
Turning a library of aerial imagery right into a natural-language-searchable information base is an issue that touches each business that depends on geospatial knowledge — insurance coverage, actual property, authorities, infrastructure, and agriculture. The standard path requires both guide tile-by-tile inspection or coaching a bespoke pc imaginative and prescient mannequin for every new query. Multimodal embeddings, massive language mannequin (LLM) captioning, and vector search on AWS provide a sooner various: index as soon as, then question utilizing pure language.
We labored with Vexcel, an aerial imagery and geospatial knowledge supplier that operates one of many largest aerial imagery applications on the earth, to guage embedding fashions, fusion methods, caption integration, and search strategies over multi-view aerial imagery. Utilizing its personal sensors and a devoted fleet of plane, Vexcel collects high-resolution knowledge throughout 45+ nations and territories, delivering orthomosaic imagery, indirect imagery from a number of angles, and elevation fashions. The information exists, and the use instances are quite a few, however turning billions of pixels into solutions about the actual world requires a sooner path.
On this put up, we stroll by the issue area, our structure on Amazon Bedrock and Amazon OpenSearch Serverless, the analysis methodology we constructed on OpenStreetMap floor reality, 4 experiments that in contrast embedding fashions, fusion methods, captioning, and search strategies, and the sensible steerage you’ll be able to apply when constructing an identical system. You’ll study which design selections transfer the needle for geospatial semantic search, together with why Amazon Nova Multimodal Embeddings delivered the best F1 scores throughout each benchmark queries in our analysis. The work described right here advanced into Vexcel Intelligence, a searchable imagery product.
Looking hundreds of thousands of aerial photos with out per-feature coaching
When a buyer must find swimming swimming pools in a suburb, determine street networks in a growth zone, or rely photo voltaic panels throughout a metropolis, somebody has to manually look tile-by-tile (inspecting every map tile in flip) throughout hundreds of thousands of photos. The choice is coaching a pc imaginative and prescient mannequin for every function, which requires labeled knowledge, engineering time, and ongoing retraining. When the following buyer desires to seek out warehouses with graffiti on the aspect (see Determine 1), they repeat the cycle. Semantic search powered by vector embeddings removes this per-feature coaching step and turns natural-language queries into leads to seconds.

Determine 1. A typical indirect picture from Vexcel, offering fashions wealthy 360-degree imaginative and prescient of the world
Vexcel had explored this downside by three prior POCs: an agent-based method combining imagery with property knowledge, a property embedding system for similarity search, and a tiled multimodal embedding pipeline with captions generated by a big language mannequin (LLM). The third confirmed promise however raised key questions: which embedding mannequin to make use of, the way to deal with a number of views per location, and whether or not captions truly enhance outcomes or simply add value.
The AWS Generative AI Innovation Middle (GenAIIC) partnered with Vexcel to reply a targeted query: what’s the optimum mixture of embedding mannequin, fusion technique, captioning method, and search technique for semantic search over multi-view aerial imagery? Vexcel introduced area experience and real-world knowledge, whereas GenAIIC contributed ML structure, an entire ingestion-to-evaluation pipeline, and AWS service integration. The result’s a system Vexcel has since advanced into Vexcel Intelligence, a product now in preview that transforms their imagery library right into a searchable, AI-queryable resolution.
Why geospatial imagery search is completely different
Geospatial imagery search is essentially completely different from looking client pictures. A question for “swimming pool” on Google Pictures retrieves standalone images from a single perspective. Aerial imagery doesn’t work that approach.
A single map tile isn’t one picture. It’s seven complementary views of the identical location.
Every tile contains an orthophoto (the top-down RGB view), 4 indirect images captured at angles from the north, south, east, and west, a Digital Floor Mannequin (DSM) encoding elevation together with constructions, and a Digital Terrain Mannequin (DTM) representing naked floor top. The next determine reveals what these seven views appear like for a single tile — every captures completely different particulars about the identical geographic location.
Determine 2. Seven complementary views of the identical tile (prime row: Ortho, North indirect, South indirect, East indirect; backside row: West indirect, DTM, DSM)
These views reveal radically completely different particulars. Within the previous determine, the constructing’s entrance façade (that includes a kiosk-like window) is barely seen from the south indirect angle; the orthophoto, the remaining indirect views, and the elevation fashions miss it fully. In the meantime, the DSM captures tree cover that obscures ground-level options within the RGB views, and the DTM strips vegetation away altogether. An embedding mannequin that sees just one view works with incomplete info. One which sees the seven views wants a method for combining them.
The bottom reality problem
Client picture search has many years of labeled datasets similar to ImageNet, COCO, and Open Pictures. Aerial function detection at this scale has none. We would have liked a option to consider search high quality with out a pre-labeled corpus, which led us to OpenStreetMap as an automatic floor reality supply, a call that formed your complete analysis framework.
Ambiguity in what counts as an accurate end result
The third problem is ambiguity, and it runs deeper than view choice. Think about a seek for “swimming swimming pools” that returns a tile the place the pool is seen solely within the ortho picture however not in any indirect view. It’s unclear whether or not that result’s right. The reverse case is equally ambiguous: a tile the place the pool is seen from the south indirect however not from above.
Zoom stage compounds this. Relying on tile decision, a single tile would possibly cowl a metropolis block or a whole neighborhood. In a dense suburban space, one tile may comprise a dozen swimming swimming pools. Ought to the bottom reality require the system to return a tile if it accommodates a matching function, or ought to it account for each occasion inside that tile? A tile-level match (no less than one pool current) and a feature-level match (each pool accounted for) are essentially completely different analysis standards, and so they reward completely different system behaviors. We needed to outline what “right” means earlier than we may measure it.
