“How a lot will it price to run our chatbot on Amazon Bedrock?” This is without doubt one of the most frequent questions we hear from clients exploring AI options. And it’s no marvel — calculating prices for AI purposes can really feel like navigating a posh maze of tokens, embeddings, and numerous pricing fashions. Whether or not you’re an answer architect, technical chief, or enterprise decision-maker, understanding these prices is essential for undertaking planning and budgeting. On this put up, we’ll have a look at Amazon Bedrock pricing via the lens of a sensible, real-world instance: constructing a customer support chatbot. We’ll break down the important price parts, stroll via capability planning for a mid-sized name heart implementation, and supply detailed pricing calculations throughout completely different basis fashions. By the tip of this put up, you’ll have a transparent framework for estimating your personal Amazon Bedrock implementation prices and understanding the important thing elements that affect them.
For people who aren’t acquainted, Amazon Bedrock is a completely managed service that provides a alternative of high-performing basis fashions (FMs) from main synthetic intelligence (AI) corporations like AI21 Labs, Anthropic, Cohere, Meta, Stability AI, and Amazon via a single API, together with a broad set of capabilities to construct generative AI purposes with safety, privateness, and accountable AI.
Amazon Bedrock gives a complete toolkit for powering AI purposes, together with pre-trained giant language fashions (LLMs), Retrieval Augmented Era (RAG) capabilities, and seamless integration with present data bases. This highly effective mixture permits the creation of chatbots that may perceive and reply to buyer queries with excessive accuracy and contextual relevance.
Resolution overview
For this instance, our Amazon Bedrock chatbot will use a curated set of information sources and use Retrieval-Augmented Era (RAG) to retrieve related data in actual time. With RAG, our output from the chatbot might be enriched with contextual data from our knowledge sources, giving our customers a greater buyer expertise. When understanding Amazon Bedrock pricing, it’s essential to familiarize your self with a number of key phrases that considerably affect the anticipated price. These parts not solely type the inspiration of how your chatbot capabilities but in addition instantly influence your pricing calculations. Let’s discover these key parts. Key Elements
- Information Sources – The paperwork, manuals, FAQs, and different data artifacts that type your chatbot’s data base.
- Retrieval-Augmented Era (RAG) – The method of optimizing the output of a giant language mannequin by referencing an authoritative data base outdoors of its coaching knowledge sources earlier than producing a response. RAG extends the already highly effective capabilities of LLMs to particular domains or a corporation’s inside data base, with out the necessity to retrain the mannequin. It’s a cost-effective strategy to bettering LLM output so it stays related, correct, and helpful in numerous contexts.
- Tokens – A sequence of characters {that a} mannequin can interpret or predict as a single unit of that means. For instance, with textual content fashions, a token might correspond not simply to a phrase, but in addition to part of a phrase with grammatical that means (comparable to “-ed”), a punctuation mark (comparable to “?”), or a typical phrase (comparable to “loads”). Amazon Bedrock costs are based mostly on the variety of enter and output tokens processed.
- Context Window – The utmost quantity of textual content (measured in tokens) that an LLM can course of in a single request. This contains each the enter textual content and extra context wanted to generate a response. A bigger context window permits the mannequin to think about extra data when producing responses, enabling extra complete and contextually acceptable outputs.
- Embeddings – Dense vector representations of textual content that seize semantic that means. In a RAG system, embeddings are created for each data base paperwork and consumer queries, enabling semantic similarity searches to retrieve probably the most related data out of your data base to reinforce the LLM’s responses.
- Vector Retailer: A vector retailer incorporates the embeddings in your knowledge sources and acts as your data base.
Embeddings Mannequin: Embedding fashions are machine studying fashions that convert knowledge (textual content, photographs, code, and many others.) into fixed-size numerical vectors. These vectors seize the semantic that means of the enter in a format that can be utilized for similarity search, clustering, classification, suggestion programs, and retrieval-augmented era (RAG). - Massive Language Fashions (LLMs) – Fashions educated on huge volumes of information that use billions of parameters to generate unique output for duties like answering questions, translating languages, and finishing sentences. Amazon Bedrock presents a various choice of these basis fashions (FMs), every with completely different capabilities and specialised strengths.
