
Protein researchers face a time-consuming problem: manually looking out by means of 1000’s of peptide sequences to seek out structurally comparable candidates is sluggish, error-prone, and requires deep area experience to interpret outcomes. Constructing a protein analysis copilot can rework how researchers seek for structurally comparable peptides throughout massive datasets — enabling pure language queries, automated embedding era, and AI-powered end result summarization in a single conversational interface.
This publish reveals you find out how to construct a conversational protein analysis assistant that mixes three capabilities:
- Pure language question parsing to extract structured search parameters.
- Vector similarity search over protein embeddings utilizing a specialised language mannequin.
- AI-generated scientific summaries of search outcomes.
The system makes use of the Strands Brokers SDK to orchestrate three specialised instruments inside one agent, deploys to Amazon Bedrock AgentCore for manufacturing serving, and shops peptide embeddings in Amazon Aurora PostgreSQL-Suitable Version with pgvector.
By the tip of this publish, you’ll have constructed an end-to-end agent software that demonstrates find out how to:
- Parse pure language consumer enter like “Discover 10 comparable peptides to the dengue virus peptide LPAIVREAI”, into structured instrument parameters utilizing the Strands Brokers SDK’s tool-use sample.
- Deploy a customized ML mannequin (ESM-C 300M) as Amazon SageMaker AI serverless endpoint with bundled weights for quick chilly begins.
- Mix vector similarity search (pgvector on Amazon Aurora PostgreSQL) with metadata filtering in a single question.
- Orchestrate a number of specialised instruments — together with nested LLM brokers — inside a single Bedrock AgentCore runtime and generate scientific summaries of search outcomes.
Stipulations
To comply with together with this publish, you want:
- An AWS account with entry to Amazon Bedrock basis fashions (Anthropic Claude Sonnet 4.6).
- Python 3.12 or later.
- The AWS Command Line Interface (AWS CLI) configured with applicable credentials.
- IAM permissions for Amazon Bedrock, Amazon SageMaker AI, Amazon Aurora, Amazon Elastic Container Service (Amazon ECS), and AWS CodeBuild.
bedrock-agentcore-starter-toolkitput in (pip set up bedrock-agentcore-starter-toolkit).- The IEDB virus epitope dataset.
- Estimated deployment time: 30–45 minutes; assessment the AWS pricing pages for Bedrock, SageMaker AI, Aurora Serverless v2, and AWS Fargate for value estimates.
Resolution overview
The copilot follows a tool-use sample the place a single Strands agent orchestrates three specialised instruments to deal with the whole analysis workflow. When a researcher submits a pure language question, the agent parses it into structured parameters, searches for comparable peptides utilizing protein embeddings, and summarizes the outcomes with scientific context.
