n8n workflows in manufacturing, you realize the stress of listening to {that a} course of failed and needing to dig by logs to seek out the foundation trigger.
Person: Samir, your automation doesn’t work anymore, I didn’t obtain my notification!
Step one is to open your n8n interface and assessment the final executions to establish the problems.

After a couple of minutes, you end up leaping between executions, evaluating timestamps and studying JSON errors to know the place issues broke.

What if an agent may inform you why your workflow failed at 3 AM with out you having to dig by the logs?
It’s potential!
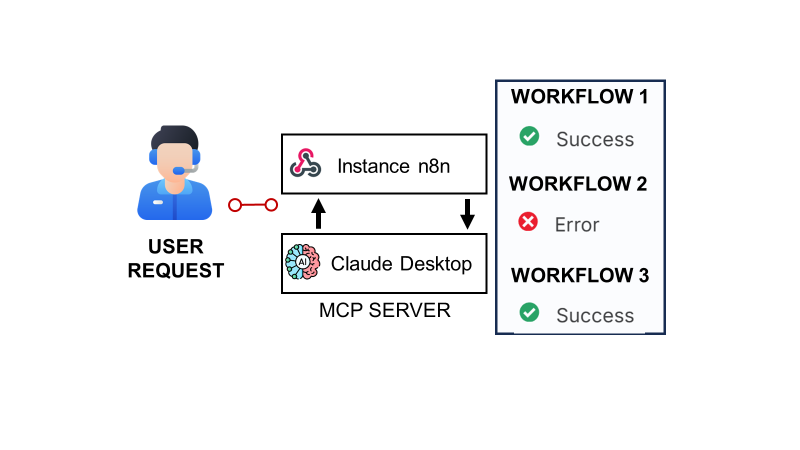
As an experiment, I related the n8n API, which gives entry to execution logs of my occasion, to an MCP server powered by Claude.

The result’s an AI assistant that may monitor workflows, analyse failures, and clarify what went flawed in pure language.

On this article, I’ll stroll you thru the step-by-step strategy of constructing this technique.
The primary part will present an actual instance from my very own n8n occasion, the place a number of workflows failed in the course of the night time.

We’ll use this case to see how the agent identifies points and explains their root causes.
Then, I’ll element how I related my n8n occasion’s API to the MCP server utilizing a webhook to allow Claude Desktop to fetch execution knowledge for natural-language debugging.

The webhook contains three features:
- Get Lively Workflows: which gives the record of all lively workflows
- Get Final Executions: contains details about the final n executions
- Get Executions Particulars (Standing = Error): particulars of failed executions formatted to assist root trigger analyses
Yow will discover the entire tutorial, together with the n8n workflow template and the MCP server supply code, linked on this article.
Demonstration: Utilizing AI to Analyse Failed n8n Executions
Allow us to look collectively at one in all my n8n cases, which runs a number of workflows that fetch occasion info from totally different cities around the globe.
These workflows assist enterprise and networking communities uncover attention-grabbing occasions to attend and be taught from.

To check the answer, I’ll begin by asking the agent to record the lively workflows.
Step 1: What number of workflows are lively?

Primarily based on the query alone, Claude understood that it wanted to work together with the n8n-monitor device, which was constructed utilizing an MCP server.

From there, it mechanically chosen the corresponding operate, Get Lively Workflows, to retrieve the record of lively automations from my n8n occasion.

That is the place you begin to sense the facility of the mannequin.
It mechanically categorised the workflows primarily based on their names
- 8 workflows to hook up with fetch occasions from APIs and course of them
- 3 different workflows which might be work-in-progress, together with the one used to fetch the logs

This marks the start of the evaluation; all these insights will likely be utilised within the root trigger evaluation.
Step 2: Analyse the final n executions
At this stage, we are able to start asking Claude to retrieve the most recent executions for evaluation.

Due to the context supplied within the doc-strings, which I’ll clarify within the subsequent part, Claude understood that it wanted to name the get workflow executions.
It’s going to obtain a abstract of the executions, with the share of failures and the variety of workflows impacted by these failures.
{
"abstract": {
"totalExecutions": 25,
"successfulExecutions": 22,
"failedExecutions": 3,
"failureRate": "12.00%",
"successRate": "88.00%",
"totalWorkflowsExecuted": 7,
"workflowsWithFailures": 1
},
"executionModes": {
"webhook": 7,
"set off": 18
},
"timing": {
"averageExecutionTime": "15.75 seconds",
"maxExecutionTime": "107.18 seconds",
"minExecutionTime": "0.08 seconds",
"timeRange": {
"from": "2025-10-24T06:14:23.127Z",
"to": "2025-10-24T11:11:49.890Z"
}
},
[...]That is the very first thing it’s going to share with you; it gives a transparent overview of the scenario.

