
Vector embeddings have change into important for contemporary Retrieval Augmented Era (RAG) functions, however organizations face vital value challenges as they scale. As data bases develop and require extra granular embeddings, many vector databases that depend on high-performance storage corresponding to SSDs or in-memory options change into prohibitively costly. This value barrier typically forces organizations to restrict the scope of their RAG functions or compromise on the granularity of their vector representations, probably impacting the standard of outcomes. Moreover, to be used instances involving historic or archival information that also wants to stay searchable, storing vectors in specialised vector databases optimized for top throughput workloads represents an pointless ongoing expense.
Beginning July 15, Amazon Bedrock Data Bases prospects can choose Amazon S3 Vectors (preview), the primary cloud object storage with built-in assist to retailer and question vectors at a low value, as a vector retailer. Amazon Bedrock Data Bases customers can now scale back vector add, storage, and question prices by as much as 90%. Designed for sturdy and cost-optimized storage of enormous vector datasets with subsecond question efficiency, S3 Vectors is right for RAG functions that require long-term storage of huge vector volumes and may tolerate the efficiency tradeoff in comparison with excessive queries per second (QPS), millisecond latency vector databases. The mixing with Amazon Bedrock means you possibly can construct extra economical RAG functions whereas preserving the semantic search efficiency wanted for high quality outcomes.
On this submit, we display tips on how to combine Amazon S3 Vectors with Amazon Bedrock Data Bases for RAG functions. You’ll be taught a sensible method to scale your data bases to deal with tens of millions of paperwork whereas sustaining retrieval high quality and utilizing S3 Vectors cost-effective storage.
Amazon Bedrock Data Bases and Amazon S3 Vectors integration overview
When making a data base in Amazon Bedrock, you possibly can choose S3 Vectors as your vector storage possibility. Utilizing this method, you possibly can construct cost-effective, scalable RAG functions with out provisioning or managing complicated infrastructure. The mixing delivers vital value financial savings whereas sustaining subsecond question efficiency, making it supreme for working with bigger vector datasets generated from huge volumes of unstructured information together with textual content, photos, audio, and video. Utilizing a pay-as-you-go pricing mannequin at low worth factors, S3 Vectors gives industry-leading value optimization that reduces the price of importing, storing, and querying vectors by as much as 90% in comparison with various options. Superior search capabilities embody wealthy metadata filtering, so you possibly can refine queries by doc attributes corresponding to dates, classes, and sources. The mix of S3 Vectors and Amazon Bedrock is right for organizations constructing large-scale data bases that demand each value effectivity and performant retrieval—from managing intensive doc repositories to historic archives and functions requiring granular vector representations. The walkthrough follows these high-level steps:
- Create a brand new data base
- Configure the information supply
- Configure information supply and processing
- Sync the information supply
- Check the data base
Conditions
Earlier than you get began, just remember to have the next conditions:
Amazon Bedrock Data Bases and Amazon S3 Vectors integration walkthrough
On this part, we stroll by the step-by-step course of of making a data base with Amazon S3 Vectors utilizing the AWS Administration Console. We cowl the end-to-end course of from configuring your vector retailer to ingesting paperwork and testing your retrieval capabilities.
For many who desire to configure their data base programmatically relatively than utilizing the console, the Amazon Bedrock Data Bases with S3 Vectors repository in GitHub offers a guided pocket book you can observe to deploy the setup in your personal account.
Create a brand new data base
To create a brand new data base, observe these steps:
- On the Amazon Bedrock console within the left navigation pane, select Data Bases. To provoke the creation course of, within the Create dropdown checklist, select Data Base with vector retailer.
- On the Present Data Base particulars web page, enter a descriptive title to your data base and an non-obligatory description to establish its objective. Choose your IAM permissions method—both create a brand new service position or use an current one—to grant the mandatory permissions for accessing AWS providers, as proven within the following screenshot.

- Select Amazon S3. Optionally, add tags to assist set up and categorize your sources and configure log supply locations corresponding to an S3 bucket or Amazon CloudWatch for monitoring and troubleshooting.