The next diagram illustrates the structure:
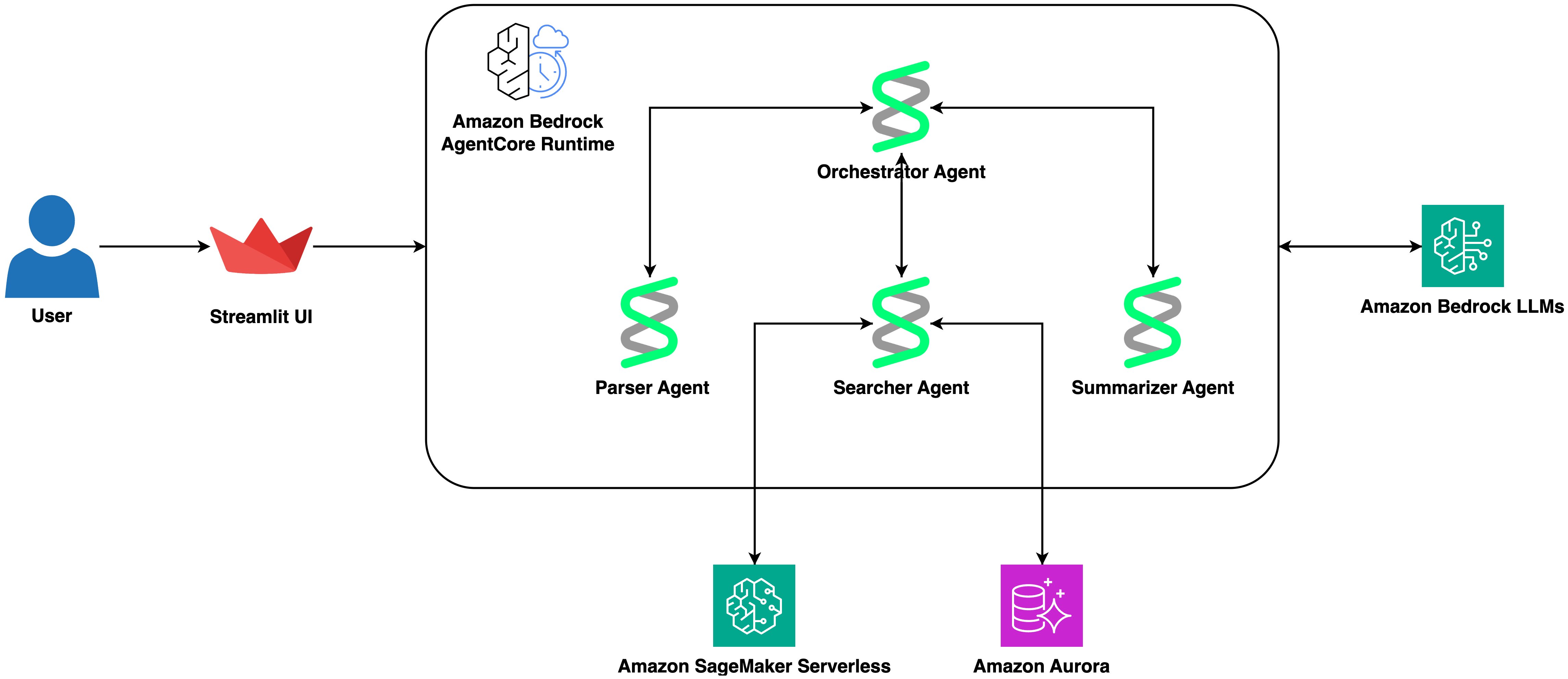
This structure has 5 elements:
- A Streamlit frontend working on AWS Fargate offers the conversational interface. It sends queries to the AgentCore runtime and shows leads to a structured format with downloadable tables.
- A Strands agent working inside a single Amazon Bedrock AgentCore runtime orchestrates the workflow. The agent makes use of Anthropic Claude Sonnet 4.6 by way of the Bedrock Converse API and has entry to 3 instruments outlined with the
@instrumentdecorator. - A parser instrument that makes use of a devoted Strands agent (LLM-as-parser sample) to extract structured search parameters — sequence, species filter, end result restrict — from pure language queries.
- A searcher instrument that generates protein embeddings by way of Amazon SageMaker AI serverless endpoint working ESM-C 300M, then performs cosine similarity search towards Amazon Aurora PostgreSQL with pgvector.
- A summarizer instrument that makes use of one other devoted Strands agent to research search outcomes and produce concise scientific summaries with strategies for additional investigation.
This single-runtime, multi-tool design retains the deployment easy whereas sustaining clear separation of issues. Every instrument encapsulates a definite functionality, and the orchestrator agent decides when and find out how to invoke them based mostly on the consumer’s question.
Protein embeddings with ESM-C 300M
The core of the similarity search is ESM-C 300M, a protein language mannequin from EvolutionaryScale (Constructed with ESM) that produces 960-dimensional embeddings capturing structural and purposeful properties of amino acid sequences. Two peptides with comparable organic operate produce embeddings which are shut in vector area, enabling similarity search with out requiring sequence alignment.
ESM-C 300M is deployed as an Amazon SageMaker AI serverless endpoint, which scales to zero when idle and incurs no value between invocations. The mannequin weights are bundled into the deployment artifact to keep away from downloading from HuggingFace at inference time — important for serverless endpoints the place chilly begin latency issues.
The inference handler constructs the mannequin structure immediately and masses pre-packaged weights:
The predict_fn handler takes a protein sequence, encodes it, and returns the mean-pooled embedding:
The endpoint is deployed as a serverless configuration with 6144 MB reminiscence and a max concurrency of 5, utilizing the PyTorch 2.6.0 CPU inference container. The mannequin packaging script downloads weights as soon as by way of from_pretrained, saves the state dict, and bundles it with the inference code right into a mannequin.tar.gz with the required code/ listing construction for SageMaker AI.
