At AWS re:Invent 2024, we launched a brand new innovation in Amazon SageMaker HyperPod on Amazon Elastic Kubernetes Service (Amazon EKS) that lets you run generative AI improvement duties on shared accelerated compute assets effectively and cut back prices by as much as 40%. Directors can use SageMaker HyperPod activity governance to control allocation of accelerated compute to groups and tasks, and implement insurance policies that decide the priorities throughout several types of duties. The ensuing enchancment in utilization of compute assets permits organizations to give attention to accelerating their generative AI innovation and time to market, as a substitute of spending time coordinating useful resource allocation and constantly replanning their generative AI improvement duties.
On this submit, we offer finest practices to maximise the worth of SageMaker HyperPod activity governance and make the administration and information science experiences seamless. We additionally talk about widespread governance situations when administering and working generative AI improvement duties.
Stipulations
To get began with SageMaker HyperPod activity governance on an present SageMaker HyperPod cluster orchestrated by Amazon EKS, be sure to uninstall any present Kueue installations, and have a Kubernetes cluster working model 1.30+.
Administration expertise
Directors are the primary persona interacting with SageMaker HyperPod activity governance. They’re answerable for managing the cluster compute allocation in line with the group’s priorities and targets.
Managing compute
Step one to managing capability throughout groups is to arrange compute allocations. When establishing a compute allocation, take into account the next issues:
- What sort of duties does this crew usually run?
- Does this crew consistently run duties and require reserved capability?
- What is that this crew’s precedence relative to different groups?
When establishing a compute allocation, an administrator units the crew’s fair-share weight, which gives relative prioritization comparative to different groups when vying for a similar idle compute. Larger weight permits a crew to entry unutilized assets inside shared capability sooner. As a finest follow, set the fair-share weight larger for groups that may require entry to capability before different groups.
After the fair-share weight is ready, the administrator then units up the quota and borrowing technique. Quota determines the allocation per occasion sort throughout the cluster’s occasion teams. Borrowing technique determines whether or not a crew will share or reserve their allotted capability. To implement correct quota administration, the full reserved quota shouldn’t surpass the cluster’s accessible capability for that useful resource. For example, if a cluster includes 20 ml.c5.2xlarge cases, the cumulative quota assigned to groups ought to stay below 20.
If the compute allocations for groups permit for “Lend and Borrow” or “Lend,” the idle capability is shared between these groups. For instance, if Staff A has a quota of 6 however is utilizing solely 2 for its duties, and Staff B has a quota of 5 and is utilizing 4 for its duties, and a activity that’s submitted to Staff B requiring 4 assets, 3 might be borrowed from Staff A primarily based on its “Lend and Borrow” settings. If any crew’s compute allocations setting is ready to “Don’t Lend,” the crew will be unable to borrow any extra capability past its reserved capability.
To keep up a pool or a set of assets that each one groups can borrow from, customers can arrange a devoted crew with assets that bridge the hole between different groups’ allocations and the full cluster capability. Be sure that this cumulative useful resource allocation contains the suitable occasion varieties and doesn’t exceed the full cluster capability. To ensure that these assets may be shared amongst groups, allow the taking part groups to have their compute allocations set to “Lend and Borrow” or “Lend” for this widespread pool of assets. As well as, each time new groups are launched, or quota allocations are modified or there are any adjustments to the cluster capability, revisit the quota allocations of all of the groups, to verify the cumulative quota stays at or beneath cluster capability.
After compute allocations have been set, the administrator may even have to set a cluster coverage, which is comprised of two parts: activity prioritization and idle compute allocation. Directors will arrange a activity prioritization, which determines the precedence degree for duties working in a cluster. Subsequent, an administrator will set idle compute allocation setting to both “first come, first serve,” wherein duties will not be prioritized, or “fair-share allocation,” wherein idle compute is distributed to groups primarily based on their fair-share weight.
