
Predictive upkeep is a method that makes use of information from gear sensors and superior analytics to foretell when a machine is more likely to fail, making certain upkeep could be carried out proactively to forestall breakdowns. This permits industries to scale back surprising failures, enhance operational effectivity, and prolong the lifespan of essential gear. It’s relevant throughout a variety of parts, together with motors, followers, gearboxes, bearings, conveyors, actuators, and extra.
On this submit, we show the way to implement a predictive upkeep answer utilizing Basis Fashions (FMs) on Amazon Bedrock, with a case research of Amazon’s manufacturing gear inside their achievement facilities. The answer is very adaptable and could be custom-made for different industries, together with oil and gasoline, logistics, manufacturing, and healthcare.
Predictive upkeep overview
Predictive upkeep could be damaged down into two key phases: sensor alarm technology and root trigger prognosis. Collectively, these phases kind a complete method to predictive upkeep, enabling well timed and efficient interventions that reduce downtime and maximize gear efficiency. After a short overview of every part, we element how customers could make the second part extra environment friendly by utilizing generative AI, permitting upkeep groups to handle gear points quicker.
Part 1: Sensor alarm technology
This part focuses on monitoring gear situations—reminiscent of temperature and vibration—by sensors that set off alarms when uncommon patterns are detected.
At Amazon, that is achieved utilizing Amazon Monitron sensors that repeatedly monitor gear situations. These sensors are an end-to-end, machine studying (ML) powered gear monitoring answer that covers the preliminary steps of the method:
 Step 1: Monitron sensors seize vibration and temperature information
Step 1: Monitron sensors seize vibration and temperature information
Step 2: Sensor information is robotically transferred to Amazon Internet Companies (AWS)
Step 3: Monitron analyzes sensor information utilizing ML and vibration ISO requirements
Step 4: Monitron app sends notifications on irregular gear situations
Part 2: Root Trigger Prognosis
This part makes use of the sensor information to establish the foundation reason behind the detected points, guiding upkeep groups in performing repairs or changes to assist forestall failures. It encompasses the remaining steps of the method.
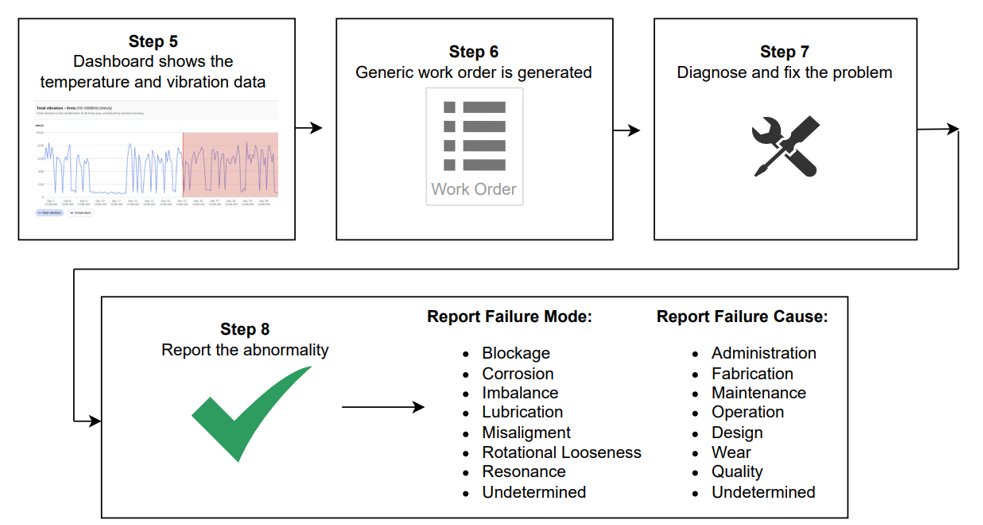
Step 5: Dashboard exhibits the temperature and vibration information
Step 6: Generic work order is generated
Step 7: Diagnose and repair the issue
Step 8: Report the abnormality
Throughout this part, technicians face two challenges: receiving generic work orders with restricted steering and having to search out related info amongst 40+ restore manuals, every with a whole bunch of pages. When gear points are of their early phases and never but exhibiting clear indicators of malfunction, it turns into tough and time-consuming for technicians to pinpoint the foundation trigger, resulting in delays in prognosis and restore. This ends in extended gear downtime, decreased operational effectivity, and elevated upkeep prices.
Answer overview
Within the Root Trigger Prognosis and Downside Decision part, greater than 50% of labor orders generated after an alarm is triggered stay labeled as “Undetermined” when it comes to root trigger. To deal with this problem, we have now developed a chatbot geared toward enhancing predictive upkeep diagnostics, making it less complicated for technicians to detect faults and pinpoint points throughout the gear. This answer considerably reduces downtime whereas bettering general operational effectivity.
The important thing options of the answer embrace:
- Time collection information evaluation and diagnostics – The assistant processes and analyzes sensor information to ship exact diagnostics, figuring out patterns and anomalies to help correct, data-driven troubleshooting.
- Guided troubleshooting with proactive multi-turn conversations – The assistant retains dialog historical past for seamless, context-aware interactions. It’s goal-oriented, centered on discovering the foundation trigger of apparatus points by a proactive, multi-turn dialogue the place the system prompts the consumer with focused questions to assemble important info for environment friendly troubleshooting.
- Multimodal capabilities – Customers can add numerous codecs—manuals, photographs, movies, and audio—to the assistant’s information base, which it may each perceive and reply to throughout these modalities. That is achieved utilizing Claude 3 Haiku and Claude 3 Sonnet, highly effective multimodal fashions obtainable by Amazon Bedrock.