Co-designing the analysis agenda
Earlier than writing a single line of optimization code, we constructed the analysis harness. This was deliberate: measure earlier than you tune. And not using a rigorous option to measure search high quality, each architectural resolution turns into an opinion.
The engagement was structured across the following six questions, every focusing on a particular architectural resolution that impacts search high quality:
- Which embedding mannequin finest understands aerial imagery? We in contrast Amazon Nova Multimodal Embeddings, Amazon Titan Multimodal Embeddings G1, and Cohere Embed v4, every obtainable in Amazon Bedrock, a completely managed service that provides a alternative of high-performing basis fashions (FMs) from main AI firms by a single API. Amazon Nova, in flip, is a household of basis fashions obtainable by Amazon Bedrock.
- How must you deal with seven photos per geographic location? We examined per-view embeddings, late fusion (common and max-pool), LLM-weighted consideration fusion, and Cohere’s native multi-image batch encoding.
- Does LLM-generated captioning enhance search accuracy? We designed a {custom} captioning immediate that instructs the FM to research the seven photos concurrently as complementary views of the identical geographic location, figuring out every picture sort (ortho, indirect angles, DSM, DTM) and synthesizing a unified description throughout land use, constructed setting, infrastructure, pure options, objects, and spatial relationships. The immediate explicitly directs the mannequin to cross-reference views: when one thing seems unclear in a single view, use different angles or elevation knowledge to resolve it. We examined this immediate with Amazon Nova 2 Lite and Anthropic’s Claude in Amazon Bedrock, measuring whether or not indexing these captions alongside picture embeddings improved retrieval.
