
As organizations scale their generative AI workloads on Amazon Bedrock, operational visibility into inference efficiency and useful resource consumption turns into important. Groups working latency-sensitive functions should perceive how rapidly fashions start producing responses. Groups managing high-throughput workloads should perceive how their requests devour quota to allow them to keep away from surprising throttling. Till now, gaining this visibility required customized client-side instrumentation or reactive troubleshooting after points occurred.
Immediately, we’re saying two new Amazon CloudWatch metrics for Amazon Bedrock, TimeToFirstToken and EstimatedTPMQuotaUsage. These metrics offer you server-side visibility into streaming latency and quota consumption. These metrics are mechanically emitted for each profitable inference request at no further value, with no API adjustments or opt-in required. They’re accessible now within the AWS/Bedrock CloudWatch namespace.
On this submit, we cowl the next:
- Why visibility into time-to-first-token latency and quota consumption issues for manufacturing AI workloads
- How the brand new TimeToFirstToken and EstimatedTPMQuotaUsage metrics work
- Tips on how to get began utilizing these metrics to set alarms, set up baselines, and proactively handle capability.
Amazon Bedrock already gives a set of CloudWatch metrics that can assist you monitor your inference workloads. The AWS/Bedrock namespace consists of metrics akin to Invocations, InvocationLatency, InvocationClientErrors, InvocationThrottles, InputTokenCount, and OutputTokenCount. These metrics present visibility into request quantity, end-to-end latency, error charges, and token utilization. These metrics can be found throughout the Converse, ConverseStream, InvokeModel, and InvokeModelWithResponseStream APIs and may be filtered by the ModelId dimension. Whereas these metrics present a robust operational basis, they go away two vital gaps: they don’t seize how rapidly a streaming response begins (time-to-first-token), they usually don’t replicate the efficient quota consumed by a request after accounting for token burndown multipliers. The 2 new metrics introduced in the present day tackle precisely these gaps.
Observability wants of manufacturing AI Inference workloads
In streaming inference functions, like chatbots, coding assistants, or real-time content material technology, the time it takes for the mannequin to return its first token immediately impacts perceived responsiveness. A delay within the first token immediately impacts the perceived responsiveness of your utility, even when general throughput stays inside acceptable ranges. Nonetheless, measuring this server-side metric beforehand required you to instrument your utility code to seize timestamps round API calls. This added complexity and probably launched measurement inaccuracies that don’t replicate the precise service-side habits.
Quota administration presents a special however equally vital problem. Amazon Bedrock applies token burndown multipliers for sure fashions. Because of this the efficient quota consumed by a request can differ from the uncooked token counts that you simply see in billing metrics. For instance, Anthropic Claude fashions, together with Claude Sonnet 4.6, Claude Opus 4.6, Claude Sonnet 4.5, and Claude Opus 4.5, apply a 5x burndown multiplier on output tokens for quota functions. This implies a request that produces 100 output tokens successfully consumes 500 tokens of your Tokens Per Minute (TPM) quota. You might be solely billed on your precise token utilization. With out visibility into this calculation, throttling can seem unpredictable, making it troublesome to set acceptable alarms or plan capability will increase forward of time. For patrons utilizing cross-Area inference profiles, these challenges are compounded since you want per-inference-profile visibility to grasp efficiency and consumption throughout geographic and international configurations.
Understanding newly launched metrics
The next diagram exhibits the place every metric is captured in the course of the lifecycle of a streaming inference request.