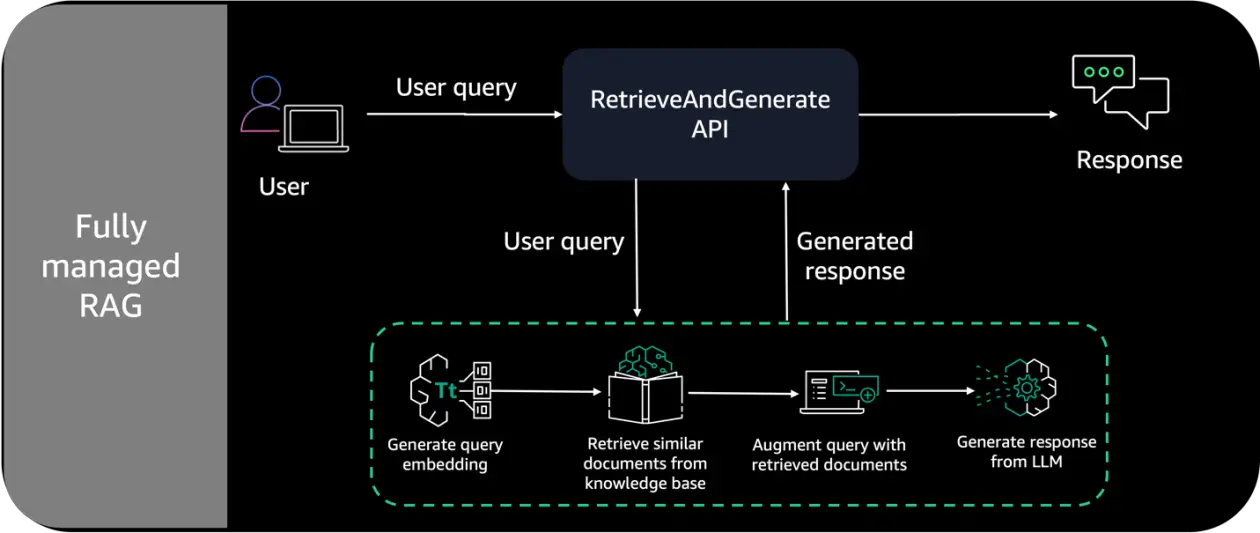
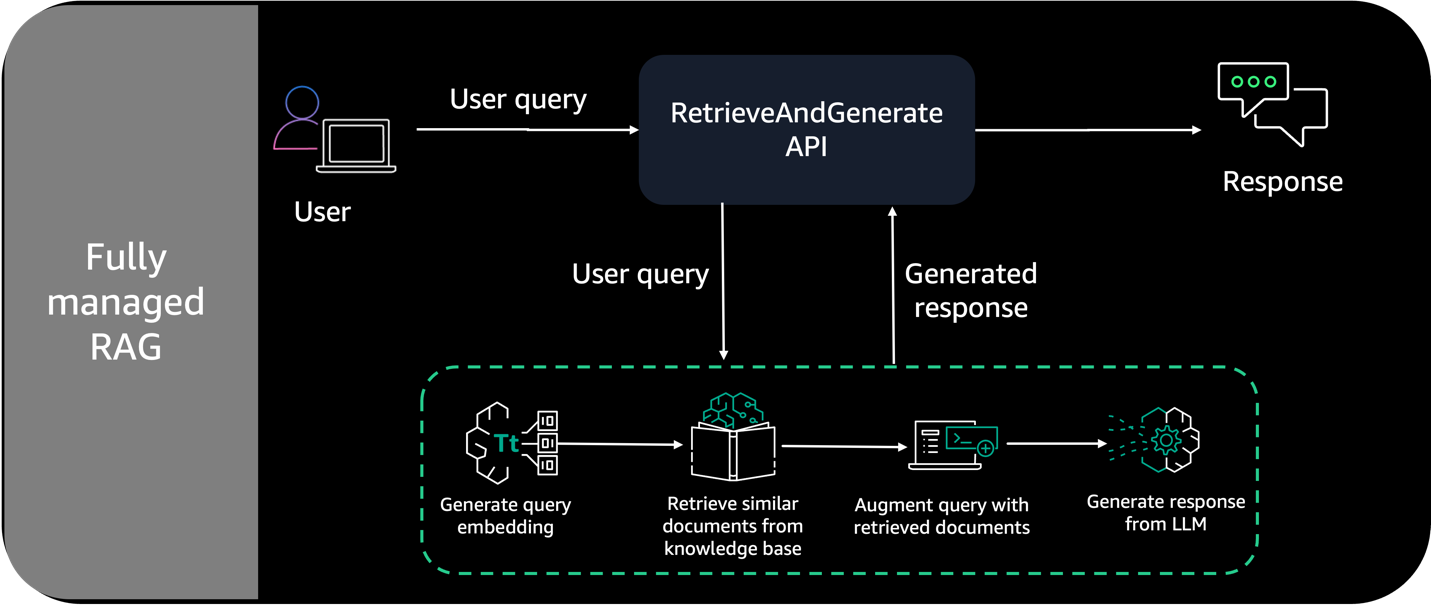
The determine beneath demonstrates the structure of a completely managed RAG resolution on AWS.
Estimating Pricing
Probably the most difficult points of implementing an AI resolution is precisely predicting your capability wants. With out correct capability estimation, you would possibly both over-provision (resulting in pointless prices) or under-provision (leading to efficiency points). Let’s stroll via strategy this significant planning step for a real-world state of affairs. Earlier than we dive into the numbers, let’s perceive the important thing elements that have an effect on your capability and prices:
- Embeddings: Vector representations of your textual content that allow semantic search capabilities. Every doc in your data base must be transformed into embeddings, which impacts each processing prices and storage necessities.
- Person Queries: The incoming questions or requests out of your customers. Understanding your anticipated question quantity and complexity is essential, as every question consumes tokens and requires processing energy.
- LLM Responses: The AI-generated solutions to consumer queries. The size and complexity of those responses instantly have an effect on your token utilization and processing prices.
- Concurrency: The variety of simultaneous customers your system must deal with. Greater concurrency necessities could necessitate extra infrastructure and might have an effect on your alternative of pricing mannequin.
