
On this article, you’ll discover ways to construct AI brokers that may browse and work together with actual web sites utilizing Playwright, browser-use, and LangGraph.
Matters we are going to cowl embody:
- Why Playwright is the correct basis for browser automation in 2026, and the way it differs from Selenium.
- scrape dynamic, JavaScript-rendered pages and full multi-step varieties reliably.
- wire browser actions into LangGraph and browser-use brokers, deal with anti-bot detection, handle ready and session persistence, and deploy the end in Docker.

Constructing Browser-Utilizing AI Brokers in Python
Introduction
Most AI agent tutorials begin with an API. They present you methods to name OpenWeather, hit the Stripe endpoint, pull knowledge from GitHub. That could be a superb place to begin till you attempt to construct one thing actual and notice that the duty you really want accomplished doesn’t have an API.
Take into consideration what people do with browsers day by day: submitting authorities varieties, studying competitor pricing, extracting analysis from websites that guard their knowledge behind JavaScript rendering, logging into portals which have by no means heard of OAuth. There are roughly 1.1 billion web sites on the web. A vanishingly small fraction of them have public APIs. The remaining solely communicate browser.
An agent that’s restricted to API calls handles perhaps 5% of the duties a human employee does day by day. Give that agent a browser, and the protection approaches every little thing. That’s the hole this text closes.
The world AI brokers market stands at $10.91 billion in 2026 and is projected to achieve $50.31 billion by 2030, with browser-capable brokers on the heart of that development. 27.7% of enterprises are already operating agentic browsers in manufacturing, up from just about none two years prior. The tooling has matured quick, and the patterns are settled sufficient to show correctly.
By the top of this text, you should have a working browser agent that navigates actual web sites, fills varieties, extracts structured knowledge, and connects to an LLM that decides what to do subsequent, all in Python.
Why Playwright, Not Selenium
In the event you constructed browser automation 5 years in the past, you constructed it with Selenium. Selenium continues to be broadly deployed, nonetheless works, and isn’t going anyplace. However for any new mission in 2026, Playwright is the default. The explanations are sensible, not theoretical.
Selenium communicates with the browser by sending particular person HTTP requests to a WebDriver. Each motion, click on, sort, scroll, is a separate request. Playwright makes use of a persistent WebSocket connection for your complete session. Instructions circulation by that channel with no per-action round-trip value. Impartial benchmarks persistently present Playwright operating 30-50% quicker than Selenium on the test-suite stage and averaging ~290ms per motion versus Selenium’s ~536ms. For a browser agent which may execute a whole lot of actions, that hole compounds.
Playwright additionally bundles its personal browser binaries. Once you set up it, you get pre-configured variations of Chromium, Firefox, and WebKit which can be assured to work together with your Playwright model. No driver model mismatches, no damaged CI pipelines as a result of somebody up to date Chrome. It has built-in auto-waiting earlier than it clicks a component; it verifies the aspect is seen, enabled, and never animating. You should not have to write down time.sleep(2) and hope for one of the best.
For AI brokers particularly, Playwright fires actual mouse and keyboard occasions that mirror how people work together with browsers. Websites designed to detect automation search for artificial DOM clicks. Playwright’s interplay mannequin is more durable to differentiate from real human enter.
There may be additionally the browser-use library, which sits one stage greater. Browser-use is a Python library that offers an LLM a working browser. Underneath the hood, it makes use of Playwright to drive the browser, however the LLM reads the web page state and decides what to click on, sort, and extract, no CSS selectors required. You give it a activity in plain English, and it figures out the remainder. We are going to cowl each uncooked Playwright and browser-use on this article, as a result of they serve totally different wants: Playwright while you need exact, predictable management; browser-use while you need the agent to deal with navigation selections autonomously.
Setting Up the Surroundings
You want Python 3.10 or greater, an OpenAI API key, and about 5 minutes.
Step 1: Create a digital surroundings
|
python –m venv browser_agent_env
# macOS / Linux supply browser_agent_env/bin/activate
# Home windows browser_agent_envScriptsactivate |
Step 2: Set up dependencies
|
pip set up playwright browser–use langchain langchain–openai langgraph langchain–group python–dotenv |
Step 3: Set up the browser binaries
That is the step most individuals miss. Playwright must obtain Chromium, Firefox, and WebKit individually from the Python package deal. Run this as soon as after putting in:
|
playwright set up chromium |
In order for you all three browser engines: playwright set up. Chromium alone is adequate for many agent work and is smaller to obtain.
Step 4: Retailer your API key
Create a .env file in your mission listing:
|
OPENAI_API_KEY=your_openai_api_key_here |
Add .env to your .gitignore instantly. Don’t commit API keys.
