had been presupposed to be learn by a machine. Outdated lodge invoices, financial institution statements, payslips, mortgage functions, medical payments, customs types, courtroom filings, work orders.
Most corporations use free instruments alongside paid APIs to attempt to convert these paperwork, and if you’d like structured output, APIs like Textract Structured run you as much as round $65 per 1k pages.
In the previous few years, although, a whole lot of new choices have appeared: smaller open-source imaginative and prescient fashions specialised for OCR, basic vision-language fashions, and doc parsing instruments like LlamaParse — altering what’s attainable and the price thereof.

So it felt like a good time to do my very own experiment to check a few of these towards paperwork of various problem.
I scouted 93 docs that would act as a proxy for what corporations use OCR for — handwritten notes, tables, monetary legacy docs, scanned invoices, receipts, charts, previous newspapers, tax types — then ran all of them via 14 totally different engines.
The concept was to see how they dealt with two issues: textual content restoration and the flexibility to protect helpful desk construction.
The primary query I wished answered: do you actually need to pay $65 for 1k structured pages, or are you able to slice that right down to a fraction? And does the specialised fashions win over the overall ones?
When doing experiments like this you all the time discover fairly a number of unusual issues, which I’ll cowl too. However to reply that major query I’ll take you thru what OCR is (skip if not new), the economics, the check, a few of the outcomes, and what else this confirmed me.
Notice: I didn’t check full area extraction, since that’s tougher to check cleanly throughout fourteen engines.
TL;DR
There is no such thing as a single greatest OCR engine. OCR is a routing drawback.
For clear high-volume paperwork, Tesseract remains to be exhausting to beat as a result of it’s free and quick. For combined manufacturing paperwork, Gemini Flash was the most effective all-rounder on this check. For tables, Mistral OCR regarded just like the cheaper structured choice.
The smaller specialist fashions regarded good inside their consolation zone, however failed tougher at paperwork they hadn’t seen. So, for high-stakes or messy paperwork, it is sensible to escalate to a bigger mannequin.
The primary takeaway is financial: don’t pay for costly structured OCR when the doc doesn’t want it. Classify your docs, check engines by yourself information, and route primarily based on value, accuracy, construction, and failure tolerance.
Benchmarks are helpful for discovery, however they won’t inform you what works in your paperwork.
Clarify the OCR area to me
OCR (Optical Character Recognition) is how a machine turns an image into machine readable textual content. Easy in precept, and for simpler docs principally solved, however tougher when issues grow to be extra human.
Simply to provide you a fast overview, older OCR discovered textual content on a web page, sliced it into characters, and matched every one towards a library of recognized shapes. Tesseract has finished this for the reason that Eighties.
Trendy OCR nonetheless (together with newer variations of Tesseract) often makes use of a neural community that appears on the entire web page without delay and outputs the doc as textual content. So, in case your doc is a clear PDF or a high-quality scan in a normal font, OCR is generally a solved drawback.
It stops being solved the second issues get messier: photographed receipts, handwritten notes, bizarre graphs and charts, dense monetary tables, or scanned tax types and mortgage functions.
Corporations want this finished effectively for apparent causes, because it’s one thing each downstream system acts on. The higher OCR will get, the extra paperwork turns into one thing a system can cause over as a substitute of one thing a human has to learn by hand.
There may be additionally the truth that if we feed AI programs badly parsed docs, every little thing after will probably be exhausting to belief.
I’m all about economics, so this area caught my eye as soon as I noticed how a lot cash is being poured into it. The Clever Doc Processing (IDP) market is projected to develop to someplace between $20 billion and $90 billion by the early 2030s, relying on which analyst you ask.
In all probability pushed by corporations paying $15–25 per bill in guide dealing with prices.
And since I keep near the tech world, I’ve watched a wave of specialised small OCR fashions ship over the previous yr (principally Chinese language), now being utilized by builders in every single place.