To make this concrete, let’s study a typical name heart implementation. Think about you’re planning to deploy a customer support chatbot for a mid-sized group dealing with product inquiries and assist requests. Right here’s how we’d break down the capability planning: First, contemplate your data base. In our state of affairs, we’re working with 10,000 assist paperwork, every averaging 500 tokens in size. These paperwork must be chunked into smaller items for efficient retrieval, with every doc sometimes splitting into 5 chunks. This provides us a complete of 5 million tokens for our data base. For the embedding course of, these 10,000 paperwork will generate roughly 50,000 embeddings once we account for chunking and overlapping content material. That is necessary as a result of embeddings have an effect on each your preliminary setup prices and ongoing storage wants.
Now, let’s have a look at the operational necessities. Based mostly on typical name heart volumes, we’re planning for:
- 10,000 buyer queries per thirty days
- Question lengths various from 50 to 200 tokens (relying on complexity)
- Common response size of 100 tokens per interplay
- Peak utilization of 100 simultaneous customers
Once we mixture these numbers, our month-to-month capability necessities form as much as:
- 5 million tokens for processing our data base
- 50,000 embeddings for semantic search
- 500,000 tokens for dealing with consumer queries
- 1 million tokens for producing responses
Understanding these numbers is essential as a result of they instantly influence your prices in a number of methods:
- Preliminary setup prices for processing and embedding your data base
- Ongoing storage prices for sustaining your vector database and doc storage
- Month-to-month processing prices for dealing with consumer interactions
- Infrastructure prices to assist your concurrency necessities
This provides us a strong basis for our price calculations, which we’ll discover intimately within the subsequent part.
