As giant language fashions (LLMs) develop into more and more built-in into customer-facing functions, organizations are exploring methods to leverage their pure language processing capabilities. Many companies are investigating how AI can improve buyer engagement and repair supply, and going through challenges in ensuring LLMs pushed engagements are on subject and comply with the specified directions.
On this weblog publish, we discover a real-world state of affairs the place a fictional retail retailer, AnyCompany Pet Provides, leverages LLMs to boost their buyer expertise. Particularly, this publish will cowl:
- What NeMo Guardrails is. We are going to present a short introduction to guardrails and the Nemo Guardrails framework for managing LLM interactions.
- Integrating with Amazon SageMaker JumpStart to make the most of the most recent giant language fashions with managed options.
- Creating an AI Assistant able to understanding buyer inquiries, offering contextually conscious responses, and steering conversations as wanted.
- Implementing Subtle Dialog Flows utilizing variables and branching flows to react to the dialog content material, ask for clarifications, present particulars, and information the dialog primarily based on consumer intent.
- Incorporating your Information into the Dialog to offer factual, grounded responses aligned together with your use case objectives utilizing retrieval augmented technology or by invoking features as instruments.
By this sensible instance, we’ll illustrate how startups can harness the ability of LLMs to boost buyer experiences and the simplicity of Nemo Guardrails to information the LLMs pushed dialog towards the specified outcomes.
Notice: For any issues of adopting this structure in a manufacturing setting, it’s crucial to seek the advice of together with your firm particular safety insurance policies and necessities. Every manufacturing surroundings calls for a uniquely tailor-made safety structure that comprehensively addresses its explicit dangers and regulatory requirements. Some hyperlinks for safety greatest practices are shared under however we strongly suggest reaching out to your account group for detailed steerage and to debate the suitable safety structure wanted for a safe and compliant deployment.
What’s Nemo Guardrails?
First, let’s attempt to perceive what guardrails are and why we’d like them. Guardrails (or “rails” for brief) in LLM functions operate very like the rails on a mountaineering path — they information you thru the terrain, preserving you on the meant path. These mechanisms assist be certain that the LLM’s responses keep throughout the desired boundaries and produces solutions from a set of pre-approved statements.
NeMo Guardrails, developed by NVIDIA, is an open-source answer for constructing conversational AI merchandise. It permits builders to outline and constrain the matters the AI agent will have interaction with, the potential responses it could possibly present, and the way the agent interacts with varied instruments at its disposal.
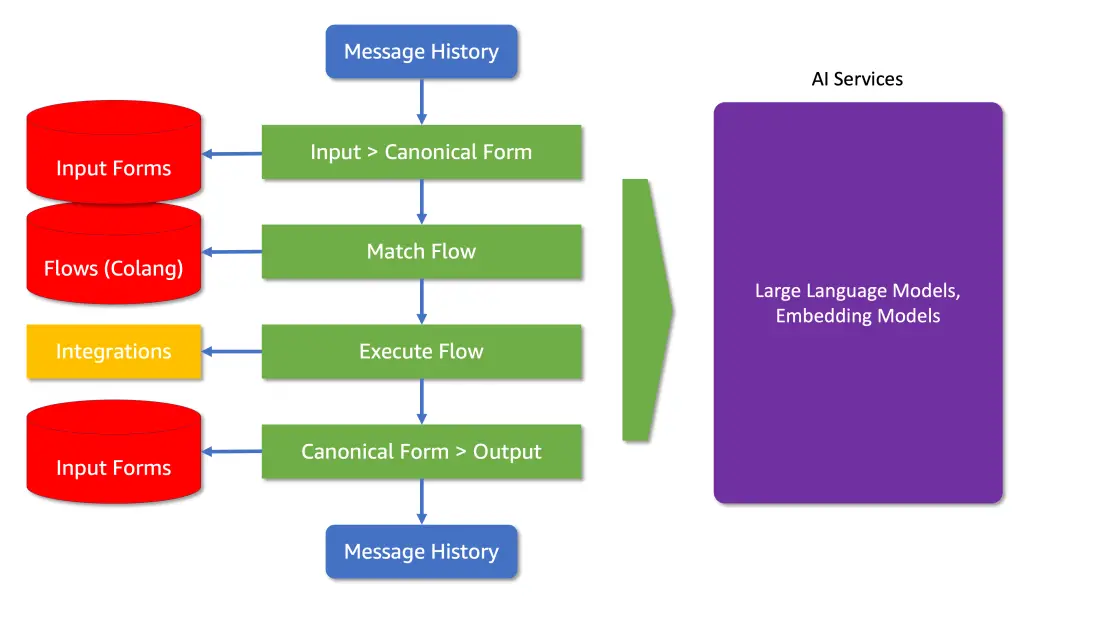
The structure consists of 5 processing steps, every with its personal set of controls, known as “rails” within the framework. Every rail defines the allowed outcomes (see Diagram 1):
- Enter and Output Rails: These determine the subject and supply a blocking mechanism for what the AI can focus on.