Which raises the query I wished to check: can the small open-source fashions truly do the work the costly APIs cost for or ought to we truly look in the direction of the overall imaginative and prescient fashions to deal with OCR too?
Skip the subsequent part if you wish to perceive what this experiment confirmed. I’ve to undergo the check setup first.
The docs, the engines, and the metrics
This experiment comes down to 3 questions: what engines we used, what docs we examined with, and the way we determined who received.
For the engines, I wished a lineup that coated all the alternatives I talked about, this meant: previous and new, open and closed, native and cloud, specialised and basic.
Tesseract turned the classical selection. It runs domestically and may be very quick. Then I added two document-parsing pipelines: Docling and Marker. Docling is slower however runs on CPU, Marker is open-weight however needing a GPU to run quick, which exhibits up later within the value.
Then for the brand new wave of specialised open OCR fashions: GLM-OCR, PaddleOCR-VL, DeepSeek-OCR, and MinerU 2.5 (a borderline case, actually a pipeline with a VLM inside). I picked them off OpenDataLab’s OmniDocBench leaderboard, the place they ranked first, second, fourth, and fifth.
I hosted them on Modal and served the relevant ones with vLLM, batching to hurry issues up. I counted the scale-up time when measuring latency later.
I additionally added one closed purpose-built mannequin, Mistral OCR, which I’d heard good issues about.
On the open facet, I used Qwen3-VL (8B, from Alibaba), additionally hosted on Modal with the remainder of the smaller fashions. I ought to flag that I gave it a plain transcription immediate slightly than the optimized serving setup it was designed for, so I could not have given it a good shot.
On the closed facet, for the overall fashions, I picked Gemini Flash 3.1 Lite (presently first on the IDP Leaderboard, the western counterpart constructed on OmniDocBench v1.5) and Claude Sonnet 4.6, at sixth.
For the cloud doc providers: LlamaParse and AWS Textract, in each its textual content and structured types. Structured Textract can do excess of I requested of it. I solely examined its textual content accuracy throughout the board and its desk extraction towards eight of the opposite engines.
Let’s flip to the paperwork. I picked seventeen doc sorts that had been both straightforward, medium, or exhausting. Ninety-three information in all.
Straightforward was the stuff OCR principally solved years in the past: clear invoices and receipts. Medium got here largely from the OmniAI OCR Benchmark dataset: financial institution statements, medical notes, photographed receipts, delivery paperwork, tax types.
Onerous was chosen when issues turned harder: charts, types, handwritten notes, weirdly scanned monetary tables, authorized papers, newspapers, and previous legacy stories.
Some docs had been actually fairly troublesome, such because the legacy scanned docs you see under, and this was simply because I used to be curious if some might truly do it effectively.