- Can LLM-extracted metadata enhance filtering? We used a second FM go to extract as much as 25 key phrase tags from every generated caption (for instance, “swimming pool”, “mature bushes”, “industrial district”) and saved them in an Amazon OpenSearch Serverless textual content area alongside the embeddings. At question time, the identical extraction runs on the consumer’s search question. Amazon OpenSearch Serverless k-nearest neighbor (k-NN) filtering then makes use of these tags as a pre-filter, narrowing the candidate set to paperwork whose tags match the question phrases earlier than working vector similarity. This makes use of native filtered k-NN to mix structured metadata with semantic search.
- Which search technique works finest for various function sorts? We in contrast fundamental k-NN, multi-view fusion search, hybrid picture+caption scoring, metadata-filtered search, and text-only search.
- Are you able to construct an automatic analysis framework utilizing publicly obtainable floor reality? We sourced floor reality from OpenStreetMap through the Overpass API, enabling repeatable benchmarks with out guide labeling.
The analysis space was Grant Park in Chicago, with two benchmark queries: “swimming swimming pools” (discrete object detection) and “roads” (distributed infrastructure detection). We examined roughly 100 distinct configurations throughout these dimensions.
Structure overview
The system follows a five-stage pipeline (Determine 3), every stage independently swappable for A/B experimentation.
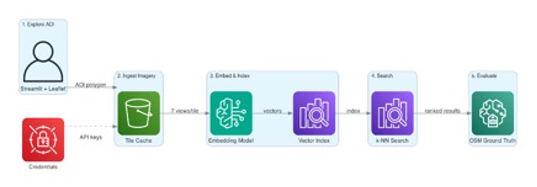
Determine 3. 5-stage pipeline structure
Stage 1. Discover Space of Curiosity (AOI). Customers draw a polygon on an interactive map to outline their space of curiosity. The AOI is persevered to Amazon Easy Storage Service (Amazon S3) for reproducibility.
Stage 2. Ingest Imagery. The system fetches tiles from Vexcel’s API for each map tile intersecting the AOI at a configurable zoom stage. Every tile yields as much as seven photos. Fee limiting (100 requests/second) and Amazon S3 caching assist forestall redundant API calls. Credentials are managed by AWS Secrets and techniques Supervisor (Determine 4).
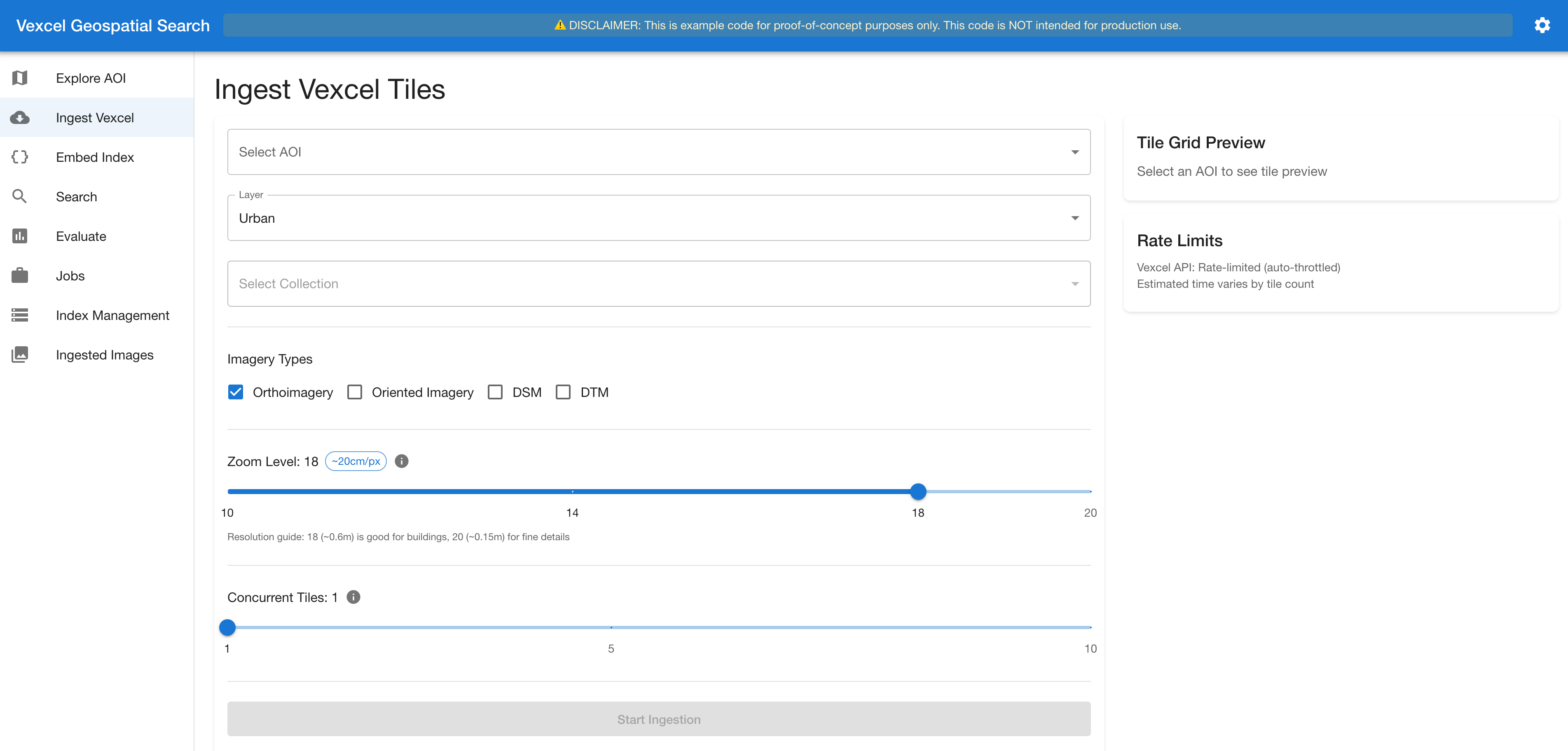
Determine 4. The ingestion interface: choosing imagery sorts and zoom stage
