Generative AI permits us to perform extra in much less time. Textual content-to-SQL empowers individuals to discover knowledge and draw insights utilizing pure language, with out requiring specialised database data. Amazon Net Companies (AWS) has helped many purchasers join this text-to-SQL functionality with their very own knowledge, which suggests extra workers can generate insights. On this course of, we found {that a} completely different method is required in enterprise environments the place there are over 100 tables, every with dozens of columns. We additionally realized that sturdy error dealing with is crucial when errors happen within the generated SQL question primarily based on customers’ questions.
This put up demonstrates how enterprises can implement a scalable agentic text-to-SQL resolution utilizing Amazon Bedrock Brokers, with superior error-handling instruments and automatic schema discovery to boost database question effectivity. Our agent-based resolution provides two key strengths:
- Automated scalable schema discovery – The schema and desk metadata could be dynamically up to date to generate SQL when the preliminary try to execute the question fails. That is necessary for enterprise prospects who’ve quite a lot of tables and columns and plenty of queries patterns.
- Automated error dealing with – The error message is instantly fed again to the agent to enhance the success charge of working queries.
You’ll discover that these options provide help to sort out enterprise-scale database challenges whereas making your text-to-SQL expertise extra sturdy and environment friendly.
Use case
An agentic text-to-SQL resolution can profit enterprises with complicated knowledge buildings. On this put up, to grasp the mechanics and advantages of the agentic text-to-SQL resolution in a fancy enterprise setting, think about you’re a enterprise analyst on the danger administration staff in a financial institution. You might want to reply questions resembling “Discover all transactions that occurred in the USA and have been flagged as fraudulent, together with the gadget info used for these transactions,” or “Retrieve all transactions for John Doe that occurred between January 1, 2023, and December 31, 2023, together with fraud flags and service provider particulars.” For this, there are dozens—or generally a whole lot—of tables that you should not solely remember but in addition craft complicated JOIN queries. The next diagram illustrates a pattern desk schema that is perhaps wanted for fraud investigations.

The important thing ache factors of implementing a text-to-SQL resolution on this complicated setting embody the next, however aren’t restricted to:
- The quantity of desk info and schema will get extreme, which is able to entail guide updates on the prompts and restrict its scale.
- Because of this, the answer may require extra validation, impacting the standard and efficiency of producing SQL.
Now, think about our resolution and the way it addresses these issues.
Answer overview
Amazon Bedrock Brokers seamlessly manages the complete course of from query interpretation to question execution and outcome interpretation, with out guide intervention. It seamlessly incorporates a number of instruments, and the agent analyzes and responds to surprising outcomes. When queries fail, the agent autonomously analyzes error messages, modifies queries, and retries—a key profit over static methods.
As of December 2024, the Amazon Bedrock with structured knowledge characteristic supplies built-in assist for Amazon Redshift, providing seamless text-to-SQL capabilities with out customized implementation. That is advisable as the first resolution for Amazon Redshift customers.
Listed below are the capabilities that this resolution provides:
- Executing text-to-SQL with autonomous troubleshooting:
- The agent can interpret pure language questions and convert them into SQL queries. It then executes these queries towards an Amazon Athena database and returns the outcomes.
- If a question execution fails, the agent can analyze the error messages returned by AWS Lambda and mechanically retries the modified question when applicable.
- Dynamic schema discovery
- Itemizing tables – The agent can present a complete listing of the tables within the fraud detection database. This helps customers perceive the obtainable knowledge buildings.
- Describing desk schemas – Customers can request detailed details about the schema of particular tables. The agent will present column names, knowledge sorts, and related feedback, giving customers a transparent understanding of the information construction.
The answer makes use of direct database instruments for schema discovery as a substitute of vector retailer–primarily based retrieval or static schema definitions. This method supplies full accuracy with decrease operational overhead as a result of it doesn’t require a synchronization mechanism and frequently displays the present database construction. Direct schema entry by means of instruments is extra maintainable than hardcoded approaches that require guide updates, and it supplies higher efficiency and cost-efficiency by means of real-time database interplay.
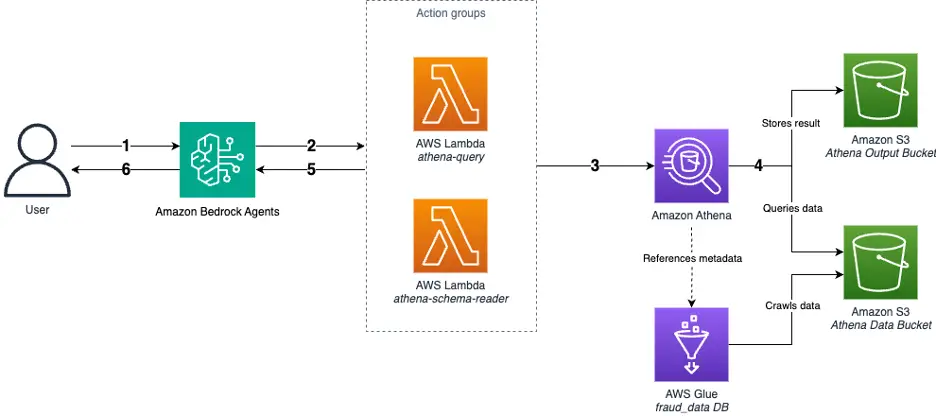
The workflow is as follows:
- A consumer asks inquiries to Amazon Bedrock Brokers.
- To serve the consumer’s questions, the agent determines the suitable motion to invoke:
- To execute the generated question with confidence, the agent will invoke the athena-query
- To substantiate the database schema first, the agent will invoke the athena-schema-reader device:
- Retrieve a listing of obtainable tables utilizing its
/list_tablesendpoint. - Receive the precise schema of a sure desk utilizing its
/describe_tableendpoint.
- Retrieve a listing of obtainable tables utilizing its
- The Lambda operate sends the question to Athena to execute.
- Athena queries the information from the Amazon Easy Storage Service (Amazon S3) knowledge bucket and shops the question ends in the S3 output bucket.
- The Lambda operate retrieves and processes the outcomes. If an error happens:
- The Lambda operate captures and codecs the error message for the agent to grasp.
- The error message is returned to Amazon Bedrock Brokers.
- The agent analyzes the error message and tries to resolve it. To retry with the modified question, the agent could repeat steps 2–5.
- The agent codecs and presents the ultimate responses to the consumer.
The next structure diagram reveals this workflow.

