
An open-source initiative that will help you deploy generative search based mostly in your native recordsdata and self-hosted (Mistral, Llama 3.x) or industrial LLM fashions (GPT4, GPT4o, and so forth.)
I’ve beforehand written about constructing your individual easy generative search, in addition to on the VerifAI mission on In the direction of Information Science. Nonetheless, there was a significant replace price revisiting. Initially, VerifAI was developed as a biomedical generative search with referenced and AI-verified solutions. This model continues to be obtainable, and we now name it VerifAI BioMed. It may be accessed right here: https://app.verifai-project.com/.
The foremost replace, nevertheless, is that you could now index your native recordsdata and switch them into your individual generative search engine (or productiveness engine, as some refer to those programs based mostly on GenAI). It will probably serve additionally as an enterprise or organizational generative search. We name this model VerifAI Core, because it serves as the muse for the opposite model. On this article, we’ll discover how one can in a couple of easy steps, deploy it and begin utilizing it. On condition that it has been written in Python, it may be run on any form of working system.
The easiest way to explain a generative search engine is by breaking it down into three elements (or parts, in our case):
- Indexing
- Retrieval-Augmented Technology (RAG) Methodology
- VerifAI accommodates an extra part, which is a verification engine, on high of the same old generative search capabilities
Indexing in VerifAI might be performed by pointing its indexer script to a neighborhood folder containing recordsdata resembling PDF, MS Phrase, PowerPoint, Textual content, or Markdown (.md). The script reads and indexes these recordsdata. Indexing is carried out in twin mode, using each lexical and semantic indexing.
For lexical indexing, VerifAI makes use of OpenSearch. For semantic indexing, it vectorizes chunks of the paperwork utilizing an embedding mannequin specified within the configuration file (fashions from Hugging Face are supported) after which shops these vectors in Qdrant. A visible illustration of this course of is proven within the diagram under.

In the case of answering questions utilizing VerifAI, the tactic is considerably complicated. Person questions, written in pure language, endure preprocessing (e.g., stopwords are excluded) and are then remodeled into queries.
For OpenSearch, solely lexical processing is carried out (e.g., excluding stopwords), and probably the most related paperwork are retrieved. For Qdrant, the question is remodeled into embeddings utilizing the identical mannequin that was used to embed doc chunks after they had been saved in Qdrant. These embeddings are then used to question Qdrant, retrieving probably the most related paperwork based mostly on dot product similarity. The dot product is employed as a result of it accounts for each the angle and magnitude of the vectors.
Lastly, the outcomes from the 2 engines should be merged. That is performed by normalizing the retrieval scores from every engine to values between 0 and 1 (achieved by dividing every rating by the best rating from its respective engine). Scores similar to the identical doc are then added collectively and sorted by their mixed rating in descending order.
Utilizing the retrieved paperwork, a immediate is constructed. The immediate accommodates directions, the highest paperwork, and the consumer’s query. This immediate is then handed to the big language mannequin of selection (which might be specified within the configuration file, or, if no mannequin is about, defaults to our regionally deployed fine-tuned model of Mistral). Lastly, a verification mannequin is utilized to make sure there aren’t any hallucinations, and the reply is introduced to the consumer via the GUI. The schematic of this course of is proven within the picture under.