Stage 3. Embed & Index. Every picture passes by the chosen Amazon Bedrock embedding mannequin. Optionally, the seven views are despatched to a imaginative and prescient LLM (Amazon Nova 2 Lite, or Anthropic’s Claude) to generate a structured textual content description. Embeddings and captions are then listed into Amazon OpenSearch Serverless or Amazon S3 Vectors. The interface gives caption technology controls, a real-time dimension influence evaluation, embedding mannequin, and fusion technique choice (Figures 5 and 6).
Stage 4. Search. Pure language queries are embedded utilizing the identical mannequin, then matched towards the index. The system auto-detects which fields exist within the index (per-view embeddings, fused embeddings, caption textual content, caption embeddings) and dynamically permits solely the search strategies that the index helps.
Stage 5. Consider. Search outcomes are scored towards OpenStreetMap floor reality utilizing precision, recall, and F1 rating. The analysis framework runs the identical question throughout each enabled search technique and reviews comparative metrics.
The modular design was the important thing architectural resolution. Each element (embedding mannequin, fusion technique, search technique, vector retailer) connects by a standard interface. Swapping Amazon Nova Multimodal Embeddings for Cohere Embed v4 is a configuration change, not a code change. This enabled us to check ~100 configurations in hours quite than weeks.
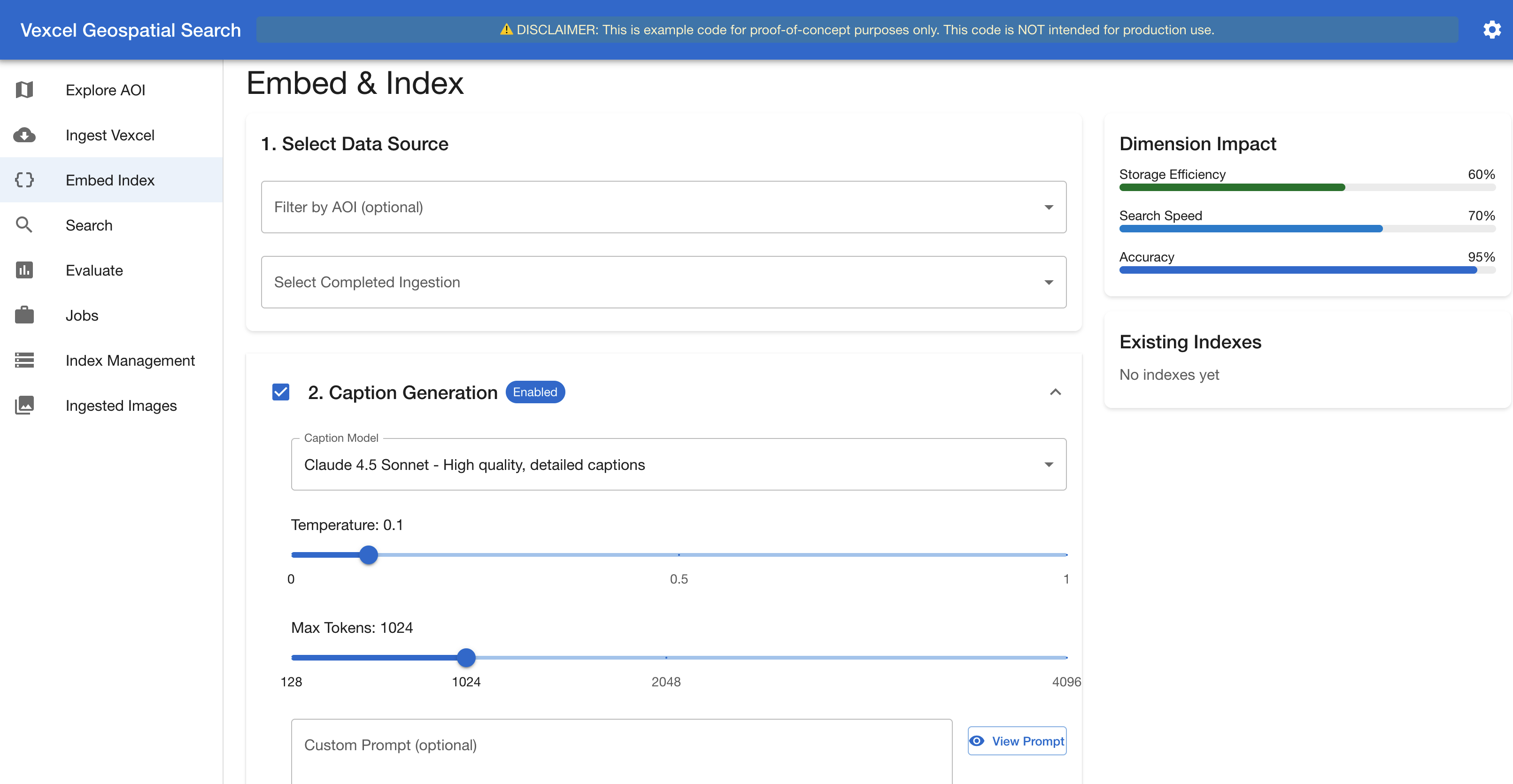
Determine 5. The Embed & Index interface – Caption Era part
The next determine reveals the embedding configuration panel, the place customers choose the embedding mannequin and fusion technique for his or her indexing run.
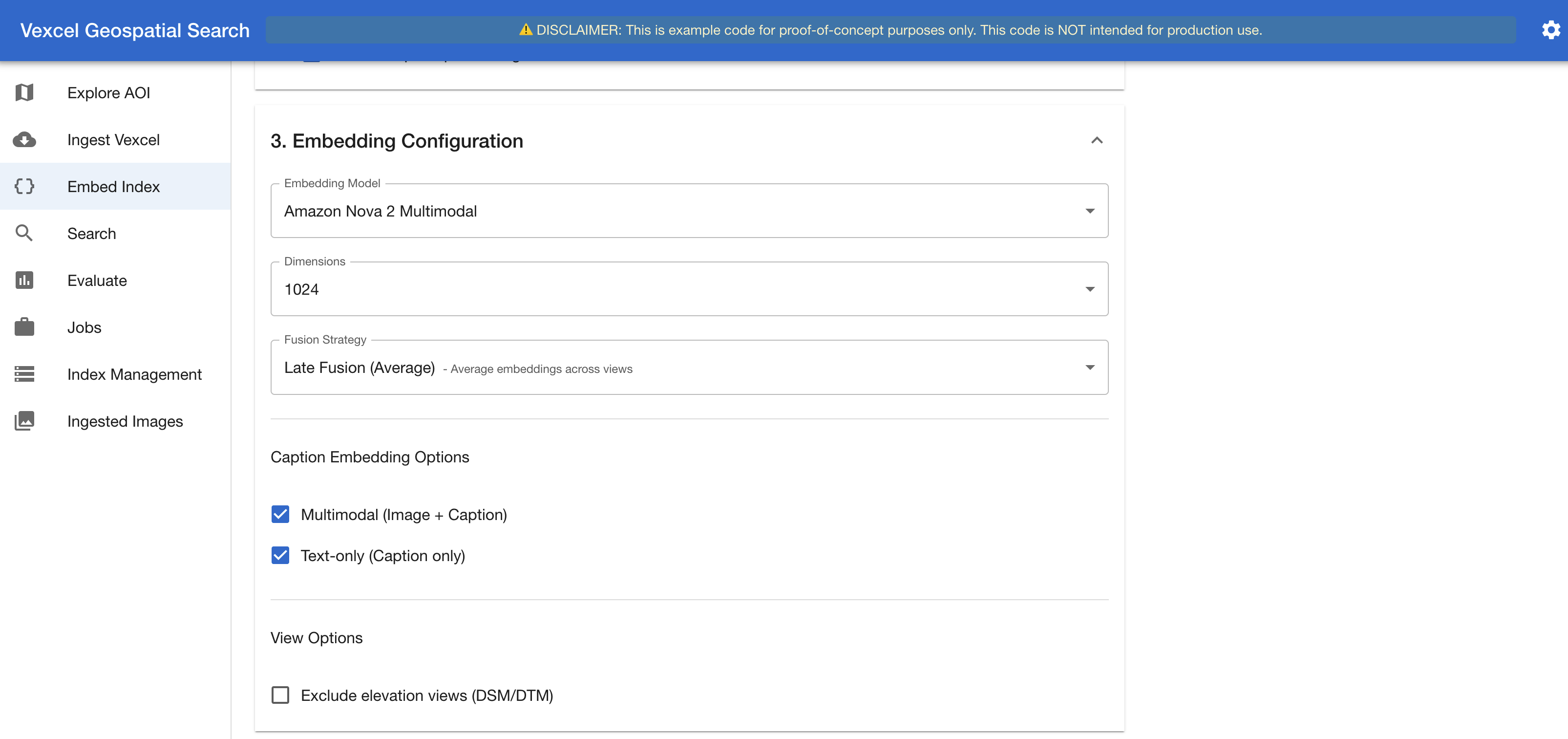
Determine 6. The Embed & Index interface – Embedding Configuration part
Selecting the best Ok
Each vector search returns the highest k-NN outcomes. Ok is a lever with actual penalties, and the best worth will depend on how frequent the function is in your dataset.