- Superior multimodal RAG with reciprocal rank fusion – Multimodal Retrieval Augmented Technology (RAG) allows the assistant to offer responses that incorporate each photographs and textual content from restore manuals. Reciprocal rank fusion makes certain that the retrieved info is each related and semantically aligned with the consumer’s question.
- Guardrails for security and compliance – The assistant employs Amazon Bedrock Guardrails to assist preserve security, accuracy, and conformance all through the diagnostic course of. These guardrails incorporate filters for delicate info and dangerous content material, blockage of inappropriate content material, and validation steps to assist forestall misguided suggestions.
Within the following sections, we define the important thing stipulations for implementing this answer and supply a complete overview of every of those key options, inspecting their performance, implementation, and the way they contribute to quicker prognosis, decreased downtime, and general operational effectivity.
Conditions
To efficiently construct and combine this predictive upkeep answer, sure foundational necessities have to be in place. These stipulations are essential to be sure that the answer could be successfully deployed and obtain its meant affect:
- Determine essential property for predictive upkeep – Begin by figuring out which property are most important to your operations and will trigger vital disruption in the event that they failed unexpectedly. Prioritize gear with a historical past of excessive restore prices, frequent breakdowns, or a essential function within the manufacturing course of.
- Gather and log actionable information – Arrange a system to repeatedly monitor vibration and temperature at 1-minute intervals. Arrange automated information switch to the AWS Cloud for safer storage and environment friendly evaluation, permitting the answer to generate correct insights for every asset.
- Collect gear restore manuals – Receive Unique Tools Producer (OEM) manuals that element upkeep necessities, advisable service intervals, and protected procedures for every asset. Additionally add institutional information from principal machinists. This info is significant in aligning predictive insights with precise upkeep wants.
- Keep Historic Upkeep Information (non-compulsory however strongly inspired) – Hold correct information of earlier upkeep actions and work orders. Whereas non-compulsory, having historic information helps refine the predictive fashions and improves the system’s accuracy in forecasting potential failures.
With these foundations in place, the following sections discover the completely different functionalities obtainable within the chatbot to ship quicker, smarter and extra dependable root trigger prognosis.
Time collection evaluation and guided troubleshooting dialog
The time collection evaluation and guided dialog are damaged down into six key steps, as proven within the following determine.
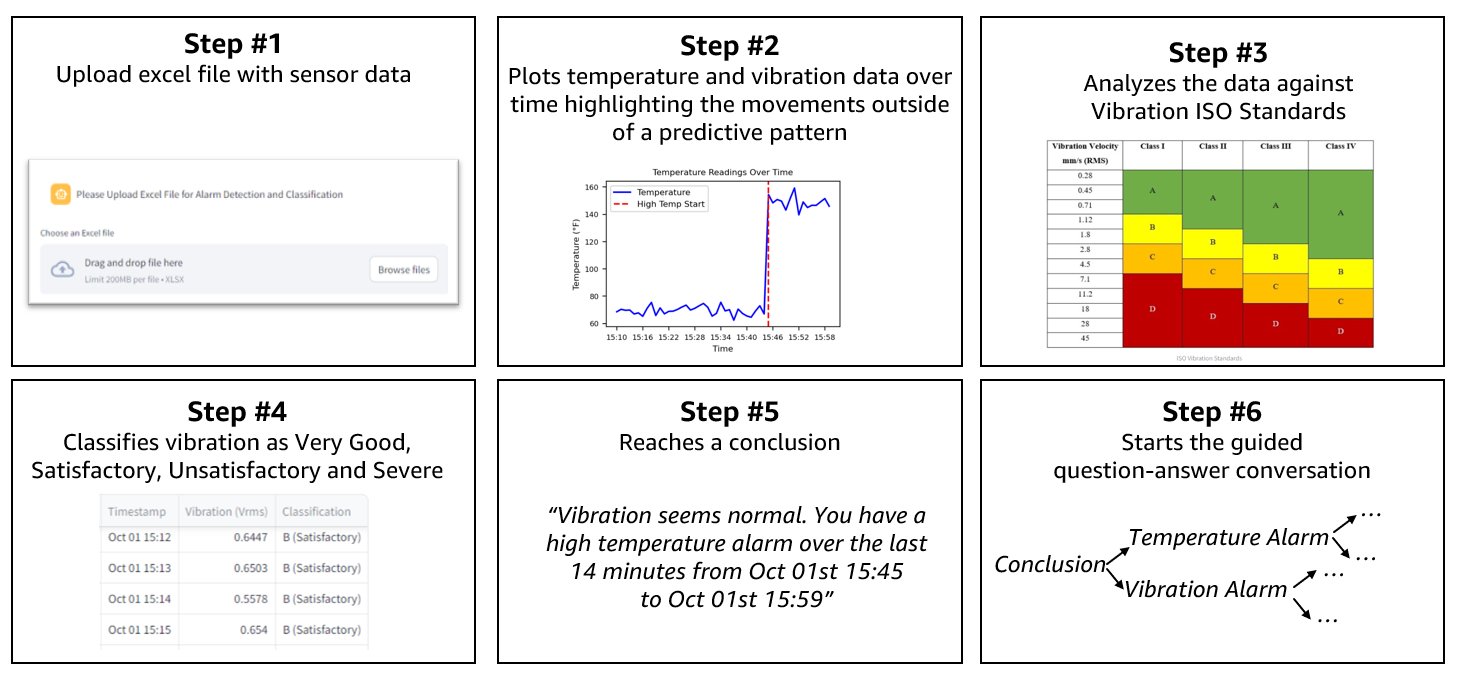
The steps are as follows:
- The consumer uploads an Excel file containing sensor information (each vibration and temperature information) within the Streamlit app. The info is extracted utilizing Python-based helper scripts for information manipulation, setting the inspiration for additional evaluation.
