This publish was written with Lokesha Thimmegowda, Muppirala Venkata Krishna Kumar, and Maraka Vishwadev of CBRE.
CBRE is the world’s largest industrial actual property providers and funding agency. The corporate serves purchasers in additional than 100 international locations and gives providers starting from capital markets and leasing advisory to funding administration, challenge administration and services administration.
CBRE makes use of AI to enhance industrial actual property options with superior analytics, automated workflows, and predictive insights. The possibility to unlock worth with AI within the industrial actual property lifecycle begins with knowledge at scale. With the trade’s largest dataset and a complete suite of enterprise-grade expertise, the corporate has carried out a spread of AI options to spice up particular person productiveness and help broad-scale transformation.
This weblog publish describes how CBRE and AWS partnered to remodel how property administration professionals entry data, making a next-generation search and digital assistant expertise that unifies entry throughout many forms of property knowledge utilizing Amazon Bedrock, Amazon OpenSearch Service, Amazon Relational Database Service, Amazon Elastic Container Service, and AWS Lambda.
Unified property administration search challenges
CBRE’s proprietary PULSE system consolidates a variety of important property knowledge—overlaying structured knowledge from relational databases that file transactions and unstructured knowledge saved in doc repositories containing the whole lot from lease agreements to property inspections. Up to now, property administration professionals needed to sift by tens of millions of paperwork and swap between a number of completely different methods to find property upkeep particulars. Knowledge was scattered throughout 10 distinct sources and 4 separate databases, which made it exhausting to get full solutions. This fragmented setup lowered productiveness and made it troublesome to uncover key insights about property operations.
Consultants in property administration, not database syntax, wanted to ask complicated questions in pure language, rapidly synthesize disparate data, and keep away from handbook overview of prolonged paperwork.
The problem: ship an intuitive, unified search answer bridging structured and unstructured content material, with strong safety, enterprise-grade efficiency and reliability.
Resolution structure
CBRE carried out a worldwide search answer inside PULSE, powered by Amazon Bedrock, to deal with these challenges. The search structure is designed for a seamless, clever, and safe data retrieval expertise throughout numerous knowledge varieties. It orchestrates an interaction of consumer interplay, AI-driven processing, and strong knowledge storage.
CBRE’s PULSE search answer makes use of Amazon Bedrock for the speedy deployment of generative AI capabilities through the use of a number of basis fashions by a single API. CBRE’s implementation makes use of Amazon Nova Professional for SQL question era, attaining a 67% discount in processing time, whereas Claude Haiku powers clever doc interactions. The answer maintains enterprise-grade safety for all property knowledge. By combining Amazon Bedrock capabilities with Retrieval Augmented Technology (RAG) and Amazon OpenSearch Service, CBRE created a unified search expertise throughout greater than eight million paperwork and a number of databases, basically reworking how property professionals entry and analyze business-critical data.