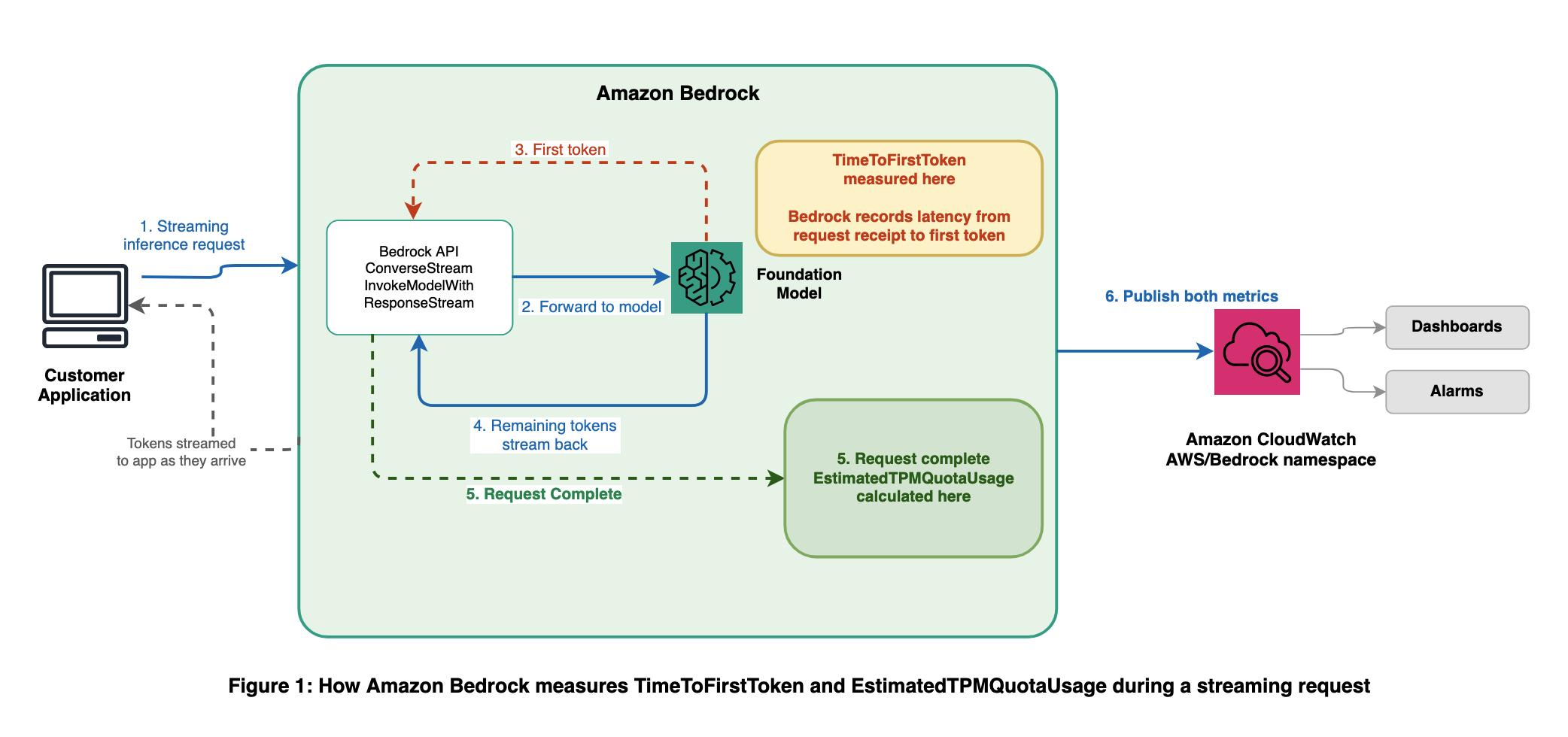
TimeToFirstToken:
The TimeToFirstToken metric measures the latency, in milliseconds, from when Amazon Bedrock receives your streaming request to when the service generates the primary response token. This metric is emitted for the streaming APIs: ConverseStream and InvokeModelWithResponseStream. As a result of this metric is measured server-side, it displays precise service-side latency with out noise from community circumstances or client-side processing.
With this metric, you’ll be able to:
- Set latency alarms – Create CloudWatch alarms that notify you when time-to-first-token exceeds acceptable thresholds, so you’ll be able to detect efficiency degradation earlier than it impacts your customers.
- Set up SLA baselines – Analyze historic TimeToFirstToken knowledge throughout fashions to set knowledgeable efficiency baselines on your functions.
- Diagnose efficiency points – Correlate TimeToFirstToken with different Amazon Bedrock metrics akin to InvocationLatency (Time to Final Token) to isolate whether or not latency points stem from preliminary mannequin response time or general request processing.