- Select Subsequent to proceed to the information supply configuration.
Configure the information supply
To configure the information supply, observe these steps:
- Assign a descriptive title to your data base information.
- In Knowledge supply location, choose whether or not the S3 bucket exists in your present AWS account or one other account, then specify the placement the place your paperwork are saved, as proven within the following screenshot.
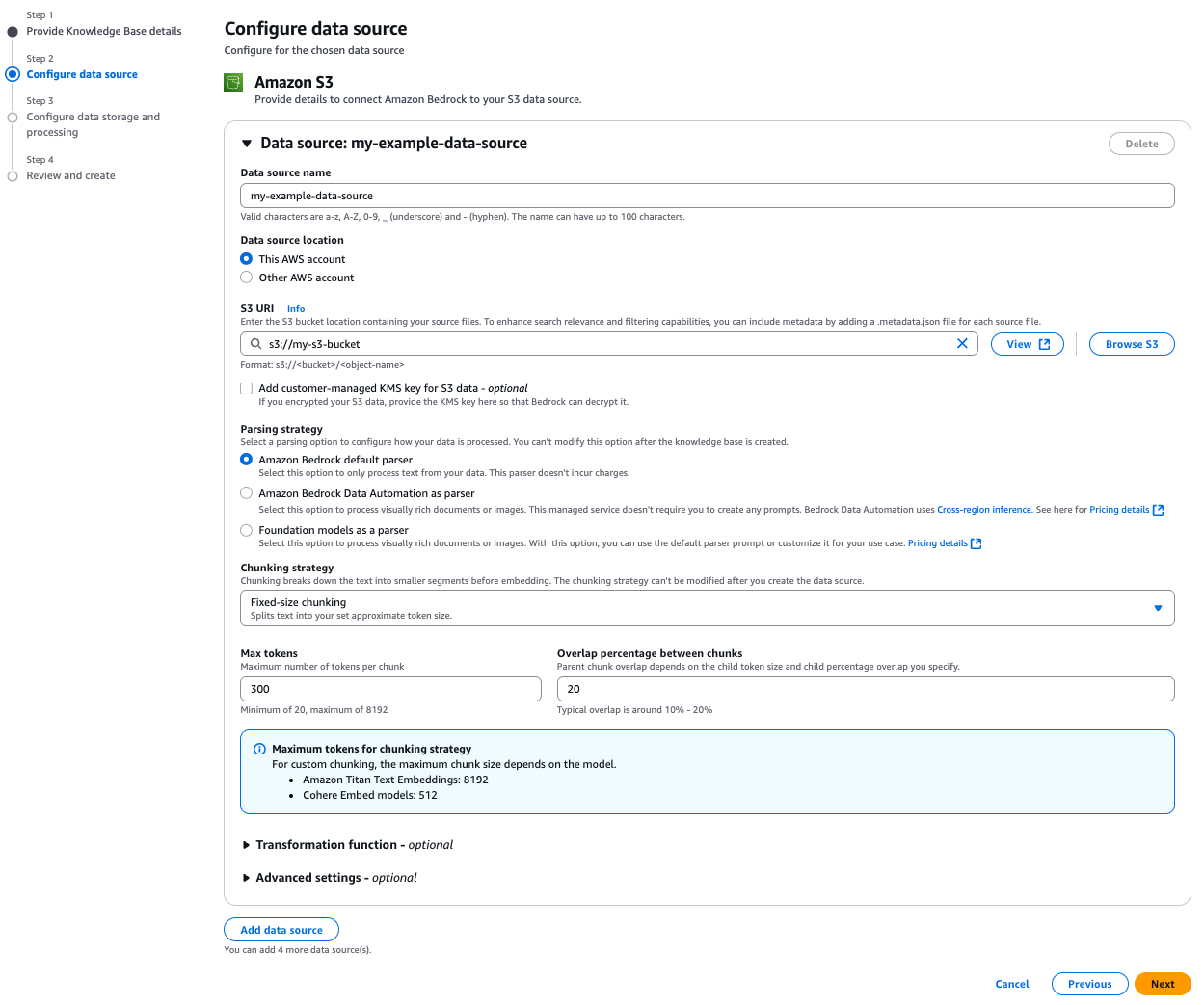
On this step, configure your parsing technique to find out how Amazon Bedrock processes your paperwork. Choose Amazon Bedrock default parser for text-only paperwork at no extra value. Choose Amazon Bedrock Knowledge Automation as parser or Basis fashions as a parser for processing complicated paperwork with visible components.
