
With Amazon Bedrock Data Bases, you can provide basis fashions (FMs) and brokers contextual info out of your group’s personal information sources to ship extra related, correct, and customised responses. As the info grows, sustaining real-time synchronization between Amazon Easy Storage Service (Amazon S3) and your information bases turns into important for correct, up-to-date responses.On this publish, we discover how Deloitte used Amazon EKS and vCluster to remodel their testing infrastructure.
On this publish, we discover an automatic resolution that detects S3 occasions and triggers ingestion jobs whereas respecting service quotas and offering complete monitoring. This serverless resolution makes use of an event-driven structure to maintain your information base present with out overwhelming the Amazon Bedrock APIs.
The problem
Data bases in Amazon Bedrock require guide synchronization every time paperwork are added, modified, or deleted in S3 (together with metadata information). Organizations want automated synchronization for frequent content material updates, multiuser environments the place groups add paperwork all through the day, real-time functions reminiscent of buyer assist methods that require rapid entry to present info, and to enhance operational effectivity by eradicating guide sync processes which can be susceptible to delays or being forgotten. To realize dependable automation, organizations should fastidiously orchestrate sync operations whereas respecting the Amazon service quotas and fee limits.
Service design issues
When implementing automated synchronization, prospects should account for the protecting constraints of Amazon Bedrock. Amazon Bedrock service quotas restrict concurrent ingestion jobs to:
- 5 jobs per AWS account (helps forestall useful resource exhaustion)
- One job per information base (facilitates centered processing)
- One job per information supply (maintains information consistency)
For extra details about Amazon Bedrock service quotas, confer with Amazon Bedrock service quotas within the Amazon Bedrock Reference information. These limits are particular to every AWS Area and would possibly change sooner or later, so seek the advice of the documentation for probably the most present quota info.
The StartIngestionJob API for information bases has a fee restrict of 0.1 requests per second (one request each 10 seconds) in every supported Area.
Think about having a content material crew updating a number of information throughout a launch. With out coordination, sync requests queue up attributable to service limits, requiring guide oversight. An orchestrated strategy handles this seamlessly, ensuring the modifications are processed effectively whereas respecting service constraints.
Answer overview
This event-driven resolution robotically synchronizes your Amazon S3 paperwork with Amazon Bedrock Data Bases. When paperwork are added, modified, or deleted in your S3 bucket (together with metadata information), the answer robotically triggers synchronization jobs whereas respecting service quotas and fee limits. The answer makes use of the streamlined AWS Serverless Software Mannequin (AWS SAM) deployment and operates as a totally serverless structure with out requiring infrastructure administration.
This resolution implements an event-driven structure that mixes key AWS providers to course of Amazon S3 modifications in actual time whereas intelligently managing ingestion jobs. The next parts work collectively to facilitate dependable synchronization whereas respecting service quotas:
- Amazon EventBridge captures real-time modifications from Amazon S3
- AWS Lambda capabilities course of occasions and handle synchronization
- Amazon Easy Queue Service (Amazon SQS) queues buffer requests to respect service quotas
- AWS Step Features orchestrate the synchronization workflow
- Amazon DynamoDB tracks doc modifications and job metadata
The next diagram reveals how the answer makes use of AWS providers to create an event-driven synchronization system.
