (MCMC) sampling.
This strategy is especially precious for capturing complicated information patterns, figuring out subpopulations, and offering extra correct and interpretable predictions in comparison with normal strategies, but holding excessive stage of interpretability.
Relating to information evaluation, one of the vital difficult duties is knowing complicated datasets that come from a number of sources or subpopulations. Combination fashions, which mix completely different distributions to signify various information teams, are a go-to resolution on this state of affairs. They’re significantly helpful whenever you don’t know the underlying construction of your information however wish to classify observations into distinct teams primarily based on their traits.
Earlier than diving into the MCMC magic, the code begins by producing artificial information. This dataset represents a number of teams, every with its personal traits (akin to coefficients and variances). These teams are modeled utilizing completely different regression equations, with every group having a singular set of explanatory variables and related parameters.
The important thing right here is that the generated information is structured in a approach that mimics real-world eventualities the place a number of teams coexist, and the purpose is to uncover the relationships between variables in every group. Through the use of simulated information, we are able to apply MCMC strategies and see how the mannequin estimates parameters underneath managed situations.

Now, let’s speak in regards to the core of this strategy: Markov Chain Monte Carlo (MCMC). In essence, MCMC is a technique for drawing samples from complicated, high-dimensional chance distributions. In our case, we’re within the posterior distribution of the parameters in our combination mannequin — issues like regression coefficients (betas) and variances (sigma). The arithmetic of this strategy has been mentioned intimately in https://medium.com/towards-data-science/introduction-to-the-finite-normal-mixtures-in-regression-with-6a884810a692.
The MCMC course of within the code is iterative, which means that it refines its estimates over a number of cycles. Let’s break down the way it works:
- Updating Group Labels: Given the present values of the mannequin parameters, we start by figuring out essentially the most possible group membership for every statement. That is like assigning a “label” to every information level primarily based on the present understanding of the mannequin.
- Sampling Regression Coefficients (Betas): Subsequent, we pattern the regression coefficients for every group. These coefficients inform us how strongly the explanatory variables affect the dependent variable inside every group.
- Sampling Variances (Sigma): We then replace the variances (sigma) for every group. Variance is essential because it tells us how unfold out the information is inside every group. Smaller variance means the information factors are intently packed across the imply, whereas bigger variance signifies extra unfold.
- Reordering Teams: Lastly, we reorganize the teams primarily based on the up to date parameters, making certain that the mannequin can higher match the information. This helps in adjusting the mannequin and bettering its accuracy over time.
- Characteristic choice: It helps decide which variables are most related for every regression part. Utilizing a probabilistic strategy, it selects variables for every group primarily based on their contribution to the mannequin, with the inclusion chance calculated for every variable within the combination mannequin. This characteristic choice mechanism allows the mannequin to concentrate on a very powerful predictors, bettering each interpretability and efficiency. This concept has been mentioned as a completely separate device in https://medium.com/dev-genius/bayesian-variable-selection-for-linear-regression-based-on-stochastic-search-in-r-applicable-to-ml-5936d804ba4a . Within the present implementation, I’ve mixed it with combination of regressions to make it highly effective part of versatile regression framework. By sampling the inclusion chances throughout the MCMC course of, the mannequin can dynamically regulate which options are included, making it extra versatile and able to figuring out essentially the most impactful variables in complicated datasets.
As soon as the algorithm has run by sufficient iterations, we are able to analyze the outcomes. The code features a easy visualization step that plots the estimated parameters, evaluating them to the true values that have been used to generate the artificial information. This helps us perceive how properly the MCMC methodology has performed in capturing the underlying construction of the information.
The graphs beneath current the result of the code with 5000 MCMC attracts. We work with a mix of three parts, every with 4 potential explanatory variables. At the place to begin we swap off among the variables inside particular person mixtures. The algorithm is ready to discover solely these options which have predictive energy for the anticipated variable. We plot the attracts of particular person beta parameters for all of the parts of regression. A few of them oscillate round 0. The pink curve presents the true worth of parameter beta within the information used for producing the combination.

We additionally plot the MCMC attracts of the inclusion chance. The pink line at both 0 or 1 signifies if that parameter has been included within the unique combination of regression for producing the information. The training of inclusion chance occurs in parallel to the parameter coaching. That is precisely what permits for a belief within the educated values of betas. The mannequin construction is revealed (i.e. the subset of variables with explanatory energy is recognized) and, on the similar time, the proper values of beta are learnt.