Within the second a part of the outputs, yow will discover an in depth breakdown of the failures for every workflow impacted.
"failureAnalysis": {
"workflowsImpactedByFailures": [
"7uvA2XQPMB5l4kI5"
],
"failedExecutionsByWorkflow": {
"7uvA2XQPMB5l4kI5": {
"workflowId": "7uvA2XQPMB5l4kI5",
"failures": [
{
"id": "13691",
"startedAt": "2025-10-24T11:00:15.072Z",
"stoppedAt": "2025-10-24T11:00:15.508Z",
"mode": "trigger"
},
{
"id": "13683",
"startedAt": "2025-10-24T09:00:57.274Z",
"stoppedAt": "2025-10-24T09:00:57.979Z",
"mode": "trigger"
},
{
"id": "13677",
"startedAt": "2025-10-24T07:00:57.167Z",
"stoppedAt": "2025-10-24T07:00:57.685Z",
"mode": "trigger"
}
],
"failureCount": 3
}
},
"recentFailures": [
{
"id": "13691",
"workflowId": "7uvA2XQPMB5l4kI5",
"startedAt": "2025-10-24T11:00:15.072Z",
"mode": "trigger"
},
{
"id": "13683",
"workflowId": "7uvA2XQPMB5l4kI5",
"startedAt": "2025-10-24T09:00:57.274Z",
"mode": "trigger"
},
{
"id": "13677",
"workflowId": "7uvA2XQPMB5l4kI5",
"startedAt": "2025-10-24T07:00:57.167Z",
"mode": "trigger"
}
]
},As a consumer, you now have visibility into the impacted workflows, together with particulars of the failure occurrences.

For this particular case, the workflow “Bangkok Meetup” is triggered each hour.
What we may see is that we had points 3 times (out of 5) over the past 5 hours.
Word: We will ignore the final sentence because the agent doesn’t but have entry to the execution particulars.
The final part of the outputs contains an evaluation of the general efficiency of the workflows.
"workflowPerformance": {
"allWorkflowMetrics": {
"CGvCrnUyGHgB7fi8": {
"workflowId": "CGvCrnUyGHgB7fi8",
"totalExecutions": 7,
"successfulExecutions": 7,
"failedExecutions": 0,
"successRate": "100.00%",
"failureRate": "0.00%",
"lastExecution": "2025-10-24T11:11:49.890Z",
"executionModes": {
"webhook": 7
}
},
[... other workflows ...]
,
"topProblematicWorkflows": [
{
"workflowId": "7uvA2XQPMB5l4kI5",
"totalExecutions": 5,
"successfulExecutions": 2,
"failedExecutions": 3,
"successRate": "40.00%",
"failureRate": "60.00%",
"lastExecution": "2025-10-24T11:00:15.072Z",
"executionModes": {
"trigger": 5
}
},
{
"workflowId": "CGvCrnUyGHgB7fi8",
"totalExecutions": 7,
"successfulExecutions": 7,
"failedExecutions": 0,
"successRate": "100.00%",
"failureRate": "0.00%",
"lastExecution": "2025-10-24T11:11:49.890Z",
"executionModes": {
"webhook": 7
}
},
[... other workflows ...]
}
]
}This detailed breakdown might help you prioritise the upkeep in case you’ve a number of workflows failing.

On this particular instance, I’ve solely a single failing workflow, which is the Ⓜ️ Bangkok Meetup.
What if I need to know when points began?
Don’t fear, I’ve added a bit with the small print of the execution hour by hour.
"timeSeriesData": {
"2025-10-24T11:00": {
"complete": 5,
"success": 4,
"error": 1
},
"2025-10-24T10:00": {
"complete": 6,
"success": 6,
"error": 0
},
"2025-10-24T09:00": {
"complete": 3,
"success": 2,
"error": 1
},
"2025-10-24T08:00": {
"complete": 3,
"success": 3,
"error": 0
},
"2025-10-24T07:00": {
"complete": 3,
"success": 2,
"error": 1
},
"2025-10-24T06:00": {
"complete": 5,
"success": 5,
"error": 0
}
}You simply need to let Claude create a pleasant visible just like the one you’ve under.
Let me remind you right here that I didn’t present any suggestion of outcomes presentation to Claude; that is all from its personal initiative!
Spectacular, no?
Step 3: Root Trigger Evaluation
Now that we all know which workflows have points, we should always seek for the foundation trigger(s).