- The system plots the temperature and vibration information over time utilizing Matplotlib, highlighting deviations from regular patterns that point out a possible challenge with a pink vertical line. This visualization step makes certain that abnormalities are clearly identifiable.
- The system evaluates the vibration information by evaluating it to ISO vibration requirements (ISO 20816-1), which set worldwide benchmarks for vibration ranges based mostly on the gear’s class. These benchmarks, generally known as analysis zones, set up fastened thresholds for vibration measured as Velocity Root Imply Sq. (VRMS). VRMS represents the typical depth of vibration over time, serving to to precisely decide whether or not an asset is working usually or experiencing irregular vibrations.
- Warning is created when the asset strikes from Zone B to C.
- Alarm is created when the asset strikes from zone C to D.
- Primarily based on the sensor information, the system classifies the vibration ranges for every timestamp as Very Good, Passable, Unsatisfactory, or Extreme, offering insights into the gear’s well being.
- A conclusion is drawn from the evaluation, as an example, figuring out that the vibration is regular however a high-temperature alarm has been triggered inside a specific timeframe.
- A guided troubleshooting dialog is initiated utilizing Python to border preliminary diagnostic questions based mostly on the evaluation. The method transitions to a generative AI-powered massive language mannequin (LLM), which acts a digital technician, partaking in a multi-turn dialogue to additional refine the diagnostic course of. The LLM adapts to consumer responses, just like a session with a medical skilled, providing focused steering towards resolving the problem. With reminiscence retention of earlier responses, the LLM offers extra correct and tailor-made troubleshooting all through the interplay. Moreover, guardrails are carried out to maintain the dialog centered, offering security, appropriateness, and relevance, which finally enhances the standard and reliability of the diagnostic steering supplied.
The next screenshot exhibits an instance of a guided dialog initiation after detecting a excessive temperature alarm. Observe that the consumer didn’t present a immediate; the dialog was solely initiated by the system based mostly on the uploaded sensor information.

The next screenshot exhibits the UI of this assistant with the LLM-generated response after the dialog from the earlier instance.
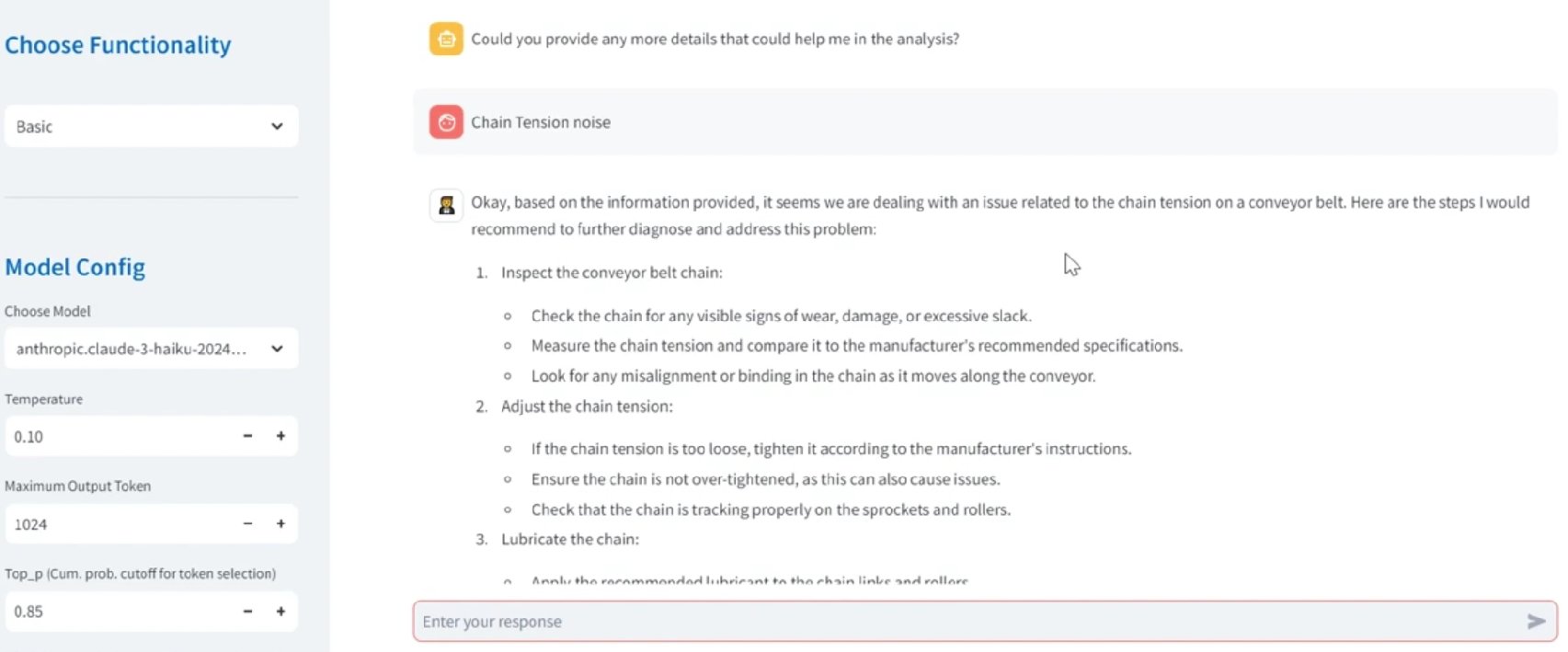
As seen within the screenshot, the earlier responses are saved, permitting the system to construct upon every response to create a extra correct, personalised prognosis. This memory-driven method makes certain that the troubleshooting dialog stays extremely related and focused, enhancing the assistant’s effectiveness as a digital assistant for root trigger prognosis.