Calculating whole price of possession (TCO)
Amazon Bedrock presents versatile pricing modes. With Amazon Bedrock, you might be charged for mannequin inference and customization. You’ve a alternative of two pricing plans for inference: 1. On-Demand and Batch: This mode permits you to use FMs on a pay-as-you-go foundation with out having to make time-based time period commitments. 2. Provisioned Throughput: This mode permits you to provision enough throughput to fulfill your software’s efficiency necessities in trade for a time-based time period dedication.
- On-demand – Ideally suited for rare or unpredictable utilization
- Batch – Designed for processing giant volumes of information in a single operation
- Provisioned throughput – Tailor-made for purposes with constant and predictable workloads
To calculate the TCO for this state of affairs as one-time price we’ll contemplate the inspiration mannequin, the quantity of information within the data base, the estimated variety of queries and responses, and the concurrency stage talked about above. For this state of affairs we’ll be utilizing an on-demand pricing mannequin and displaying how the pricing can be for among the basis fashions out there on Amazon Bedrock.
The On-Demand Pricing formulation might be:
The price of this setup would be the sum of price of LLM inferences and price of vector retailer. To estimate price of inferences, you may acquire the variety of enter tokens, context measurement and output tokens within the response metadata returned by the LLM. Whole Price Incurred = ((Enter Tokens + Context Measurement) * Value per 1000 Enter Tokens + Output tokens * Value per 1000 Output Tokens) + Embeddings. For enter tokens we might be including a further context measurement of about 150 tokens for Person Queries. Due to this fact as per our assumption of 10,000 Person Queries, the entire Context Measurement might be 1,500,000 tokens.
The next is a comparability of estimated month-to-month prices for numerous fashions on Amazon Bedrock based mostly on our instance use case utilizing the on-demand pricing formulation:
Embeddings Price:
For textual content embeddings on Amazon Bedrock, we are able to select from Amazon Titan Embeddings V2 mannequin or Cohere Embeddings Mannequin. On this instance we’re calculating a one-time price for the embeddings.
- Amazon Titan Textual content Embeddings V2:
- Value per 1,000 enter tokens – $0.00002
- Price of Embeddings – (Information Sources + Person Queries) * Embeddings price per 1000 tokens
- (5,000,000 +500,000) * 0.00002/1000 = $0.11
- Cohere Embeddings:
- Value per 1,000 enter tokens – $0.0001
- Price of Embeddings – (5,000,000+500,000) * 0.0001/1000 =$0.55
The same old price of vector shops has 2 parts: measurement of vector knowledge + variety of requests to the shop. You’ll be able to select whether or not to let the Amazon Bedrock console arrange a vector retailer in Amazon OpenSearch Serverless for you or to make use of one that you’ve created in a supported service and configured with the suitable fields. In the event you’re utilizing OpenSearch Serverless as a part of your setup, you’ll want to think about its prices. Pricing particulars might be discovered right here: OpenSearch Service Pricing .
Right here utilizing the On-Demand pricing formulation, the general price is calculated utilizing some basis fashions (FMs) out there on Amazon Bedrock and the Embeddings price.
- Claude 4 Sonnet: ((500,000 +1,500,000) tokens/1000 * $0.003 + 1,000,000 tokens/1000* $0.015 = $21+0.11= $21.11
- Claude 3 Haiku: ((500,000 +1,500,000) tokens/1000 * $0.00025 + 1,000,000 tokens/1000* $0.00125 = $1.75+0.11= $1.86
• Amazon Nova:
- Amazon Nova Professional: ((500,000 +1,500,000) tokens/1000 * $0.0008 + 1,000,000 tokens/1000* $0.0032= $4.8+0.11= $4.91
- Amazon Nova Lite: ((500,000 +1,500,000) tokens/1000 * $0.00006 + 1,000,000 tokens/1000* $0.00024 = $0.36+0.11= $0.47
• Meta Llama:
- Llama 4 Maverick (17B): ((500,000 +1,500,000) tokens/1000 * $0.00024 + 1,000,000 tokens/1000* $0.00097= $1.45+0.11= $1.56
- Llama 3.3 Instruct (70B): ((500,000 +1,500,000) tokens/1000 * $0.00072 + 1,000,000 tokens/1000* $0.00072 = $2.16+0.11= $2.27
Consider fashions not simply on their pure language understanding (NLU) and era (NLG) capabilities, but in addition on their price-per-token ratios for each enter and output processing. Contemplate whether or not premium fashions with larger per-token prices ship proportional worth in your particular use case, or if more cost effective alternate options like Amazon Nova Lite or Meta Llama fashions can meet your efficiency necessities at a fraction of the associated fee.