The next diagram illustrates the structure for the answer that CBRE carried out in AWS:
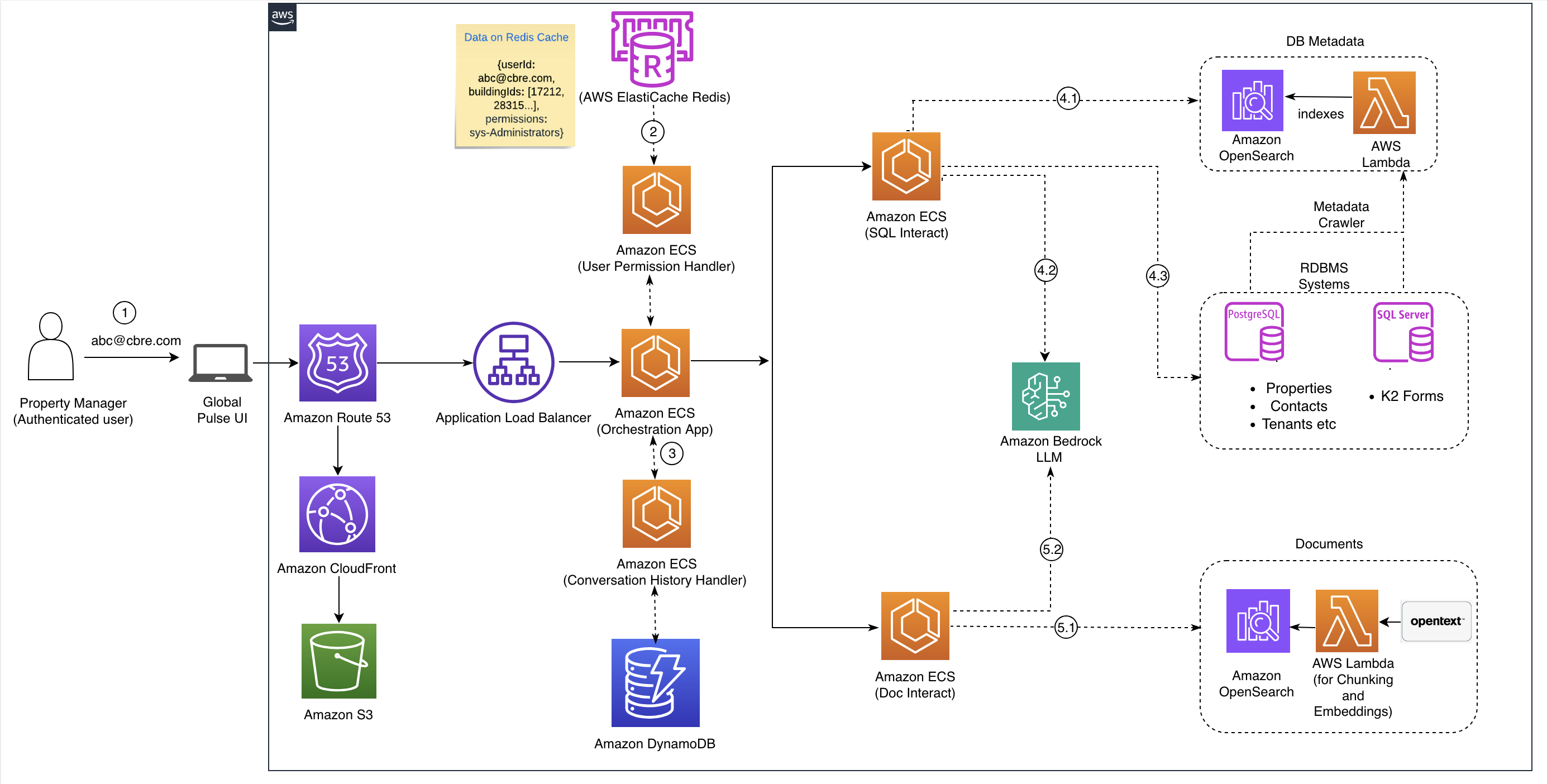
Allow us to undergo the circulate for the answer:
- Property Supervisor and PULSE UI: Property managers work together by the intuitive PULSE consumer interface, which serves because the gateway for each conventional key phrase searches and pure language queries (NLQ). The UI shows search outcomes, helps doc conversations, and presents clever summaries in desktop and cellular.
- Dynamic search execution: When customers submit requests, the system first retrieves user-specific permissions from Amazon ElastiCache for Redis, chosen for its low latency and excessive throughput. Search operations throughout Amazon OpenSearch and transactional databases are then constrained by these user-specific permissions, ensuring customers solely entry approved outcomes with real-time granular management.
- Orchestration layer: This central management hub serves as the appliance’s mind, receiving consumer requests from PULSE UI and intelligently routing them to acceptable backend providers. Key obligations embody:
- Routing queries to related knowledge methods (structured databases, unstructured paperwork, or each for deep search).
- Initiating parallel searches throughout SQL Work together and Doc Work together parts.
- Merging, de-duplicating, and rating outcomes from disparate sources for unified outcomes.
- Managing dialog historical past by Amazon DynamoDB integration.
- SQL work together part (structured knowledge search): This pathway manages interactions with structured relational databases (RDBMS) by these key steps:
- 4.1 Database metadata retrieval: Dynamically fetches schema particulars (for instance, desk names, column names, knowledge varieties, relationships, constraints) for entities like property, contacts, and tenants from an Amazon OpenSearch index.
- 4.2 Amazon Bedrock LLM (Amazon Nova Professional): Interprets the consumer’s pure language question alongside schema metadata, translating it into correct, optimized SQL queries tailor-made to the database. The answer lowered SQL question era time from a median of 12 seconds earlier to 4 seconds utilizing Amazon Nova Professional.
- 4.3 RDBMS methods (PostgreSQL, MS SQL): Precise transactional databases, equivalent to PostgreSQL and MS SQL, which home the core structured property administration knowledge (for instance, properties, contacts, tenants, K2 varieties). They execute the LLM-generated SQL queries and return the structured tabular outcomes again to the SQL Work together part.
- DocInteract Part (Unstructured Doc Search): This pathway is particularly designed for clever search and interplay with unstructured paperwork.
- 5.1 Vector Retailer (OpenSearch Cluster): Shops paperwork, together with these from OpenText, as high-dimensional vectors for environment friendly semantic search utilizing strategies like k-Nearest Neighbors whereas prioritizing velocity and accuracy with metadata filtering.