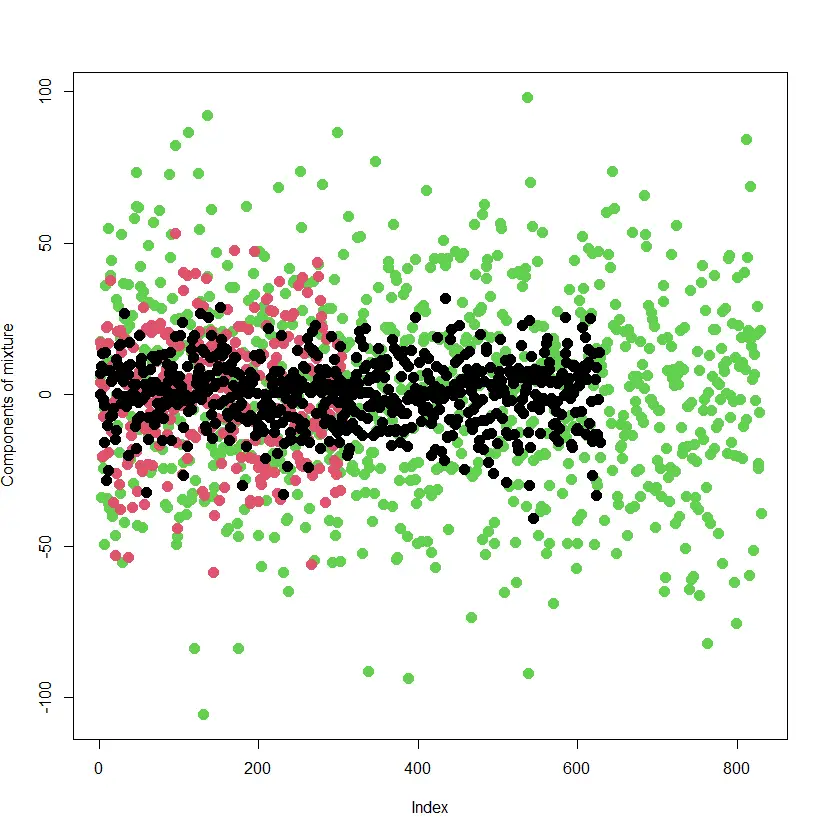
Lastly, we current the result of classification of particular person information factors to the respective parts of the combination. The power of the mannequin to categorise the information factors to the part of the combination they actually stem from is nice. The mannequin has been unsuitable solely in 6 % of instances.

What makes this strategy significantly fascinating is its capacity to uncover hidden buildings in information. Take into consideration datasets that come from a number of sources or have inherent subpopulations, akin to buyer information, medical trials, and even environmental measurements. Combination fashions permit us to categorise observations into these subpopulations with out having to know their precise nature beforehand. The usage of MCMC makes this much more highly effective by permitting us to estimate parameters with excessive precision, even in instances the place conventional estimation strategies may fail.
Combination fashions with MCMC are extremely highly effective instruments for analyzing complicated datasets. By making use of MCMC strategies, we’re in a position to estimate parameters in conditions the place conventional fashions could battle. This flexibility makes MCMC a go-to alternative for a lot of superior information evaluation duties, from figuring out buyer segments to analyzing medical information and even predicting future tendencies primarily based on historic patterns.
The code we explored on this article is only one instance of how combination fashions and MCMC may be utilized in R. With some customization, you may apply these strategies to all kinds of datasets, serving to you uncover hidden insights and make extra knowledgeable choices.
For anybody considering statistical modeling, machine studying, or information science, mastering combination fashions and MCMC is a game-changer. These strategies are versatile, highly effective, and — when utilized accurately — can unlock a wealth of insights out of your information.
As information turns into more and more complicated, having the instruments to mannequin and interpret it successfully is extra necessary than ever. Combination fashions mixed with MCMC provide a strong framework for dealing with multi-group information, and studying easy methods to implement these strategies will considerably enhance your analytical capabilities.
On this planet of information science, mastering these superior strategies opens up an enormous array of prospects, from enterprise analytics to scientific analysis. With the R code offered, you now have a stable place to begin for exploring combination fashions and MCMC in your personal tasks, whether or not you’re uncovering hidden patterns in information or fine-tuning a predictive mannequin. The subsequent time you encounter a posh dataset, you’ll be well-equipped to dive deep and extract significant insights.
There’s one necessary by product of the beneath implementation. Linear regression, whereas foundational in machine studying, usually falls quick in real-world purposes as a consequence of its assumptions and limitations. One main challenge is its assumption of a linear relationship between enter options and the goal variable, which hardly ever holds true in complicated datasets.
Moreover, linear regression is delicate to outliers and multicollinearity, the place extremely correlated options distort the mannequin’s predictions. It additionally struggles with non-linear relationships and interactions between options, making it much less versatile in capturing the complexity of recent information. In apply, information scientists usually flip to extra strong strategies akin to determination bushes, random forests, assist vector machines, and neural networks. These strategies can deal with non-linearity, interactions, and huge datasets extra successfully, providing higher predictive efficiency and adaptableness in dynamic environments.
Nonetheless, whereas above talked about strategies provide improved predictive energy, they usually come at the price of interpretability. These fashions function as “black packing containers,” making it obscure how enter options are being remodeled into predictions, which poses challenges for explain-ability and belief in crucial decision-making purposes.
So, is it doable to revive the shine of linear regression and make it a strong device once more? Positively, should you observe beneath carried out strategy with the combination of regular regression, you’ll really feel the ability of the underlying idea of linear regression with its nice interpretability side!
Until in any other case famous, all pictures are by the writer.



{kind=link}