Vector search with Aurora PostgreSQL and pgvector
Peptide embeddings are saved in Amazon Aurora PostgreSQL-Suitable Version Serverless v2 with the pgvector extension. The database schema is simple:
The properties JSONB column shops organic metadata — species, supply organism, supply molecule, epitope positions — enabling mixed vector and metadata filtering. For instance, a question like “Discover peptides much like LPAIVREAI from dengue virus” triggers each a cosine similarity search on the embedding column and a filter on properties->>'species'.
The information loading pipeline reads from the IEDB virus epitope dataset, generates embeddings for every peptide sequence by way of the SageMaker AI endpoint, and inserts them into the database utilizing the Amazon RDS Information API. The preliminary load samples 1,000 linear peptides:
Database entry goes by means of the Amazon Relational Database Service (Amazon RDS) Information API, which suggests the agent runtime doesn’t want direct community connectivity to the database — it communicates over HTTPS, simplifying the networking necessities for AgentCore deployment.
Constructing the agent with Strands Brokers SDK
The Strands Brokers SDK offers a clear abstraction for constructing tool-using brokers. Every instrument is a Python operate embellished with @instrument, and the agent mechanically generates instrument descriptions for the LLM from the operate’s docstring and kind hints.
Software definitions
The parser instrument delegates to a devoted Strands agent that acts as a structured output extractor:
The searcher instrument combines SageMaker AI embedding era with pgvector similarity search:
The summarizer instrument makes use of one other devoted Strands agent for scientific evaluation:
Orchestrator agent
The orchestrator ties every part collectively. It receives the consumer’s question and decides which instruments to name and in what order:
This design makes use of the “agents-as-tools” sample: the parser and summarizer are themselves Strands brokers, however they’re wrapped in @instrument decorators and uncovered to the orchestrator as callable instruments. The orchestrator doesn’t know or care that these instruments internally use LLMs — it calls them as capabilities. This retains the orchestration logic clear whereas permitting every instrument to leverage LLM capabilities the place wanted.
Deploying to Amazon Bedrock AgentCore
Amazon Bedrock AgentCore offers a managed runtime for internet hosting AI brokers. The agent code runs in a containerized atmosphere constructed and deployed by way of AWS CodeBuild — no native Docker set up is required.
Agent entrypoint
The AgentCore runtime expects an entrypoint operate that receives a payload and context:
The entrypoint captures instrument outputs in a shared dictionary in order that the response consists of structured information (parsed question, search outcomes desk, abstract textual content) as an alternative of the agent’s last textual content output alone. This structured response is what the Streamlit frontend makes use of to render tables and expandable sections.
Infrastructure as code
The deployment makes use of AWS CloudFormation for all infrastructure. The VPC stack creates non-public subnets with NAT gateways and VPC endpoints for Amazon Bedrock, Amazon RDS Information API, and AWS Secrets and techniques Supervisor — serving to to make sure the agent runtime can attain all required companies with out traversing the general public web.
Amazon Aurora PostgreSQL-Suitable Version Serverless v2 database can be required with automated scaling from 0.5 to 4 ACUs (1–8 GB RAM). An AWS Lambda-backed customized useful resource initializes the pgvector extension and creates the peptides desk throughout stack creation:
Deploy the answer
The answer requires the next elements, deployed so as:
Warning: Full the deployment steps so as. Skipping steps might end in deployment failures.
- VPC and networking — Non-public subnets with NAT gateways and VPC endpoints for Amazon Bedrock, the Amazon RDS Information API, and AWS Secrets and techniques Supervisor, so the agent runtime can attain all required companies with out traversing the general public web.
- Aurora PostgreSQL database — An Amazon Aurora PostgreSQL-Suitable Version Serverless v2 cluster with the pgvector extension enabled and the peptides desk initialized by way of a Lambda-backed AWS CloudFormation customized useful resource.
- SageMaker AI endpoint — A serverless endpoint working ESM-C 300M with 6144 MB reminiscence and a max concurrency of 5, utilizing the PyTorch 2.6.0 CPU inference container.
- Peptide information — The IEDB virus epitope dataset is loaded into the database by producing embeddings for every sequence by way of the SageMaker AI endpoint and inserting them utilizing the Amazon RDS Information API.
- AgentCore runtime and Streamlit UI — The Strands agent is deployed to an Amazon Bedrock AgentCore runtime by way of AWS CodeBuild (no native Docker required), and the Streamlit frontend is deployed to AWS Fargate.
Streamlit frontend
The frontend is a light-weight Streamlit software that communicates with the AgentCore runtime by way of the bedrock-agentcore boto3 shopper. It runs on AWS Fargate with a minimal container picture that features solely streamlit, pandas, and boto3 — no ML libraries.