A few of these pictures got here with gold floor fact and a few didn’t, and the bottom fact I did have wasn’t all the time constant, some information labeled appropriately, some not, which is why we must always briefly cowl the metrics too.
Since each engine emits totally different markup, the standard scoring didn’t fairly match. One may choose Precision and Recall for a case like this.
Precision seems to be at how most of the OCR output’s phrases truly match within the GT whereas Recall measures what number of instances every GT phrase was captured.
Precision would punish engines that emit markdown construction the GT doesn’t include, moreover the GT generally skipped labels fully which might punish the engine unfairly. Recall would measure the phrases however punish the frequency.
So, I added on a 3rd metric known as Protection. I simply wished to measure how a lot of the bottom fact exhibits up someplace within the engine’s output. It isn’t excellent, however it tells me whether or not an engine caught most of what mattered, with out penalizing it for gaps that had been the bottom fact’s fault slightly than the engine’s.
For the paperwork with no gold floor fact in any respect, I fell again on an LLM decide, with Gemini 3 Professional as the bottom mannequin and anybody who’s used one is aware of that is fickle enterprise.
What this experiment confirmed
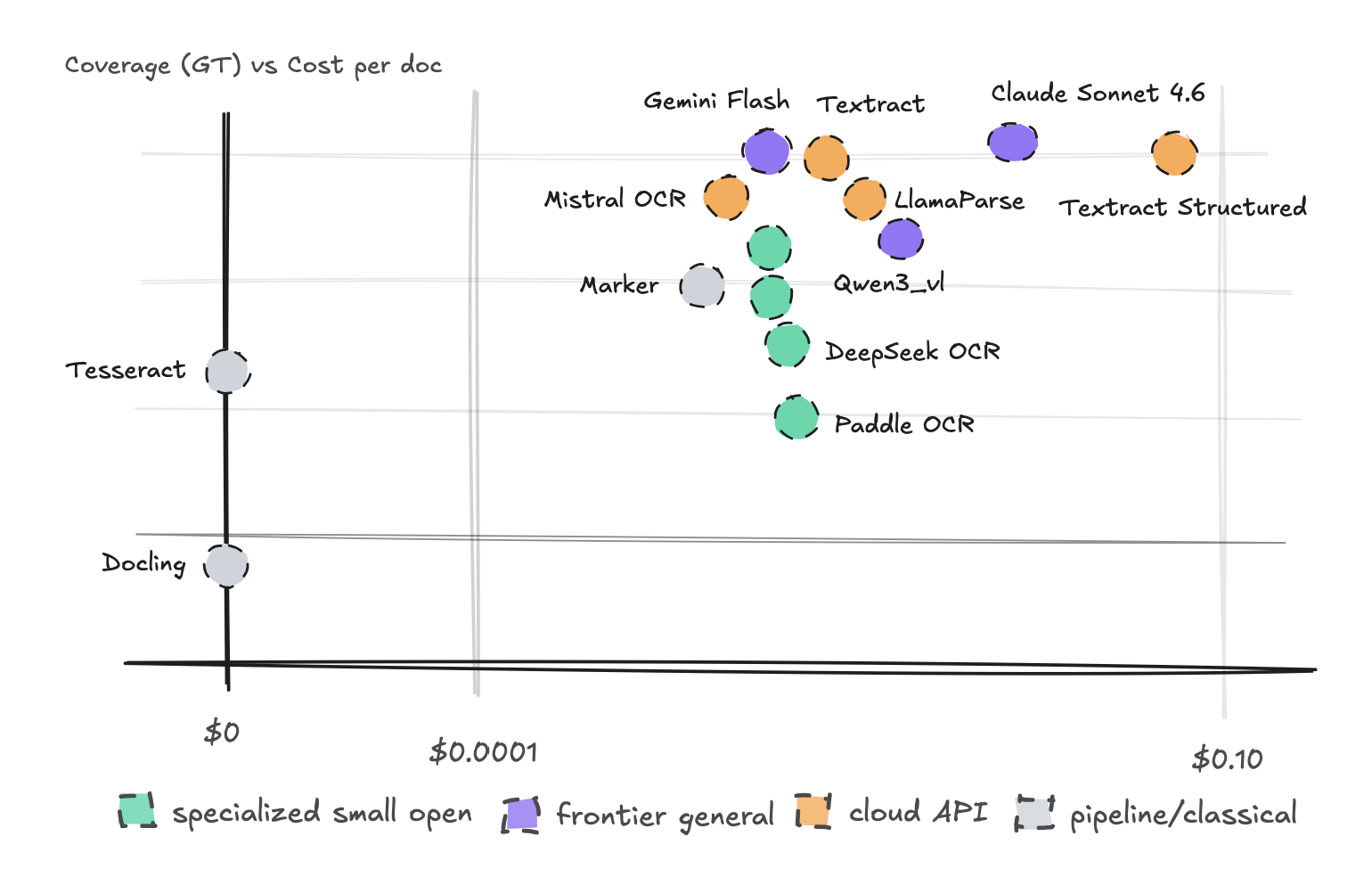
We mapped each doc towards the Protection metric to construct a scatter chart, and tracked latency on a separate chart. The factor a generalized chart can’t inform you although is that the engines failed in numerous methods.
The bubble graph confirmed that almost all engines fall someplace within the center prime, with two outliers on either side of it.

Gemini Flash and Textract Textual content did very effectively throughout the board with some edge circumstances. The specialised fashions all fell under the overall fashions and specialised APIs. Sonnet carried out the very best but additionally with a steeper price ticket.
This may increasingly not have been a shock because the check set was extremely uncommon. Among the specialised fashions could not have seen a lot of them. Moreover, this check was on English paperwork and most of those smaller fashions have Chinese language origin.
After we additionally mapped latency, a few of the fashions turned out to be very sluggish, however once more most wound up someplace within the center.

The outliers right here had been: Tesseract, Claude Sonnet 4.6, and Docling. Tesseract was extremely quick in comparison with all different engines. It ought to be your go-to for simpler paperwork.
These graphs generalise throughout all of the paperwork, however I did separate the outcomes primarily based on the sort and problem stage.
To start out with the straightforward docs. On invoices, each engine did effectively, Tesseract particularly. Receipts knocked everybody down a little bit.