- 5.2 Amazon Bedrock LLM (Claude Haiku): Interprets NLQs and interprets them into optimized OpenSearch DSL queries, whereas powering the “Chat With AI” function for direct doc interplay, producing concise, conversational responses together with solutions, summaries, and pure dialogue.
Having established the core structure with each SQL Work together and DocInteract parts, the next sections discover the precise optimizations and improvements carried out for every knowledge sort, starting with structured knowledge search enhancements.
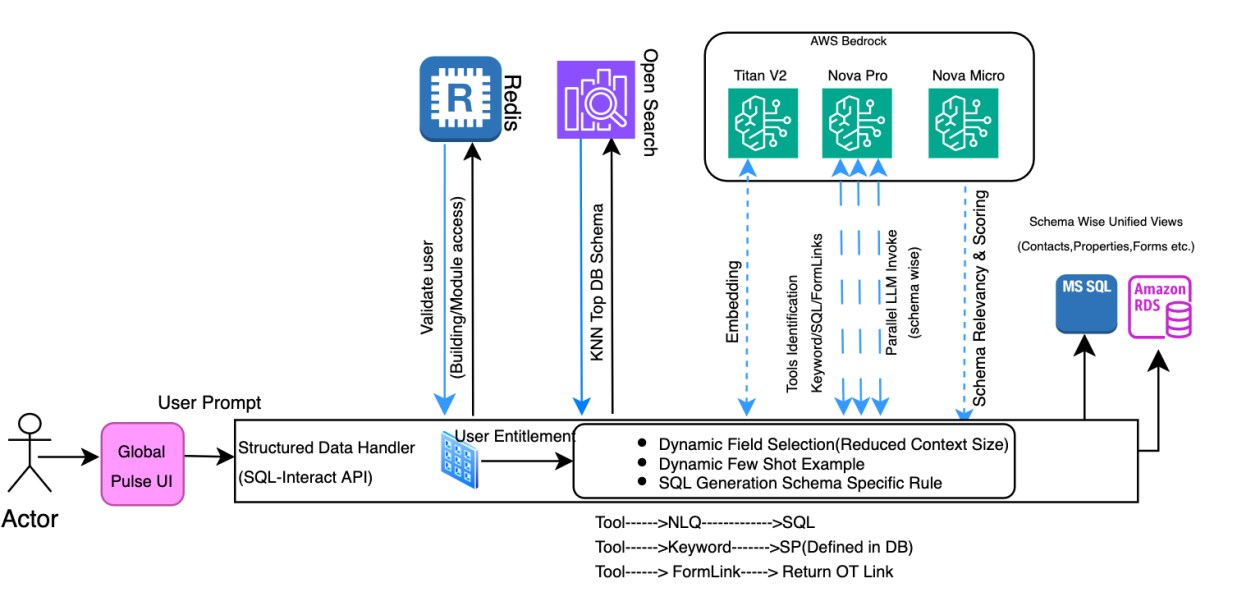
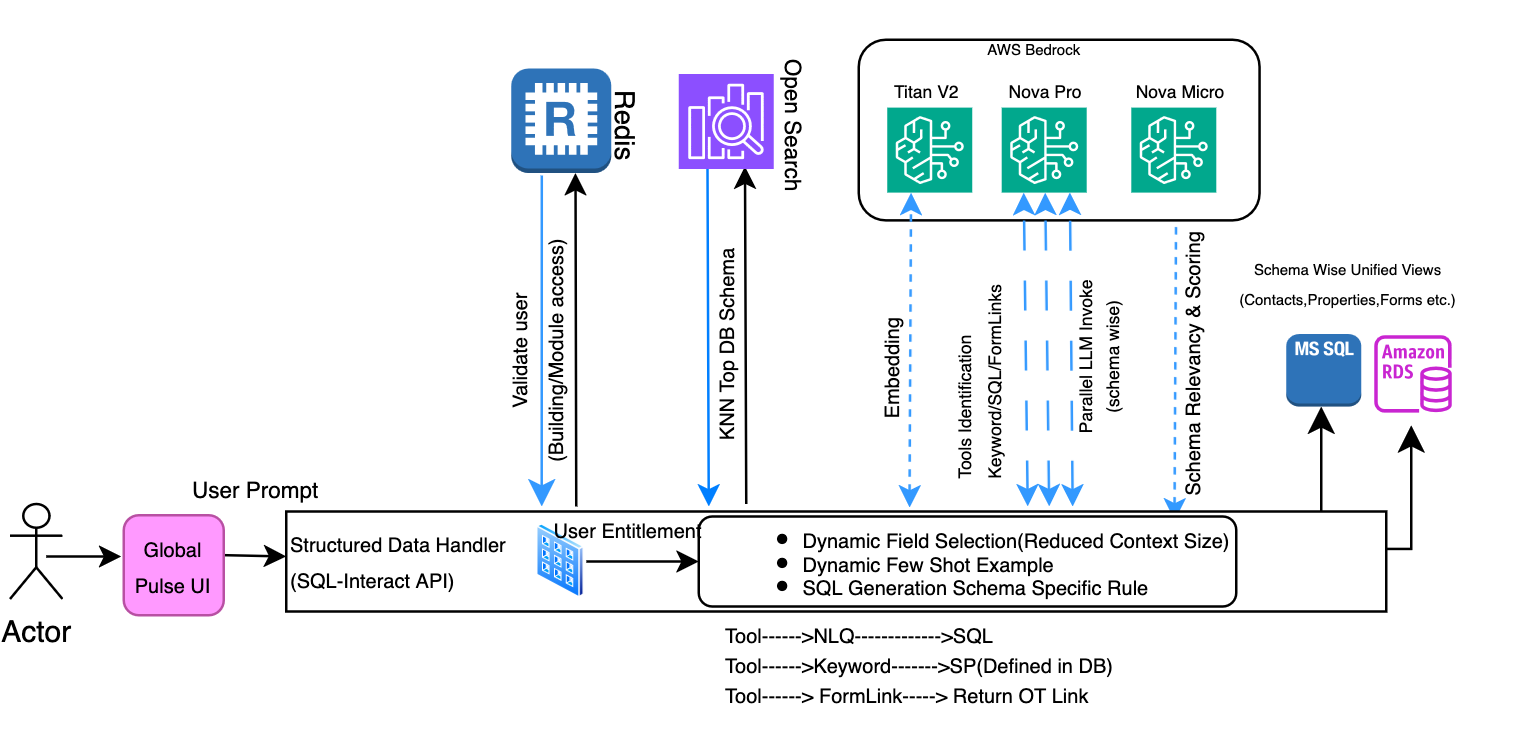
Structured knowledge search
Constructing on the SQL work together part outlined within the structure, the PULSE Search software gives two search strategies for accessing structured knowledge in PostgreSQL and MS SQL. Key phrase Search scans the fields and schemas for particular phrases, facilitating complete protection of the whole knowledge system. With Pure Language Question (NLQ) Search customers can work together with the databases utilizing on a regular basis language, translating queries into database queries. Each strategies help property managers to effectively find and retrieve data throughout the database modules.
Database layer search efficiency enhancement on the SQL stage
Our distinctive problem concerned implementing application-wide key phrase searches that wanted to scan throughout the columns in database tables – a non-conventional requirement in comparison with conventional listed column-specific searches in RDBMS methods. This common search functionality was important for consumer expertise, permitting data discovery with out realizing particular column names or knowledge constructions.
We leveraged native full-text search capabilities in each PostgreSQL and MS SQL Server databases:
- PostgreSQL Implementation:
- Microsoft SQL Server Implementation:
Notice: Our implementation makes use of specialised textual content search columns (textsearchable_all_col) concatenating the searchable fields from the view pd_db_view_name, whereas ms_db_view_name represents a view created with full-text search indexing.