Multimodal capabilities
To reinforce diagnostic capabilities and supply complete help, the system permits customers to work together by a number of enter modalities. This flexibility makes certain that technicians can talk utilizing essentially the most appropriate format for his or her wants, whether or not that be a picture, audio, or video. Through the use of generative AI, the system can analyze and combine info from the three modalities, providing deeper insights and simpler troubleshooting options.
The system helps the next multimodal inputs:
- Picture – Add photographs of apparatus or particular parts for visible evaluation and fault detection
- Audio – File and add audio descriptions or machine sounds, permitting the system to transcribe and analyze verbal inputs or uncommon noises
- Video – Present movies capturing gear operation or failures, enabling frame-by-frame evaluation and built-in audio-video diagnostics
Within the following sections, we discover how every of those inputs is processed and built-in into the system’s diagnostic workflow to ship a holistic upkeep answer.
Picture evaluation for diagnostic evaluation
The assistant makes use of multimodal capabilities to research photographs, which could be significantly helpful when technicians must add a photograph of a degraded or malfunctioning element. Utilizing a multimodal LLM reminiscent of Anthropic’s Claude Sonnet 3.5 on Amazon Bedrock, the system processes the picture, producing an in depth description that aids in understanding the state of the gear. For example, an operator may add a picture of a worn-out bearing, and the assistant may present a textual abstract of seen put on patterns, reminiscent of discoloration or cracks, serving to to pinpoint the problem with out guide interpretation.
The workflow consists of the next steps:
- The consumer uploads a picture — for instance, a photograph of a worn element — by the assistant interface.
- The picture is resized or processed to satisfy the mannequin’s enter constraints, ensuring that it adheres to file measurement and determination limits.
- The picture is transformed into base64 format, which permits it to be transmitted in a standardized manner as a part of the enter payload for the multimodal LLM.
- A predefined immediate is used to instruct the mannequin to explain the picture, for instance, “Describe any seen defects or abnormalities within the element proven on this picture.”
- The mannequin generates a text-based description of the picture. For instance, if the uploaded picture exhibits a bearing with floor cracks and discoloration, the mannequin may output one thing like: “The element exhibits indicators of wear and tear with seen floor cracks and heat-related discoloration.”
The flexibility to research photographs offers technicians with an intuitive method to diagnose issues past sensor information alone. This visible context, mixed with the assistant’s information base, permits for extra correct and environment friendly upkeep actions, decreasing downtime and bettering general operational effectivity.
Audio inputs for real-time voice processing
Along with picture and textual content modalities, the chatbot additionally helps audio inputs, enabling technicians to file their observations, notes, or ask questions in real-time utilizing voice. That is significantly helpful in eventualities the place technicians won’t have the time or capacity to kind, reminiscent of when they’re on-site or working hands-on with gear.
The next diagram illustrates how audio processing works.
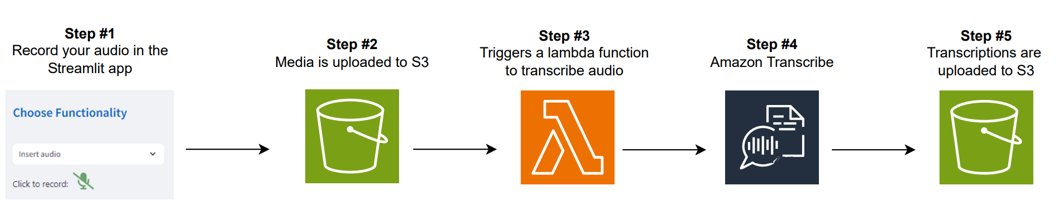
The workflow consists of the next steps:
- The technician can file an audio clip, reminiscent of a voice word describing the present situation of the gear or a query a few explicit upkeep challenge. The system helps fast audio recordings straight throughout the assistant interface.
- After the audio is recorded, it’s processed by an Computerized Speech Recognition (ASR) system (Amazon Transcribe), which transcribes the spoken phrases into textual content. The transcription offers an correct illustration of the spoken content material, which is used as enter for additional evaluation or dialog.
- After transcription, the textual content is offered to the technician, permitting them to overview the transcription and ensure it accurately captures their intent.
- When the transcription is on the market, the dialog is initiated and guided by LLMs, permitting the technician to ask follow-up questions or request further evaluation. For instance, they may ask, “Primarily based on this audio, are you able to advocate the following steps for resolving the problem?” The transcribed textual content is handed to the LLM together with the consumer’s query, the place responses are generated with Amazon Bedrock guardrails. These guardrails be sure that solutions stay related, acceptable, and protected, delivering centered and dependable insights or steering all through the interplay.
- The system additionally retains the context of the dialog, enabling multi-turn interactions. Which means additional questions the technician asks are framed throughout the context of the preliminary audio recording and transcription, permitting for extra correct responses and continued troubleshooting.