- Retrieval and Execution Rails: These govern how the AI interacts with exterior instruments and knowledge sources.
- Dialog Rails: These keep the conversational movement as outlined by the developer.
For a retail chatbot like AnyCompany Pet Provides’ AI assistant, guardrails assist guarantee that the AI collects the knowledge wanted to serve the client, supplies correct product data, maintains a constant model voice, and integrates with the encompassing providers supporting to carry out actions on behalf of the consumer.
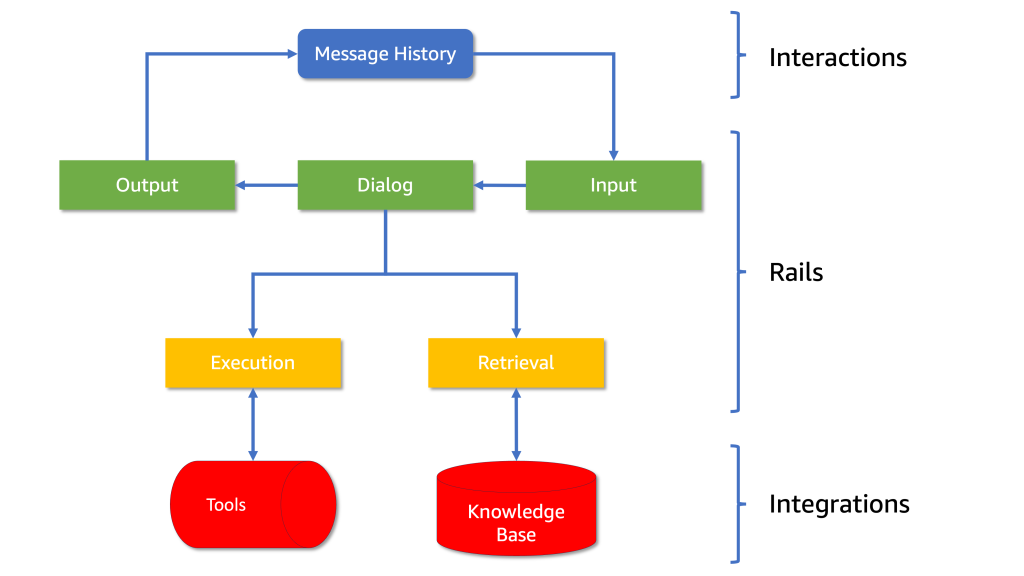
Diagram 1: The structure of NeMo Guardrails, displaying how interactions, rails and integrations are structured.
Inside every rail, NeMo can perceive consumer intent, invoke integrations when obligatory, choose essentially the most acceptable response primarily based on the intent and dialog historical past and generate a constrained message as a reply (see Diagram 2).
