Music era fashions have emerged as highly effective instruments that rework pure language textual content into musical compositions. Originating from developments in synthetic intelligence (AI) and deep studying, these fashions are designed to grasp and translate descriptive textual content into coherent, aesthetically pleasing music. Their potential to democratize music manufacturing permits people with out formal coaching to create high-quality music by merely describing their desired outcomes.
Generative AI fashions are revolutionizing music creation and consumption. Corporations can benefit from this know-how to develop new merchandise, streamline processes, and discover untapped potential, yielding vital enterprise affect. Such music era fashions allow numerous functions, from personalised soundtracks for multimedia and gaming to instructional assets for college students exploring musical types and buildings. It assists artists and composers by offering new concepts and compositions, fostering creativity and collaboration.
One distinguished instance of a music era mannequin is AudioCraft MusicGen by Meta. MusicGen code is launched below MIT, mannequin weights are launched below CC-BY-NC 4.0. MusicGen can create music based mostly on textual content or melody inputs, supplying you with higher management over the output. The next diagram exhibits how MusicGen, a single stage auto-regressive Transformer mannequin, can generate high-quality music based mostly on textual content descriptions or audio prompts.

MusicGen makes use of cutting-edge AI know-how to generate numerous musical types and genres, catering to varied artistic wants. Not like conventional strategies that embody cascading a number of fashions, corresponding to hierarchically or upsampling, MusicGen operates as a single language mannequin, which operates over a number of streams of compressed discrete music illustration (tokens). This streamlined strategy empowers customers with exact management over producing high-quality mono and stereo samples tailor-made to their preferences, revolutionizing AI-driven music composition.
MusicGen fashions can be utilized throughout training, content material creation, and music composition. They’ll allow college students to experiment with numerous musical types, generate customized soundtracks for multimedia initiatives, and create personalised music compositions. Moreover, MusicGen can help musicians and composers, fostering creativity and innovation.
This put up demonstrates tips on how to deploy MusicGen, a music era mannequin on Amazon SageMaker utilizing asynchronous inference. We particularly deal with textual content conditioned era of music samples utilizing MusicGen fashions.
Answer overview
With the flexibility to generate audio, music, or video, generative AI fashions will be computationally intensive and time-consuming. Generative AI fashions with audio, music, and video output can use asynchronous inference that queues incoming requests and course of them asynchronously. Our answer includes deploying the AudioCraft MusicGen mannequin on SageMaker utilizing SageMaker endpoints for asynchronous inference. This entails deploying AudioCraft MusicGen fashions sourced from the Hugging Face Mannequin Hub onto a SageMaker infrastructure.
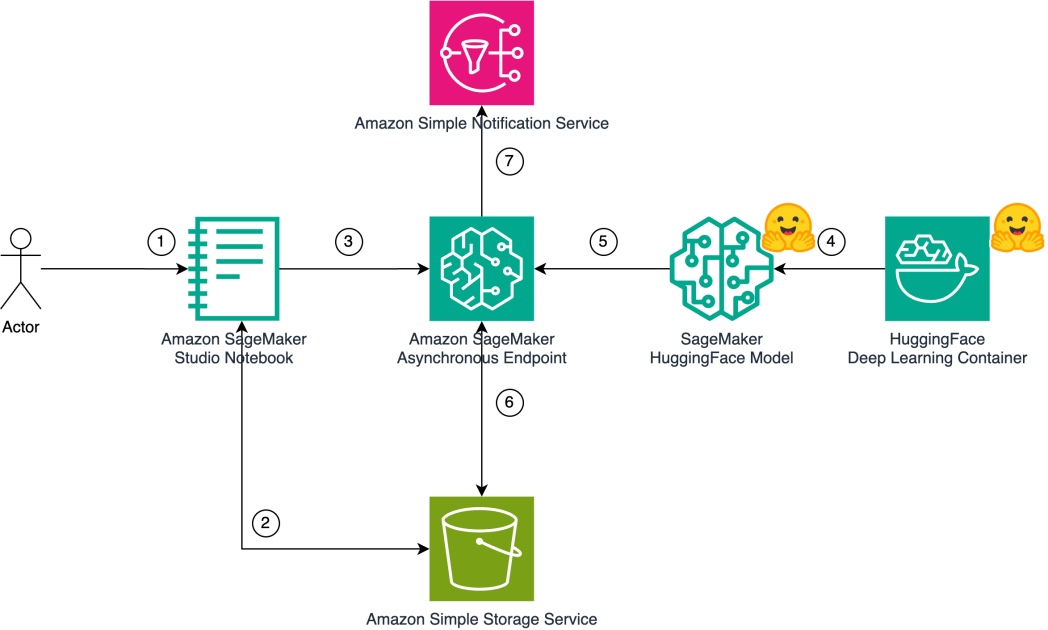
The next answer structure diagram exhibits how a person can generate music utilizing pure language textual content as an enter immediate by utilizing AudioCraft MusicGen fashions deployed on SageMaker.