The next Python code demonstrates a utility perform for transcribing audio recordsdata utilizing Amazon Transcribe. This perform uploads an audio file to an Amazon Easy Storage Service (Amazon S3) bucket, triggers a transcription by a customized Amazon API Gateway endpoint, and retrieves the transcription end result:
The next is an AWS Lambda perform designed to course of audio transcription jobs. This perform makes use of Amazon Transcribe to deal with audio recordsdata supplied by S3 uniform useful resource identifiers (URIs), screens the transcription job standing, and returns the ensuing transcription URI. The perform is optimized for asynchronous transcription duties and strong error dealing with:
This code captures an audio file from an S3 URI, transcribes it utilizing Amazon Transcribe, and returns the transcription end result. The transcription can now be used for assistant interactions, permitting technicians to doc their observations verbally and obtain immediate suggestions or steering. It streamlines the troubleshooting course of, particularly in environments the place hands-free interplay is helpful.
Video information processing with multimodal evaluation
Along with supporting picture and audio inputs, the system can even course of video information, which is very helpful when technicians want visible steering or wish to present detailed proof of apparatus conduct. For example, technicians may add movies showcasing irregular machine operation, enabling the assistant to research the footage for diagnostic functions. Moreover, technicians may add coaching movies and rapidly get essentially the most related info, with the ability to ask questions on how sure procedures are carried out.
To help this performance, we developed a customized video processing workflow that extracts each audio and visible parts for multimodal evaluation. Whereas this method was needed on the time of growth, newer developments, such because the native video understanding capabilities of Amazon Nova in Amazon Bedrock, now supply a streamlined and scalable different for organizations seeking to combine comparable performance.
The next determine showcases the video processing workflow.
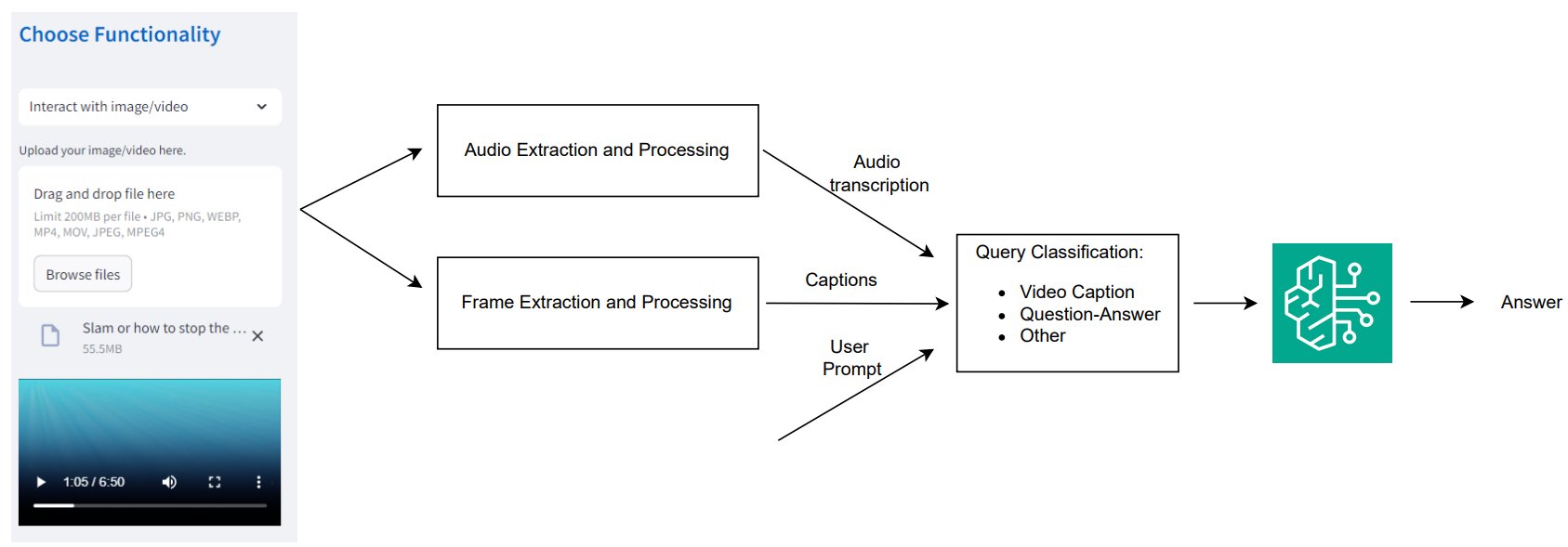
The workflow consists of the next key steps:
- The technician uploads a video by the Streamlit utility interface.
- If the video incorporates voice directions, the audio is extracted and its transcription is obtained utilizing the identical ASR methodology talked about earlier, ensuring that the audio information is used for diagnostic functions.
- The system extracts particular person video frames at common intervals (for instance, each three seconds) and converts them into base64-encoded frames. This offers environment friendly processing and evaluation of the video content material. Every extracted body is handed by a multimodal LLM, which generates captions for the frames. This helps in summarizing the visible content material of the video, specializing in key elements reminiscent of gear situations, put on and tear, or irregular actions. To take care of alignment between video frames and spoken content material, the system makes use of the body extraction timestamps and maps them to the corresponding time ranges within the transcribed audio. This facilitates coherent multimodal interpretation throughout visible and auditory inputs.
- The system acts as an LLM-based router, which implies it’s liable for directing queries to the suitable processing path based mostly on their classification. A router determines the kind of question and routes it accordingly to offer an correct and environment friendly response. On this context, the system classifies the technician’s question based mostly on their interplay with the video. Queries can fall into completely different classes, reminiscent of:
- Video caption – If the technician requests a abstract or description of the video content material.