When a function is sparse (just a few swimming swimming pools scattered throughout lots of of tiles), a big Ok floods outcomes with irrelevant tiles. The system retrieves Ok outcomes no matter whether or not Ok related tiles exist. Set Ok=50 when solely 8 tiles comprise swimming pools, and 42 of these outcomes are noise. Precision collapses. F1 follows.
When a function is ample (roads showing in most tiles), a small Ok artificially caps recall. Set Ok=5 when 60 tiles comprise roads, and you may solely discover 8% of them. Recall collapses. F1 rating follows.
The connection is mechanical. Precision@Ok = relevant_found / Ok. If Ok exceeds the variety of related tiles, precision can by no means attain 1.0. Recall@Ok = relevant_found / total_relevant. If Ok is smaller than the full related tiles, good recall is inconceivable.
We evaluated at a number of Ok values concurrently (Ok = 3, 5, 7, 10, 15, 20, 25, 30, 50) and tracked how precision, recall, and F1 rating shifted throughout the vary. The optimum Ok constantly landed close to the precise rely of related tiles within the floor reality, a quantity you received’t know in manufacturing. In follow, begin with Ok=10–20 for basic queries, observe the precision-recall tradeoff in your analysis outcomes, and alter per function class. The analysis framework makes this calibration quick; rerunning with completely different Ok values prices seconds, not hours.
Two methods to measure: tile-based vs. entity-based analysis
A single metric can masks essential conduct relying on what you rely as a success. We constructed the analysis framework with two complementary modes that reply completely different questions.
Tile-based analysis asks: did we discover the best places? A tile is both related (accommodates no less than one occasion of the function) or not. If a tile has one swimming pool or twelve, it counts as one related tile both approach. Precision, recall, and F1 are computed over tiles.
Entity-based analysis asks: did we discover probably the most options? Every particular person entity (every pool, every street section) counts individually. A tile with 5 swimming pools contributes 5 to the related whole. Discovering that tile recovers 5 entities. Lacking it loses 5.
The 2 modes diverge when options are inconsistently distributed, and in aerial imagery, they nearly all the time are. Think about this state of affairs from our analysis:
| State of affairs | Tile-Primarily based Recall | Entity-Primarily based Recall |
| Discovered 1 tile with 5 swimming pools, missed 1 tile with 1 pool (6 whole) | 50% | 83% |
| Discovered 1 tile with 1 pool, missed 1 tile with 5 swimming pools (6 whole) | 50% | 17% |
Tile-based recall is an identical in each instances: 1 of two tiles discovered. Entity-based recall reveals the essential distinction: the primary state of affairs recovered a lot of the precise swimming pools; the second missed most of them.
Which mode to make use of will depend on the query. Tile-based analysis is the best lens when geographic protection issues, similar to “discover each location that has a pool.” Entity-based analysis issues when density issues, similar to “discover the areas with probably the most swimming pools.” We report each as a result of the hole between them reveals function distribution: a big divergence indicators that options are clustered in just a few dense tiles quite than unfold evenly throughout the realm. The analysis framework additionally computes nDCG (normalized discounted cumulative acquire) utilizing entity counts as graded relevance, and stratified metrics that break efficiency into sparse tiles (precisely 1 entity) versus dense tiles (2+), so you’ll be able to see precisely the place the system succeeds and the place it struggles.
Experiment 1: Which mannequin understands aerial imagery?
We listed the identical Grant Park dataset 3 times, as soon as per embedding mannequin, conserving different variables fixed. Every mannequin processed the identical tiles, the identical views, and the identical Amazon OpenSearch Serverless configuration. We then ran each benchmark queries throughout every fusion and search configuration and computed the common F1 rating per mannequin.
Amazon Nova Multimodal Embeddings achieved the best common F1 scores for each swimming swimming pools (0.621) and roads (0.555) in our analysis (Determine 7). The margin over Cohere Embed v4 was modest for swimming swimming pools (0.621 vs. 0.606) however substantial for roads, a notable distinction (0.555 vs. 0.415). Cohere Embed v4’s native multi-image batch encoding carried out nicely for discrete objects however confirmed lowered sensitivity to distributed infrastructure options like street networks in our testing.
We anticipated Amazon Titan Multimodal Embeddings G1 to compete carefully. It didn’t. Its common F1 rating of 0.340 for swimming pools was considerably decrease than the Amazon Nova Multimodal Embeddings rating. Worse, a number of configurations produced near-zero F1 scores in image-based search: instances the place the mannequin returned nearly fully irrelevant outcomes. These weren’t outliers. They appeared constantly throughout particular fusion and search technique mixtures.
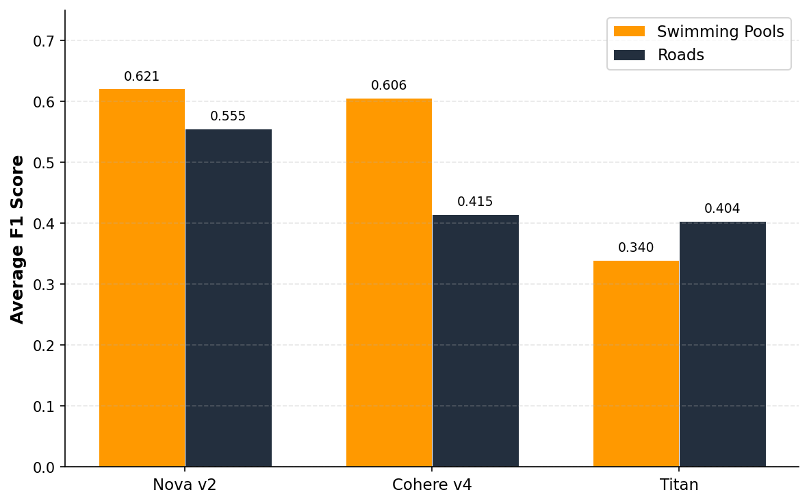
Determine 7. Common F1 rating by embedding mannequin throughout each benchmark queries.