The next steps element the sequence taking place within the workflow from the second the person enters the enter to the purpose the place music is generated as output:
- The person invokes the SageMaker asynchronous endpoint utilizing an Amazon SageMaker Studio pocket book.
- The enter payload is uploaded to an Amazon Easy Storage Service (Amazon S3) bucket for inference. The payload consists of each the immediate and the music era parameters. The generated music shall be downloaded from the S3 bucket.
- The
fb/musicgen-largemannequin is deployed to a SageMaker asynchronous endpoint. This endpoint is used to deduce for music era. - The HuggingFace Inference Containers picture is used as a base picture. We use a picture that helps PyTorch 2.1.0 with a Hugging Face Transformers framework.
- The SageMaker
HuggingFaceModelis deployed to a SageMaker asynchronous endpoint. - The Hugging Face mannequin (
fb/musicgen-large) is uploaded to Amazon S3 throughout deployment. Additionally, throughout inference, the generated outputs are uploaded to Amazon S3. - We use Amazon Easy Notification Service (Amazon SNS) matters to inform the success and failure as outlined as part of SageMaker asynchronous inference configuration.
Conditions
Ensure you have the next stipulations in place :
- Affirm you could have entry to the AWS Administration Console to create and handle assets in SageMaker, AWS Id and Entry Administration (IAM), and different AWS companies.
- In case you’re utilizing SageMaker Studio for the primary time, create a SageMaker area. Confer with Fast setup to Amazon SageMaker to create a SageMaker area with default settings.
- Receive the AWS Deep Studying Containers for Massive Mannequin Inference from pre-built HuggingFace Inference Containers.
Deploy the answer
To deploy the AudioCraft MusicGen mannequin to a SageMaker asynchronous inference endpoint, full the next steps:
- Create a mannequin serving bundle for MusicGen.
- Create a Hugging Face mannequin.
- Outline asynchronous inference configuration.
- Deploy the mannequin on SageMaker.
We element every of the steps and present how we are able to deploy the MusicGen mannequin onto SageMaker. For sake of brevity, solely vital code snippets are included. The complete supply code for deploying the MusicGen mannequin is obtainable within the GitHub repo.
Create a mannequin serving bundle for MusicGen
To deploy MusicGen, we first create a mannequin serving bundle. The mannequin bundle comprises a necessities.txt file that lists the required Python packages to be put in to serve the MusicGen mannequin. The mannequin bundle additionally comprises an inference.py script that holds the logic for serving the MusicGen mannequin.
Let’s take a look at the important thing features utilized in serving the MusicGen mannequin for inference on SageMaker:
The model_fn perform masses the MusicGen mannequin fb/musicgen-large from the Hugging Face Mannequin Hub. We depend on the MusicgenForConditionalGeneration Transformers module to load the pre-trained MusicGen mannequin.