- Query-Reply – If the technician asks particular questions based mostly on the video (for instance, “What’s the challenge with this element based mostly on the video?”).
- Different – If the question doesn’t match into the usual classes however nonetheless requires processing (for instance, extra basic requests).
- When the question and captions are prepared, the system makes use of the LLM to generate solutions based mostly on the processed video and audio content material. This enables the assistant to offer correct, context-aware responses concerning the gear’s state or the following steps for decision. The generated responses information technicians by troubleshooting steps, with detailed directions on resolving the detected challenge based mostly on each the visible and audio inputs. The solutions embrace built-in guardrails to assist preserve high quality, security, and relevance in steering.
After extracting captions and audio from the video, they are often seamlessly processed utilizing the identical strategies outlined for the picture and audio modalities mentioned earlier on this submit.
The flexibility to add coaching or inspection movies, have the system analyze and summarize them, and reply to technician queries makes the chatbot a useful instrument for predictive upkeep. By combining a number of information varieties (video, audio, and pictures), the chatbot offers complete diagnostic help, considerably decreasing downtime and bettering effectivity.
Multimodal RAG for complete decision dedication
Multimodal RAG permits technicians to work together with the database of guide paperwork and former coaching recordsdata or diagnostics. By permitting for multimodality, technicians can entry not solely the textual content from manuals but additionally related diagrams or photographs that assist them diagnose and resolve points. The next screenshot showcases an instance of this performance.
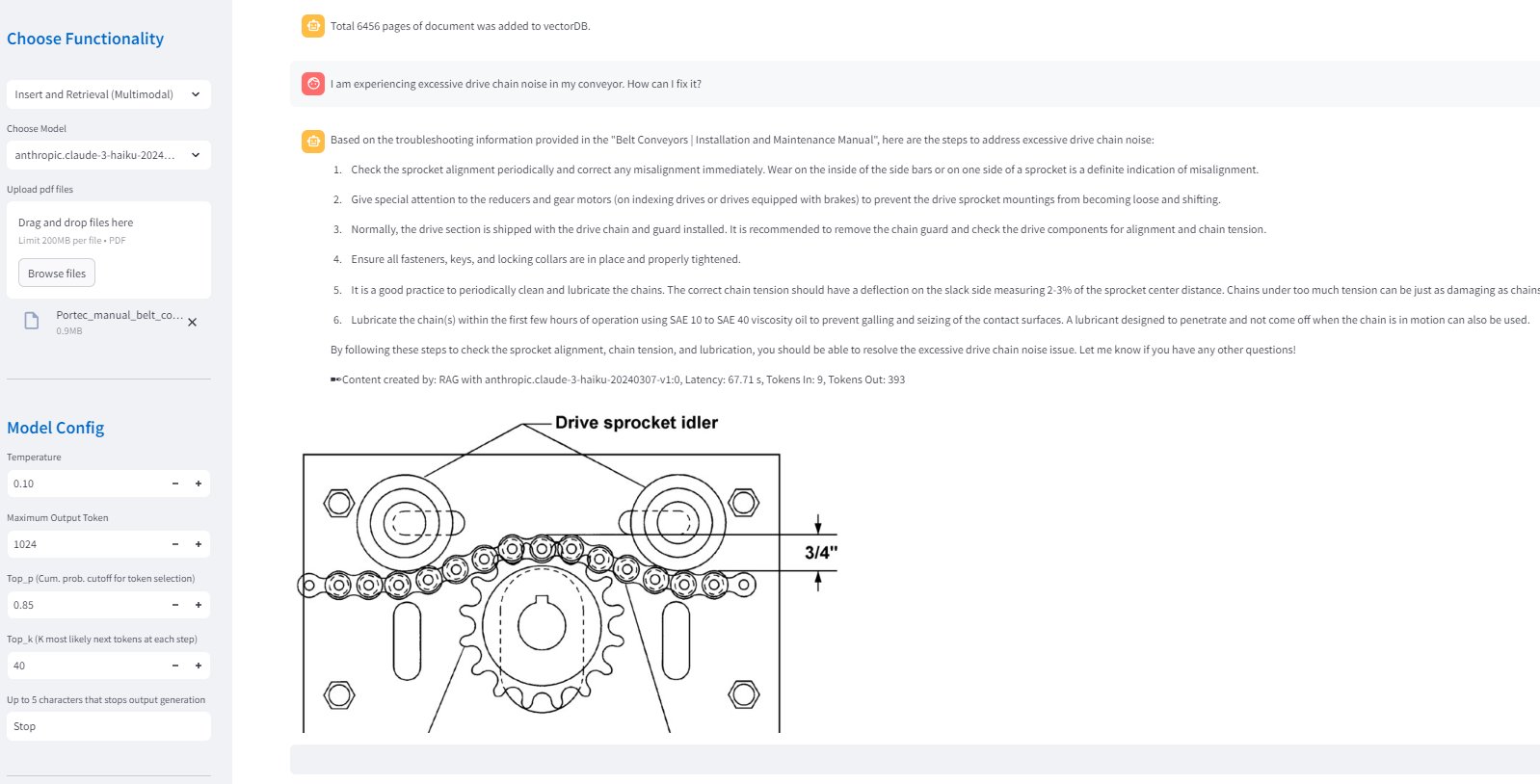
The next steps define step-by-step how the system processes each textual content and picture information to facilitate complete retrieval and response technology:
Create doc embeddings
Step one entails extracting each textual content and pictures from paperwork like PDF manuals to generate embeddings, which assist in retrieving related info later. The next diagram showcases how this course of works.