The chunking technique configuration is equally vital as a result of it defines how your content material is segmented into significant models for vector embedding, instantly impacting retrieval high quality and context preservation. We have now chosen Mounted-size chunking for this instance resulting from its predictable token sizing and ease. As a result of each parsing and chunking selections can’t be modified after creation, choose choices that finest match your content material construction and retrieval wants. For delicate information, you should use superior settings to implement AWS Key Administration Service (AWS KMS) encryption or apply customized transformation features to optimize your paperwork earlier than ingestion. By default, S3 Vectors will use server-side encryption (SSE-S3).
Configure information storage and processing
To configure information storage and processing, first choose the embeddings mannequin, as proven within the following screenshot. The embeddings mannequin will rework your textual content chunks into numerical vector representations for semantic search capabilities. If connecting to an current S3 Vector as a vector retailer, be certain the embedding mannequin dimensions match these used when creating your vector retailer as a result of dimensional mismatches will trigger ingestion failures. Amazon Bedrock gives a number of embeddings fashions to select from, every with completely different vector dimensions and efficiency traits optimized for varied use instances. Think about each the semantic richness of the mannequin and its value implications when making your choice.
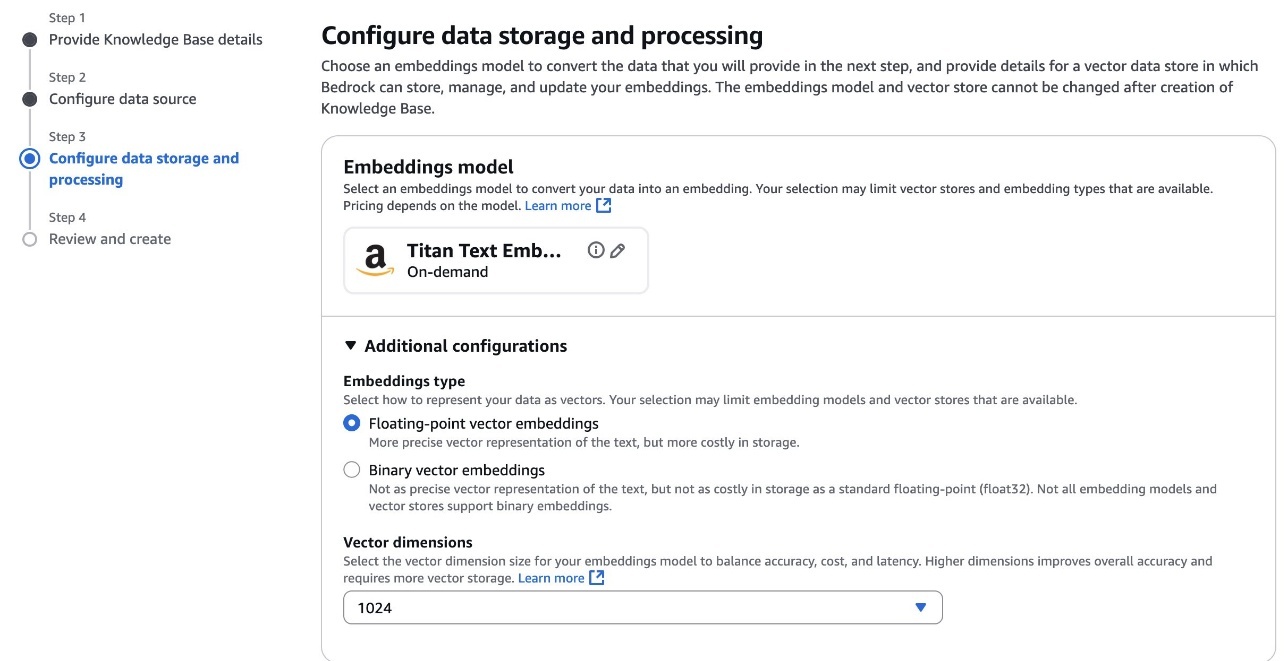
Subsequent, configure the vector retailer. For vector storage choice, select how Amazon Bedrock Data Bases will retailer and handle the vector embeddings generated out of your paperwork in Amazon S3 Vectors, utilizing one of many following two choices:
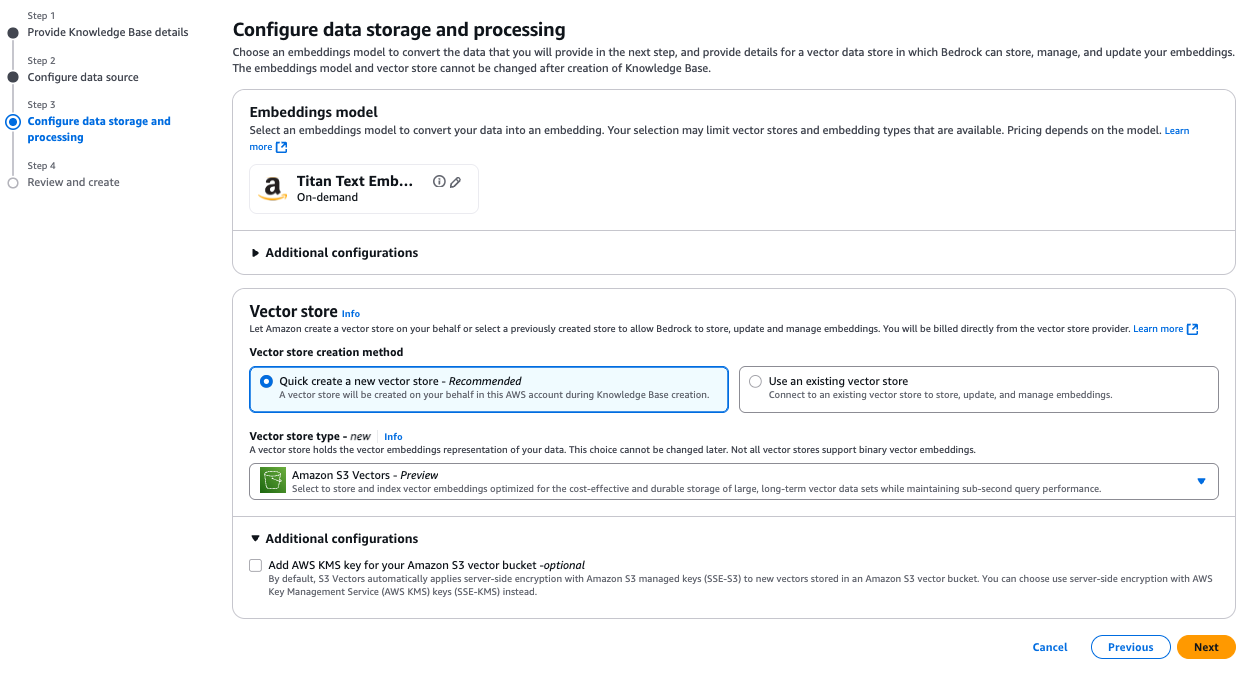
Possibility 1. Fast create a brand new vector retailer
This advisable possibility, proven within the following screenshot, mechanically creates an S3 vector bucket in your account throughout data base creation. The system optimizes your vector storage for cost-effective, sturdy storage of large-scale vector datasets, creating an S3 vector bucket and vector index for you.