Step 5: Confirm every little thing works
Here’s a first script that navigates to a URL, reads the heading, and saves a screenshot. Use instance.com, a publicly accessible take a look at area maintained by IANA that won’t block you.
run: Save as first_run.py and run python first_run.py
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 |
# first_run.py # Navigate to a URL, take a screenshot, and extract the web page title. # Conditions: pip set up playwright && playwright set up chromium # run: python first_run.py
import asyncio from playwright.async_api import async_playwright
async def major(): async with async_playwright() as p: # Launch Chromium in headless mode (no seen browser window). # Set headless=False if you wish to watch it run throughout growth. browser = await p.chromium.launch(headless=True)
# A browser context is sort of a recent browser profile. # It isolates cookies, storage, and cache from different contexts. context = await browser.new_context( viewport={“width”: 1280, “peak”: 720}, user_agent=( “Mozilla/5.0 (Home windows NT 10.0; Win64; x64) “ “AppleWebKit/537.36 (KHTML, like Gecko) “ “Chrome/120.0.0.0 Safari/537.36” ) )
web page = await context.new_page()
# Navigate to the URL and wait till the community is idle. # “networkidle” means no open community connections for 500ms. # For quicker pages, “domcontentloaded” is adequate. await web page.goto(“https://instance.com”, wait_until=“networkidle”)
# Extract the web page title title = await web page.title() print(f“Web page title: {title}”)
# Extract the textual content content material of the h1 heading h1 = await web page.text_content(“h1”) print(f“H1 heading: {h1}”)
# Take a full-page screenshot and reserve it to disk await web page.screenshot(path=“screenshot.png”, full_page=True) print(“Screenshot saved to screenshot.png”)
await browser.shut()
asyncio.run(major()) |
What this does: async_playwright() is the entry level for your complete Playwright session. The browser_context is equal to opening a recent incognito window; cookies, native storage, and cache are remoted from every little thing else. wait_until=”networkidle” tells Playwright to attend till the web page has completed all its community exercise earlier than your code continues, which is the most secure wait technique for dynamic pages.
If this runs and saves a screenshot, your surroundings is working accurately.
Net Navigation and Scraping
The explanation you want Playwright as an alternative of requests + BeautifulSoup is JavaScript rendering. Trendy web sites ship a skeleton of HTML after which construct the precise content material dynamically after the web page hundreds: React, Vue, Angular, Subsequent.js. A plain HTTP request fetches the skeleton. Playwright runs an actual browser, so it sees precisely what a human sees in any case JavaScript has executed.
The goal beneath is books.toscrape.com, a authorized scraping sandbox constructed for follow. It paginates outcomes, makes use of dynamic class names for rankings, and carefully mirrors the construction of actual e-commerce product pages.
run: Save as scrape_books.py and run python scrape_books.py
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 |
# scrape_books.py # Scrape e-book titles, costs, and rankings from books.toscrape.com # It is a authorized scraping sandbox web site constructed for follow. # Conditions: pip set up playwright && playwright set up chromium # run: python scrape_books.py
import asyncio import json from playwright.async_api import async_playwright
async def scrape_books(max_pages: int = 3) -> record[dict]: “”“ Scrape e-book listings from books.toscrape.com throughout a number of pages. Returns a listing of dicts with title, worth, ranking, and web page quantity. ““” outcomes = []
async with async_playwright() as p: browser = await p.chromium.launch(headless=True) context = await browser.new_context(viewport={“width”: 1280, “peak”: 720}) web page = await context.new_page()
for page_num in vary(1, max_pages + 1): url = f“https://books.toscrape.com/catalogue/page-{page_num}.html” print(f“Scraping web page {page_num}: {url}”)
await web page.goto(url, wait_until=“domcontentloaded”)
# Await the product playing cards to be seen earlier than extracting. # That is essential on JavaScript-heavy pages the place content material hundreds after the HTML. # timeout=10000 means wait as much as 10 seconds earlier than elevating an error. await web page.wait_for_selector(“article.product_pod”, timeout=10000)
# Get all e-book playing cards on the present web page books = await web page.query_selector_all(“article.product_pod”)
for e-book in books: title_el = await e-book.query_selector(“h3 a”) title = await title_el.get_attribute(“title”) if title_el else “N/A”
# Extract worth textual content price_el = await e-book.query_selector(“.price_color”) worth = await price_el.inner_text() if price_el else “N/A”
# Extract star ranking from the CSS class title. # e.g.
rating_el = await e-book.query_selector(“p.star-rating”) rating_class = await rating_el.get_attribute(“class”) if rating_el else “” ranking = rating_class.exchange(“star-rating”, “”).strip()
outcomes.append({ “title”: title, “worth”: worth, “ranking”: ranking, “web page”: web page_num })
print(f” Extracted {len(books)} books from web page {page_num}”)
await browser.shut()
return outcomes
async def major(): books = await scrape_books(max_pages=2) print(f“nTotal books scraped: {len(books)}”) print(json.dumps(books[:3], indent=2))
asyncio.run(major()) |
What this does: wait_for_selector() is the important thing name right here. As a substitute of sleeping for a hard and fast time and hoping the content material has loaded, it watches the DOM and proceeds the second the goal aspect seems, or raises a TimeoutError if it doesn’t seem throughout the timeout window. That’s the proper conduct: fail quick and explicitly quite than silently extracting from an empty web page.
The ranking extraction deserves consideration. The star ranking is encoded as a CSS class (star-rating Three), not a quantity. The code strips “star-rating” from the category string to get the textual content worth. That is the type of factor you solely know by inspecting the precise HTML. Once you hand this activity to a uncooked LLM with no browser, it has no strategy to know what the category construction seems like. With Playwright, you may examine it straight and extract it precisely.