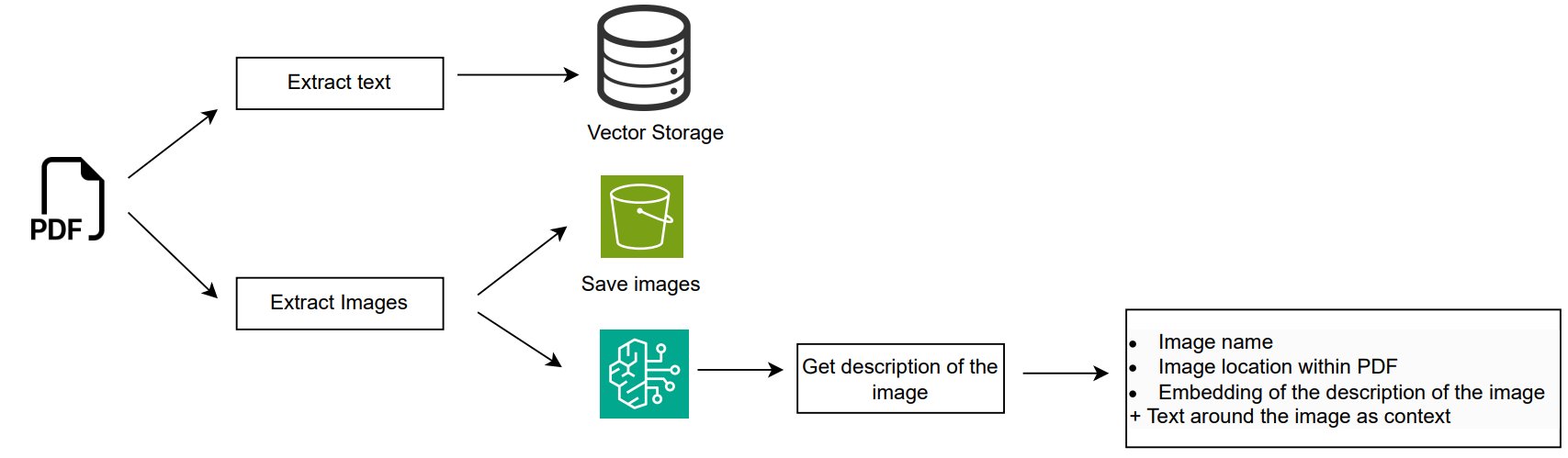
The workflow consists of the next steps:
- Textual content information is extracted from every web page of the PDF utilizing the PyMuPDF library. This enables the answer to seize each structured information (like tables) and unstructured content material for embedding. Every extracted textual content section is transformed into embeddings utilizing the Amazon Titan v2 mannequin, and saved into Amazon Bedrock Information Bases for environment friendly retrieval.
- Photos are additionally extracted from every web page of the PDF similarly, with filtering to take away small or irrelevant photographs. Every picture is processed by a multimodal LLM reminiscent of Anthropic’s Claude Sonnet 3.5 on Amazon Bedrock to generate an in depth description, which incorporates each seen parts and context from the encompassing textual content on the web page. The system saves these photographs and generates embeddings based mostly on the descriptions. The picture metadata collected consists of:
- Picture title
- Picture location throughout the PDF
- Embedding of the picture description
- Contextual textual content across the picture within the doc
By capturing not solely the picture description but additionally the encompassing contextual textual content, the system features a extra complete understanding of the picture’s relevance and which means. This method enhances retrieval accuracy and makes certain that the photographs are interpreted accurately inside their broader doc context.
Retrieval and technology
For retrieval and technology, the system differentiates between textual content and picture retrieval to be sure that each semantic textual content context and visible info are successfully integrated into the ultimate response. This method permits technicians to obtain a extra holistic reply that makes use of each written insights and visible aids, enhancing the general troubleshooting course of.
Textual content retrieval and technology
Beginning with the textual content, we use reciprocal rank fusion, a way that makes certain the retrieved outcomes are related and in addition semantically aligned with the consumer’s question. Reciprocal rank fusion operates by reworking a single consumer question into a number of associated queries generated by an LLM, every retrieving a various set of paperwork. These paperwork are reranked utilizing the reciprocal rank fusion algorithm, ensuring that crucial info is prioritized. The next diagram illustrates this course of.

The workflow consists of the next steps:
- The consumer inputs a query or question. For instance, “Why is my conveyor motor vibrating abnormally?”
- The question is shipped to an LLM together with a immediate to generate a number of associated search queries. By producing these associated queries, the system offers complete retrieval of data. For instance, the preliminary consumer question could be divided into:
- Question 1: “What are attainable causes of irregular vibrations in conveyor belts?”
- Question 2: “What are some steps for conveyor motor troubleshooting for prime vibration ranges?”
- Question 3: “What are the vibration thresholds and alarm settings for conveyor techniques?”
- Question 4: “What’s the upkeep historical past of conveyor motors with vibration points?”
- The generated queries are despatched to a semantic search retriever to search out the related doc from the vector database. For every question, the retriever produces a ranked checklist of related paperwork based mostly on embedding’s similarity.
- The ranked outcomes are reranked utilizing the reciprocal rank fusion (RRF) components (see the next determine). For each question q within the set Q, the components evaluates how nicely a doc d ranks for that particular question (represented as rq(d)). The addition of the fixed ok helps management the affect of particular person queries on the general rating, as a result of it helps forestall a single question from having a disproportionately massive affect on the ultimate rating, offering a extra balanced contribution from the associated queries. The scores are added up. Which means if a doc d ranks extremely throughout a number of associated queries, it receives the next RRF rating.