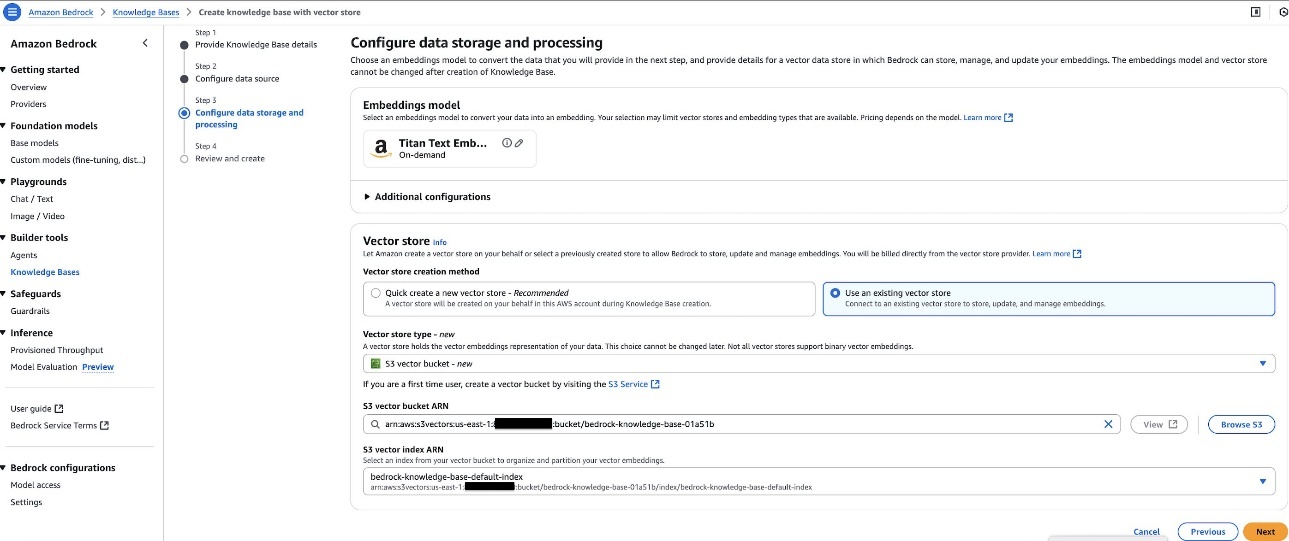
Possibility 2. Use an current vector retailer
When creating your Amazon S3 Vector as a vector retailer index to be used with Amazon Bedrock Data Bases, you possibly can connect metadata (corresponding to, 12 months, creator, style, and placement) as key-value pairs to every vector. By default, metadata fields can be utilized as filters in similarity queries until specified as nonfilterable metadata on the time of vector index creation. S3 Vector indexes assist string, quantity, and Boolean varieties as much as 40 KB per vector, with filterable metadata capped at 2 KB per vector.
To accommodate bigger textual content chunks and richer metadata whereas nonetheless permitting filtering on different vital attributes, add "AMAZON_BEDROCK_TEXT" to the nonFilterableMetadataKeys checklist in your index configuration. This method optimizes your storage allocation for doc content material whereas preserving filtering capabilities for significant attributes like classes or dates. Take into account that fields added to the nonFilterableMetadataKeys array can’t be used with metadata filtering in queries and may’t be modified after the index is created.
Right here’s an instance for creating an Amazon S3 Vector index with correct metadata configuration:
For particulars on tips on how to create a vector retailer, seek advice from Introducing Amazon S3 Vectors within the AWS Information Weblog.
After you have got an S3 Vector bucket and index, you possibly can join it to your data base. You’ll want to supply each the S3 Vector bucket Amazon Useful resource Title (ARN) and vector index ARN, as proven within the following screenshot, to accurately hyperlink your data base to your current S3 Vector index.