The sensible takeaway: mannequin alternative has an outsized impact on geospatial search high quality, and the impact varies by function sort. Roads confirmed a significant efficiency variation throughout fashions for each function sorts. In case you’re beginning a geospatial search venture on AWS, you’ll be able to default to Amazon Nova Multimodal Embeddings.
Experiment 2: How must you deal with seven photos per location?
Seven photos per tile creates an indexing dilemma. You may retailer them individually (7 embeddings per tile), merge them into one (fusion), or let the mannequin deal with the mix natively.
We examined 4 approaches:
- Per-view embeddings: 7 separate vectors per tile, every searchable independently. Outcomes are aggregated throughout views at question time.
- Late fusion (common/max-pool): Compute 7 embeddings, then common or max-pool them right into a single vector. Less complicated to index, however the merged vector loses view-specific sign.
- Consideration fusion: An LLM assigns per-view weights based mostly on the question, then the weighted mixture produces a single embedding. A “swimming pool” question would possibly weight the orthophoto at 0.4 whereas a “tall buildings” question weights the DSM at 0.35.
- Cohere batch: Cohere Embed v4’s native multi-image API processes the seven views in a single name, producing one embedding that captures cross-view relationships internally.
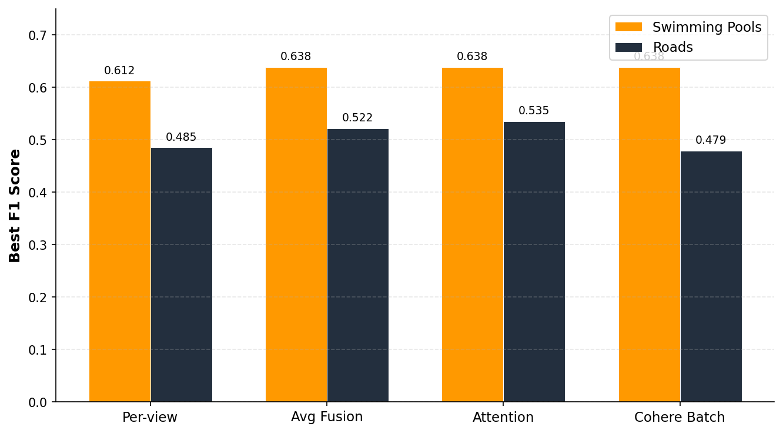
Determine 8. Greatest F1 rating by fusion technique throughout each benchmark queries.
For swimming swimming pools, three methods (Cohere batch, consideration fusion, and late common) every achieved a mean F1 rating of 0.638, the best rating (Determine 8). Per-view underperformed at 0.612, largely as a result of metadata filtering behaved inconsistently when working throughout 7 separate embedding fields. The 4.2% hole between Cohere batch and per-view signifies that fusion method alternative has significant influence, notably for reliability throughout completely different search strategies.
For roads, the story reversed. Consideration fusion led at 0.535. Late common adopted at 0.522. Per-view got here in at 0.485. Cohere batch dropped to 0.479, a 12% hole between finest and worst. The identical technique that tied for first on swimming pools positioned final on roads.
No single fusion method dominates throughout function sorts. The optimum technique will depend on what you’re trying to find.
Experiment 3: Does captioning assist?
We used Amazon Nova 2 Lite to generate structured captions from the seven views concurrently. The immediate instructs the mannequin to explain land use, constructed setting, infrastructure, pure options, and spatial relationships seen throughout the complete set of views. The result’s a single textual content description per tile that synthesizes info no particular person view accommodates alone.
Caption integration turned out to be the one most impactful optimization we examined.
For swimming swimming pools, the perfect Amazon Nova Multimodal Embeddings configuration with caption integration (“each strategies”: picture and caption embeddings fused right into a mixed rating) achieved a finest configuration F1 rating of 0.638, in comparison with 0.573 with out captions. That’s an 11% enchancment. For roads, the hole was even bigger: 13% (F1 of 0.555 vs. 0.490).
Right here’s what shocked us: caption integration technique mattered greater than embedding mannequin alternative. Cohere Embed v4 and Amazon Nova Multimodal Embeddings achieved an identical finest configuration F1 scores of 0.638 for swimming pools when paired with optimum caption integration. The captions supplied a textual grounding that compensated for variations in visible embedding high quality.
However captions alone aren’t sufficient. Textual content-only search (matching question phrases towards captions with none picture embeddings) dropped 17% to F1 of 0.532 for swimming pools. The visible sign carries info that textual content descriptions are lacking. One of the best outcomes come from combining each modalities.
Caption mannequin alternative has a measurable downstream influence. Completely different caption fashions produced completely different vocabularies of their descriptions, which affected downstream tag-based filtering. In some instances, one mannequin’s captions surfaced options that one other’s missed, leading to completely different F1 scores for metadata-filtered search. In case your pipeline makes use of tag-based filtering, the caption mannequin’s vocabulary instantly impacts recall.
We additionally examined whether or not DSM and DTM knowledge contributed to object detection. They didn’t. Configurations with 4 views (ortho + obliques) matched or exceeded these utilizing the seven views together with elevation. For normal object detection duties like swimming pools and roads, you’ll be able to skip the elevation knowledge; it provides embedding value with out enhancing accuracy.