This optimization delivered an 80% enchancment in question efficiency by harnessing native database capabilities whereas balancing complete search protection with optimum database efficiency by specialised indexing algorithms.
Database layer search efficiency enhancement on the SQL work together API stage
We carried out a number of optimizations in database search performance focusing on three key performances (KPIs): Accuracy (precision of outcomes), Consistency (reproducible outcomes), and Relevancy (ensuring outcomes align with consumer intent). The enhancements lowered response latency whereas concurrently boosting these ACR metrics, leading to sooner and extra reliable search outcomes.
Immediate Engineering Modifications: We carried out a complete method to immediate administration and optimization, specializing in the next elements.
- Configurability: We carried out modular immediate templates saved in exterior recordsdata to allow model management, simplified administration, and lowered immediate measurement, enhancing efficiency and maintainability.
- Dynamic discipline choice for context window discount: The system makes use of KNN-based similarity search to filter and choose solely essentially the most related schema fields aligned with consumer intent, lowering context window measurement and optimizing immediate effectiveness.
- Dynamic few-shot instance: The system intelligently selects essentially the most related few-shot instance from a configuration file utilizing KNN-based similarity seek for the SQL era. This sensible, context-aware method makes positive that solely essentially the most pertinent instance is included within the immediate, minimizing pointless knowledge overhead. This method helped in getting constant and correct SQL era from LLM.
- Enterprise rule integration: The system maintains a centralized repository of enterprise guidelines in a devoted schema smart configuration file, making rule administration and updates streamlined and environment friendly. Throughout immediate era, related enterprise guidelines are dynamically built-in into prompts, facilitating consistency in rule software whereas offering flexibility for updates and upkeep.