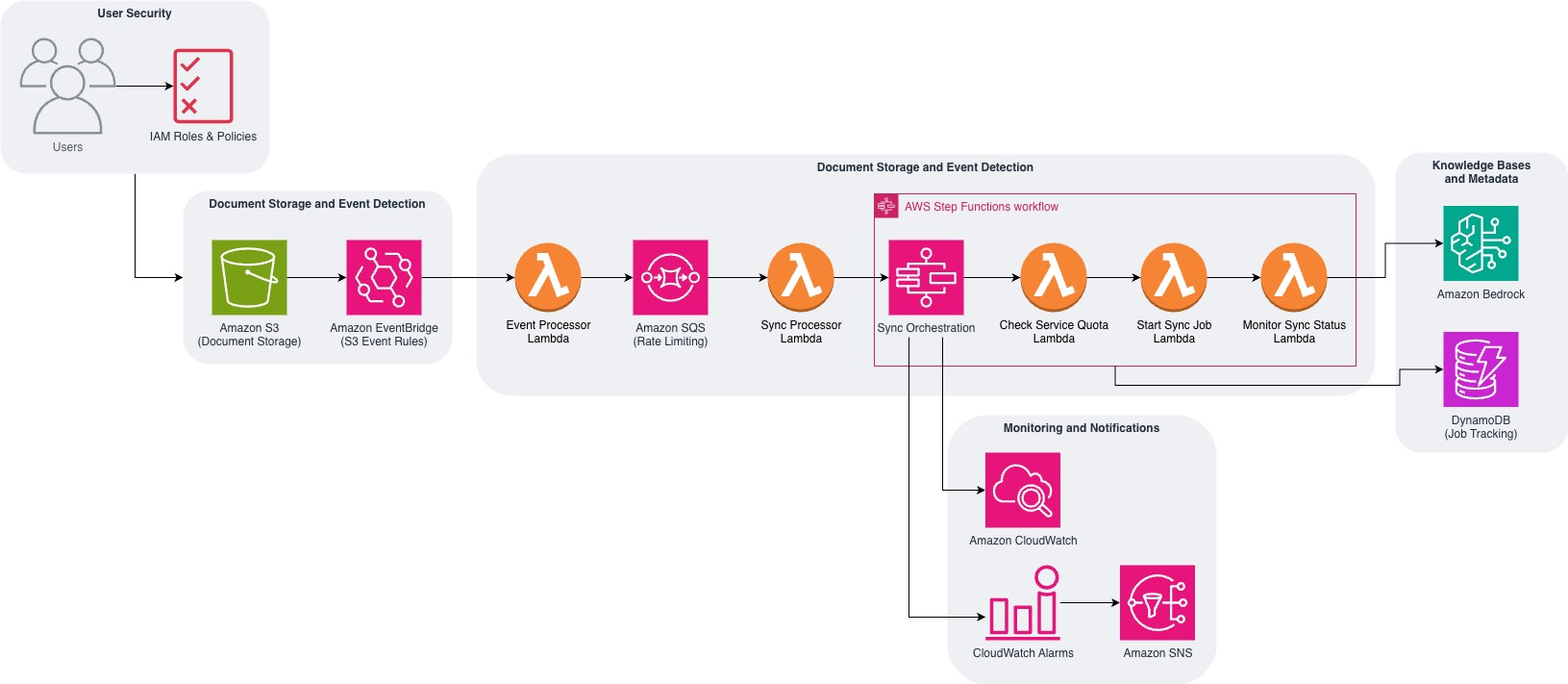
The answer structure consists of 5 interconnected parts that work collectively to handle the whole synchronization workflow. Let’s discover how every element capabilities inside the system, with code examples for instance the technical implementation behind this ready-to-deploy resolution.