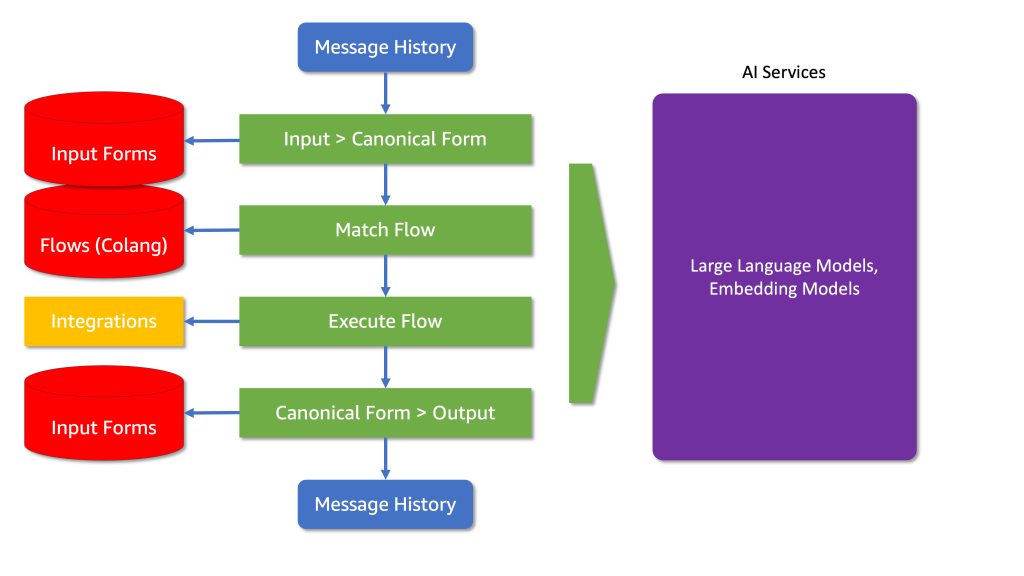
Diagram 2: The movement from enter types to the ultimate output, together with how integrations and AI providers are utilized.
An Introduction to Colang
Making a conversational AI that’s good, participating and operates together with your use case objectives in thoughts will be difficult. That is the place NeMo Guardrails is available in. NeMo Guardrails is a toolset designed to create sturdy conversational brokers, using Colang — a modelling language particularly tailor-made for outlining dialogue flows and guardrails. Let’s delve into how NeMo Guardrails personal language can improve your AI’s efficiency and supply a guided and seamless consumer expertise.
Colang is purpose-built for simplicity and adaptability, that includes fewer constructs than typical programming languages, but providing exceptional versatility. It leverages pure language constructs to explain dialogue interactions, making it intuitive for builders and easy to take care of.
Let’s delve right into a fundamental Colang script to see the way it works:
On this script, we see the three basic sorts of blocks in Colang:
- Consumer Message Blocks (outline consumer …): These outline potential consumer inputs.
- Bot Message Blocks (outline bot …): These specify the bot’s responses.
- Stream Blocks (outline movement …): These describe the sequence of interactions.
Within the instance above, we outlined a easy dialogue movement the place a consumer expresses gratitude, and the bot responds with a welcoming message. This easy method permits builders to assemble intricate conversational pathways that makes use of the examples given to route the dialog towards the specified responses.
Integrating Llama 3.1 and NeMo Guardrails on SageMaker JumpStart
For this publish, we’ll use Llama 3.1 8B instruct mannequin from Meta, a current mannequin that strikes glorious stability between dimension, inference value and conversational capabilities. We are going to launch it by way of Amazon SageMaker JumpStart, which supplies entry to quite a few basis fashions from suppliers akin to Meta, Cohere, Hugging Face, Anthropic and extra.
By leveraging SageMaker JumpStart, you may rapidly consider and choose appropriate basis fashions primarily based on high quality, alignment and reasoning metrics. The chosen fashions can then be additional fine-tuned in your knowledge to higher match your particular use case wants. On prime of ample mannequin selection, the extra profit is that it allows your knowledge to stay inside your Amazon VPC throughout each inference and fine-tuning.
When integrating fashions from SageMaker JumpStart with NeMo Guardrails, the direct interplay with the SageMaker inference API requires some customization, which we are going to discover under.
Creating an Adapter for NeMo Guardrails
To confirm compatibility, we have to create an adapter to guarantee that requests and responses match the format anticipated by NeMo Guardrails. Though NeMo Guardrails supplies a SagemakerEndpoint wrapper class, it requires some customization to deal with the Llama 3.1 mannequin API uncovered by SageMaker JumpStart correctly.
Under, you will see an implementation of a NeMo-compatible class that arranges the parameters required to name our SageMaker endpoint:
Structuring the Immediate for Llama 3.1
The Llama 3.1 mannequin from Meta requires prompts to comply with a selected construction, together with particular tokens like and {function} to outline components of the dialog. When invoking the mannequin by NeMo Guardrails, it’s essential to guarantee that the prompts are formatted appropriately.