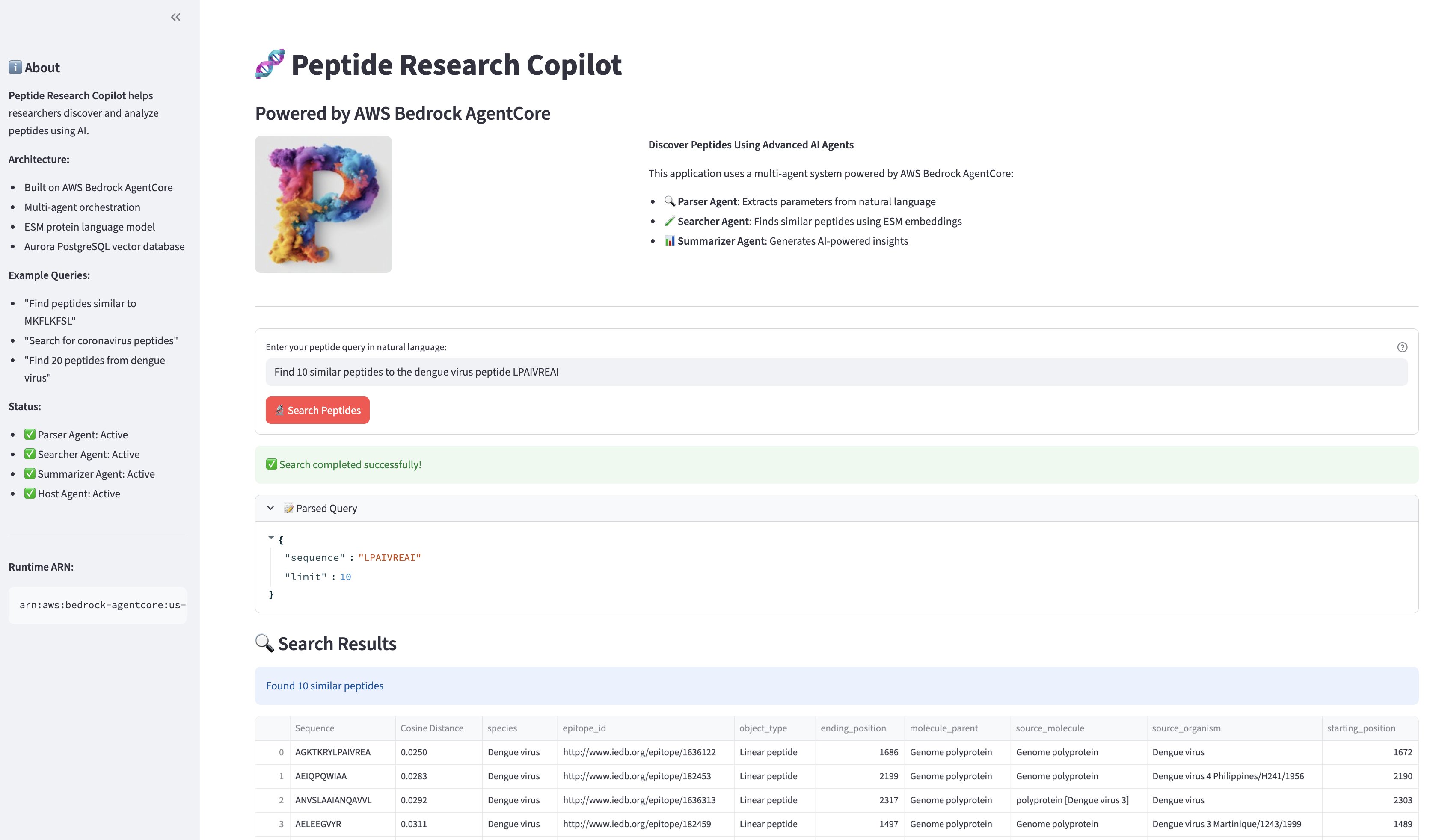
The UI shows leads to three sections: the parsed question parameters (expandable), a sortable desk of comparable peptides with cosine distances and metadata, and the AI-generated scientific abstract. Customers can obtain outcomes as CSV for additional evaluation.
The next screenshot reveals the search question and the outcomes.