Claude ought to typically name the Get Error Executions operate to retrieve particulars of executions with failures.
To your info, the failure of this workflow is because of an error within the node JSON Tech that processes the output of the API name.
- Meetup Tech is sending an HTTP question to the Meetup API
- Processed by Consequence Tech Node
- JSON Tech is meant to remodel this output right into a remodeled JSON

Here’s what occurs when all the pieces goes properly.

Nevertheless, it could occur that the API name typically fails and the JavaScript node receives an error, because the enter will not be within the anticipated format.
Word: This situation has been corrected in manufacturing since then (the code node is now extra strong), however I saved it right here for the demo.
Allow us to see if Claude can find the foundation trigger.
Right here is the output of the Get Error Executions operate.
{
"workflow_id": "7uvA2XQPMB5l4kI5",
"workflow_name": "Ⓜ️ Bangkok Meetup",
"error_count": 5,
"errors": [
{
"id": "13691",
"workflow_name": "Ⓜ️ Bangkok Meetup",
"status": "error",
"mode": "trigger",
"started_at": "2025-10-24T11:00:15.072Z",
"stopped_at": "2025-10-24T11:00:15.508Z",
"duration_seconds": 0.436,
"finished": false,
"retry_of": null,
"retry_success_id": null,
"error": {
"message": "A 'json' property isn't an object [item 0]",
"description": "Within the returned knowledge, each key named 'json' should level to an object.",
"http_code": null,
"stage": "error",
"timestamp": null
},
"failed_node": {
"title": "JSON Tech",
"sort": "n8n-nodes-base.code",
"id": "dc46a767-55c8-48a1-a078-3d401ea6f43e",
"place": [
-768,
-1232
]
},
"set off": {}
},
[... 4 other errors ...]
],
"abstract": {
"total_errors": 5,
"error_patterns": {
"A 'json' property is not an object [item 0]": {
"depend": 5,
"executions": [
"13691",
"13683",
"13677",
"13660",
"13654"
]
}
},
"failed_nodes": {
"JSON Tech": 5
},
"time_range": {
"oldest": "2025-10-24T05:00:57.105Z",
"latest": "2025-10-24T11:00:15.072Z"
}
}
}Claude now has entry to the small print of the executions with the error message and the impacted nodes.

Within the response above, you’ll be able to see that Claude summarised the outputs of a number of executions in a single evaluation.
We all know now that:
- Errors occurred each hour besides at 08:00 am
- Every time, the identical node, referred to as “JSON Tech”, is impacted
- The error happens rapidly after the workflow is triggered
This descriptive evaluation is accomplished by the start of a diagnostic.
This assertion will not be incorrect, as evidenced by the error message on the n8n UI.

Nevertheless, as a result of restricted context, Claude begins to supply suggestions to repair the workflow that aren’t appropriate.

Along with the code correction, it gives an motion plan.

As I do know that the difficulty will not be (solely) on the code node, I wished to information Claude within the root trigger evaluation.

It lastly challenged the preliminary proposal of the decision and commenced to share assumptions in regards to the root trigger(s).

This begins to get nearer to the precise root trigger, offering sufficient insights for us to begin exploring the workflow.

The revised repair is now higher because it considers the likelihood that the difficulty comes from the node enter knowledge.
For me, that is one of the best I may count on from Claude, contemplating the restricted info that he has readily available.
Conclusion: Worth Proposition of This Device
This straightforward experiment demonstrates how an AI agent powered by Claude can lengthen past primary monitoring to ship real operational worth.
Earlier than manually checking executions and logs, you’ll be able to first converse together with your automation system to ask what failed, why it failed, and obtain context-aware explanations inside seconds.
This won’t change you totally, however it could speed up the foundation trigger evaluation course of.
Within the subsequent part, I’ll briefly introduce how I arrange the MCP Server to attach Claude Desktop to my occasion.
Constructing a neighborhood MCP Server to attach Claude Desktop to a FastAPI Microservice
To equip Claude with the three features out there within the webhook (Get Lively Workflows, Get Workflow Executions and Get Error Executions), I’ve applied an MCP Server.