Section 1: Doc change detection
The preliminary part establishes automated detection and processing of doc modifications in your S3 bucket. Listed below are the primary actions carried out throughout this part:
- EventBridge captures S3 occasions – When paperwork are uploaded, modified, or deleted, S3 robotically sends occasions to EventBridge
- Lambda processes occasions sequentially – EventBridge triggers the occasion processor Lambda perform, which extracts doc metadata (file path, change sort, and timestamp) and creates monitoring entries in DynamoDB for audit functions
- SQS queues sync requests – The identical Lambda perform instantly sends a sync request message to Amazon SQS, which buffers the requests to handle fee limits and facilitate dependable processing
The next code reveals how the occasion processor Lambda perform handles incoming S3 occasions and coordinates the monitoring and queuing course of:
Section 2: Queue administration
To keep up constant processing and respect service quotas, the answer implements a queuing mechanism that manages doc change requests. The queue administration part entails these important steps:
- Amazon SQS buffers requests – Messages from part 1 are queued to implement the speed restrict between sync job requests are met
- Lambda processes messages – The sync processor Lambda perform consumes one message at a time from the SQS queue
- Workflow initiation – Every message triggers a brand new Step Features execution with the doc change particulars and information base configuration
This code demonstrates how the sync processor Lambda perform consumes SQS messages and launches the orchestration workflow:
Section 3: Orchestrated synchronization
The orchestration part makes use of AWS Step Features to coordinate the synchronization course of whereas managing service quotas and dealing with failures. This workflow contains:
- Quota validation – Checks the lively ingestion jobs within the present Area throughout the information bases to substantiate service limits aren’t exceeded
- Conditional execution – If quotas permit, begins the sync job instantly; in any other case waits 5 minutes earlier than checking once more
- Job monitoring – Tracks sync job progress and handles each profitable completion and failure situations
- Error dealing with – Implements retry logic and lifeless letter processing for failed synchronization makes an attempt
The next Step Features state machine definition reveals the choice logic for quota administration and job execution:
Section 4: Data base processing
Throughout this part, the information base processes the synchronized content material and makes it out there to be used. The next steps happen:
- Doc processing – Amazon Bedrock scans the modified paperwork recognized in the course of the sync job
- Vector conversion – Paperwork are chunked and transformed to vector embeddings utilizing the configured embedding mannequin
- Index updates – New embeddings are saved within the vector database whereas outdated embeddings are eliminated
- Content material availability – Up to date content material turns into instantly out there for semantic search and retrieval
Section 5: Monitoring and alerts
The ultimate part implements complete monitoring and alerting to verify the answer operates reliably. This contains:
- Standing monitoring – Updates doc change standing in DynamoDB as jobs are accomplished efficiently or fail
- Notification supply – Sends success or failure alerts by way of Amazon SNS to configured electronic mail addresses or endpoints
- Efficiency monitoring – Amazon CloudWatch metrics monitor sync job period, success charges, and quota utilization
- Automated alerting – CloudWatch alarms set off when error charges exceed thresholds or jobs stay caught
Key options
This resolution offers a number of important capabilities that facilitate environment friendly and dependable synchronization between Amazon S3 and your information bases. Let’s discover every key function and its advantages.
Actual-time occasion processing
The answer instantly responds to S3 modifications. EventBridge integration captures S3 occasions in actual time. The system processes Amazon S3 object modifications as they happen through the use of S3 occasion notifications to robotically set off ingestion jobs. Response is immediate and there’s no ready for scheduled processes.
Complete quota administration
The answer respects the Amazon Bedrock service quotas:
Clever fee limiting
SQS queue configuration facilitates correct fee limiting:
Strong error dealing with
The answer implements complete error dealing with with lifeless letter queues for failed messages, computerized retry logic for transient failures, and detailed logging by way of CloudWatch to facilitate dependable operation and easy troubleshooting.