- LLM score-based relevancy: We added a fourth LLM name to guage and reorder schema relevance after preliminary KNN retrieval, addressing challenges the place vector search returned irrelevant or poorly ordered schemas.For instance, when processing a consumer question about property or contact data, the vector search may return three schemas, however:
- The third schema could be irrelevant to the question.
- The ordering of the 2 related schemas may not mirror their true relevancy to the question.
To handle these challenges, we launched a further LLM processing (4th LLM parallel name) step that:
- Evaluates the relevance of every schema to the consumer question.
- Assigns relevancy scores to find out schema significance.
- Reorders schemas primarily based on their precise relevance to the question.
This enhancement improved our schema choice course of by:
- Ensuring solely really related schemas are chosen.
- Sustaining correct relevancy ordering.
- Offering extra correct context for subsequent question processing.
These enhancements improved schema choice by verifying solely really related schemas are processed, sustaining correct relevancy ordering, and offering extra correct context for question processing. The outcome was extra exact, contextually acceptable responses and improved general software efficiency.
Parallel LLM inference for SQL era with Amazon Nova Professional
We carried out a complete parallel processing structure for NLQ to SQL conversion, enhancing system efficiency and effectivity. The answer introduces concurrent schema-based API calls to the LLM inference engine, with asynchronous processing for a number of schema evaluations. Our security-first method authenticates and validates consumer entitlements whereas performing context-aware schema identification that includes similarity search and enforces entry permissions. The system solely processes schemas for which the consumer has specific authorization, facilitating foundational knowledge safety. Following authentication, the system dynamically generates prompts (as detailed in our immediate engineering framework) and initiates concurrent processing of essentially the most related schemas by parallel LLM inference calls. Earlier than execution, it enhances the generated SQL queries with necessary safety joins that implement building-level entry controls, proscribing customers to their approved buildings solely.
Finalized SQL queries are executed on respective database methods (PostgreSQL or SQL Server). The system processes the question outcomes and returns them as a structured API response, sustaining safety and knowledge integrity all through the whole workflow. This structure facilitates each optimum efficiency by parallel processing and complete safety by multi-layered entry controls.
This built-in method incorporates concurrent validation of generated SQL queries, leading to lowered processing time and improved system throughput and lowered inference latency with Amazon Nova Professional. With introduction of Nova Professional there was important enchancment in inference latency. The framework’s structure facilitates environment friendly useful resource utilization whereas sustaining excessive accuracy in SQL question era, making it notably efficient for dealing with complicated database operations and high-volume question processing necessities.
Enhancing unstructured knowledge search
The PULSE doc search makes use of two principal strategies, enhanced by purpose-built specialised search features. Customers can use the streamlined Key phrase Search to exactly find phrases inside paperwork and metadata for quick retrieval when exact search phrases are recognized. This easy method makes positive customers can rapidly find actual matches throughout the whole doc panorama. The second methodology, Pure Language Question (NLQ) Search, helps interplay with paperwork utilizing on a regular basis language, decoding intent and changing queries into search parameters—notably highly effective for complicated or idea -based queries. Complementing these core search strategies, the system gives specialised search capabilities together with Favorites and Collections search so customers can effectively navigate their personally curated doc units and shared collections. Moreover, the system supplies clever doc add search performance that helps customers rapidly find acceptable doc classes and add places primarily based on doc varieties and property contexts.
The search infrastructure helps complete file codecs together with PDFs, Microsoft Workplace paperwork (Phrase, Excel, PowerPoint), emails (MSG), photographs (JPG, PNG), textual content recordsdata, HTML recordsdata, and varied different doc varieties, facilitating complete protection throughout the doc classes within the property administration setting.
Immediate engineering and administration optimization
Our Doc Search system incorporates superior immediate engineering strategies to boost search accuracy, effectivity, and maintainability. Let’s discover the important thing options of our immediate administration system and the worth they bring about to the search expertise.
Two-stage immediate structure and modular immediate administration:
On the core of our system is a two-stage immediate structure. This design separates software choice from activity execution for extra environment friendly and correct question processing.
This structure reduces token utilization by as much as 60% by loading solely needed prompts per question processing stage. The light-weight preliminary stage rapidly routes queries to acceptable instruments, whereas specialised prompts deal with the precise execution with centered context, enhancing each efficiency and accuracy in software choice and question execution.
Our modular immediate administration system shops prompts in exterior configuration recordsdata for dynamic loading primarily based on context and supporting personalization. It helps immediate updates with out code deployments, reducing replace cycles from hours to minutes. This structure facilitates A/B testing of various immediate variations and fast rollbacks, enhancing system adaptability and reliability.