To realize seamless integration, you may modify the immediate.yaml file. Right here’s an instance:
For extra particulars on formatting enter textual content for Llama fashions, you may discover these assets:
Creating an AI Assistant
In our activity to create an clever and accountable AI assistant for AnyCompany Pet Provides, we’re leveraging NeMo Guardrails to construct a conversational AI chatbot that may perceive buyer wants, present product suggestions, and information customers by the acquisition course of. Right here’s how we implement this.
On the coronary heart of NeMo Guardrails are two key ideas: flows and intents. These work collectively to create a structured, responsive, and context-aware conversational AI.
Flows in NeMo Guardrails
Flows outline the dialog construction and information the AI’s responses. They’re sequences of actions that the AI ought to comply with in particular eventualities. For instance:
These flows define how the AI ought to reply in numerous conditions. When a consumer asks about pets, the chatbot will present a solution. When confronted with an unrelated query, it’ll politely refuse to reply.
Intent Capturing and Stream Choice
The method of selecting which movement to comply with begins with capturing the consumer intent. NeMo Guardrails makes use of a multi-faceted method to grasp consumer intent:
- Sample Matching: The system first appears to be like for predefined patterns that correspond to particular intents:
- Dynamic Intent Recognition: After deciding on the almost certainly candidates, NeMo makes use of a classy intent recognition system outlined within the
prompts.ymlfile to slender down the intent:
This immediate is designed to information the chatbot in figuring out the consumer’s intent. Let’s break it down:
- Context Setting: The immediate begins by defining the AI’s function as a pet product specialist. This focuses the chatbot’s consideration on pet-related queries.
- Common Directions: The
{{ general_instructions }}variable incorporates general pointers for the chatbot’s conduct, as outlined in ourconfig.yml. - Instance Dialog: The
{{ sample_conversation }}supplies a mannequin of how interactions ought to movement, giving the chatbot context for understanding consumer intents. - Present Dialog: The
{ user_assistant_sequence }variable contains the precise dialog historical past, permitting the chatbot to contemplate the context of the present interplay. - Intent Choice: The chatbot is instructed to select from a predefined checklist of intents
{{ potential_user_intents }}. This constrains the chatbot to a set of recognized intents, making certain consistency and predictability in intent recognition. - Recency Bias: The immediate particularly mentions that “the final messages are extra necessary for outlining the present intent.” This instructs the chatbot to prioritize current context, which is commonly most related to the present intent.
- Single Intent Output: The chatbot is instructed to “Write solely certainly one of:
{{ potential_user_intents }}“. This supplies a transparent, unambiguous intent choice.
In Follow:
Right here’s how this course of works in observe (see Diagram 3):
- When a consumer sends a message, NeMo Guardrails initiates the intent recognition activity.
- The chatbot evaluations the dialog historical past, specializing in the newest messages.
- It matches the consumer’s enter towards an inventory of predefined intents.
- The chatbot selects essentially the most appropriate intent primarily based on this evaluation.
- The recognized intent determines the corresponding movement to information the dialog.
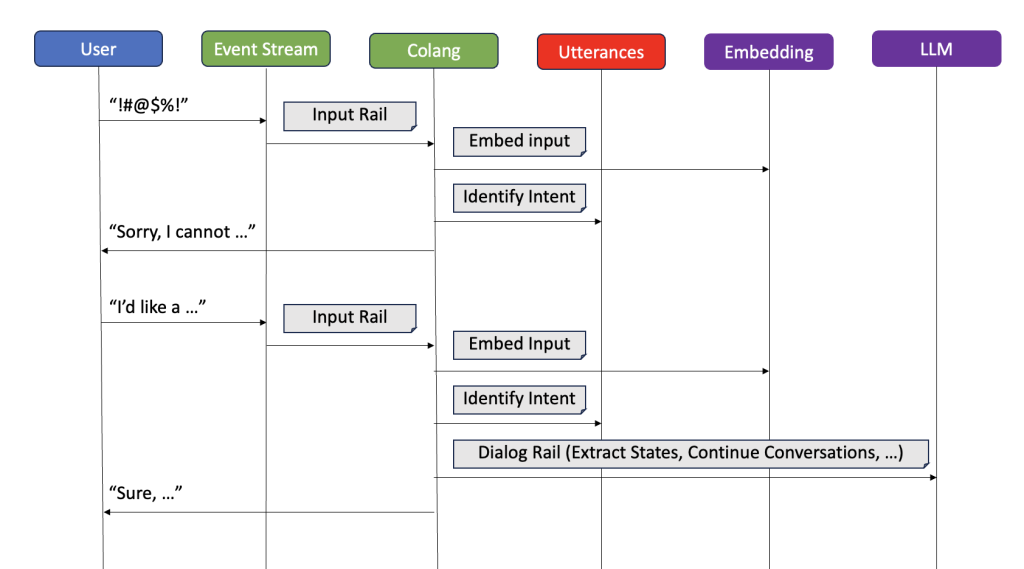
Diagram 3: Two instance dialog flows, one denied by the enter rails, one allowed to the dialog rail the place the LLM picks up the dialog.