Experiment 4: What’s the proper option to search?
We applied 5 search strategies (Determine 9), every representing a distinct tradeoff between sophistication, value, and accuracy.
Fundamental k-NN: Easy vector similarity towards the aggregated picture embedding. Lowest latency, with no extra FM calls. That is the best default when captions are already baked into the index.
Picture + Caption Fusion: Runs parallel k-NN searches towards each the picture embedding and caption embedding fields, then blends scores utilizing a tunable alpha weight (default 0.7 picture / 0.3 caption). Captures each visible and semantic similarity.
Metadata Filtering: Applies tag-based pre-filtering earlier than vector search, narrowing the candidate set to tiles whose generated tags match the question phrases. Quickest path when the consumer names a identified function (similar to “swimming pool” or “car parking zone”).
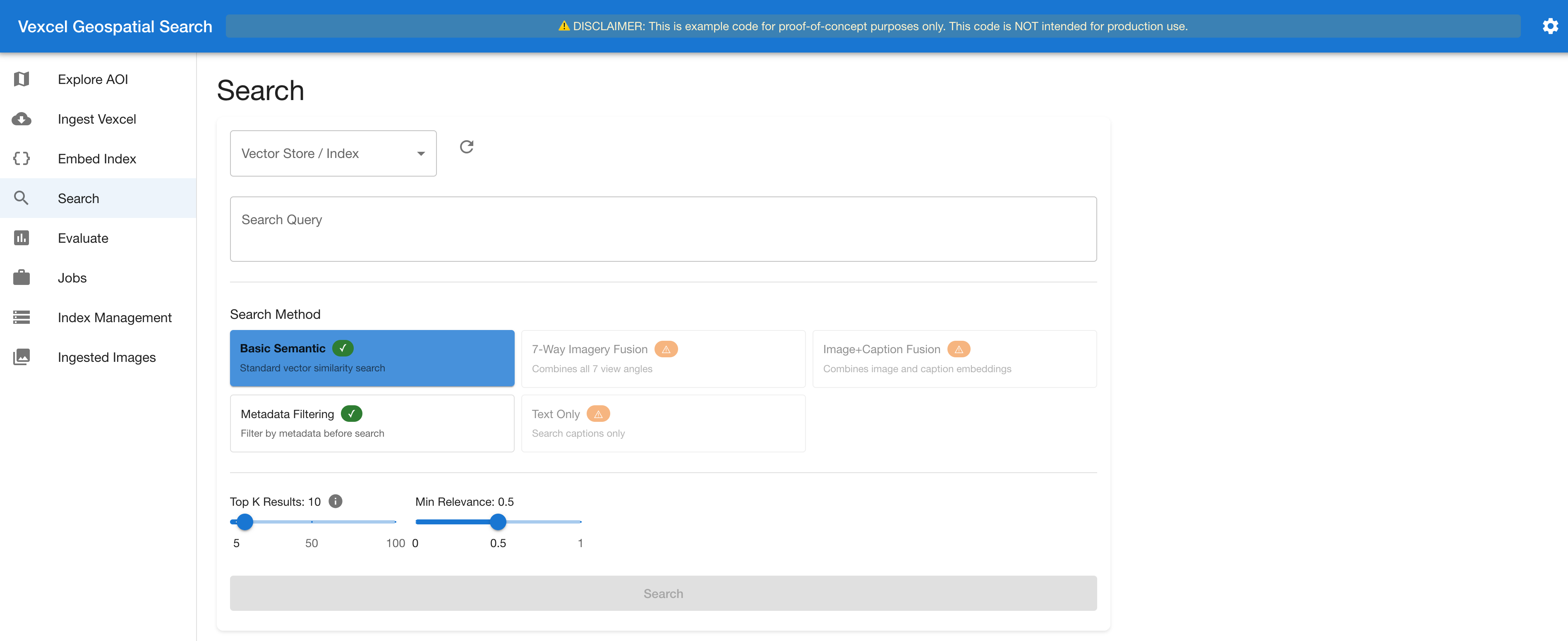
Determine 9. Search web page displaying the 5 strategies with availability indicators
Textual content-Solely Search: Key phrase matching towards the caption area with no vector similarity.
7-Method Imagery Fusion: Runs parallel k-NN searches throughout the seven per-view embedding fields plus captions, with dynamic per-query weight task. An FM analyzes the search question and assigns relevance weights to every view. For instance, a “baseball area” question weights the orthophoto at ~0.3 for area markings, whereas a “multi-story buildings” question weights the DSM at ~0.35 for top knowledge. The weighted scores are mixed right into a remaining rating.
No single search technique dominates throughout function sorts. The optimum technique will depend on what you’re trying to find, which is why the system exposes every of the 5 strategies and the analysis framework measures which works finest per question class.
The next tables summarize search technique efficiency for every of our two benchmark queries. For swimming swimming pools, a number of strategies obtain the identical prime F1 rating, whereas roads present clearer differentiation between approaches.
Swimming swimming pools
| Search Technique | Greatest Config F1 | When to Use |
| Fundamental k-NN | 0.638 | Common-purpose, low latency |
| Picture + caption fusion | 0.638 | Balanced multimodal queries |
| Metadata filtering | 0.638 | Excessive-precision object detection |
| Textual content-only | 0.532 | Low value, visible options not decisive |
| 7-way imagery fusion | — | Question maps to particular view views |
Roads
| Search Technique | Greatest Config F1 | Notes |
| Fundamental k-NN (Nova captions) | 0.524 | Greatest general for infrastructure |
| Picture + caption fusion | 0.506 | Visible options dominate over caption sign |
| Textual content-only | 0.395 | Highway descriptions too diverse for pure textual content matching |
| Metadata filtering | 0.358 | Inconsistent tag matching on street descriptions |
Three strategies tied at F1 of 0.638 for swimming swimming pools: fundamental k-NN, picture + caption fusion, and metadata filtering. For roads, fundamental k-NN dominated at 0.524. The optimum search technique relies upon fully on the function sort.