You may also consult with musicgen-large-load-from-s3/deploy-musicgen-large-from-s3.ipynb, which demonstrates the most effective apply of downloading the mannequin from the Hugging Face Hub to Amazon S3 and reusing the mannequin artifacts for future deployments. As an alternative of downloading the mannequin each time from Hugging Face once we deploy or when scaling occurs, we obtain the mannequin to Amazon S3 and reuse it for deployment and through scaling actions. Doing so can enhance the obtain velocity, particularly for giant fashions, thereby serving to forestall the obtain from taking place over the web from a web site exterior of AWS. This finest apply additionally maintains consistency, which suggests the identical mannequin from Amazon S3 will be deployed throughout varied staging and manufacturing environments.
The predict_fn perform makes use of the info supplied through the inference request and the mannequin loaded by model_fn:
Utilizing the knowledge obtainable within the knowledge dictionary, we course of the enter knowledge to acquire the immediate and era parameters used to generate the music. We talk about the era parameters in additional element later on this put up.
We load the mannequin to the machine after which ship the inputs and era parameters as inputs to the mannequin. This course of generates the music within the type of a three-dimensional Torch tensor of form (batch_size, num_channels, sequence_length).
We then use the tensor to generate .wav music and add these information to Amazon S3 and clear up the .wav information saved on disk. We then receive the S3 URI of the .wav information and ship them places within the response.
We now create the archive of the inference scripts and add these to the S3 bucket:
The uploaded URI of this object on Amazon S3 will later be used to create the Hugging Face mannequin.
Create the Hugging Face mannequin
Now we initialize HuggingFaceModel with the required arguments. Throughout deployment, the mannequin serving artifacts, saved in s3_model_location, shall be deployed. Earlier than the mannequin serving, the MusicGen mannequin shall be downloaded from Hugging Face as per the logic in model_fn.
The env argument accepts a dictionary of parameters corresponding to TS_MAX_REQUEST_SIZE and TS_MAX_RESPONSE_SIZE, which outline the byte measurement values for request and response payloads to the asynchronous inference endpoint. The TS_DEFAULT_RESPONSE_TIMEOUT key within the env dictionary represents the timeout in seconds after which the asynchronous inference endpoint stops responding.
You possibly can run MusicGen with the Hugging Face Transformers library from model 4.31.0 onwards. Right here we set transformers_version to 4.37. MusicGen requires not less than PyTorch model 2.1 or newest, and now we have set pytorch_version to 2.1.
Outline asynchronous inference configuration
Music era utilizing a textual content immediate as enter will be each computationally intensive and time-consuming. Asynchronous inference in SageMaker is designed to deal with these calls for. When working with music era fashions, it’s necessary to notice that the method can typically take greater than 60 seconds to finish.
SageMaker asynchronous inference queues incoming requests and processes them asynchronously, making it superb for requests with massive payload sizes (as much as 1 GB), lengthy processing instances (as much as 1 hour), and close to real-time latency necessities. By queuing incoming requests and processing them asynchronously, this functionality effectively handles the prolonged processing instances inherent in music era duties. Furthermore, asynchronous inference permits seamless auto scaling, ensuring that assets are allotted solely when wanted, resulting in value financial savings.
Earlier than we proceed with asynchronous inference configuration , we create SNS matters for achievement and failure that can be utilized to carry out downstream duties:
We now create an asynchronous inference endpoint configuration by specifying the AsyncInferenceConfig object:
The arguments to the AsyncInferenceConfig are detailed as follows:
- output_path – The situation the place the output of the asynchronous inference endpoint shall be saved. The information on this location may have an .out extension and can include the small print of the asynchronous inference carried out by the MusicGen mannequin.
- notification_config – Optionally, you may affiliate success and error SNS matters. Dependent workflows can ballot these matters to make knowledgeable selections based mostly on the inference outcomes.
Deploy the mannequin on SageMaker
With the asynchronous inference configuration outlined, we are able to deploy the Hugging Face mannequin, setting initial_instance_count to 1:
After efficiently deploying, you may optionally configure computerized scaling to the asynchronous endpoint. With asynchronous inference, it’s also possible to scale down your asynchronous endpoint’s cases to zero.