For instance, if a consumer asks, “What’s the perfect meals for a kitten?”, the chatbot may classify this as a “product_inquiry” intent. This intent would then activate a movement designed to suggest pet meals merchandise.
Whereas this structured method to intent recognition makes certain that the chatbot’s responses are targeted and related to the consumer’s wants, it might introduce latency because of the must course of and analyze dialog historical past and intent in real-time. Every step, from intent recognition to movement choice, includes computational processing, which may affect the response time, particularly in additional advanced interactions. Discovering the correct stability between flexibility, management, and real-time processing is essential for creating an efficient and dependable conversational AI system.
Implement Sophisticate Dialog Flows
In our earlier dialogue about Colang, we examined its core construction and its function in crafting conversational flows. Now, we are going to delve into certainly one of Colang’s standout options: the power to make the most of variables to seize and course of consumer enter. This performance allows us to assemble conversational brokers that aren’t solely extra dynamic but additionally extremely responsive, tailoring their interactions primarily based on exact consumer knowledge.
Persevering with with our sensible instance of creating a pet retailer assistant chatbot:
Within the supplied instance above, we encounter the road:
$pet_type = ...
The ellipsis (...) serves as a placeholder in Colang, signaling the place knowledge extraction or inference is to be carried out. This notation doesn’t characterize executable code however relatively means that some type of logic or pure language processing must be utilized at this stage.
Extra particularly, using an ellipsis right here implies that the system is anticipated to:
- Analyze the consumer’s enter beforehand captured beneath “consumer categorical pet merchandise wants.”
- Decide or infer the kind of pet being mentioned.
- Retailer this data within the $pet_type variable.
The remark accompanying this line sheds extra gentle on the meant knowledge extraction course of:
#extract the precise pet kind at very excessive degree if accessible, like canine, cat, chicken. Ensure you nonetheless class issues like pet as "canine", kitty as "cat", and so on. if accessible or "not accessible" if none apply
This directive signifies that the extraction ought to:
- Acknowledge the pet kind at a excessive degree (canine, cat, chicken).
- Classify frequent variations (e.g., “pet” as “canine”).
- Default to “not accessible” if no clear pet kind is recognized.
Returning to our preliminary code snippet, we use the $pet_type variable to customise responses, enabling the bot to supply particular recommendation primarily based on whether or not the consumer has a canine, chicken, or cat.
Subsequent, we are going to develop on this instance to combine a Retrieval Augmented Era (RAG) workflow, enhancing our assistant’s capabilities to suggest particular merchandise tailor-made to the consumer’s inputs.
Deliver Your Information into the Dialog
Incorporating superior AI capabilities utilizing a mannequin just like the Llama 3.1 8B instruct mannequin requires extra than simply managing the tone and movement of conversations; it necessitates controlling the information the mannequin accesses to reply to consumer queries. A standard method to attain that is Retrieval Augmented Era (RAG). This technique includes looking a semantic database for content material related to a consumer’s request and incorporating these findings into the mannequin’s response context.
The everyday method makes use of an embedding mannequin, which converts a sentence right into a semantic numeric illustration—known as a vector. These vectors are then saved in a vector database designed to effectively search and retrieve carefully associated semantic data. For extra data on this subject, please consult with Getting began with Amazon Titan Textual content Embeddings in Amazon Bedrock.