Concerns
Earlier than deploying this resolution to manufacturing, maintain the next design and operational trade-offs in thoughts:
Chilly begin latency. The SageMaker AI serverless endpoint takes 2–3 minutes on the primary invocation after an idle interval whereas the container initializes and masses mannequin weights. Subsequent invocations throughout the keep-alive window full in seconds. For latency-sensitive workloads, contemplate a provisioned endpoint or setting the next provisioned concurrency on the serverless configuration.
Embedding mannequin alternative. We use ESM-C 300M for its steadiness of embedding high quality and inference velocity on CPU. For greater accuracy on structural similarity duties, ESM-C 600M or ESM2 fashions supply bigger embedding dimensions at the price of elevated reminiscence and latency. The 960-dimensional embeddings from ESM-C 300M present robust efficiency for peptide similarity search in testing.
Scaling the dataset. The preliminary load makes use of 1,000 sampled peptides from the IEDB dataset. For manufacturing use with bigger datasets, contemplate batch-loading embeddings, growing the IVFFlat index lists parameter proportionally, and scaling Aurora ACUs accordingly. The Amazon RDS Information API has a 1 MB response measurement restrict, so queries returning massive end result units might have pagination.
Price. The serverless elements (SageMaker AI serverless endpoint, Aurora Serverless v2, AgentCore runtime) scale to near-zero when idle, making this structure cost-effective for analysis workloads with intermittent utilization patterns. The first ongoing prices throughout lively use are Bedrock LLM inference (three calls per question: parser, orchestrator, summarizer) and SageMaker AI endpoint invocations.
Cleansing up
To keep away from ongoing costs, delete the assets within the following order:
Warning: Delete assets in reverse order to keep away from dependency errors.
- Streamlit UI — Delete the AWS Fargate stack by way of the AWS CloudFormation console or AWS CLI.
- SageMaker AI endpoint — Delete the endpoint, endpoint configuration, and mannequin by way of the Amazon SageMaker AI console or AWS CLI.
- Database — Delete the IEDB dataset after which the Aurora PostgreSQL database stack, by way of the AWS CloudFormation console.
- VPC — Delete the VPC stack by way of the AWS CloudFormation console.
- AgentCore runtime — Delete the runtime by way of the Amazon Bedrock AgentCore console.
Conclusion
This publish confirmed you find out how to construct a protein analysis copilot that mixes protein language mannequin embeddings with LLM-powered evaluation in a single conversational interface.
What historically requires a researcher to manually question sequence databases, run alignment instruments, and interpret outcomes throughout a number of functions — a course of that may take hours per search — is diminished to a single pure language question that returns ranked, summarized leads to beneath a minute (or 2–3 minutes on chilly begin). This consolidation of parsing, embedding-based search, and scientific summarization into one conversational workflow can considerably speed up the early levels of peptide analysis and candidate screening.
The Strands Brokers SDK’s tool-use sample offers a clear technique to compose specialised capabilities — parsing, looking out, summarizing — right into a coherent workflow, whereas Amazon Bedrock AgentCore handles the operational complexity of internet hosting and scaling the agent.
The identical structure generalizes past peptide analysis. Domains the place researchers want to look over specialised embeddings, filter by structured metadata, and synthesize outcomes — genomics, drug design, supplies science — can profit from this sample of mixing domain-specific embedding fashions with LLM orchestration. The important thing design selections that make this sensible are: bundling mannequin weights to keep away from cold-start downloads, utilizing the Amazon RDS Information API to simplify networking, and automating the deployment with infrastructure as code.
As subsequent steps, contemplate exploring bigger ESM fashions for greater embedding accuracy, including assist for batch queries, or extending the metadata schema to incorporate extra organic annotations from the IEDB dataset.
References
Vita R, Blazeska N, Marrama D; IEDB Curation Workforce Members; Duesing S, Bennett J, Greenbaum J, De Almeida Mendes M, Mahita J, Wheeler DK, Cantrell JR, Overton JA, Natale DA, Sette A, Peters B. The Immune Epitope Database (IEDB): 2024 replace. Nucleic Acids Res. 2025 Jan 6;53(D1):D436-D443. doi: 10.1093/nar/gkae1092. PMID: 39558162; PMCID: PMC11701597.
ESM Workforce. “ESM Cambrian: Revealing the mysteries of proteins with unsupervised studying.” EvolutionaryScale, 2024. https://evolutionaryscale.ai/weblog/esm-cambrian
Concerning the authors



{kind=link}