The metric is revealed with the ModelId dimension, and optionally ServiceTier and ResolvedServiceTier dimensions. For cross-Area inference profiles, the ModelId corresponds to your inference profile identifier (for instance, us.anthropic.claude-sonnet-4-5-v1), so you’ll be able to monitor TimeToFirstToken individually for every profile. This metric is emitted just for efficiently accomplished streaming requests.
EstimatedTPMQuotaUsage:
The EstimatedTPMQuotaUsage metric tracks the estimated Tokens Per Minute (TPM) quota consumed by your requests. In contrast to uncooked token counts, this metric accounts for the elements that Amazon Bedrock makes use of when evaluating quota consumption, together with cache write tokens and output token burndown multipliers. The metric title consists of “Estimated” to replicate that it gives an in depth approximation of your quota consumption for monitoring and capability planning functions. The interior throttling choices of Amazon Bedrock are based mostly on real-time calculations that may differ barely from this metric, however EstimatedTPMQuotaUsage is designed to present you a dependable, actionable sign. It must be correct sufficient to set alarms, monitor consumption traits, and plan quota will increase with confidence. This metric is emitted throughout all inference APIs, together with Converse, InvokeModel, ConverseStream, and InvokeModelWithResponseStream.
Understanding the quota consumption method:
The method for calculating estimated quota consumption will depend on your throughput kind:
On-demand inference:
EstimatedTPMQuotaUsage = InputTokenCount + CacheWriteInputTokens + (OutputTokenCount × burndown_rate)
The burndown price varies by mannequin — for the total checklist of fashions and their relevant charges, consult with Token burndown multipliers for quota administration. For on-demand inference, cache learn tokens don’t depend towards the quota.
For example, Claude Sonnet 4.5 has a 5x burndown price on output tokens. An on-demand request with 1,000 enter tokens, 200 cache write tokens, and 100 output tokens consumes 1,000 + 200 + (100 × 5) = 1,700 tokens of quota. That is 400 greater than you may estimate from uncooked token counts alone.
Provisioned Throughput (reserved tier):
EstimatedTPMQuotaUsage = InputTokenCount + (CacheWriteInputTokens × 1.25) + (CacheReadInputTokens × 0.1) + OutputTokenCount
For Provisioned Throughput, the burndown multiplier on output tokens doesn’t apply. Nonetheless, cache learn tokens contribute at a 0.1 price and cache write tokens are weighted at 1.25.
Be aware that billing differs from quota utilization — you might be billed for precise token utilization, not the burndown-adjusted or weighted quantities. For extra particulars, consult with Token burndown multipliers for quota administration.
With this metric, you’ll be able to:
- Set proactive quota alarms – Create CloudWatch alarms that set off when your estimated quota utilization approaches your TPM restrict, so you’ll be able to act earlier than requests are throttled.
- Observe consumption throughout fashions – Evaluate quota utilization throughout totally different fashions to grasp which workloads are consuming essentially the most capability and optimize accordingly.
- Plan quota will increase – Use historic consumption traits to request quota will increase via AWS service quotas earlier than your utilization development results in throttling.
Metric dimensions and filtering
Each metrics share the next traits:
The metrics embrace dimensions akin to ModelId, permitting you to filter and combination knowledge per mannequin. Once you use a cross-Area inference profile, whether or not geographic (for instance, us.anthropic.claude-sonnet-4-5-v1) or international (for instance, international.anthropic.claude-sonnet-4-5-v1), the ModelId dimension corresponds to your inference profile identifier. This implies you could view separate metrics for every cross-Area inference profile and mannequin mixture. This provides you granular visibility into efficiency and consumption throughout your inference configurations.