Implementation walkthrough
To implement the answer, use the directions within the following sections.
Clever error dealing with
Our agentic text-to-SQL resolution implements sensible error dealing with that helps brokers perceive and get better from points. By structuring errors with constant parts, returning nonbreaking errors the place potential, and offering contextual hints, the system permits brokers to self-correct and proceed their reasoning course of.
Agent directions
Take into account the important thing immediate elements that make this resolution distinctive. Clever error dealing with helps automate troubleshooting and refine the question by letting the agent perceive the kind of errors and what to do when error occurs:
The immediate offers steering on how one can method the errors. It additionally states that the error sorts and hints can be offered by Lambda. Within the subsequent part, we clarify how Lambda processes the errors and passes them to the agent.
Implementation particulars
Listed below are some key examples from our error dealing with system:
These error sorts cowl the primary eventualities in text-to-SQL interactions:
- Question execution failures – Handles syntax errors and desk reference points, guiding the agent to make use of the right desk names and SQL syntax
- End result retrieval points – Addresses permission issues and invalid column references, serving to the agent confirm the schema and entry rights
- API validation – Verifies that primary necessities are met earlier than question execution, minimizing pointless API calls
Every error sort consists of each an explanatory message and an actionable trace, enabling the agent to take applicable corrective steps. This implementation reveals how easy it may be to allow clever error dealing with; as a substitute of dealing with errors historically inside Lambda, we return structured error messages that the agent can perceive and act upon.
Dynamic schema discovery
The schema discovery is pivotal to retaining Amazon Bedrock Brokers consuming the newest and related schema info.
Agent directions
As an alternative of hardcoded database schema info, we enable the agent to find the database schema dynamically. We’ve created two API endpoints for this goal:
Implementation particulars
Primarily based on the agent directions, the agent will invoke the suitable API endpoint.
The /list_tables endpoint lists the tables in a specified database. That is notably helpful when you’ve gotten a number of databases or incessantly add new tables:
The /describe_table endpoint reads a selected desk’s schema with particulars. We use the “DESCRIBE” command, which incorporates column feedback together with different schema particulars. These feedback assist the agent higher perceive the which means of the person columns:
When implementing a dynamic schema reader, think about together with complete column descriptions to boost the agent’s understanding of the information mannequin.
These endpoints allow the agent to take care of an up-to-date understanding of the database construction, bettering its means to generate correct queries and adapt to adjustments within the schema.
Demonstration
You won’t expertise the very same response with the introduced screenshot because of the indeterministic nature of massive language fashions (LLMs).
The answer is accessible so that you can deploy in your setting with pattern knowledge. Clone the repository from this GitHub hyperlink and comply with the README steering. After you deploy the 2 stacks—AwsText2Sql-DbStack and AwsText2Sql-AgentStack—comply with these steps to place the answer in motion:
- Go to Amazon Bedrock and choose Brokers.
- Choose AwsText-to-SQL-AgentStack-DynamicAgent and take a look at by asking questions within the Check window on the proper.
- Instance interactions:
- Which demographic teams or industries are most incessantly focused by fraudsters? Current aggregated knowledge.
- What particular strategies or strategies are generally utilized by perpetrators within the reported fraud circumstances?
- What patterns or developments can we establish within the timing and placement of fraud incidents?
- Present the small print of shoppers who’ve made transactions with retailers positioned in Denver.
- Present a listing of all retailers together with the overall variety of transactions they’ve processed and the variety of these transactions that have been flagged as fraudulent.
- Checklist the highest 5 prospects primarily based on the very best transaction quantities they’ve made.