We now dive into inferencing the asynchronous endpoint for music era.
Inference
On this part, we present tips on how to carry out inference utilizing an asynchronous inference endpoint with the MusicGen mannequin. For the sake of brevity, solely vital code snippets are included. The complete supply code for inferencing the MusicGen mannequin is obtainable within the GitHub repo. The next diagram explains the sequence of steps to invoke the asynchronous inference endpoint.

We element the steps to invoke the SageMaker asynchronous inference endpoint for MusicGen by prompting a desired temper in pure language utilizing English. We then display tips on how to obtain and play the .wav information generated from the person immediate. Lastly, we cowl the method of cleansing up the assets created as a part of this deployment.
Put together immediate and directions
For managed music era utilizing MusicGen fashions, it’s necessary to grasp varied era parameters:
From the previous code, let’s perceive the era parameters:
- guidance_scale – The
guidance_scaleis utilized in classifier-free steerage (CFG), setting the weighting between the conditional logits (predicted from the textual content prompts) and the unconditional logits (predicted from an unconditional or ‘null’ immediate). A better steerage scale encourages the mannequin to generate samples which might be extra carefully linked to the enter immediate, normally on the expense of poorer audio high quality. CFG is enabled by settingguidance_scale > 1. For finest outcomes, useguidance_scale = 3. Our deployment defaults to three. - max_new_tokens – The
max_new_tokensparameter specifies the variety of new tokens to generate. Era is restricted by the sinusoidal positional embeddings to 30-second inputs, which means MusicGen can’t generate greater than 30 seconds of audio (1,503 tokens). Our deployment defaults to 256. - do_sample – The mannequin can generate an audio pattern conditioned on a textual content immediate by use of the
MusicgenProcessorto preprocess the inputs. The preprocessed inputs can then be handed to the.generatemethodology to generate text-conditional audio samples. Our deployment defaults toTrue. - temperature – That is the softmax temperature parameter. A better temperature will increase the randomness of the output, making it extra numerous. Our deployment defaults to 1.
Let’s take a look at tips on how to construct a immediate to deduce the MusicGen mannequin:
The previous code is the payload, which shall be saved as a JSON file and uploaded to an S3 bucket. We then present the URI of the enter payload through the asynchronous inference endpoint invocation together with different arguments as follows.
The texts key accepts an array of texts, which can include the temper you wish to mirror in your generated music. You possibly can embody musical devices within the textual content immediate to the MusicGen mannequin to generate music that includes these devices.
The response from the invoke_endpoint_async is a dictionary of assorted parameters:
OutputLocation within the response metadata represents Amazon S3 URI the place the inference response payload is saved.
Asynchronous music era
As quickly because the response metadata is shipped to the consumer, the asynchronous inference begins the music era. The music era occurs on the occasion chosen through the deployment of the MusicGen mannequin on the SageMaker asynchronous Inference endpoint , as detailed within the deployment part.
Steady polling and acquiring music information
Whereas the music era is in progress, we repeatedly ballot for the response metadata parameter OutputLocation:
The get_output perform retains polling for the presence of OutputLocation and returns the S3 URI of the .wav music file.
Audio output
Lastly, we obtain the information from Amazon S3 and play the output utilizing the next logic:
You now have entry to the .wav information and might attempt altering the era parameters to experiment with varied textual content prompts.
The next is one other music pattern based mostly on the next era parameters:
Clear up
To keep away from incurring pointless expenses, you may clear up utilizing the next code:
The aforementioned cleanup routine will delete the SageMaker endpoint, endpoint configurations, and fashions related to MusicGen mannequin, so that you simply keep away from incurring pointless expenses. Ensure to set cleanup variable to True, and substitute
Conclusion
On this put up, we discovered tips on how to use SageMaker asynchronous inference to deploy the AudioCraft MusicGen mannequin. We began by exploring how the MusicGen fashions work and coated varied use instances for deploying MusicGen fashions. We additionally explored how one can profit from capabilities corresponding to auto scaling and the mixing of asynchronous endpoints with Amazon SNS to energy downstream duties. We then took a deep dive into the deployment and inference workflow of MusicGen fashions on SageMaker, utilizing the AWS Deep Studying Containers for HuggingFace inference and the MusicGen mannequin sourced from the Hugging Face Hub.