The system implements context-aware immediate choice, adapting to question varieties, doc traits, and search contexts. This method makes positive that essentially the most acceptable immediate and question construction are used for every distinctive search state of affairs. For instance, the system distinguishes between completely different query varieties (for instance, ‘list_question’) for tailor-made processing of varied question intents.
Search algorithm optimization
Our doc search system implements search algorithms that mix vector-based semantic search with conventional text-based approaches to look throughout doc metadata and content material. We use completely different question methods optimized for particular search eventualities.
Key phrase search:
Key phrase search makes use of a twin technique combining each metadata and content material searches utilizing phrase matching. A hard and fast question template construction facilitates effectivity and consistency, incorporating predefined metadata, content material, permission guidelines, and constructing ID constraints, whereas dynamically integrating user-specific phrases and roles. This method permits for quick and dependable searches whereas sustaining correct entry controls and relevance.
Person queries like “lease settlement” or “property tax 2023” are parsed into part phrases, every requiring a match within the doc content material for relevancy, facilitating exact outcomes.
Equally, for metadata searches, the system makes use of phrase looking throughout metadata fields:
This method supplies actual matching capabilities throughout doc metadata, facilitating exact outcomes when customers are looking for particular doc properties. The system executes each search varieties concurrently and outcomes from each searches are then merged and deduplicated, with scoring normalized throughout each outcome units.
Pure language question search:
Our NLQ search combines LLM-generated queries with vector-based semantic search by two principal parts. The metadata search makes use of an LLM to generate OpenSearch queries from pure language enter. As an illustration, “Discover lease agreements mentioning early termination for tech firms from final 12 months” is remodeled right into a structured question that searches throughout doc varieties, dates, property names and different metadata fields.
For content material searches, we make use of KNN vector search with a Okay-factor of 5 to determine semantically comparable content material. The system converts queries into vector embeddings and executes each metadata and content material searches concurrently, combining outcomes whereas minimizing duplicates.
Chat with Doc (digital assistant for in-depth doc interplay):
The Chat with Doc function helps pure dialog with particular paperwork after preliminary search. Customers can ask questions, request summaries, or search particular data from chosen paperwork by an easy interplay course of.
When engaged, the system retrieves the whole doc content material utilizing its node identifier and processes consumer queries by a streamlined pipeline. Every question is dealt with by an LLM utilizing fastidiously constructed prompts that mix the consumer’s query with related doc context.
With this functionality customers can extract data from complicated paperwork effectively. For instance, property managers can rapidly perceive lease phrases or fee schedules with out manually scanning prolonged agreements. The function supplies prompt summaries and explanations for speedy data entry and decision-making in document-intensive workflows.
Scaling doc ingestion
To deal with high-throughput doc processing and large-scale enterprise ingestion, our ingestion pipeline makes use of asynchronous Amazon Textract for scalable, parallel textual content extraction. The structure effectively processes numerous file types-PDFs, PPTs, Phrase paperwork, Excel recordsdata and images-even with a whole bunch of pages or high-resolution content material. As soon as a doc is uploaded to an Amazon S3 bucket, a message triggers an SQS queue, invoking a Lambda operate that initiates an asynchronous Textract job, offloading heavy extraction and OCR duties with out blocking execution.
For textual content paperwork, the system reads the file from Amazon S3 and submits it to Amazon Textract’s asynchronous API, which processes the doc within the background. As soon as the job completes, the outcomes are retrieved and parsed to extract structured textual content. This textual content is then chunked intelligently—primarily based on token rely or semantic boundaries—and handed by a Bedrock embedding mannequin (For instance, Amazon Titan Textual content embeddings v2). Every chunk is enriched with metadata and listed into Amazon OpenSearch for quick and context-aware search capabilities. As soon as ingested, our clever question technique, pushed by consumer and CBRE market lookups, dynamically directs searches to the related OpenSearch indexes.
Picture recordsdata observe an analogous circulate however use Amazon Bedrock Claude 3 Haiku for OCR after base64 conversion. Extracted textual content is then chunked, embedded, and listed like normal textual content paperwork.
Safety and entry management
Person authentication and authorization happens by a multi-layered safety course of:
- Entry token validation: The system verifies the consumer’s id by validating the consumer id in Microsoft B2C and their entry token in opposition to every request. The consumer can also be checked for his or her authorization to entry software.
- Entitlement verification: Concurrently, the system checks the consumer’s permissions in a Redis database to confirm they’ve the suitable entry rights to particular modules in software and database schemas (entitlements) they’re approved to question on.
- Property entry validation: The system additionally retrieves their approved constructing record from Redis database (constructing id record to which the consumer is mapped), ensuring they’ll solely entry knowledge associated to their properties inside their enterprise portfolio.