Sync information supply
After you’ve configured your data base with S3 Vectors, you have to synchronize your information supply to generate and retailer vector embeddings. From the Amazon Bedrock Data Bases console, open your created data base and find your configured information supply and select Sync to provoke the method, as proven within the following screenshot. Throughout synchronization, the system processes your paperwork in line with your parsing and chunking configurations, generates embeddings utilizing your chosen mannequin, and shops them in your S3 vector index. You possibly can monitor the synchronization progress in actual time when you’ve configured Amazon CloudWatch Logs and confirm completion standing earlier than testing your data base’s retrieval capabilities.

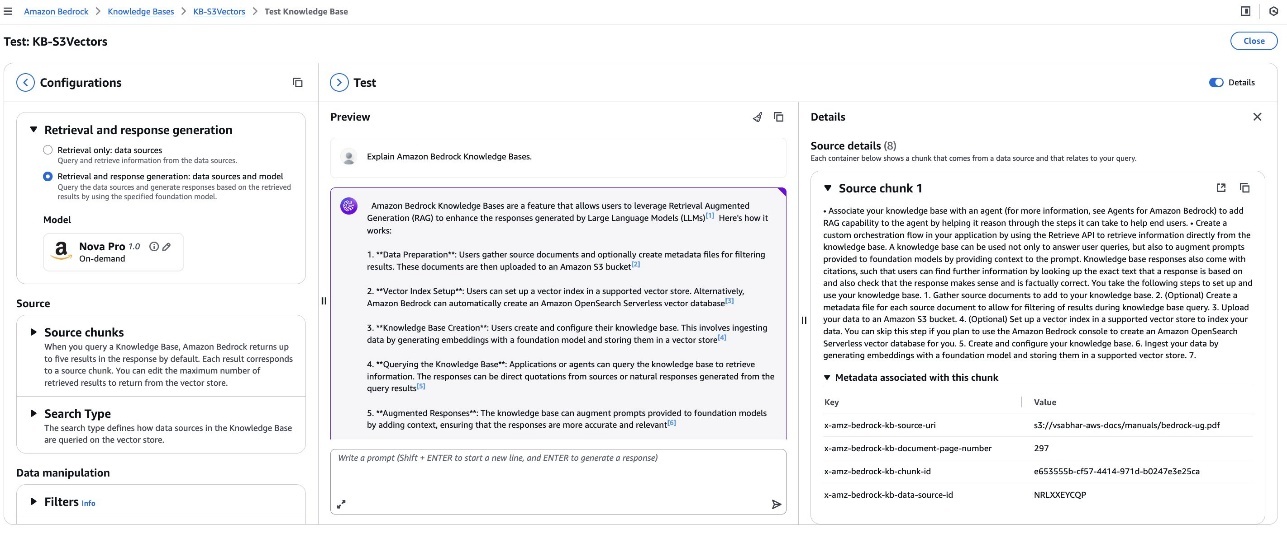
Check the data base
After efficiently configuring your data base with S3 Vectors, you possibly can validate its performance utilizing the built-in testing interface. You should utilize this interactive console to experiment with completely different question varieties and look at each retrieval outcomes and generated responses. Choose between Retrieval solely (Retrieve API) mode to look at uncooked supply chunks or Retrieval and Response technology (RetrieveandGenerate API) to find out how basis fashions (FMs) corresponding to Amazon Nova use your retrieved content material. The testing interface offers helpful insights into how your data base processes queries, displaying supply chunks, their relevance scores, and related metadata.
You may also configure question settings to your data base simply as you’d with different vector storage choices, together with filters for metadata-based choice, guardrails for acceptable responses, reranking capabilities, and question modification choices. These instruments assist optimize retrieval high quality and ensure essentially the most related data is offered to your FMs. S3 Vectors at the moment helps semantic search performance. Utilizing this hands-on validation, you possibly can refine your configuration earlier than integrating the data base with manufacturing functions.
Creating your Amazon Bedrock data base programmatically
Within the earlier sections, we walked by making a data base with Amazon S3 Vectors utilizing the AWS Administration Console. For many who desire to automate this course of or combine it into current workflows, you can even create your data base programmatically utilizing the AWS SDK.