Kind Completion and Multi-Step Flows
Filling varieties is the place browser brokers earn their maintain and the place most automation scripts fail. The reason being that internet varieties are usually not simply inputs and buttons. They fireplace focus, enter, change, and blur occasions in sequence. JavaScript validation listens for these occasions. In the event you inject a price into an enter area by straight setting worth within the DOM (as older automation instruments usually do), the validation listeners by no means fireplace and the shape breaks.
Playwright’s fill() and click on() strategies fireplace actual browser occasions in the correct order, which is why they work on type validation that may block lower-level approaches.
The goal beneath is the-internet.herokuapp.com/login, a public take a look at web site maintained particularly for automation follow. It accepts tomsmith / SuperSecretPassword! as legitimate credentials and returns clear success/failure messages.
run: Save as form_submit.py and run python form_submit.py
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 |
# form_submit.py # Full and submit a multi-field login type on a public demo web site. # Goal: https://the-internet.herokuapp.com/login (public take a look at web site) # Conditions: pip set up playwright && playwright set up chromium # run: python form_submit.py
import asyncio from playwright.async_api import async_playwright
async def login_and_verify(username: str, password: str) -> dict: “”“ Try and log in to a demo web site and return whether or not it succeeded. Handles: enter filling, button clicking, and consequence verification. ““” async with async_playwright() as p: browser = await p.chromium.launch(headless=True) context = await browser.new_context() web page = await context.new_page()
await web page.goto(“https://the-internet.herokuapp.com/login”)
# Await the shape to be seen earlier than interacting. # state=”seen” is the default however makes the intent specific. await web page.wait_for_selector(“#username”, state=“seen”)
# fill() clears the sphere first, then sorts the worth. # It fires the main focus, enter, and alter occasions so as. await web page.fill(“#username”, username) await web page.fill(“#password”, password)
# click on() fires actual mouse occasions — mousedown, mouseup, click on. # This triggers JavaScript listeners {that a} plain DOM click on misses. await web page.click on(“button[type=”submit”]”)
# Await the web page to settle after type submission await web page.wait_for_load_state(“networkidle”)
# Verify which consequence aspect appeared success_el = await web page.query_selector(“.flash.success”) error_el = await web page.query_selector(“.flash.error”)
if success_el: message = await success_el.inner_text() consequence = {“success”: True, “message”: message.strip()} elif error_el: message = await error_el.inner_text() consequence = {“success”: False, “message”: message.strip()} else: consequence = {“success”: False, “message”: “Unknown consequence”}
await browser.shut() return consequence
async def major(): # Legitimate credentials for the demo web site consequence = await login_and_verify(“tomsmith”, “SuperSecretPassword!”) print(f“Legitimate login: {consequence}”)
# Invalid credentials to confirm error dealing with result_fail = await login_and_verify(“wronguser”, “wrongpass”) print(f“Invalid login: {result_fail}”)
asyncio.run(major()) |
What this does: The sample right here, fill() → click on() → wait_for_load_state() → examine for consequence aspect, is the template for nearly any type interplay. The wait_for_load_state(“networkidle”) after the submit is essential: with out it, you question the DOM earlier than the web page has up to date and get the pre-submission state, not the consequence.
For extra advanced varieties with file uploads, dropdowns, and checkboxes:
|
# File add await web page.set_input_files(“#file-upload”, “/path/to/doc.pdf”)
# Choose dropdown by seen label textual content await web page.select_option(“#country-select”, label=“Nigeria”)
# Verify a checkbox await web page.examine(“#agree-terms”)
# Deal with a modal dialog (verify/alert) web page.on(“dialog”, lambda dialog: asyncio.ensure_future(dialog.settle for())) |
Instrument Orchestration with LangChain and LangGraph
Uncooked Playwright scripts are highly effective however fastened. They do precisely what you coded, no extra. The second a web page modifications its construction, or the duty requires a call the script didn’t anticipate, it breaks.
Connecting Playwright to an LLM modifications this. Browser actions turn into instruments the agent can name when it decides they’re wanted. The agent reads the duty, causes about what to do, calls a software, reads the consequence, and decides what to do subsequent. That loop handles variation {that a} fastened script can not.
That is the bridge from “browser automation script” to “AI agent.”
run: Save as agent_tools.py, guarantee OPENAI_API_KEY is in your .env, then run python agent_tools.py
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 |
# agent_tools.py # LangGraph agent with three browser instruments: navigate_and_extract, fill_and_submit_form, take_screenshot # Conditions: pip set up playwright langchain langchain-openai langgraph python-dotenv # playwright set up chromium # run: python agent_tools.py
import asyncio import os from dotenv import load_dotenv from langchain_openai import ChatOpenAI from langchain.instruments import software from langchain_core.messages import HumanMessage from langgraph.prebuilt import create_react_agent from playwright.async_api import async_playwright
load_dotenv()
# ── SHARED BROWSER STATE ────────────────────────────────────────────────────── # We maintain a single browser occasion alive for the agent’s lifetime. # Creating and destroying a browser on each software name is gradual and wasteful. _browser = None _page = None _playwright = None
async def get_page(): “”“Return the shared web page, launching the browser if wanted.”“” world _browser, _page, _playwright if _browser is None: _playwright = await async_playwright().begin() _browser = await _playwright.chromium.launch(headless=True) context = await _browser.new_context(viewport={“width”: 1280, “peak”: 720}) _page = await context.new_page() return _page
async def close_browser(): “”“Clear up browser assets when the agent session ends.”“” world _browser, _page, _playwright if _browser: await _browser.shut() await _playwright.cease() _browser = None _page = None _playwright = None
# ── BROWSER TOOLS ───────────────────────────────────────────────────────────── # Observe: these are async instruments (async def). LangChain’s @software decorator helps # async capabilities straight, and the agent have to be invoked with ainvoke() in order that # software calls run on the identical occasion loop as an alternative of attempting to begin a second one.