The one outlier was Docling, which struggled throughout a whole lot of the classes, even the straightforward ones.
Once I regarded into the Docling failures I discovered issues like Ifjointreturn as a substitute of “joint return,” and worse, strings like Metropolis,wrostffielfouaveaoreignadresalcomletacesb. DeepSeek additionally missed key particulars right here like bill quantity and date, which is why its quantity sits low.
The identical sample holds within the medium class, although that’s the place PaddleOCR began degrading on particular sorts: financial institution statements, delivery, tax types. Tax types had been exhausting for everybody, however PaddleOCR and Docling wound up on the backside.
Textract was the most effective engine on a whole lot of the medium sorts, together with Claude Sonnet 4.6 and Mistral OCR.
On the tougher sorts, Gemini Flash began rising, beating Textract on types and handwritten notes, matching it elsewhere. It did remarkably effectively in every single place. Tesseract and Docling failed exhausting on handwritten, and types had been powerful for them too.
Virtually all of the specialised fashions didn’t pull via on these tougher docs besides on monetary tables, the place they held about even.
For the docs with no floor fact (newspapers, authorized, stories, some scanned legacy paperwork) we used an LLM decide. These are genuinely exhausting, so it’s no shock nearly everybody failed on the stories and newspapers.
Besides Gemini Flash that did moderately effectively in every single place. Mistral OCR additionally did effectively for newspapers. Gemini Flash received in every single place with the decide, although we used Gemini Professional because the decide so take that with a grain of salt (however I did double verify myself).
Earlier than rounding off: I additionally ran 8 engines towards Textract Structured to see how they did on monetary tables, extracting an HTML desk. I used Textract Structured’s output as the bottom fact for TEDS (Tree Edit Distance Similarity) and scored Claude Sonnet 4.6, LlamaParse, Mistral OCR, Gemini Flash, Marker, MinerU, DeepSeek-OCR, and Docling towards it.

Mistral OCR, and LlamaParse, and Sonnet did very effectively whereas being less expensive. I additionally ran it via an LLM decide, and the winners had been the identical three (even earlier than Textract Structured) although I’d wish to construct that check higher earlier than I totally belief it.

Now, let’s speak about what it prices to scale this up, and what would make sense the place.
When does what make sense
Let’s run via what it prices to scale up with these engines, after which primarily based on these docs what you’d selected the place.
First, the price of utilizing these engines fluctuate wildly, as you noticed earlier than. Generally it helps to see the price not only for one doc, however hundreds as much as 1,000,000.