- Select Present hint and study every step to grasp what instruments are used and the agent’s rationale for approaching your query, as proven within the following screenshot.

- (Non-compulsory) You possibly can take a look at the Amazon Bedrock Brokers code interpreter by enabling it in Agent settings. Observe the directions at Allow code interpretation in Amazon Bedrock and ask the agent “Create a bar chart exhibiting the highest three cities which have essentially the most fraud circumstances.”

Finest practices
Constructing on our dialogue of dynamic schema discovery and clever error dealing with, listed below are key practices to optimize your agentic text-to-SQL resolution:
- Use dynamic schema discovery and error dealing with – Use endpoints resembling
/list_tablesand/describe_tableto permit the agent to dynamically adapt to your database construction. Implement complete error dealing with as demonstrated earlier, enabling the agent to interpret and reply to numerous error sorts successfully. - Steadiness static and dynamic info – Though dynamic discovery is highly effective, think about together with essential, steady info within the immediate. This may embody database names, key desk relationships, or incessantly used tables that not often change. Putting this stability can enhance efficiency with out sacrificing flexibility.
- Tailoring to your setting – We designed the pattern to at all times invoke
/list_tablesand/describe_table, and your implementation may want changes. Take into account your particular database engine’s capabilities and limitations. You may want to offer extra context past solely column feedback. Take into consideration together with database descriptions, desk relationships, or frequent question patterns. The secret is to provide your agent as a lot related info as potential about your knowledge mannequin and enterprise context, whether or not by means of prolonged metadata, customized endpoints, or detailed directions. - Implement sturdy knowledge safety – Though our resolution makes use of Athena, which inherently doesn’t assist write operations, it’s essential to think about knowledge safety in your particular setting. Begin with clear directions within the immediate (for instance, “read-only operations solely”), and think about extra layers resembling Amazon Bedrock Guardrails or an LLM-based evaluate system to ensure that generated queries align together with your safety insurance policies.
- Implement layered authorization – To reinforce knowledge privateness when utilizing Amazon Bedrock Brokers, you should utilize companies resembling Amazon Verified Permissions to validate consumer entry earlier than the agent processes delicate knowledge. Cross consumer id info, resembling a JWT token, to the agent and its related Lambda operate, enabling fine-grained authorization checks towards pre-built insurance policies. By implementing entry management on the utility stage primarily based on the Verified Permissions determination, you’ll be able to mitigate unintended knowledge disclosure and preserve robust knowledge isolation. To study extra, check with Enhancing knowledge privateness with layered authorization for Amazon Bedrock Brokers within the AWS Safety Weblog.
- Establish the perfect orchestration technique on your agent – Amazon Bedrock supplies you with an choice to customise your agent’s orchestration technique. Customized orchestration offers you full management of the way you need your brokers to deal with multistep duties, make selections, and execute workflows.
By implementing these practices, you’ll be able to create a text-to-SQL resolution that not solely makes use of the total potential of AI brokers, it additionally maintains the safety and integrity of your knowledge methods.
Conclusion
In conclusion, the implementation of a scalable agentic text-to-SQL resolution utilizing AWS companies provides important benefits for enterprise workloads. By utilizing automated schema discovery and sturdy error dealing with, organizations can effectively handle complicated databases with quite a few tables and columns. The agent-based method promotes dynamic question era and refinement, resulting in increased success charges in knowledge querying. We’d like to ask you to do that resolution out right this moment! Go to GitHub to dive deeper into the small print of the answer, and comply with the deployment information to check in your AWS account.
In regards to the Authors
 Jimin Kim is a Prototyping Architect on the AWS Prototyping and Cloud Engineering (PACE) staff, primarily based in Los Angeles. With specialties in Generative AI and SaaS, she loves serving to her prospects succeed of their enterprise. Outdoors of labor, she cherishes moments along with her spouse and three cute calico cats.
Jimin Kim is a Prototyping Architect on the AWS Prototyping and Cloud Engineering (PACE) staff, primarily based in Los Angeles. With specialties in Generative AI and SaaS, she loves serving to her prospects succeed of their enterprise. Outdoors of labor, she cherishes moments along with her spouse and three cute calico cats.
 Jiwon Yeom is a Options Architect at AWS, primarily based in New York Metropolis. She focuses on Generative AI within the monetary companies trade and is keen about serving to prospects construct scalable, safe, and human-centered AI options. Outdoors of labor, she enjoys writing, and exploring hidden bookstores.
Jiwon Yeom is a Options Architect at AWS, primarily based in New York Metropolis. She focuses on Generative AI within the monetary companies trade and is keen about serving to prospects construct scalable, safe, and human-centered AI options. Outdoors of labor, she enjoys writing, and exploring hidden bookstores.



{kind=link}