@software async def navigate_and_extract(url: str) -> str: “”“ Navigate to a URL and return the seen textual content content material of the web page. Use this to go to web sites and browse their content material. Enter: a full URL string together with https:// (e.g., ‘https://instance.com’). ““” web page = await get_page() await web page.goto(url, wait_until=“domcontentloaded”, timeout=15000) await web page.wait_for_load_state(“networkidle”) content material = await web page.inner_text(“physique”) # Truncate to keep away from flooding the LLM context window return content material[:3000] if len(content material) > 3000 else content material
@software async def fill_and_submit_form(selector_value_pairs: str) -> str: “”“ Fill type fields and submit a type on the presently loaded web page. Enter: a comma-separated string of ‘selector:worth’ pairs ending with ‘submit:button_selector’. Instance: ‘#electronic mail:consumer@instance.com,#password:secret,submit:button[type=submit]’ ““” web page = await get_page() strive: pairs = selector_value_pairs.cut up(“,”) submit_selector = None
for pair in pairs: key, val = pair.cut up(“:”, 1) key = key.strip() val = val.strip() if key == “submit”: submit_selector = val else: await web page.fill(key, val)
if submit_selector: await web page.click on(submit_selector) await web page.wait_for_load_state(“networkidle”)
return f“Kind submitted. Present URL: {web page.url}” besides Exception as e: return f“Kind interplay failed: {str(e)}”
@software async def take_screenshot(filename: str) -> str: “”“ Take a screenshot of the present browser web page and reserve it to a file. Use this to visually confirm the present state of the web page. Enter: filename string (e.g., ‘consequence.png’). ““” web page = await get_page() await web page.screenshot(path=filename, full_page=False) return f“Screenshot saved to {filename}”
# ── AGENT SETUP ───────────────────────────────────────────────────────────────
llm = ChatOpenAI( mannequin=“gpt-4o”, temperature=0, api_key=os.getenv(“OPENAI_API_KEY”) )
instruments = [navigate_and_extract, fill_and_submit_form, take_screenshot]
# create_react_agent wires collectively the LLM, the instruments, and the ReAct reasoning loop. # The agent decides which software to name, calls it, reads the consequence, and continues. agent = create_react_agent(llm, instruments)
# ── DEMO ──────────────────────────────────────────────────────────────────────
async def major(): consequence = await agent.ainvoke({ “messages”: [HumanMessage( content=( “Go to https://example.com, read the page content, “ “then take a screenshot called example.png” ) )] }) print(consequence[“messages”][–1].content material) await close_browser()
asyncio.run(major()) |
What this does: The three @software-decorated capabilities are registered with the agent. Every docstring is what the LLM reads to grasp what the software does and when to make use of it. Write them like job descriptions, not code feedback. The shared _browser and _page globals imply the browser stays open throughout a number of software calls, which is crucial for duties that span a number of pages in the identical session. As a result of the instruments are outlined with async def, the agent is invoked with ainvoke() quite than invoke(), so the software calls run on the identical occasion loop that major() is already utilizing.
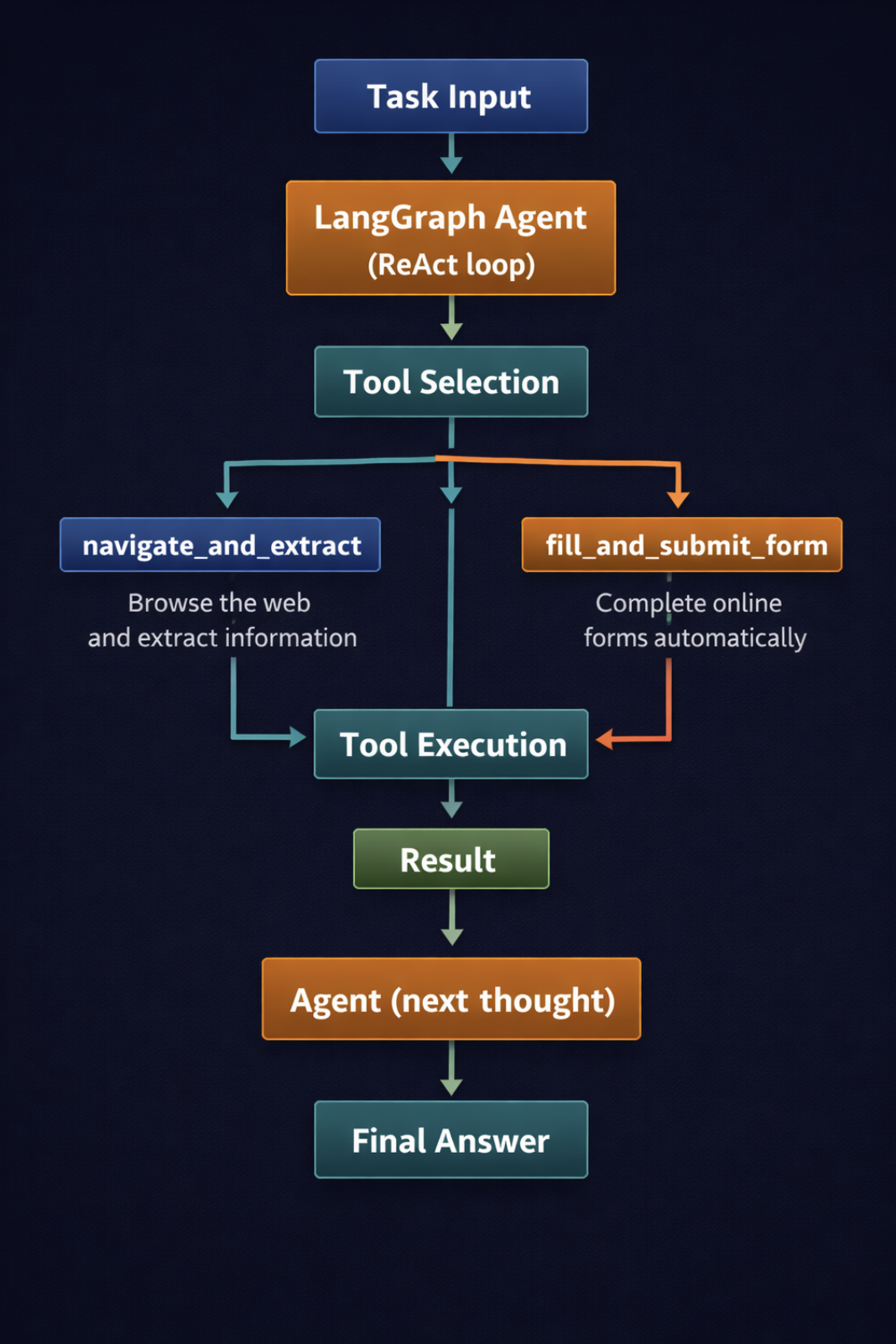
A vertical circulation diagram exhibiting how a activity request flows by the agent (click on to enlarge)
Picture by Editor
The important thing design resolution on this snippet is the shared browser occasion. If every software name launched and closed its personal browser, you’ll lose all session state between calls, comparable to cookies, navigation historical past, and any type state the agent had already constructed up. Holding the browser alive for the total agent session preserves that context.