NeMo Guardrails simplifies this course of: builders can retailer related content material in a delegated ‘kb’ folder. NeMo robotically reads this knowledge, applies its inner embedding mannequin and shops the vectors in an “Annoy” index, which features as an in-memory vector database. Nonetheless, this technique won’t scale nicely for intensive knowledge units typical in e-commerce environments. To handle scalability, listed below are two options:
- Customized Adapter or Connector: Implement your individual extension of the
EmbeddingsIndexbase class. This lets you customise storage, search and knowledge embedding processes in keeping with your particular necessities, whether or not native or distant. This integration makes certain that that related data stays within the conversational context all through the consumer interplay, although it doesn’t permit for exact management over when or how the knowledge is used. For instance: - Retrieval Augmented Era by way of Operate Name: Outline a operate that handles the retrieval course of utilizing your most well-liked supplier and method. This operate can instantly replace the conversational context with related knowledge, making certain that the AI can take into account this data in its responses. For instance:
Within the dialog rail’s movement, use variables and performance calls to exactly handle searches and the mixing of outcomes:
These strategies supply completely different ranges of flexibility and management, making them appropriate for varied functions relying on the complexity of your system. Within the subsequent part, we are going to see how these methods are utilized in a extra advanced state of affairs to additional improve the capabilities of our AI assistant.
Full Instance with Variables, Retrievers and Dialog Flows
State of affairs Overview
Let’s discover a posh implementation state of affairs with NeMo Guardrails interacting with a number of instruments to drive particular enterprise outcomes. We’ll preserve the deal with the pet retailer e-commerce web site that’s being upgraded with a conversational gross sales agent. This agent is built-in instantly into the search area on the prime of the web page. For example, when a consumer searches for “double coat shampoo,” the outcomes web page shows a number of merchandise and a chat window robotically engages the consumer by processing the search phrases.
Detailed Dialog Stream
Because the consumer interplay begins, the AI processes the enter from the search area:
Output: "Would you have the ability to share the kind of your canine breed?"
This initiates the engine’s recognition of the consumer’s intent to inquire about pet merchandise. Right here, the chatbot makes use of variables to try to extract the sort and breed of the pet. If the breed isn’t instantly accessible from the enter, the bot requests additional clarification.
Retrieval and Response Era
If the consumer responds with the breed (e.g., “It’s a Labradoodle”), the chatbot proceeds to tailor its seek for related merchandise:
Output: We discovered a number of shampoos for Labradoodles: [Product List]. Would you want so as to add any of those to your cart?
The chatbot makes use of the extracted variables to refine product search standards, then retrieves related objects utilizing an embedded retrieval operate. It codecs this data right into a user-friendly message, itemizing accessible merchandise and providing additional actions.
Advancing the Sale
If the consumer expresses a need to buy a product (“I’d like to purchase the second possibility from the checklist”), the chatbot transitions to processing the order:
Output: "Nice selection! To finalize your order, might you please present your full transport deal with?"
At this level, we wouldn’t have the transport data so the bot ask for it. Nonetheless, if this was a recognized buyer, the information might be injected into the dialog from different sources. For instance, if the consumer is authenticated and has made earlier orders, their transport deal with will be retrieved from the consumer profile database and robotically populated throughout the dialog movement. Then the mannequin would simply have requested for affirmation in regards to the buy, skipping the half about asking for transport data.
Finishing the Sale
As soon as our variables are crammed and now we have sufficient data to course of the order, we will transition the dialog naturally right into a gross sales movement and have the bot finalize the order:
Output: "Success"
On this instance, we’ve applied a mock operate known as add_order to simulate a backend service name. This operate verifies the deal with and locations the chosen product into the consumer’s session cart. You possibly can seize the return string from this operate on the consumer facet and take additional motion, as an example, if it signifies ‘Success,’ you may then run some JavaScript to show the crammed cart to the consumer. This may present the cart with the merchandise, pre-entered transport particulars and a prepared checkout button throughout the consumer interface, closing the gross sales loop expertise for the consumer and tying collectively the conversational interface with the procuring cart and buying movement.
Sustaining Dialog Integrity
Throughout this interplay, the NeMo Guardrails framework maintains the dialog throughout the boundaries set by the Colang configuration. For instance, if the consumer deviates with a query akin to ‘What’s the climate like immediately?’, NeMo Guardrails will classify this as a part of a refusal movement and outdoors the related matters of ordering pet provides. It is going to then tactfully declines to handle the unrelated question and steers the dialogue again in the direction of deciding on and ordering merchandise, replying with a typical response like, ‘I’m afraid I can’t assist with climate data, however let’s proceed together with your pet provides order.’ as outlined in Colang.