- The generative mannequin makes use of the top-ranked paperwork to supply the ultimate reply, offering steering on diagnosing the foundation reason behind irregular vibrations within the conveyor belt.
Picture retrieval and technology
The system follows a separate retrieval course of for image-based queries, ensuring that visible info can also be integrated into the response. The next determine exhibits how this course of works.

The workflow consists of the next steps:
- When the consumer inputs a question, the system first converts this question into an embedding, which is a numerical illustration that captures the semantic which means of the question. This embedding serves as a reference level to establish associated picture descriptions.
- The system calculates the cosine similarity between the immediate embedding (created within the earlier step) and the embeddings of picture descriptions saved within the database to retrieve essentially the most related photographs. For this instance, a question about conveyor motor vibrations, related photographs may embrace diagrams of motor parts, visible representations of vibration patterns, or photographs depicting gear misalignment.
- After calculating the similarity scores, the system filters the outcomes to retain solely photographs which have a sufficiently excessive rating. The edge for this filtering is about empirically to 0.4 to be sure that solely essentially the most related photographs, that are intently aligned with the consumer’s question, are thought of for additional evaluation. This step helps forestall the inclusion of irrelevant or marginally associated photographs, sustaining the accuracy of the response.
The steps described above are carried out within the following code snippet, which demonstrates the way to course of image-based queries for retrieval and relevance scoring:
- The ultimate step entails utilizing the filtered set of photographs to contribute to the reply technology. Within the case of diagnosing irregular vibrations in a conveyor motor, the system may embrace diagrams of potential failure modes or visible guides for troubleshooting steps alongside the textual rationalization.
Conclusion
The implementation of a generative AI-powered assistant for predictive upkeep is anticipated to enhance diagnostics by providing mechanics clear, actionable steering when an alarm is triggered, considerably decreasing the incidence of undetermined root causes. This enchancment may also help mechanics extra confidently and precisely handle gear points, enhancing their capacity to behave promptly and successfully.
By streamlining diagnostics and offering focused troubleshooting suggestions, this answer cannot solely reduce operational delays but additionally promote higher gear reliability and scale back downtime at Amazon’s achievement facilities. Moreover, the assistant’s adaptable design makes it appropriate for broader predictive upkeep functions throughout numerous industries, from manufacturing to logistics and healthcare. Although initially developed for Amazon’s achievement facilities, the answer has the potential to scale past the Amazon setting, providing a flexible, AI-driven method to enhancing gear reliability and efficiency.
Future enhancements may additional prolong the answer’s affect, together with increasing retrieval capabilities to embody movies alongside photographs, coaching an clever agent to advocate optimum subsequent steps based mostly on profitable previous diagnoses, and implementing automated job project options that dynamically generate work orders, specify sources, and assign duties based mostly on diagnostic outcomes. Enhancing the answer’s intelligence to help a broader vary of predictive upkeep eventualities may make it extra versatile and impactful throughout various industries.
Take step one towards reworking your upkeep operations by exploring these superior capabilities – contact us immediately to find out how these improvements can drive effectivity and reliability in your group.
Concerning the authors
 Carla Lorente is a Senior Gen AI Lead at AWS, serving to inside groups remodel advanced processes into environment friendly, AI-powered workflows. With twin levels from MIT—a MS in Pc Science and an MBA—Carla operates on the intersection of engineering and technique, translating cutting-edge AI into scalable options that drive measurable affect throughout AWS.
Carla Lorente is a Senior Gen AI Lead at AWS, serving to inside groups remodel advanced processes into environment friendly, AI-powered workflows. With twin levels from MIT—a MS in Pc Science and an MBA—Carla operates on the intersection of engineering and technique, translating cutting-edge AI into scalable options that drive measurable affect throughout AWS.
 Yingwei Yu is an Utilized Science Supervisor at Generative AI Innovation Heart, AWS, the place he leverages machine studying and generative AI to drive innovation throughout industries. With a PhD in Pc Science from Texas A&M College and years of working expertise, Yingwei brings in depth experience in making use of cutting-edge applied sciences to real-world functions.
Yingwei Yu is an Utilized Science Supervisor at Generative AI Innovation Heart, AWS, the place he leverages machine studying and generative AI to drive innovation throughout industries. With a PhD in Pc Science from Texas A&M College and years of working expertise, Yingwei brings in depth experience in making use of cutting-edge applied sciences to real-world functions.
 Parth Patwa is a Information Scientist within the Generative AI Innovation Heart at Amazon Internet Companies. He has co-authored analysis papers at high AI/ML venues and has 1500+ citations.
Parth Patwa is a Information Scientist within the Generative AI Innovation Heart at Amazon Internet Companies. He has co-authored analysis papers at high AI/ML venues and has 1500+ citations.
 Aude Genevay is a Senior Utilized Scientist on the Generative AI Innovation Heart, the place she helps prospects deal with essential enterprise challenges and create worth utilizing generative AI. She holds a PhD in theoretical machine studying and enjoys turning cutting-edge analysis into real-world options.
Aude Genevay is a Senior Utilized Scientist on the Generative AI Innovation Heart, the place she helps prospects deal with essential enterprise challenges and create worth utilizing generative AI. She holds a PhD in theoretical machine studying and enjoys turning cutting-edge analysis into real-world options.



{kind=link}