This parallel validation course of facilitates safer and acceptable entry whereas sustaining optimum efficiency by Redis’s high-speed knowledge retrieval capabilities. Redis is populated throughout the software load by mapping consumer entitlement and constructing mapping maintained within the database. If the consumer particulars should not present in Redis an API is invoked to replenish the Redis database.

Outcomes and impression
CBRE’s expertise with this initiative has led to enhanced operational effectivity and knowledge reliability, immediately translating into tangible enterprise advantages:
- Value financial savings and useful resource optimization: By lowering hours of handbook effort yearly per consumer, the enterprise can understand substantial value financial savings (for instance, in labor prices, lowered time beyond regulation, or reallocated personnel). This frees up invaluable consumer time in order that the crew can give attention to extra strategic, high-value duties that drive constructing efficiency, innovation and progress slightly than repetitive handbook processes.
- Improved decision-making and danger mitigation: Delivering outcomes with 95% accuracy for enterprise selections which can be primarily based on extremely dependable knowledge. This minimizes the chance of errors, resulting in extra knowledgeable methods, fewer expensive errors, and finally, higher enterprise outcomes.
- Elevated productiveness and throughput: With much less time spent on handbook duties and the next assurance of information high quality, workflows can change into smoother and sooner. This interprets to elevated general productiveness and doubtlessly greater throughput for associated processes, enhancing service supply.
Classes realized and finest practices
The next are our classes realized and finest practices primarily based on our expertise constructing this answer:
- Use immediate modularization: Immediate engineering is crucial for optimizing software efficiency and sustaining constant outcomes. Breaking prompts into modular parts helped in higher immediate administration, enhanced management and maintainability by streamlined model management, simplified testing and validation processes, and improved efficiency monitoring capabilities. The modular method to immediate design lowered token utilization, which in flip decreased LLM response instances and improved general system efficiency. Module method additionally helps in enhanced SQL era effectivity by sooner troubleshooting, lowered implementation time, and extra dependable question era, leading to faster decision of edge instances and enterprise rule updates.
- Present correct few shot instance: For elevated accuracy and consistency of SQL era, use dynamic few shot instance with modular parts for seamless updates to instance repository.
- Embody examples overlaying widespread use instances and edge eventualities.
- Preserve a various set of high-quality instance pairs overlaying varied enterprise eventualities.
- Maintain examples concise and centered on particular patterns.
- Repeatedly replace examples primarily based on new enterprise necessities. Take away or replace outdated examples.
- Restrict to top-1 or top-2 most related examples to handle token utilization.
- Repeatedly validate the relevance of chosen examples.
- Arrange suggestions loops to constantly enhance instance matching accuracy.
- Fantastic-tune similarity thresholds for optimum instance matching.
- Scale back the context window: For lowering the context window measurement of the context handed, choose solely the top-N KNN fields from the schema definition together with key/necessary fields. Solely apply the dynamic context discipline choice for schema the place excessive variety of fields are current and growing the context window measurement.
- Enhance relevancy: LLM Scoring mechanism helped us in getting the fitting related set of schemas (modules). Harnessing LLM intelligence over the KNN results of related module helped us get essentially the most related ordered outcomes. Additionally take into account:
- Vector similarity alone might not seize true semantic relevance.
- High-Okay nearest neighbors don’t all the time assure contextual accuracy.
- Order of outcomes might not mirror precise relevance to the question.
- Use of LLM Scoring offered a extra correct schema relevancy willpower.
Conclusion
CBRE Property Administration and AWS collectively demonstrated how modern cloud AI options can unlock actual enterprise worth at scale. Through the use of AWS providers and finest practices, enterprises can reimagine how they entry, handle, and derive perception from their knowledge and take actual motion.
To learn the way your group can speed up digital transformation with AWS, contact your AWS account crew or begin exploring AWS AI and knowledge analytics providers right this moment.
Additional studying on AWS providers featured on this answer:
Concerning the authors
 Lokesha Thimmegowda is a Senior Principal Software program Engineer at CBRE, specializing in synthetic intelligence and AWS. With 4 AWS certifications, together with Options Architect Skilled and AWS AI Practitioner, he excels at guiding groups by complicated challenges with modern options. Lokesha is captivated with designing transformative answer architectures that drive effectivity. Outdoors of labor, he enjoys each day tennis along with his daughters and weekend cricket.
Lokesha Thimmegowda is a Senior Principal Software program Engineer at CBRE, specializing in synthetic intelligence and AWS. With 4 AWS certifications, together with Options Architect Skilled and AWS AI Practitioner, he excels at guiding groups by complicated challenges with modern options. Lokesha is captivated with designing transformative answer architectures that drive effectivity. Outdoors of labor, he enjoys each day tennis along with his daughters and weekend cricket.