Utilizing browser-use for Excessive-Degree Agent Duties
Uncooked Playwright with @software capabilities offers you exact management. The trade-off is that you’re nonetheless writing selectors, nonetheless serious about web page construction, nonetheless dealing with each edge case manually. If the positioning modifications its HTML, your selectors break.
browser-use takes a unique method. As a substitute of writing selectors, you give the agent a activity in plain English. browser-use makes use of Playwright beneath the hood, however the LLM reads the present web page state on every step and decides what to do subsequent: which aspect to click on, what to sort, and when the duty is full. The web page construction shouldn’t be hardcoded into your code. The agent figures it out at runtime.
browser-use is a Python library that offers an LLM a working browser. The LLM reads every web page and decides what to click on, sort, and extract. This makes it resilient to web site modifications that may break a selector-based script.
When to make use of browser-use over uncooked Playwright:
- If the duty is exploratory and the web page construction is unpredictable, use browser-use.
- In case you are operating a hard and fast, repeatable workflow the place each selector is understood and secure, uncooked Playwright is extra dependable and cheaper per run.
- A browser-use agent makes a number of LLM calls per activity step; a scripted Playwright run makes none.
run: Save as browser_use_agent.py, guarantee OPENAI_API_KEY is in your .env, then run python browser_use_agent.py
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 |
# browser_use_agent.py # A browser-use agent that accepts a pure language activity and completes it # with none CSS selectors or hardcoded web page construction. # Conditions: pip set up browser-use playwright python-dotenv # playwright set up chromium # run: python browser_use_agent.py
import asyncio import os from dotenv import load_dotenv from langchain_openai import ChatOpenAI from browser_use import Agent
load_dotenv()
async def run_browser_task(activity: str) -> str: “”“ Hand a pure language activity to a browser-use agent. The agent handles navigation, clicks, and extraction with out selectors. ““” # temperature=0 retains selections deterministic and reduces hallucinated actions llm = ChatOpenAI( mannequin=“gpt-4o”, temperature=0, api_key=os.getenv(“OPENAI_API_KEY”) )
# Agent wraps the browser, the LLM, and the duty loop collectively. # max_actions_per_step limits what number of actions the agent takes earlier than # re-reading the web page — prevents runaway loops on advanced pages. agent = Agent( activity=activity, llm=llm, max_actions_per_step=5 )
# run() executes the total activity loop: # learn web page → determine motion → take motion → learn up to date web page → repeat consequence = await agent.run()
# final_result() returns the agent’s extracted content material or conclusion return consequence.final_result() or “Activity accomplished with no extracted output.”
async def major(): activity = ( “Go to https://books.toscrape.com and discover the three costliest books “ “on the primary web page. Return their titles and costs.” ) print(f“Activity: {activity}n”) output = await run_browser_task(activity) print(f“Outcome:n{output}”)
asyncio.run(major()) |
What this does: Your complete activity, navigating to the positioning, studying the web page, figuring out the three highest costs, and extracting them, is dealt with by the agent with no single CSS selector in your code. If books.toscrape.com redesigns its worth show tomorrow, the script nonetheless works. With a selector-based scraper, it will break silently.