On this part, I’ll briefly introduce the implementation, focusing solely on Get Lively Workflows and Get Workflows Executions, to reveal how I clarify the utilization of those instruments to Claude.
For a complete and detailed introduction to the answer, together with directions on the right way to deploy it on your machine, I invite you to look at this tutorial on my YouTube Channel.
Additionally, you will discover the MCP Server supply code and the n8n workflow of the webhook.
Create a Class to Question the Workflow
Earlier than inspecting the right way to arrange the three totally different instruments, let me introduce the utility class, which is outlined with all of the features wanted to work together with the webhook.
Yow will discover it within the Python file: ./utils/n8n_monitory_sync.py
import logging
import os
from datetime import datetime, timedelta
from typing import Any, Dict, Elective
import requests
import traceback
logger = logging.getLogger(__name__)
class N8nMonitor:
"""Handler for n8n monitoring operations - synchronous model"""
def __init__(self):
self.webhook_url = os.getenv("N8N_WEBHOOK_URL", "")
self.timeout = 30Primarily, we retrieve the webhook URL from an setting variable and set a question timeout of 30 seconds.
The primary operate get_active_workflows is querying the webhook passing as a parameter: "motion": get_active_workflows".
def get_active_workflows(self) -> Dict[str, Any]:
"""Fetch all lively workflows from n8n"""
if not self.webhook_url:
logger.error("Setting variable N8N_WEBHOOK_URL not configured")
return {"error": "N8N_WEBHOOK_URL setting variable not set"}
attempt:
logger.information("Fetching lively workflows from n8n")
response = requests.put up(
self.webhook_url,
json={"motion": "get_active_workflows"},
timeout=self.timeout
)
response.raise_for_status()
knowledge = response.json()
logger.debug(f"Response sort: {sort(knowledge)}")
# Checklist of all workflows
workflows = []
if isinstance(knowledge, record):
workflows = [item for item in data if isinstance(item, dict)]
if not workflows and knowledge:
logger.error(f"Anticipated record of dictionaries, bought record of {sort(knowledge[0]).__name__}")
return {"error": "Webhook returned invalid knowledge format"}
elif isinstance(knowledge, dict):
if "knowledge" in knowledge:
workflows = knowledge["data"]
else:
logger.error(f"Surprising dict response with keys: {record(knowledge.keys())} n {traceback.format_exc()}")
return {"error": "Surprising response format"}
else:
logger.error(f"Surprising response sort: {sort(knowledge)} n {traceback.format_exc()}")
return {"error": f"Surprising response sort: {sort(knowledge).__name__}"}
logger.information(f"Efficiently fetched {len(workflows)} lively workflows")
return {
"total_active": len(workflows),
"workflows": [
{
"id": wf.get("id", "unknown"),
"name": wf.get("name", "Unnamed"),
"created": wf.get("createdAt", ""),
"updated": wf.get("updatedAt", ""),
"archived": wf.get("isArchived", "false") == "true"
}
for wf in workflows
],
"abstract": {
"complete": len(workflows),
"names": [wf.get("name", "Unnamed") for wf in workflows]
}
}
besides requests.exceptions.RequestException as e:
logger.error(f"Error fetching workflows: {e} n {traceback.format_exc()}")
return {"error": f"Didn't fetch workflows: {str(e)} n {traceback.format_exc()}"}
besides Exception as e:
logger.error(f"Surprising error fetching workflows: {e} n {traceback.format_exc()}")
return {"error": f"Surprising error: {str(e)} n {traceback.format_exc()}"}I’ve added many checks, because the API typically fails to return the anticipated knowledge format.
This resolution is extra strong, offering Claude with all the knowledge to know why a question failed.
Now that the primary operate is roofed, we are able to concentrate on getting all of the final n executions with get_workflow_executions.
def get_workflow_executions(
self,
restrict: int = 50,
includes_kpis: bool = False,
) -> Dict[str, Any]:
"""Fetch workflow executions of the final 'restrict' executions with or with out KPIs """
if not self.webhook_url:
logger.error("Setting variable N8N_WEBHOOK_URL not set")
return {"error": "N8N_WEBHOOK_URL setting variable not set"}
attempt:
logger.information(f"Fetching the final {restrict} executions")
payload = {
"motion": "get_workflow_executions",
"restrict": restrict
}
response = requests.put up(
self.webhook_url,
json=payload,
timeout=self.timeout
)
response.raise_for_status()
knowledge = response.json()
if isinstance(knowledge, record) and len(knowledge) > 0:
knowledge = knowledge[0]
logger.information("Efficiently fetched execution knowledge")
if includes_kpis and isinstance(knowledge, dict):
logger.information("Together with KPIs within the execution knowledge")
if "abstract" in knowledge:
abstract = knowledge["summary"]
failure_rate = float(abstract.get("failureRate", "0").rstrip("%"))
knowledge["insights"] = {
"health_status": "🟢 Wholesome" if failure_rate < 10 else
"🟡 Warning" if failure_rate < 25 else
"🔴 Important",
"message": f"{abstract.get('totalExecutions', 0)} executions with {abstract.get('failureRate', '0%')} failure fee"
}
return knowledge
besides requests.exceptions.RequestException as e:
logger.error(f"HTTP error fetching executions: {e} n {traceback.format_exc()}")
return {"error": f"Didn't fetch executions: {str(e)}"}
besides Exception as e:
logger.error(f"Surprising error fetching executions: {e} n {traceback.format_exc()}")
return {"error": f"Surprising error: {str(e)}"}The one parameter right here is the quantity n of executions you need to retrieve: "restrict": n.
The outputs embrace a abstract with a well being standing that’s generated by the code node Processing Audit. (extra particulars within the tutorial)
The operate get_workflow_executions solely retrieves the outputs for formatting earlier than sending them to the agent.
Now that now we have outlined our core features, we are able to create the instruments to equip Claude through the MCP server.
Arrange an MCP Server with Instruments
Now it’s the time to create our MCP server with instruments and sources to equip (and educate) Claude.
from mcp.server.fastmcp import FastMCP
import logging
from typing import Elective, Dict, Any
from utils.n8n_monitor_sync import N8nMonitor
logging.basicConfig(