The next is a pattern code exhibiting how the API name appears when programmatically creating an Amazon Bedrock data base with an current Amazon S3 Vector index:
The position hooked up to the data base ought to have a number of insurance policies hooked up to it, together with entry to the S3 Vectors API, the fashions used for embedding, technology, and reranking (if used), and the S3 bucket used as information supply. In case you’re utilizing a buyer managed key to your S3 Vector as a vector retailer, you’ll want to supply an extra coverage to permit the decryption of the information. The next is the coverage wanted to entry the Amazon S3 Vector as a vector retailer:
Cleanup
To wash up your sources, full the next steps. To delete the data base:
- On the Amazon Bedrock console, select Data Bases
- Choose your Data Base and be aware each the IAM service position title and S3 Vector index ARN
- Select Delete and make sure
To delete the S3 Vector as a vector retailer, use the next AWS Command Line Interface (AWS CLI) instructions:
- On the IAM console, discover the position famous earlier
- Choose and delete the position
To delete the pattern dataset:
- On the Amazon S3 console, discover your S3 bucket
- Choose and delete the information you uploaded for this tutorial
Conclusion
The mixing between Amazon Bedrock Data Bases and Amazon S3 Vectors represents a major development in making RAG functions extra accessible and economically viable at scale. By utilizing the cost-optimized storage of Amazon S3 Vectors, organizations can now construct data bases at scale with improved value effectivity. This implies prospects can strike an optimum stability between efficiency and economics, and you’ll deal with creating worth by AI-powered functions relatively than managing complicated vector storage infrastructure.
To get began on Amazon Bedrock Data Bases and Amazon S3 Vectors integration, seek advice from Utilizing S3 Vectors with Amazon Bedrock Data Bases within the Amazon S3 Person Information.
In regards to the authors
 Vaibhav Sabharwal is a Senior Options Architect with Amazon Net Providers (AWS) primarily based out of New York. He’s obsessed with studying new cloud applied sciences and aiding prospects in constructing cloud adoption methods, designing modern options, and driving operational excellence. As a member of the Monetary Providers Technical Area Group at AWS, he actively contributes to the collaborative efforts inside the {industry}.
Vaibhav Sabharwal is a Senior Options Architect with Amazon Net Providers (AWS) primarily based out of New York. He’s obsessed with studying new cloud applied sciences and aiding prospects in constructing cloud adoption methods, designing modern options, and driving operational excellence. As a member of the Monetary Providers Technical Area Group at AWS, he actively contributes to the collaborative efforts inside the {industry}.
 Dani Mitchell is a Generative AI Specialist Options Architect at Amazon Net Providers (AWS). He’s targeted on serving to speed up enterprises the world over on their generative AI journeys with Amazon Bedrock.
Dani Mitchell is a Generative AI Specialist Options Architect at Amazon Net Providers (AWS). He’s targeted on serving to speed up enterprises the world over on their generative AI journeys with Amazon Bedrock.
 Irene Marban is a Generative AI Specialist Options Architect at Amazon Net Providers (AWS), working with prospects throughout EMEA to design and implement generative AI options to speed up their companies. With a background in biomedical engineering and AI, her work focuses on serving to organizations leverage the newest AI applied sciences to drive innovation and development. In her spare time, she loves studying and cooking for her buddies.
Irene Marban is a Generative AI Specialist Options Architect at Amazon Net Providers (AWS), working with prospects throughout EMEA to design and implement generative AI options to speed up their companies. With a background in biomedical engineering and AI, her work focuses on serving to organizations leverage the newest AI applied sciences to drive innovation and development. In her spare time, she loves studying and cooking for her buddies.
 Ashish Lal is an AI/ML Senior Product Advertising Supervisor for Amazon Bedrock. He has over 11 years of expertise in product advertising and enjoys serving to prospects speed up time to worth and scale back their AI lifecycle value.
Ashish Lal is an AI/ML Senior Product Advertising Supervisor for Amazon Bedrock. He has over 11 years of expertise in product advertising and enjoys serving to prospects speed up time to worth and scale back their AI lifecycle value.



{kind=link}