The max_actions_per_step=5 parameter is price explaining. On every step, the agent reads the web page and may determine to take as much as 5 actions (click on, sort, scroll, navigate) earlier than re-reading the web page. Holding this low forces the agent to examine its work extra ceaselessly, which catches errors earlier.
Dealing with the Exhausting Elements
Three issues break most browser brokers in manufacturing. Every has an answer, however none of them is clear till you’ve gotten already been burned.
1. Anti-Bot Detection
Web sites that don’t need to be automated detect automation in a number of methods, comparable to checking the navigator.webdriver property (which Playwright units to true by default), in search of headless browser fingerprints within the JavaScript surroundings, and analyzing interplay patterns which can be too quick or too uniform to be human.
An important mitigation is eradicating the webdriver flag. Past that, a sensible consumer agent string, an ordinary viewport measurement, and a sensible locale and timezone cowl most detection strategies wanting refined fingerprint evaluation.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 |
# hard_parts.py — Half 1: Anti-bot stealth launch # Conditions: pip set up playwright && playwright set up chromium # run: python hard_parts.py
import asyncio import json from pathlib import Path from playwright.async_api import async_playwright
async def launch_stealth_browser(playwright): “”“ Launch a browser context that appears extra like an actual human session. Covers: practical viewport, user-agent, locale, timezone, webdriver flag. Observe: For severe anti-bot targets, contemplate a paid service like Browserbase. ““” browser = await playwright.chromium.launch( headless=True, args=[ “–disable-blink-features=AutomationControlled”, # Hides webdriver detection “–no-sandbox”, “–disable-dev-shm-usage”, ] )
context = await browser.new_context( viewport={“width”: 1366, “peak”: 768}, # Widespread desktop decision user_agent=( “Mozilla/5.0 (Home windows NT 10.0; Win64; x64) “ “AppleWebKit/537.36 (KHTML, like Gecko) “ “Chrome/124.0.0.0 Safari/537.36” ), locale=“en-US”, timezone_id=“America/New_York”, java_script_enabled=True, )
# Take away the ‘webdriver’ property that Playwright injects by default. # Bot detection programs examine for this within the browser’s JS surroundings. await context.add_init_script( “Object.defineProperty(navigator, ‘webdriver’, {get: () => undefined})” )
return browser, context |
What this does: The add_init_script() name runs earlier than any web page JavaScript executes, which implies the navigator.webdriver override is in place earlier than the positioning’s detection code can examine for it. The –disable-blink-features=AutomationControlled launch argument removes a separate automation flag on the browser engine stage. Collectively, these two modifications deal with the most typical detection strategies.
For websites with aggressive fingerprinting and CAPTCHA programs, these mitigations won’t be sufficient. Companies like Browserbase, Spidra and Brightdata’s Scraping Browser deal with CAPTCHA fixing, residential IP rotation, and browser fingerprint administration as managed infrastructure.
2. Good Ready
The second failure mode is timing. The reflex is so as to add time.sleep() calls and improve them when issues break. That is mistaken in each instructions: too quick on gradual connections, too lengthy on quick ones, and utterly opaque when debugging.
Playwright has 4 correct wait methods. Use the one which matches what you’re really ready for:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 |
# Half 2: Good ready methods (add to your scraper or agent instruments)
async def smart_wait_examples(web page): “”“ 4 methods to attend for the correct web page state, with out arbitrary sleeps. ““” # STRATEGY 1: Await a selected aspect to look within the DOM # Use when you understand precisely what aspect alerts content material has loaded await web page.wait_for_selector(“.product-list”, state=“seen”, timeout=10000)
# STRATEGY 2: Await a selected API response # Use when the content material comes from an XHR/fetch name you may determine async with web page.expect_response( lambda r: “/api/merchandise” in r.url and r.standing == 200 ) as response_info: await web page.click on(“#load-more”) response = await response_info.worth print(f“API responded: {response.standing}”)
# STRATEGY 3: Await the URL to alter after type submission # Use when a profitable submit redirects to a brand new web page await web page.wait_for_url(“**/dashboard**”, timeout=10000)
# STRATEGY 4: Await a JavaScript variable to be set # Use when no visible aspect reliably alerts the prepared state await web page.wait_for_function( “() => window.__dataLoaded === true”, timeout=10000 ) |
What this does: Every technique is tied to a selected observable occasion quite than an arbitrary time delay. wait_for_selector watches the DOM. expect_response hooks into the community layer. wait_for_url screens navigation. wait_for_function evaluates JavaScript within the browser context. Use whichever one most straight alerts “the factor I want is now prepared.”
3. Session and Cookie Persistence
The third failure mode is dropping session state. In case your agent logs right into a web site throughout the 1st step after which the browser context is destroyed, step two has no authentication. Recreating the login on each run is gradual and may set off price limiting or lockout.