 Muppirala Venkata Krishna Kumar Principal Software program Engineer at CBRE with over 18 years of experience in main technical groups and designing end-to-end options throughout numerous domains. A strategic technical lead with a robust command over each front-end and back-end applied sciences, cloud structure utilizing AWS, and AI/ML-driven improvements. Obsessed with staying on the forefront of expertise, constantly studying, and implementing fashionable instruments to drive impactful outcomes. Outdoors of labor, values high quality time with household and enjoys religious journey experiences that deliver steadiness and inspiration.
Muppirala Venkata Krishna Kumar Principal Software program Engineer at CBRE with over 18 years of experience in main technical groups and designing end-to-end options throughout numerous domains. A strategic technical lead with a robust command over each front-end and back-end applied sciences, cloud structure utilizing AWS, and AI/ML-driven improvements. Obsessed with staying on the forefront of expertise, constantly studying, and implementing fashionable instruments to drive impactful outcomes. Outdoors of labor, values high quality time with household and enjoys religious journey experiences that deliver steadiness and inspiration.
 Maraka Vishwadev is a Senior Employees Engineer at CBRE with 18 years of expertise in enterprise software program growth, specializing in backend–frontend applied sciences and AWS Cloud. He leads impactful initiatives in Generative AI, leveraging Massive Language Fashions to drive clever automation, improve consumer experiences, and unlock new enterprise capabilities. He’s deeply concerned in architecting and delivering scalable, safe, and cloud-native options, aligning expertise with enterprise technique. Vishwa balances his skilled life with cooking, motion pictures, and high quality household time.
Maraka Vishwadev is a Senior Employees Engineer at CBRE with 18 years of expertise in enterprise software program growth, specializing in backend–frontend applied sciences and AWS Cloud. He leads impactful initiatives in Generative AI, leveraging Massive Language Fashions to drive clever automation, improve consumer experiences, and unlock new enterprise capabilities. He’s deeply concerned in architecting and delivering scalable, safe, and cloud-native options, aligning expertise with enterprise technique. Vishwa balances his skilled life with cooking, motion pictures, and high quality household time.
 Chanpreet Singh is a Senior Marketing consultant at AWS with 18+ years of trade expertise, specializing in Knowledge Analytics and AI/ML options. He companions with enterprise prospects to architect and implement cutting-edge options in Large Knowledge, Machine Studying, and Generative AI utilizing AWS native providers, companion options and open-source applied sciences. A passionate technologist and drawback solver, he balances his skilled life with nature exploration, studying, and high quality household time.
Chanpreet Singh is a Senior Marketing consultant at AWS with 18+ years of trade expertise, specializing in Knowledge Analytics and AI/ML options. He companions with enterprise prospects to architect and implement cutting-edge options in Large Knowledge, Machine Studying, and Generative AI utilizing AWS native providers, companion options and open-source applied sciences. A passionate technologist and drawback solver, he balances his skilled life with nature exploration, studying, and high quality household time.
 Sachin Khanna is a Lead Marketing consultant specializing in Synthetic Intelligence and Machine Studying (AI/ML) inside the AWS Skilled Companies crew. With a robust background in knowledge administration, generative AI, giant language fashions, and machine studying, he brings in depth experience to tasks involving knowledge, databases, and AI-driven options. His proficiency in cloud migration and value optimization has enabled him to information prospects by profitable cloud adoption journeys, delivering tailor-made options and strategic insights.
Sachin Khanna is a Lead Marketing consultant specializing in Synthetic Intelligence and Machine Studying (AI/ML) inside the AWS Skilled Companies crew. With a robust background in knowledge administration, generative AI, giant language fashions, and machine studying, he brings in depth experience to tasks involving knowledge, databases, and AI-driven options. His proficiency in cloud migration and value optimization has enabled him to information prospects by profitable cloud adoption journeys, delivering tailor-made options and strategic insights.
 Dwaragha Sivalingam is a Senior Options Architect specializing in generative AI at AWS, serving as a trusted advisor to prospects on cloud transformation and AI technique. With seven AWS certifications together with ML Specialty, he has helped prospects in lots of industries, together with insurance coverage, telecom, utilities, engineering, building, and actual property. A machine studying fanatic, he balances his skilled life with household time, having fun with street journeys, motion pictures, and drone images.
Dwaragha Sivalingam is a Senior Options Architect specializing in generative AI at AWS, serving as a trusted advisor to prospects on cloud transformation and AI technique. With seven AWS certifications together with ML Specialty, he has helped prospects in lots of industries, together with insurance coverage, telecom, utilities, engineering, building, and actual property. A machine studying fanatic, he balances his skilled life with household time, having fun with street journeys, motion pictures, and drone images.



{kind=link}