stage=logging.INFO,
format='%(asctime)s - %(levelname)s - %(message)s',
handlers=[
logging.FileHandler("n8n_monitor.log"),
logging.StreamHandler()
]
)
logger = logging.getLogger(__name__)
mcp = FastMCP("n8n-monitor")
monitor = N8nMonitor()It’s a primary implementation utilizing FastMCP and importing n8n_monitor_sync.py with the features outlined within the earlier part.
# Useful resource for the agent (Samir: replace it every time you add a device)
@mcp.useful resource("n8n://assist")
def get_help() -> str:
"""Get assist documentation for the n8n monitoring instruments"""
return """
📊 N8N MONITORING TOOLS
=======================
WORKFLOW MONITORING:
• get_active_workflows()
Checklist all lively workflows with names and IDs
EXECUTION TRACKING:
• get_workflow_executions(restrict=50, include_kpis=True)
Get execution logs with detailed KPIs
- restrict: Variety of latest executions to retrieve (1-100)
- include_kpis: Calculate efficiency metrics
ERROR DEBUGGING:
• get_error_executions(workflow_id)
Retrieve detailed error info for a particular workflow
- Returns final 5 errors with complete debugging knowledge
- Exhibits error messages, failed nodes, set off knowledge
- Identifies error patterns and problematic nodes
- Contains HTTP codes, error ranges, and timing information
HEALTH REPORTING:
• get_workflow_health_report(restrict=50)
Generate complete well being evaluation primarily based on latest executions
- Identifies problematic workflows
- Exhibits success/failure charges
- Offers execution timing metrics
KEY METRICS PROVIDED:
• Complete executions
• Success/failure charges
• Execution instances (avg, min, max)
• Workflows with failures
• Execution modes (handbook, set off, built-in)
• Error patterns and frequencies
• Failed node identification
HEALTH STATUS INDICATORS:
• 🟢 Wholesome: <10% failure fee
• 🟡 Warning: 10-25% failure fee
• 🔴 Important: >25% failure fee
USAGE EXAMPLES:
- "Present me all lively workflows"
- "What workflows have been failing?"
- "Generate a well being report for my n8n occasion"
- "Present execution metrics for the final 48 hours"
- "Debug errors in workflow CGvCrnUyGHgB7fi8"
- "What's inflicting failures in my knowledge processing workflow?"
DEBUGGING WORKFLOW:
1. Use get_workflow_executions() to establish problematic workflows
2. Use get_error_executions() for detailed error evaluation
3. Examine error patterns to establish recurring points
4. Assessment failed node particulars and set off knowledge
5. Use workflow_id and execution_id for focused fixes
"""Because the device is advanced to apprehend, we embrace a immediate, within the type of an MCP useful resource, to summarise the target and options of the n8n workflow related through webhook.
Now we are able to outline the primary device to get all of the lively workflows.
@mcp.device()
def get_active_workflows() -> Dict[str, Any]:
"""
Get all lively workflows within the n8n occasion.
Returns:
Dictionary with record of lively workflows and their particulars
"""
attempt:
logger.information("Fetching lively workflows")
consequence = monitor.get_active_workflows()
if "error" in consequence:
logger.error(f"Didn't get workflows: {consequence['error']}")
else:
logger.information(f"Discovered {consequence.get('total_active', 0)} lively workflows")
return consequence
besides Exception as e:
logger.error(f"Surprising error: {str(e)}")
return {"error": str(e)}The docstring, used to elucidate to the MCP server the right way to use the device, is comparatively transient, as there aren’t any enter parameters for get_active_workflows().
Allow us to do the identical for the second device to retrieve the final n executions.
@mcp.device()
def get_workflow_executions(
restrict: int = 50,
include_kpis: bool = True
) -> Dict[str, Any]:
"""
Get workflow execution logs and KPIs for the final N executions.
Args:
restrict: Variety of executions to retrieve (default: 50)
include_kpis: Embody calculated KPIs (default: true)
Returns:
Dictionary with execution knowledge and KPIs
"""
attempt:
logger.information(f"Fetching the final {restrict} executions")
consequence = monitor.get_workflow_executions(
restrict=restrict,
includes_kpis=include_kpis
)
if "error" in consequence:
logger.error(f"Didn't get executions: {consequence['error']}")
else:
if "abstract" in consequence:
abstract = consequence["summary"]
logger.information(f"Executions: {abstract.get('totalExecutions', 0)}, "
f"Failure fee: {abstract.get('failureRate', 'N/A')}")
return consequence
besides Exception as e:
logger.error(f"Surprising error: {str(e)}")
return {"error": str(e)}Not like the earlier device, we have to specify the enter knowledge with the default worth.
We have now now geared up Claude with these two instruments that can be utilized as within the instance introduced within the earlier part.
What’s subsequent? Deploy it in your machine!
As I wished to maintain this text quick, I’ll solely introduce these two instruments.
For the remainder of the functionalities, I invite you to look at this entire tutorial on my YouTube channel.
I embrace step-by-step explanations on the right way to deploy this in your machine with an in depth assessment of the supply code shared on my GitHub (MCP Server) and n8n profile (workflow).
Conclusion
That is only the start!
We will think about this as model 1.0 of what can develop into an excellent agent to handle your n8n workflows.
What do I imply by this?
There’s a large potential for enhancing this resolution, particularly for the foundation trigger evaluation by:
- Offering extra context to the agent utilizing the sticky notes contained in the workflows
- Exhibiting how good inputs and outputs look with analysis nodes to assist Claude carry out hole analyses
- Exploiting the opposite endpoints of the n8n API for extra correct analyses
Nevertheless, I don’t assume I can, as a full-time startup founder and CEO, develop such a complete device by myself.
Due to this fact, I wished to share that with the In the direction of Knowledge Science and n8n group as an open-source resolution out there on my GitHub profile.
Want inspiration to begin automating with n8n?
On this weblog, I’ve revealed a number of articles to share examples of workflow automations now we have applied for small, medium and enormous operations.