Observability
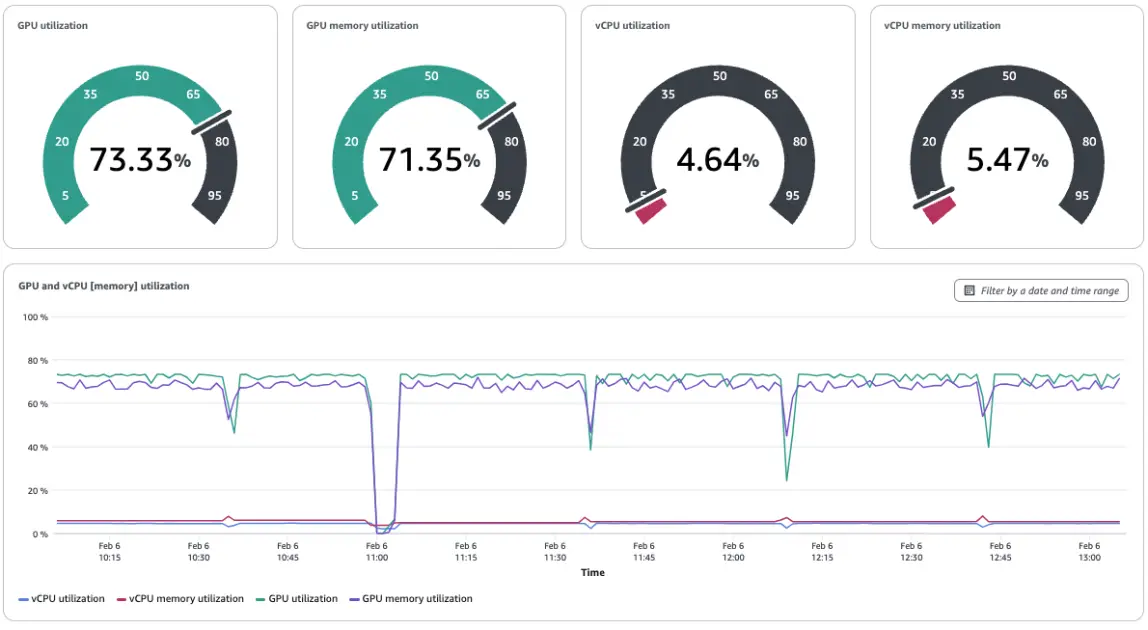
To get began with observability, set up the Amazon CloudWatch Observability add-on with Kueue metrics chosen. The SageMaker HyperPod activity governance dashboard gives a single pane of glass view for cluster utilization throughout groups. At current, you possibly can view duties working for PyTorch, TensorFlow, and MPI duties. Directors can analyze the graphs throughout the dashboard to know fairness in useful resource sharing and utilization of assets.
To view utilization of assets, customers can see the next dashboard exhibiting GPU and vCPU utilization. These graphs inform directors the place groups can additional maximize their GPU utilization. On this instance, directors observe GPU utilization round 52%

Directors have a real-time view of utilization of cases as duties are working or moved to pending throughout preemption. On this instance, the ML engineering crew is borrowing 5 GPUs for his or her coaching activity


With SageMaker HyperPod, you possibly can moreover arrange observability instruments of your alternative. In our public workshop, we’ve got steps on methods to arrange Amazon Managed Prometheus and Grafana dashboards.
Knowledge scientist expertise
Knowledge scientists are the second persona interacting with SageMaker HyperPod clusters. Knowledge scientists are answerable for the coaching, fine-tuning, and deployment of fashions on accelerated compute cases. It’s essential to verify information scientists have the mandatory capability and permissions when interacting with clusters of GPUs.
Entry management
When working with SageMaker HyperPod activity governance, information scientists will assume their particular position. Every information science crew might want to have their very own position and related role-based entry management (RBAC) on the cluster. RBAC prevents information scientists from submitting duties to groups wherein they don’t belong. For extra details about information science position permissions, see AWS Id and Entry Administration for SageMaker HyperPod. As a finest follow, directors ought to restrict information scientists in line with the precept of least privilege. After roles and entry entries are arrange, information scientists can assume their related AWS Id and Entry Administration (IAM) position to submit duties to corresponding namespaces. It’s essential to notice that customers interacting with the console dashboard who didn’t create the related EKS cluster might want to have their position added to the AccessEntry checklist for the EKS cluster.