To put in VerifAI Generative Search, you can begin by cloning the most recent codebase from GitHub or utilizing one of many obtainable releases.
git clone https://github.com/nikolamilosevic86/verifAI.git
When putting in VerifAI Search, it’s endorsed to start out by making a clear Python surroundings. I’ve examined it with Python 3.6, however it ought to work with most Python 3 variations. Nonetheless, Python 3.10+ might encounter compatibility points with sure dependencies.
To create a Python surroundings, you should utilize the venv library as follows:
python -m venv verifai
supply verifai/bin/activate
After activating the surroundings, you’ll be able to set up the required libraries. The necessities file is situated within the verifAI/backend listing. You may run the next command to put in all of the dependencies:
pip set up -r necessities.txt
The following step is configuring VerifAI and its interactions with different instruments. This may be performed both by setting surroundings variables straight or by utilizing an surroundings file (the popular possibility).
An instance of an surroundings file for VerifAI is offered within the backend folder as .env.native.instance. You may rename this file to .env, and the VerifAI backend will routinely learn it. The file construction is as follows:
SECRET_KEY=6293db7b3f4f67439ad61d1b798242b035ee36c4113bf870
ALGORITHM=HS256DBNAME=verifai_database
USER_DB=myuser
PASSWORD_DB=mypassword
HOST_DB=localhost
OPENSEARCH_IP=localhost
OPENSEARCH_USER=admin
OPENSEARCH_PASSWORD=admin
OPENSEARCH_PORT=9200
OPENSEARCH_USE_SSL=False
QDRANT_IP=localhost
QDRANT_PORT=6333
QDRANT_API=8da7625d78141e19a9bf3d878f4cb333fedb56eed9097904b46ce4c33e1ce085
QDRANT_USE_SSL=False
OPENAI_PATH=
OPENAI_KEY=
OPENAI_DEPLOYMENT_NAME=
MAX_CONTEXT_LENGTH=128000
USE_VERIFICATION = True
EMBEDDING_MODEL="sentence-transformers/msmarco-bert-base-dot-v5"
INDEX_NAME_LEXICAL = 'myindex-lexical'
INDEX_NAME_SEMANTIC = "myindex-semantic"
Among the variables are fairly easy. The primary Secret key and Algorithm are used for communication between the frontend and the backend.
Then there are variables configuring entry to the PostgreSQL database. It wants the database title (DBNAME), username, password, and host deal with the place the database is situated. In our case, it’s on localhost, on the docker picture.
The following part is the configuration of OpenSearch entry. There may be IP (localhost in our case once more), username, password, port quantity (default port is 9200), and variable defining whether or not to make use of SSL.
An identical configuration part has Qdrant, only for Qdrant, we use an API key, which must be right here outlined.
The following part outlined the generative mannequin. VerifAI makes use of the OpenAI python library, which grew to become the trade normal, and permits it to make use of each OpenAI API, Azure API, and consumer deployments by way of vLLM, OLlama, or Nvidia NIMs. The consumer must outline the trail to the interface, API key, and mannequin deployment title that will probably be used. We’re quickly including help the place customers can modify or change the immediate that’s used for technology. In case no path to an interface is offered and no key, the mannequin will obtain the Mistral 7B mannequin, with the QLoRA adapter that we’ve got fine-tuned, and deploy it regionally. Nonetheless, in case you would not have sufficient GPU RAM, or RAM normally, this will likely fail, or work terribly slowly.
You may set additionally MAX_CONTEXT_LENGTH, on this case it’s set to 128,000 tokens, as that’s context dimension of GPT4o. The context size variable is used to construct context. Usually, it’s constructed by placing in instruction about answering query factually, with references, after which offering retrieved related paperwork and query. Nonetheless, paperwork might be massive, and exceed context size. If this occurs, the paperwork are splitted in chunks and high n chunks that match into the context dimension will probably be used to context.
The following half accommodates the HuggingFace title of the mannequin that’s used for embeddings of paperwork in Qdrant. Lastly, there are names of indexes each in OpenSearch (INDEX_NAME_LEXICAL) and Qdrant (INDEX_NAME_SEMANTIC).
As we beforehand stated, VerifAI has a part that verifies whether or not the generated declare relies on the offered and referenced doc. Nonetheless, this may be turned on or off, as for some use-cases this performance is just not wanted. One can flip this off by setting USE_VERIFICATION to False.
The ultimate step of the set up is to run the install_datastores.py file. Earlier than working this file, it’s essential to set up Docker and make sure that the Docker daemon is working. As this file reads configuration for establishing the consumer names, passwords, or API keys for the instruments it’s putting in, it’s essential to first make a configuration file. That is defined within the subsequent part.
This script units up the mandatory parts, together with OpenSearch, Qdrant, and PostgreSQL, and creates a database in PostgreSQL.
python install_datastores.py
Observe that this script installs Qdrant and OpenSearch with out SSL certificates, and the next directions assume SSL is just not required. For those who want SSL for a manufacturing surroundings, you will want to configure it manually.
Additionally, be aware that we’re speaking about native set up on docker right here. If you have already got Qdrant and OpenSearch deployed, you’ll be able to merely replace the configuration file to level to these cases.
This configuration is utilized by each the indexing methodology and the backend service. Due to this fact, it should be accomplished earlier than indexing. As soon as the configuration is about up, you’ll be able to run the indexing course of by pointing index_files.py to the folder containing the recordsdata to be listed:
python index_files.py
We’ve got included a folder known as test_data within the repository, which accommodates a number of take a look at recordsdata (primarily my papers and different previous writings). You may substitute these recordsdata with your individual and run the next:
python index_files.py test_data
This is able to run indexing over all recordsdata in that folder and its subfolders. As soon as completed, one can run VerifAI providers for backend and frontend.
The backend of VerifAI might be run just by working:
python essential.py
This may begin the FastAPI service that may act as a backend, and go requests to OpenSearch, and Qdrant to retrieve related recordsdata for given queries and to the deployment of LLM for producing solutions, in addition to make the most of the native mannequin for declare verification.
Frontend is a folder known as client-gui/verifai-ui and is written in React.js, and due to this fact would want a neighborhood set up of Node.js, and npm. Then you’ll be able to merely set up dependencies by working npm set up and run the entrance finish by working npm begin:
cd ..
cd client-gui/verifai-ui
npm set up
npm begin
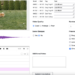
Lastly, issues ought to look by some means like this:


Thus far, VerifAI has been began with the assistance of funding from the Subsequent Technology Web Search mission as a subgrant of the European Union. It was began as a collaboration between The Institute for Synthetic Intelligence Analysis and Improvement of Serbia and Bayer A.G.. The primary model has been developed as a generative search engine for biomedicine. This product will proceed to run at https://app.verifai-project.com/. Nonetheless, these days, we determined to develop the mission, so it could possibly really turn into an open-source generative search with verifiable solutions for any recordsdata, that may be leveraged brazenly by totally different enterprises, small and medium corporations, non-governmental organizations, or governments. These modifications have been developed by Natasa Radmilovic and me voluntarily (enormous shout out to Natasa!).
Nonetheless, given that is an open-source mission, obtainable on GitHub (https://github.com/nikolamilosevic86/verifAI), we’re welcoming contributions by anybody, by way of pull requests, bug reviews, function requests, discussions, or the rest you’ll be able to contribute with (be happy to get in contact — for each BioMed and Core (doc generative search, as described right here) variations web site will stay the identical — https://verifai-project.com). So we welcome you to contribute, begin our mission, and comply with us sooner or later.


{kind=link}