Clear Up
When utilizing Amazon SageMaker JumpStart you’re deploying the chosen fashions utilizing on-demand GPU cases managed by Amazon SageMaker. These cases are billed per second and it’s necessary to optimize your prices by turning off the endpoint when not wanted.
To wash up your assets, please be certain that you run the clear up cells within the three notebooks that you simply used. Ensure you delete the suitable mannequin and endpoints by executing related cells:
Please word that within the third pocket book, you moreover must delete the embedding endpoints:
Moreover, you may just remember to have deleted the suitable assets manually by finishing the next steps:
- Delete the mannequin artifacts:
- On the Amazon SageMaker console, select Fashions beneath Inference within the navigation pane.
- Please make sure you would not have
llm-modeland embedding-model artifacts. - To delete these artifacts, select the suitable fashions and click on Delete beneath Actions dropdown menu.
- Delete endpoint configurations:
- On the Amazon SageMaker console, select Endpoint configuration beneath Inference within the navigation pane.
- Please make sure you would not have
llm-modeland embedding-model endpoint configuration. - To delete these configurations, select the suitable endpoint configurations and click on Delete beneath Actions dropdown menu.
- Delete the endpoints:
- On the Amazon SageMaker console, select Endpoints beneath Inference within the navigation pane.
- Please make sure you would not have
llm-modeland embedding-model endpoints working. - To delete these endpoints, select the suitable mannequin endpoint names and click on Delete beneath Actions dropdown menu.
Finest Practices and Concerns
When integrating NeMo Guardrails with SageMaker JumpStart, it’s necessary to contemplate AI governance frameworks and safety greatest practices to make sure accountable AI deployment. Whereas this weblog focuses on showcasing the core performance and capabilities of NeMo Guardrails, safety facets are past its scope.
For additional steerage, please discover:
Conclusion
Integrating NeMo Guardrails with Massive Language Fashions (LLMs) is a robust step ahead in deploying AI in customer-facing functions. The instance of AnyCompany Pet Provides illustrates how these applied sciences can improve buyer interactions whereas dealing with refusal and guiding the dialog towards the applied outcomes. Trying ahead, sustaining this stability of innovation and duty will probably be key to realizing the complete potential of AI in varied industries. This journey in the direction of moral AI deployment is essential for constructing sustainable, trust-based relationships with prospects and shaping a future the place expertise aligns seamlessly with human values.
Subsequent Steps
You could find the examples used inside this text by way of this hyperlink.
We encourage you to discover and implement NeMo Guardrails to boost your individual conversational AI options. By leveraging the guardrails and methods demonstrated on this publish, you may rapidly constraint LLMs to drive tailor-made and efficient outcomes to your use case.
Concerning the Authors
 Georgi Botsihhin is a Startup Options Architect at Amazon Internet Companies (AWS), primarily based in the UK. He helps prospects design and optimize functions on AWS, with a powerful curiosity in AI/ML expertise. Georgi is a part of the Machine Studying Technical Area Neighborhood (TFC) at AWS. In his free time, he enjoys staying lively by sports activities and taking lengthy walks together with his canine.
Georgi Botsihhin is a Startup Options Architect at Amazon Internet Companies (AWS), primarily based in the UK. He helps prospects design and optimize functions on AWS, with a powerful curiosity in AI/ML expertise. Georgi is a part of the Machine Studying Technical Area Neighborhood (TFC) at AWS. In his free time, he enjoys staying lively by sports activities and taking lengthy walks together with his canine.
 Lorenzo Boccaccia is a Startup Options Architect at Amazon Internet Companies (AWS), primarily based in Spain. He helps startups in creating cost-effective, scalable options for his or her workloads working on AWS, with a deal with containers and EKS. Lorenzo is obsessed with Generative AI and is is a licensed AWS Options Architect Skilled, Machine Studying Specialist and a part of the Containers TFC. In his free time, he will be discovered on-line collaborating sim racing leagues.
Lorenzo Boccaccia is a Startup Options Architect at Amazon Internet Companies (AWS), primarily based in Spain. He helps startups in creating cost-effective, scalable options for his or her workloads working on AWS, with a deal with containers and EKS. Lorenzo is obsessed with Generative AI and is is a licensed AWS Options Architect Skilled, Machine Studying Specialist and a part of the Containers TFC. In his free time, he will be discovered on-line collaborating sim racing leagues.



{kind=link}