Submitting duties
There are two methods to submit duties on Amazon EKS orchestrated SageMaker HyperPod clusters: kubectl and the SageMaker HyperPod CLI. With each choices, information scientists might want to reference their crew’s namespace and activity precedence class within the activity configuration file with a view to use their allotted quota with acceptable prioritization. If the consumer doesn’t a specify precedence class, then SageMaker HyperPod activity governance will robotically assume the bottom precedence.
Within the following code snippet, we present the labels required in a kubectl manifest file for the researchers namespace with inference precedence. Precedence lessons can have -priority appended to the identify set within the cluster coverage. For additional steering on submitting duties to SageMaker HyperPod activity governance, observe the documentation right here.
metadata:
identify: job-name
namespace: hyperpod-ns-researchers
labels:
kueue.x-k8s.io/queue-name: hyperpod-ns-researchers-localqueue
kueue.x-k8s.io/priority-class: inference-priorityHyperPod CLI
The HyperPod CLI was created to summary the complexities of working with kubectl and allow builders utilizing SageMaker HyperPod to iterate quicker with customized instructions. HyperPod CLI v2.0.0 introduces a brand new default scheduler sort with autofill instructions, auto discovery of namespaces, improved cluster and activity administration options, and enhanced visibility into activity priorities and accelerator quota allocations. Knowledge scientists can use the brand new HyperPod CLI to shortly submit duties, iterate, and experiment of their generative AI improvement lifecycle.
Pattern instructions
The next is a brief reference information for useful instructions when interacting with SageMaker HyperPod activity governance:
- Describing cluster coverage with the AWS CLI – This AWS Command Line Interface (AWS CLI) command is beneficial to view the cluster coverage settings in your cluster.
- Listing compute quota allocations with the AWS CLI – This AWS CLI command is beneficial to view the totally different groups and arrange activity governance and their respective quota allocation settings.
- HyperPod CLI – The HyperPod CLI abstracts widespread kubectl instructions used to work together with SageMaker HyperPod clusters equivalent to submitting, itemizing, and cancelling duties. Seek advice from the for a full checklist of instructions.
- kubectl – You may as well use kubectl to work together with activity governance with the next instance instructions:
kubectl get pytorchjobs -n hyperpod-ns-This command reveals you the PyTorch duties working within the specified crew namespace.kubectl get workloads -n hyperpod-ns-/kubectl describe workload– These instructions present the workloads working in your cluster per namespace and supply detailed reasonings on Kueue Admission. You should use these instructions to reply questions equivalent to “Why was my activity preempted?” or “Why did my activity get admitted?”-n hyperpod-ns-
Frequent situations
SageMaker HyperPod activity governance permits allocating compute quota to groups, growing utilization of compute assets, lowering prices, and accelerating ready duties by precedence and in flip accelerating time to market. To narrate these worth propositions to actual work situations, we’ll discuss a enterprise and a startup scenario.
Enterprises have totally different groups working in direction of varied enterprise targets, every with budgets that restrict their compute entry. To maximise useful resource utilization inside price range constraints, SageMaker HyperPod activity governance permits enterprises to allocate compute quotas to groups for synthetic intelligence and machine studying (AI/ML) duties. When groups expend their allocation, they’ll entry idle compute from different groups to speed up ready duties, offering optimum useful resource utilization throughout the group.
Startups goal to maximise compute useful resource utilization whereas reaching well timed allocation for high-priority duties. SageMaker HyperPod activity governance’s prioritization function means that you can assign priorities to totally different activity varieties, equivalent to prioritizing inference over coaching. This makes positive that high-priority duties obtain mandatory compute assets earlier than lower-priority ones, optimizing total useful resource allocation.
Now we’ll stroll you thru two widespread situations for customers interacting with SageMaker HyperPod activity governance.