Conclusion
Understanding and estimating Amazon Bedrock prices doesn’t should be overwhelming. As we’ve demonstrated via our customer support chatbot instance, breaking down the pricing into its core parts – token utilization, embeddings, and mannequin choice – makes it manageable and predictable.
Key takeaways for planning your Bedrock implementation prices:
- Begin with a transparent evaluation of your data base measurement and anticipated question quantity
- Contemplate each one-time prices (preliminary embeddings) and ongoing operational prices
- Examine completely different basis fashions based mostly on each efficiency and pricing
- Think about your concurrency necessities when selecting between on-demand, batch, or provisioned throughput pricing
By following this systematic strategy to price estimation, you may confidently plan your Amazon Bedrock implementation and select probably the most cost-effective configuration in your particular use case. Keep in mind that the most cost effective choice isn’t all the time the perfect – contemplate the stability between price, efficiency, and your particular necessities when making your ultimate resolution.
Getting Began with Amazon Bedrock
With Amazon Bedrock, you’ve gotten the pliability to decide on probably the most appropriate mannequin and pricing construction in your use case. We encourage you to discover the AWS Pricing Calculator for extra detailed price estimates based mostly in your particular necessities.
To study extra about constructing and optimizing chatbots with Amazon Bedrock, try the workshop Constructing with Amazon Bedrock.
We’d love to listen to about your experiences constructing chatbots with Amazon Bedrock. Share your success tales or challenges within the feedback!
In regards to the authors
 Srividhya Pallay is a Options Architect II at Amazon Net Companies (AWS) based mostly in Seattle, the place she helps small and medium-sized companies (SMBs) and makes a speciality of Generative Synthetic Intelligence and Video games. Srividhya holds a Bachelor’s diploma in Computational Information Science from Michigan State College School of Engineering, with a minor in Laptop Science and Entrepreneurship. She holds 6 AWS Certifications.
Srividhya Pallay is a Options Architect II at Amazon Net Companies (AWS) based mostly in Seattle, the place she helps small and medium-sized companies (SMBs) and makes a speciality of Generative Synthetic Intelligence and Video games. Srividhya holds a Bachelor’s diploma in Computational Information Science from Michigan State College School of Engineering, with a minor in Laptop Science and Entrepreneurship. She holds 6 AWS Certifications.
 Prerna Mishra is a Options Architect at Amazon Net Companies(AWS) supporting Enterprise ISV clients. She makes a speciality of Generative AI and MLOPs as a part of Machine Studying and Synthetic Intelligence neighborhood. She graduated from New York College in 2022 with a Grasp’s diploma in Information Science and Data Methods.
Prerna Mishra is a Options Architect at Amazon Net Companies(AWS) supporting Enterprise ISV clients. She makes a speciality of Generative AI and MLOPs as a part of Machine Studying and Synthetic Intelligence neighborhood. She graduated from New York College in 2022 with a Grasp’s diploma in Information Science and Data Methods.
 Brian Clark is a Options Architect at Amazon Net Companies (AWS) supporting Enterprise clients within the monetary providers vertical. He is part of the Machine Studying and Synthetic Intelligence neighborhood and makes a speciality of Generative AI and Agentic workflows. Brian has over 14 years of expertise working in know-how and holds 8 AWS certifications.
Brian Clark is a Options Architect at Amazon Net Companies (AWS) supporting Enterprise clients within the monetary providers vertical. He is part of the Machine Studying and Synthetic Intelligence neighborhood and makes a speciality of Generative AI and Agentic workflows. Brian has over 14 years of expertise working in know-how and holds 8 AWS certifications.



{kind=link}