We’re self-hosting on Modal, so these prices come from precise utilization there. You possibly can run domestically, however my laptop wouldn’t permit it and I didn’t wish to attempt it.
In case you had been to simply use one engine that handles each straightforward and exhausting paperwork, I’d suppose you wound up with a much bigger invoice than vital. Utilizing Textract Structured for any paperwork that aren’t wanted would hand you a invoice of $6.5k per 100k docs.
I do surprise what number of corporations go the straightforward approach right here and choose the costly choices for simple in addition to exhausting docs and go away some huge cash on the desk.
The important thing thought to take with you right here is that there’s no single greatest engine for each use case, it relies on doc kind, privateness, desk construction, failure tolerance, value, and so forth.
For the docs we now have right here, Gemini Flash 3.1-Lite is a transparent winner. This one was appropriate from trying on the leaderboards. Mistral OCR did effectively on structured tables whereas staying low cost. Claude Sonnet 4.6 did very effectively too, however it’s very sluggish and costly comparatively.
Docling is so very sluggish on my laptop computer. I’m certain there are methods to hurry it up, however it additionally failed in ways in which make it inherently unstable (nonetheless a small check although).
The specialised OCR fashions had been a little bit of a headache, particularly on English docs; I noticed output errors in Chinese language that I’ll cowl in a bit, so I’m wondering if that’s a part of it.
Textract is a steady selection, however structured buys you nearly no further textual content accuracy so in the event you’re paying that steep markup for structured output, be sure to truly use it. I’m guessing it’s a fairly good enterprise mannequin for them.
So, generally for this very small check: for clear, high-volume print, simply use Tesseract. For basic heterogeneous manufacturing, go Gemini Flash. For a cost-floor with desk construction, check Mistral OCR. For prime-stakes docs, path to Sonnet or a bigger mannequin.
Since everybody did effectively in numerous methods you’ll should contact me for specifics but when it’s essential go non-public it could be price it to take a look at fine-tuning a mannequin in your docs. Or, use a small specialised mannequin and escalate on failures.
Let me simply rapidly speak about some issues that stood out after doing this experiment.
Different stuff I ought to point out
A handful of issues surfaced from this which are price pulling out on their very own.
First, if you wish to perceive how a mannequin or engine will do in your docs, the one approach is to check on these docs, you possibly can’t depend on benchmarks to inform you. This was the primary perception this confirmed. OCR usefulness relies upon by yourself doc combine, layouts, languages, scans, tables, handwriting, and failure tolerance.
Don’t pay for construction in the event you don’t want it. I’m wondering what number of are utilizing sure APIs or fashions for a cause they will’t justify. Map the price to grasp what you might be shedding by not utilizing the right engine for the paperwork.
The specialist fashions, as talked about earlier than, have sharp boundaries. That is apparent, they are often glorious inside their coaching distribution however fail exterior of it. That is the place the overall fashions will win.
If you wish to fine-tune it could assist, however provided that the stream is steady as it is going to additionally fail whether it is consistently launched new doc lessons.
Lastly, the failure modes advised us greater than the averages.
PaddleOCR had repetition loops, column-merging, fallback into Chinese language textbook template textual content like 书名:___ repeated tons of of instances. Whereas Docling has character errors, word-merging, and column misalignment all stacking collectively.
DeepSeek OCR has chart blindness and empty outputs on some docs. Tesseract did wonderful on clear docs (as talked about) however failed on photograph/handwriting altogether outputting rubbish.
Caveats to contemplate
Earlier than we spherical up, let me cowl how this check is in the end imperfect by naming the problems within the GT, the metrics used, and the pattern dimension.
I coated this in one of many part above, however the floor fact differs between paperwork relying on the dataset the place they had been discovered. Typically tokenization artifacts could make appropriate OCR look worse than it’s.
Most engines have totally different codecs, some return plain textual content, some markdown, some HTML/wealthy markdown and it’s exhausting to generalize throughout all.
We’re utilizing Protection, after which additionally another metrics, however these aren’t excellent. Protection received’t cost the engine if it outputs an excessive amount of textual content or the construction of it’s off. Although I did discover that for the engines that failed, they did so at first or mid-way via slightly than on the finish.
This implies it’s helpful for rating however not an ideal method to rating.
LLM judges are usually not impartial fact: I’ve coated this previously, however they’re biased and really immediate delicate.
Then I simply must say that this check is attention-grabbing however not that large, the pattern dimension is approach too small to make use of this as a factual research. However, I don’t totally belief these metrics nor the decide so it was the one approach for me to have the ability to double verify the outcomes by myself with out this turning right into a yr lengthy undertaking.
So, this check is helpful for path and getting a way of what works, however for getting a way of your use case, it’s essential run it via together with your particular docs.
Lastly, latency and reproducibility is unstable. Serverless chilly begins make timing noisy, and API fashions can silently change over time, so precise replica is difficult.
Like all the time with these articles, it takes fairly a bit to do an experiment like this however I don’t simply do it for content material, I do it as a result of I’m genuinely curious.
What it seems to be like although is that OCR appears to be a routing drawback, and maybe an analysis drawback. Classify your docs and run them via a number of engines, then attempt to construct a good router and validator in your pipeline to escalate failures after which log the prices.
If it’s essential get the total outcomes from this experiment otherwise you need me to run it via your docs, get in contact.
You possibly can observe my writing on Medium, my web site or join with me through LinkedIn.
❤
All datasets used on this benchmark are publicly out there and sourced from HuggingFace. Licenses embody MIT, CC-BY-4.0, and fair-use frameworks (UCSF Trade Paperwork Library) overlaying analysis, scholarship, and training. No supply paperwork are reproduced — datasets had been used solely as analysis inputs to measure OCR engine efficiency.



{kind=link}