The answer is saving cookies to disk after login and loading them in the beginning of each subsequent run:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 |
# Half 3: Session persistence throughout runs
COOKIES_FILE = Path(“session_cookies.json”)
async def save_session(context) -> None: “”“Save browser cookies to disk after a profitable login.”“” cookies = await context.cookies() COOKIES_FILE.write_text(json.dumps(cookies, indent=2)) print(f“Session saved: {len(cookies)} cookies written.”)
async def load_session(context) -> bool: “”“Load saved cookies earlier than navigating. Returns True if session was discovered.”“” if not COOKIES_FILE.exists(): print(“No saved session. Contemporary login required.”) return False cookies = json.hundreds(COOKIES_FILE.read_text()) await context.add_cookies(cookies) print(f“Session restored: {len(cookies)} cookies loaded.”) return True |
What this does: context.cookies() returns all cookies for the present browser context, together with session tokens and authentication cookies. Writing them to JSON and reloading them on the subsequent run means the browser begins in an authenticated state. Observe that classes expire; add a examine that falls again to a recent login if the saved session returns a redirect to the login web page.
Deploying Browser Brokers
Getting a browser agent working regionally is one factor. Working it reliably in a cloud surroundings is one other.
The principle distinction between a Python script that works in your laptop computer and one which fails in CI is system dependencies. Playwright’s Chromium browser requires a set of shared libraries which can be current on most developer machines however absent from minimal cloud pictures. The cleanest resolution is Docker.
Dockerfile — construct a container that ships every little thing Playwright wants:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 |
# Dockerfile for headless Playwright-based browser agent # Construct: docker construct -t browser-agent . # Run: docker run –rm -e OPENAI_API_KEY=your_key browser-agent
FROM python:3.11–slim
# Set up system dependencies required by Chromium RUN apt–get replace && apt–get set up –y libnss3 libatk1.0–0 libatk–bridge2.0–0 libcups2 libdrm2 libxkbcommon0 libxcomposite1 libxdamage1 libxrandr2 libgbm1 libasound2 libpangocairo–1.0–0 libpango–1.0–0 libcairo2 libx11–6 libxext6 libxfixes3 fonts–liberation wget ca–certificates && rm –rf /var/lib/apt/lists/*
WORKDIR /app
# Set up Python dependencies first (cached layer — solely rebuilds on necessities change) COPY necessities.txt . RUN pip set up —no–cache–dir –r necessities.txt
# Set up Playwright browser binaries into the picture RUN playwright set up chromium RUN playwright set up–deps chromium
# Copy utility code final (modifications right here do not invalidate the pip/playwright layers) COPY . .
CMD [“python”, “agent_tools.py”]
necessities.txt: playwright browser–use langchain langchain–openai langgraph python–dotenv |
For concurrent workloads operating a number of browser classes in parallel, use Playwright’s async API with asyncio.collect():
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 |
# Parallel scraping with semaphore price limiting # Runs as much as 3 browser classes concurrently
import asyncio from playwright.async_api import async_playwright
async def scrape_url(browser, url: str, semaphore: asyncio.Semaphore) -> dict: “”“Scrape a single URL, respecting the concurrency semaphore.”“” async with semaphore: context = await browser.new_context() web page = await context.new_page() await web page.goto(url, wait_until=“domcontentloaded”) title = await web page.title() await context.shut() # Shut context (not browser) to launch assets return {“url”: url, “title”: title}
async def scrape_parallel(urls: record[str], max_concurrent: int = 3) -> record[dict]: “”“Scrape a listing of URLs in parallel, capped at max_concurrent classes.”“” semaphore = asyncio.Semaphore(max_concurrent) # Cap concurrent classes
async with async_playwright() as p: # One browser shared throughout all contexts — less expensive than one browser per URL browser = await p.chromium.launch(headless=True) duties = [scrape_url(browser, url, semaphore) for url in urls] outcomes = await asyncio.collect(*duties) await browser.shut()
return record(outcomes) |
What this does: The asyncio.Semaphore(max_concurrent) caps what number of browser contexts run on the identical time. With out it, launching 50 concurrent browser contexts will exhaust reminiscence. One browser course of is shared throughout all contexts; a context is reasonable; a full browser occasion shouldn’t be.
On the managed infrastructure aspect, Amazon Nova Act launched in March 2025 as a devoted SDK for constructing browser brokers on AWS, integrating natively with Playwright for browser management. Playwright’s personal MCP server offers AI assistants full browser management by the Mannequin Context Protocol, utilizing structured accessibility snapshots quite than screenshots, which implies token prices keep low whereas the agent’s understanding of the web page stays excessive.