Metadata filtering reveals the starkest distinction. It tied for finest on swimming pools as a result of the FM extracted “swimming pool” tags that matched caption textual content exactly, enabling tight pre-filtering earlier than k-NN. On roads, it collapsed to 0.358. Highway descriptions in captions are extra diverse and fewer constantly tagged, making key phrase pre-filtering unreliable.
The picture + caption fusion method computes a weighted mixture: α × image_score + (1−α) × caption_score. We examined each manually tuned weights and FM-assigned dynamic weights. Each achieved an F1 rating of 0.638 for swimming pools. For these comparatively easy queries, guide tuning sufficed. Dynamic weighting might show extra invaluable for complicated, multi-faceted searches the place the optimum alpha varies per question; for instance, “residential areas close to water with industrial buildings” requires completely different image-vs-text weighting than “parking heaps.”
In case you’re selecting a single search technique to begin with, fundamental k-NN over caption-enriched embeddings display probably the most constant outcomes throughout function sorts in our testing. Add specialised strategies while you determine question classes that underperform.
What we discovered
Throughout roughly 100 configurations examined on two benchmark queries, the next seven findings emerged as probably the most actionable steerage for groups constructing geospatial semantic search techniques:
- Begin with Amazon Nova Multimodal Embeddings. It delivered the best common F1 rating throughout configurations for each swimming pools (0.621) and roads (0.555). You should utilize it as a powerful default for geospatial semantic search.
- Combine FM-generated captions. This was the highest-ROI optimization we examined: an 11% F1 rating enchancment for swimming pools and 13% for roads, extra influence than switching embedding fashions or tuning fusion methods. In case you do one factor past baseline k-NN search, add captions.
- Skip elevation knowledge for traditional object detection. DSM and DTM added no measurable enchancment for swimming pools or roads, whereas rising embedding prices by ~40% (seven views vs. 5). Reserve elevation knowledge for queries the place top info is semantically related, similar to constructing classification, flood threat evaluation, or vegetation cover evaluation.
- Match fusion technique to your function sort. Consideration fusion works finest for distributed infrastructure (roads). For discrete objects (swimming pools), Cohere batch, consideration fusion, and late common every tied; fusion alternative issues much less when the function is visually distinct. There is no such thing as a common finest, so you need to use the analysis framework to find out optimum settings per question class.
- Select your search technique by question sort. Fundamental k-NN with captions works finest for visually distinct options at low latency. Metadata filtering is quickest for known-label queries. FM-weighted fusion fits complicated, multi-faceted queries the place optimum view weighting varies per question. Keep away from text-only search.
- Construct the analysis framework first. We examined ~100 configurations throughout two question sorts. With out automated analysis towards OpenStreetMap floor reality, this is able to have required weeks of guide inspection. The framework is the first deliverable: it retains discovering optimum configurations as newer fashions launch and new function sorts are added.
- Plan for cost-effective operation at manufacturing scale. The price of semantic search over world imagery is dominated by the one-time indexing and embedding pipeline. As soon as embedded, query-time search is negligible, comparable to look in domains like textual content, music, or video. Against this, having fashions analyze pixels at runtime is inherently costly and could be minimized.
Conclusion and subsequent steps
This engagement proved that multimodal AI may remodel aerial imagery from a visible archive you browse right into a information base you question. A pure language search over hundreds of thousands of geographic tiles (one thing that required guide inspection or custom-trained fashions just a few years in the past) now works with general-purpose basis fashions (FMs) and customary AWS companies.
What made this doable was shut collaboration between AWS and Vexcel: we introduced ML structure and analysis methodology, whereas Vexcel introduced area experience, real-world knowledge, and manufacturing necessities that saved the work grounded in precise use instances.
The modular structure means Vexcel received’t have to rebuild the pipeline when higher fashions arrive. When a brand new Amazon Nova or Cohere launch launches in Amazon Bedrock, swapping it in is a configuration change. The analysis framework instantly measures whether or not the brand new mannequin improves outcomes.
Alongside the search pipeline, AWS GenAIIC delivered an AI-powered code onboarding chat service, an Amazon Bedrock-backed interface hosted through Amazon CloudFront that lets Vexcel engineers ask pure language questions concerning the codebase itself. Queries like “What are the embedding fusion strategies within the app?” or “Which file ought to I modify so as to add extra caption technology fashions?” return focused solutions, assuaging guide code exploration for engineers inheriting the system.
The strongest validation of this work is what Vexcel did with it. The ideas and structure from this engagement have advanced into Vexcel Intelligence, a product now in preview that provides searchable vector embeddings, an API, and a studio software throughout Vexcel’s world imagery library spanning 45+ nations. Queries like “Mediterranean-style houses with an in-ground pool and tennis courtroom” or “communication towers with room for extra tools in Japan,” the sorts of semantic searches we prototyped in Grant Park, Chicago, have gotten manufacturing options.
Our analysis covers two question sorts in a single geographic space. Vexcel’s path to manufacturing follows three phases: targeted deployment in high-value areas, enlargement to broader geographic areas because the analysis framework validates efficiency, and in the end full protection of their world imagery repository. The instruments to measure, examine, and optimize at every part are already in place.
In regards to the authors



{kind=link}