Get began with producing music utilizing your artistic prompts by signing up for AWS. The complete supply code is obtainable on the official GitHub repository.
References
In regards to the Authors
 Pavan Kumar Rao Navule is a Options Architect at Amazon Net Companies, the place he works with ISVs in India to assist them innovate on the AWS platform. He’s specialised in architecting AI/ML and generative AI companies at AWS. Pavan is a broadcast creator for the guide “Getting Began with V Programming.” In his free time, Pavan enjoys listening to the good magical voices of Sia and Rihanna.
Pavan Kumar Rao Navule is a Options Architect at Amazon Net Companies, the place he works with ISVs in India to assist them innovate on the AWS platform. He’s specialised in architecting AI/ML and generative AI companies at AWS. Pavan is a broadcast creator for the guide “Getting Began with V Programming.” In his free time, Pavan enjoys listening to the good magical voices of Sia and Rihanna.
 David John Chakram is a Principal Options Architect at AWS. He makes a speciality of constructing knowledge platforms and architecting seamless knowledge ecosystems. With a profound ardour for databases, knowledge analytics, and machine studying, he excels at reworking advanced knowledge challenges into revolutionary options and driving companies ahead with data-driven insights.
David John Chakram is a Principal Options Architect at AWS. He makes a speciality of constructing knowledge platforms and architecting seamless knowledge ecosystems. With a profound ardour for databases, knowledge analytics, and machine studying, he excels at reworking advanced knowledge challenges into revolutionary options and driving companies ahead with data-driven insights.
 Sudhanshu Hate is a principal AI/ML specialist with AWS and works with purchasers to advise them on their MLOps and generative AI journey. In his earlier function earlier than Amazon, he conceptualized, created, and led groups to construct ground-up open source-based AI and gamification platforms, and efficiently commercialized it with over 100 purchasers. Sudhanshu has to his credit score a few patents, has written two books and several other papers and blogs, and has introduced his factors of view in varied technical boards. He has been a thought chief and speaker, and has been within the trade for almost 25 years. He has labored with Fortune 1000 purchasers throughout the globe and most not too long ago with digital native purchasers in India.
Sudhanshu Hate is a principal AI/ML specialist with AWS and works with purchasers to advise them on their MLOps and generative AI journey. In his earlier function earlier than Amazon, he conceptualized, created, and led groups to construct ground-up open source-based AI and gamification platforms, and efficiently commercialized it with over 100 purchasers. Sudhanshu has to his credit score a few patents, has written two books and several other papers and blogs, and has introduced his factors of view in varied technical boards. He has been a thought chief and speaker, and has been within the trade for almost 25 years. He has labored with Fortune 1000 purchasers throughout the globe and most not too long ago with digital native purchasers in India.
 Rupesh Bajaj is a Options Architect at Amazon Net Companies, the place he collaborates with ISVs in India to assist them leverage AWS for innovation. He makes a speciality of offering steerage on cloud adoption by well-architected options and holds seven AWS certifications. With 5 years of AWS expertise, Rupesh can also be a Gen AI Ambassador. In his free time, he enjoys enjoying chess.
Rupesh Bajaj is a Options Architect at Amazon Net Companies, the place he collaborates with ISVs in India to assist them leverage AWS for innovation. He makes a speciality of offering steerage on cloud adoption by well-architected options and holds seven AWS certifications. With 5 years of AWS expertise, Rupesh can also be a Gen AI Ambassador. In his free time, he enjoys enjoying chess.



{kind=link}