Situation 1: Enterprise
Within the first state of affairs, we’ve got an enterprise firm who needs to handle compute allocations to optimize for value. This firm has 5 groups sharing 80 GPUs, with the next configuration:
- Staff 1 – Compute allocation: 20; Technique: Don’t Lend
- Staff 2 – Compute allocation: 20; Technique: Don’t Lend
- Staff 3 – Compute allocation: 5; Technique: Lend & Borrow at 150%; Truthful-share weight: 100
- Staff 4 – Compute allocation: 10; Technique: Lend & Borrow at 100%; Truthful-share weight: 75
- Staff 5 – Compute allocation: 25; Technique: Lend & Borrow at 50%; Truthful-share weight: 50
This pattern configuration reserves capability to groups that might be consistently utilizing cases for high-priority duties. As well as, just a few groups have the choice to lend and borrow idle compute from different groups—this improves value optimization by reserving capability as wanted and permitting non-consistent workloads to run utilizing accessible idle compute with prioritization.
Situation 2: Startup
Within the second state of affairs, we’ve got a startup buyer who needs to offer equitable compute allocation for members of their engineering and analysis groups. This firm has three groups sharing 15 GPUs:
- Staff 1 (ML engineering) – Compute allocation: 6; Technique: Lend & Borrow at 50%; Truthful-share weight: 100
- Staff 2 (Researchers) – Compute allocation: 5; Technique: Lend & Borrow at 50%; Truthful-share weight: 100
- Staff 3 (Actual-time chatbot) – Compute allocation: 4; Technique: Don’t Lend; Truthful-share weight: 100
This pattern configuration promotes equitable compute allocation throughout the corporate as a result of all groups have the identical fair-share weight and are capable of preempt duties with decrease precedence.

Conclusion
On this submit, we mentioned finest practices for environment friendly use of SageMaker HyperPod activity governance. We additionally offered sure patterns that you may undertake whereas administering generative AI duties, whether or not you might be aiming to optimize for value or optimize for equitable compute allocation. To get began with SageMaker HyperPod activity governance, discuss with the Amazon EKS Assist in Amazon SageMaker HyperPod workshop and SageMaker HyperPod activity governance.
In regards to the Writer
 Nisha Nadkarni is a Senior GenAI Specialist Options Architect at AWS, the place she guides corporations via finest practices when deploying giant scale distributed coaching and inference on AWS. Previous to her present position, she spent a number of years at AWS centered on serving to rising GenAI startups develop fashions from ideation to manufacturing.
Nisha Nadkarni is a Senior GenAI Specialist Options Architect at AWS, the place she guides corporations via finest practices when deploying giant scale distributed coaching and inference on AWS. Previous to her present position, she spent a number of years at AWS centered on serving to rising GenAI startups develop fashions from ideation to manufacturing.
 Chaitanya Hazarey leads software program improvement for SageMaker HyperPod activity governance at Amazon, bringing intensive experience in full-stack engineering, ML/AI, and information science. As a passionate advocate for accountable AI improvement, he combines technical management with a deep dedication to advancing AI capabilities whereas sustaining moral issues. His complete understanding of recent product improvement drives innovation in machine studying infrastructure.
Chaitanya Hazarey leads software program improvement for SageMaker HyperPod activity governance at Amazon, bringing intensive experience in full-stack engineering, ML/AI, and information science. As a passionate advocate for accountable AI improvement, he combines technical management with a deep dedication to advancing AI capabilities whereas sustaining moral issues. His complete understanding of recent product improvement drives innovation in machine studying infrastructure.
 Kareem Syed-Mohammed is a Product Supervisor at AWS. He’s centered on compute optimization and value governance. Previous to this, at Amazon QuickSight, he led embedded analytics, and developer expertise. Along with QuickSight, he has been with AWS Market and Amazon retail as a Product Supervisor. Kareem began his profession as a developer for name middle applied sciences, Native Professional and Adverts for Expedia, and administration guide at McKinsey.
Kareem Syed-Mohammed is a Product Supervisor at AWS. He’s centered on compute optimization and value governance. Previous to this, at Amazon QuickSight, he led embedded analytics, and developer expertise. Along with QuickSight, he has been with AWS Market and Amazon retail as a Product Supervisor. Kareem began his profession as a developer for name middle applied sciences, Native Professional and Adverts for Expedia, and administration guide at McKinsey.



{kind=link}