Placing It All Collectively
Here’s a full end-to-end agent that takes a analysis query, navigates to a public knowledge supply, extracts structured outcomes, and returns a clear abstract. It makes use of the browser instruments from Part 5 orchestrated by a LangGraph agent.
run: Save as reference_agent.py, guarantee OPENAI_API_KEY is in your .env, and run python reference_agent.py
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 |
# reference_agent.py # Full browser-using AI agent: navigates, extracts, summarizes. # Goal: books.toscrape.com (public scraping sandbox) # Conditions: pip set up playwright langchain langchain-openai langgraph python-dotenv # playwright set up chromium # run: python reference_agent.py
import asyncio import os from dotenv import load_dotenv from langchain_openai import ChatOpenAI from langchain.instruments import software from langchain_core.messages import HumanMessage, SystemMessage from langgraph.prebuilt import create_react_agent from playwright.async_api import async_playwright
load_dotenv()
# ── BROWSER STATE ───────────────────────────────────────────────────────────── _browser = None _context = None _page = None _playwright = None
async def get_page(): world _browser, _context, _page, _playwright if _browser is None: _playwright = await async_playwright().begin() _browser = await _playwright.chromium.launch(headless=True) _context = await _browser.new_context( viewport={“width”: 1280, “peak”: 720}, user_agent=( “Mozilla/5.0 (Home windows NT 10.0; Win64; x64) “ “AppleWebKit/537.36 (KHTML, like Gecko) “ “Chrome/120.0.0.0 Safari/537.36” ) ) # Take away webdriver fingerprint await _context.add_init_script( “Object.defineProperty(navigator, ‘webdriver’, {get: () => undefined})” ) _page = await _context.new_page() return _page
async def teardown(): world _browser, _playwright if _browser: await _browser.shut() await _playwright.cease() _browser = None _playwright = None
# ── TOOLS ─────────────────────────────────────────────────────────────────────
@software async def navigate(url: str) -> str: “”“ Navigate the browser to a URL and return the web page’s textual content content material. Use when it’s essential to open an internet site or transfer to a brand new web page. Enter: full URL with https:// prefix. ““” web page = await get_page() await web page.goto(url, wait_until=“domcontentloaded”, timeout=20000) await web page.wait_for_load_state(“networkidle”) content material = await web page.inner_text(“physique”) return content material[:4000]
@software async def extract_structured(css_selector: str) -> str: “”“ Extract textual content from all parts matching a CSS selector on the present web page. Use when it’s essential to pull particular parts from the loaded web page. Enter: legitimate CSS selector string (e.g., ‘h3 a’, ‘.price_color’, ‘article.product_pod’). ““” web page = await get_page() strive: await web page.wait_for_selector(css_selector, timeout=5000) parts = await web page.query_selector_all(css_selector) texts = [] for el in parts[:20]: # Cap at 20 parts to maintain output manageable textual content = await el.inner_text() texts.append(textual content.strip()) return “n”.be part of(texts) if texts else “No parts discovered.” besides Exception as e: return f“Extraction failed: {str(e)}”
@software async def get_current_url() -> str: “”“Return the URL the browser is presently on. No enter required.”“” web page = await get_page() return web page.url
# ── AGENT ─────────────────────────────────────────────────────────────────────
llm = ChatOpenAI( mannequin=“gpt-4o”, temperature=0, api_key=os.getenv(“OPENAI_API_KEY”) )
instruments = [navigate, extract_structured, get_current_url] agent = create_react_agent(llm, instruments)
SYSTEM = ( “You’re a browser-based analysis agent. You could have entry to an actual browser. “ “Use navigate() to open pages, extract_structured() to tug particular parts, “ “and get_current_url() to examine the place you’re. “ “All the time navigate first, then extract. Be concise in your closing reply.” )
async def run_agent(question: str) -> str: consequence = await agent.ainvoke({ “messages”: [ SystemMessage(content=SYSTEM), HumanMessage(content=query) ] }) await teardown() return consequence[“messages”][–1].content material
# ── DEMO ──────────────────────────────────────────────────────────────────────
if __name__ == “__main__”: question = ( “Go to https://books.toscrape.com and extract the titles and costs “ “of the primary 5 books listed. Return them as a structured record.” ) print(f“Question: {question}n”) reply = asyncio.run(run_agent(question)) print(f“Reply:n{reply}”) |
What this does: This agent has three clear instruments: navigate, extract_structured, and get_current_url, plus a system immediate that tells it precisely when to make use of each. The agent calls navigate to load the web page, extract_structured to tug the e-book titles and costs by CSS selector, and synthesizes a structured record within the closing reply. The teardown() name after the agent finishes closes the browser cleanly so no zombie Chromium processes are left operating.
Conclusion
The browser shouldn’t be a specialised software for automation engineers. It’s the common interface for the online, and the online is the place a lot of the world’s precise work will get accomplished. An AI agent that may use a browser doesn’t want a companion staff sustaining API integrations. It might probably attain something a human can attain.
What makes this sensible now, not simply theoretically attention-grabbing, is the maturity of the tooling. Playwright handles the onerous components of browser interplay. browser-use removes the necessity to write selectors for exploratory duties. LangGraph offers the LLM clear software hooks and a reasoning loop that handles variable web page constructions. The patterns on this article are usually not demos. They’re the identical patterns 51% of enterprises now operating AI brokers in manufacturing are constructing on.
Begin with the scraping instance. Get it operating towards a web site you really want knowledge from. Add the agent layer while you want selections the script can not anticipate. Add browser-use when the web page construction is simply too dynamic for selectors. Deploy in Docker while you want it operating someplace apart from your laptop computer.
The onerous half shouldn’t be the code. It’s figuring out which software to achieve for at every layer. Hopefully this text made that clearer.


{kind=link}