Conditions
Earlier than you deploy this resolution, ensure you have the next:
- An AWS account with permissions to create and handle the next providers:
- A preconfigured Amazon Bedrock information base with:
- At the least one information supply linked to Amazon S3
- Acceptable permissions to handle Amazon Bedrock Data Bases
- The next instruments put in in your growth machine:
Estimated time for the infrastructure deployment: 5–10 minutes
Answer walkthrough
This part walks you thru the step-by-step technique of deploying the automated sync resolution in your AWS setting. To deploy this resolution, comply with these steps:
- Clone the GitHub repository:
- Construct and deploy the answer:
Throughout deployment, you’ll be prompted to offer these parameters:
- Stack Title [
kb-auto-sync] – Title on your CloudFormation stack - AWS Area [
us-west-2] – Area the place your Amazon Bedrock information base exists - KnowledgeBaseId – Your Amazon Bedrock information base identifier
- S3BucketName – Title of the S3 bucket containing your paperwork
- S3KeyPrefix (Non-obligatory) – Particular folder prefix to sync (for instance,
paperwork/) - NotificationsEmail (Non-obligatory) – E-mail deal with for sync job notifications
- MaxConcurrentJobs [5] – Most variety of concurrent sync jobs
- Enable AWS SAM CLI IAM position creation [Y/n] – Permission to create IAM roles
- Save arguments to configuration file [Y/n] – Save settings for future deployments
The next code reveals an instance enter:
Setting default arguments for sam deploy
===============================
Stack Title [kb-auto-sync]: my-kb-sync
AWS Area [us-west-2]: us-east-1
Parameter KnowledgeBaseId: kb-1234567890
Parameter S3BucketName: my-document-bucket
Parameter S3KeyPrefix: paperwork/
Parameter NotificationsEmail: consumer@instance.com
Enable SAM CLI IAM position creation [Y/n]: Y
Save arguments to configuration file [Y/n]: Y
The deployment will create the required sources and output the stack particulars upon completion.
Value issues
The answer makes use of a number of AWS providers, every with its personal pricing mannequin:
These are the estimated month-to-month prices for typical utilization per 10,000 paperwork:
- Lambda invocations: ~$0.20
- EventBridge occasions: ~$1.00
- Different providers: Minimal prices
This resolution is right for organizations that want real-time doc synchronization, course of frequent doc updates, and require automated information base upkeep with minimal guide intervention. The method follows these actions in a real-world instance the place a consumer uploads a doc:
- The consumer uploads the doc to Amazon S3 at 2:00 PM
- EventBridge captures the S3 occasion instantly
- The occasion processor Lambda perform creates a monitoring entry and sends an SQS message
- The sync processor Lambda perform receives the message and begins a Step Features workflow
- The quota verify verifies there are not any lively jobs for the information base
- The ingestion job begins instantly
- The monitor perform tracks progress till completion at 2:05 PM
- The change is marked as processed in DynamoDB
Troubleshooting
Sync job failures and fee limiting are widespread points that may be resolved as follows:
- Sync job failure – This will happen when permissions are misconfigured or doc sizes exceed limits. To resolve:
- Overview ingestion job warnings within the Amazon Bedrock console underneath your Data Base information supply sync historical past.
- Confirm that IAM permissions are appropriately configured
- Verify that doc sizes are inside the allowed limits
- Price limiting – This occurs when too many sync requests are processed concurrently or service quotas are reached. To resolve this, take these steps:
- Monitor CloudWatch metrics to determine bottlenecks
- Alter concurrency settings as wanted to remain inside limits
Cleanup
To keep away from incurring ongoing expenses, it’s essential to correctly clear up the sources created by this resolution. Comply with these steps to facilitate the elimination of the parts.
To delete the stack utilizing AWS SAM, enter the next code:
To delete the stack utilizing CloudFormation, comply with these steps:
- Open the AWS CloudFormation console
- Choose your stack:
kb-auto-sync(or the customized identify you selected throughout deployment) - Select Delete and ensure the deletion
- Look forward to stack deletion to finish with out errors
The next sources will stay after stack deletion:
- Unique S3 paperwork
- Amazon Bedrock information base
- CloudWatch logs (till retention interval expires)
- Manually created sources exterior the stack
Conclusion
This event-driven automated sync resolution offers an answer to maintain Amazon Bedrock Data Bases synchronized with S3 paperwork in actual time. By combining rapid occasion processing with clever quota administration and complete monitoring, the answer facilitates dependable operation whereas optimizing efficiency. The true-time strategy is right for functions requiring rapid doc availability, reminiscent of buyer assist methods, documentation methods, and information administration options.
Subsequent steps and extra sources
Need to be taught extra? Listed below are some useful sources to proceed your journey. Deeper dive:
Associated options:
Documentation:
Assist and neighborhood:
Concerning the authors



{kind=link}