The main focus was primarily on logistics and provide chain operations with actual case research:
I even have a full playlist on my YouTube Channel, Provide Science, with greater than 15 tutorials.

You may comply with these tutorials to deploy the workflows I share on my n8n creator profile (linked within the descriptions) that cowl:
- Course of Automation for Logistics and Provide Chain
- AI-Powered Workflows for Content material Creation
- Productiveness and Language Studying
Be at liberty to share your questions within the remark sections of the movies.
Different examples of MCP Server Implementation
This isn’t my first implementation of MCP servers.
In one other experiment, I related Claude Desktop with a Provide-Chain Community Optimisation device.

On this instance, the n8n workflow is changed by a FastAPI microservice internet hosting a linear programming algorithm.

The target is to find out the optimum set of factories to supply and ship merchandise to market on the lowest value and with the smallest environmental footprint.

In such a train, Claude is doing a fantastic job of synthesising and presenting outcomes.
For extra info, take a look at this In the direction of Knowledge Science Article.
About Me
Let’s join on Linkedin and Twitter. I’m a Provide Chain Engineer who makes use of knowledge analytics to enhance logistics operations and cut back prices.
For consulting or recommendation on analytics and sustainable provide chain transformation, be happy to contact me through Logigreen Consulting.
If you’re concerned with Knowledge Analytics and Provide Chain, take a look at my web site.



{kind=link}