That is in step with current Amazon Bedrock CloudWatch metrics like Invocations, InvocationLatency, and token depend metrics.
| Attribute | TimeToFirstToken | EstimatedTPMQuotaUsage |
| CloudWatch namespace | AWS/Bedrock | AWS/Bedrock |
| Unit | Milliseconds | Depend |
| Supported APIs | ConverseStream, InvokeModelWithResponseStream | Converse, InvokeModel, ConverseStream, InvokeModelWithResponseStream |
| Replace frequency | 1-minute aggregation | 1-minute aggregation |
| Scope | Efficiently accomplished requests | Efficiently accomplished requests |
| Main dimension | ModelId |
ModelId |
| Elective dimensions | ServiceTier, ResolvedServiceTier |
ServiceTier, ResolvedServiceTier, ContextWindow (for enter contexts exceeding 200K tokens) |
| Supported inference sorts | Cross-Area inference (geographic and international), in-Area inference | Cross-Area inference (geographic and international), in-region inference |
Getting began
These metrics are already accessible in your CloudWatch dashboard. When your utility calls an Amazon Bedrock inference API, the service processes the request, invokes the mannequin, and publishes all relevant metrics — together with TimeToFirstToken and EstimatedTPMQuotaUsage — to the AWS/Bedrock namespace in your CloudWatch account. You’ll be able to then use CloudWatch dashboards, alarms, and metric math to observe, alert on, and analyze these metrics. Full the next steps to begin utilizing them:
- Open the Amazon CloudWatch console and navigate to Metrics > All metrics.
- Choose the AWS/Bedrock namespace.
- Discover the TimeToFirstToken or EstimatedTPMQuotaUsage metrics and filter by
ModelIdto view knowledge for particular fashions. - Create alarms to get notified of latency degradation or quota consumption approaching your limits.
Make inference requests and observe the brand new metrics
To generate metric knowledge factors, make inference requests towards Amazon Bedrock. The next examples use the AWS SDK for Python (Boto3) to exhibit a non-streaming request (which emits EstimatedTPMQuotaUsage) and a streaming request (which emits each EstimatedTPMQuotaUsage and TimeToFirstToken).
In these examples, we use us-east-1 because the AWS Area and us.anthropic.claude-sonnet-4-6-v1 as a cross-Area inference profile. Change these with your individual Area and mannequin or inference profile ID.
Converse (non-streaming)
The next instance makes use of the Converse API. This non-streaming name emits the EstimatedTPMQuotaUsage metric in CloudWatch underneath the AWS/Bedrock namespace.
ConverseStream (streaming)
The next instance makes use of the ConverseStream API. This streaming name emits each EstimatedTPMQuotaUsage (worth in double) for quota consumption and TimeToFirstToken (worth in milliseconds) measuring latency from request to the primary streamed token.
The identical metrics are emitted for the InvokeModel (non-streaming) and InvokeModelWithResponseStream (streaming) APIs. The next desk summarizes which metrics every API emits:
| API | Emitted metrics |
| Converse | EstimatedTPMQuotaUsage |
| ConverseStream | EstimatedTPMQuotaUsage, TimeToFirstToken |
| InvokeModel | EstimatedTPMQuotaUsage |
| InvokeModelWithResponseStream | EstimatedTPMQuotaUsage, TimeToFirstToken |
After making these requests, enable roughly 1–2 minutes for the metrics to seem, then navigate to the CloudWatch console underneath Metrics > All metrics > AWS/Bedrock to confirm that the information factors are current on your mannequin.
Question metrics utilizing the AWS CLI
You need to use the AWS CLI to confirm that the brand new metrics can be found and retrieve their values. First, affirm that the metrics are being revealed on your mannequin:
Conclusion
With the brand new TimeToFirstToken and EstimatedTPMQuotaUsage CloudWatch metrics, Amazon Bedrock offers you the observability that you want to run manufacturing generative AI workloads with confidence. Key takeaways:
- Measure streaming latency server-side – TimeToFirstToken gives correct, server-side latency measurement for streaming APIs with out requiring any client-side instrumentation.
- Perceive true quota consumption – EstimatedTPMQuotaUsage displays the estimated quota impression of your requests, together with burndown multipliers, so you’ll be able to predict and forestall throttling.
- No motion required to begin – Each metrics are mechanically emitted at no further value. Open your CloudWatch dashboard to start utilizing them.
- Set proactive alarms – Use these metrics to create alarms that catch efficiency points and quota strain earlier than they impression your functions.
Open your Amazon CloudWatch console in the present day to discover these new metrics and arrange alarms tailor-made to your workload necessities.
For extra info, consult with the next assets:
Concerning the authors



{kind=link}