In Half 1 of this collection, we explored how Amazon’s Worldwide Returns & ReCommerce (WWRR) group constructed the Returns & ReCommerce Knowledge Help (RRDA)—a generative AI resolution that transforms pure language questions into validated SQL queries utilizing Amazon Bedrock Brokers. Though this functionality improves information entry for technical customers, the WWRR group’s journey towards actually democratized information doesn’t finish there.
For a lot of stakeholders throughout WWRR, visualizing traits and patterns is way extra worthwhile than working with uncooked information. These customers want fast insights to drive selections with out having to interpret SQL outcomes. Though we preserve pre-built Amazon QuickSight dashboards for generally tracked metrics, enterprise customers ceaselessly require assist for long-tail analytics—the power to conduct deep dives into particular issues, anomalies, or regional variations not lined by commonplace stories.
To bridge this hole, we prolonged our RRDA resolution past SQL era to incorporate visualization capabilities. On this put up, we dive into how we built-in Amazon Q in QuickSight to rework pure language requests like “Present me what number of objects had been returned within the US over the previous 6 months” into significant information visualizations. We show how combining Amazon Bedrock Brokers with Amazon Q in QuickSight creates a complete information assistant that delivers each SQL code and visible insights via a single, intuitive conversational interface—democratizing information entry throughout the enterprise.
Intent and area classification for visible analytics
The general structure diagram of the RRDA system has two components. In Half 1, we centered on the higher pathway that generates SQL; for Half 2, we discover the decrease pathway (highlighted in purple within the following diagram) that connects customers on to visible insights via Amazon Q in QuickSight.

RRDA Structure Overview highlighting the visualization pathway (proven in purple) that processes SHOW_METRIC intents via Q matter retrieval and choice to ship embedded Amazon Q in QuickSight visualizations.
As talked about in Half 1, RRDA routes consumer queries via intent and area classification techniques that decide how every request needs to be processed. When a question is assessed as SHOW_METRIC (triggered by phrases like “present me” or “show,” or questions on visualizing traits), the system routes to our Amazon Q in QuickSight integration pathway as an alternative of producing SQL. Concurrently, our area classifier identifies enterprise contexts like Returns Processing or Promotions to focus the search scope. This twin classification makes it attainable to seamlessly swap the consumer expertise between receiving code and receiving visible insights whereas sustaining enterprise context.
For instance, when a consumer asks “Present me the development for what number of objects had been returned for the previous quarter,” our system identifies each the visualization intent and the Returns Processing enterprise area, permitting subsequent LLMs to look inside domain-specific Amazon QuickSight Q matters moderately than throughout the complete catalog. After the consumer intent is assessed, RRDA notifies the consumer that it’s looking for related metrics in Amazon Q in QuickSight and initiates the domain-filtered Q matter choice course of described within the subsequent part.
Q matter retrieval and choice
After the consumer intent is assessed as SHOW_METRIC and the related enterprise area is recognized, RRDA should now decide which particular Q matter can finest visualize the requested info. Q matters are specialised configurations that allow enterprise customers to ask pure language questions on particular datasets. Every Q matter comprises metadata about out there metrics, dimensions, time durations, and synonyms—making matter choice a essential step in delivering correct visible insights. The problem lies in intelligently mapping consumer requests to probably the most applicable Q matters from our catalog of over 50 specialised configurations. To unravel this downside, RRDA employs a two-step method: first retrieving semantically related Q matters utilizing vector search with metadata filtering to slim down candidates effectively, then selecting the right matches utilizing an Amazon Bedrock basis mannequin (FM) to judge every candidate’s capability to handle the particular metrics and dimensions within the consumer’s question.
We applied this retrieval-then-selection method by constructing a devoted Q matter information base utilizing Amazon Bedrock Information Bases, a totally managed service that you should use to retailer, search, and retrieve organization-specific info to be used with massive language fashions (LLMs). The metadata for every Q matter—together with title, description, out there metrics, dimensions, and pattern questions—is transformed right into a searchable doc and embedded utilizing the Amazon Titan Textual content Embeddings V2 mannequin. When a consumer asks a query, RRDA extracts the core question intent and specified area, then performs a vector similarity search in opposition to our Q matter information base. The system applies area filters to the vector search configuration when a particular enterprise area is recognized, ensuring that solely related Q matters are thought of. From this retrieved record, a light-weight Amazon Bedrock FM analyzes the candidates and identifies probably the most related Q matter that may handle the consumer’s particular query, contemplating components like metric availability, dimension assist, and question compatibility.
The next diagram illustrates the Q matter retrieval and choice workflow.

Q matter retrieval and choice workflow illustrating how RRDA identifies related visualization sources via vector search, then optimizes consumer questions for Amazon Q in QuickSight utilizing Amazon Bedrock.
Persevering with our earlier instance, when a consumer asks “Present me the development for what number of objects had been returned for the previous quarter,” our system first detects the intent as SHOW_METRIC, then determines whether or not a website like Returns Processing or Promotions is specified. The question is then handed to our Q matter retrieval perform, which makes use of the Retrieve API to seek for Q matters with related metadata. The search returns a ranked record of 10 candidate Q matters, every containing details about its capabilities, supported metrics, and visualization choices.
This retrieval mechanism solves a essential downside in enterprise enterprise intelligence (BI) environments—discovering which report or dataset has info to reply the consumer’s query. Fairly than requiring customers to know which of our greater than 50 Q matters to question, our system robotically identifies the related Q matters primarily based on semantic understanding of the request. This clever Q matter choice creates a frictionless expertise the place enterprise customers can concentrate on asking questions in pure language whereas RRDA handles the complexity of discovering the proper information sources behind the scenes.
Query rephrasing for optimum Q matter outcomes
After RRDA identifies related Q matters, we face one other essential problem: bridging the hole between how customers naturally ask questions and the optimum format that Amazon Q in QuickSight expects. With out this significant step, even with the proper Q matter chosen, customers would possibly obtain suboptimal visualizations.
The query rephrasing problem
Enterprise customers categorical their information wants in numerous methods:
- Imprecise time frames: “What number of objects had been returned currently?”
- Complicated multi-part questions: “Examine what number of objects had been returned between NA & EU for Q1”
- Comply with-up questions: “Write a SQL question for what number of returned objects are at the moment being processed within the returns heart” and after RRDA responds with the SQL question, then “Nice! Now present me this metric for this yr”
Though Amazon Q in QuickSight is designed to deal with pure language, it’s a generative Q&A system moderately than a conversational interface, and it performs finest with clear, well-structured questions. The appropriate phrasing considerably improves response high quality by ensuring Amazon Q in QuickSight exactly understands what to visualise.
Structured query era with the Amazon Bedrock Converse API
To unravel this problem, we applied a query rephrasing system utilizing the Amazon Bedrock Converse API with structured outputs. This method makes positive consumer queries are remodeled into optimum codecs for Amazon Q in QuickSight whereas preserving essential filters and parameters.
First, we outline Pydantic information fashions to construction the FM output:
The Converse API software use functionality makes it attainable to construction responses utilizing these outlined information fashions so our code can parse them reliably. Our system passes the consumer question, dialog historical past, and retrieved Q matter metadata to the Amazon Bedrock FM, which formulates questions following validated patterns:
- “Present me the [specific metric(s)] for/over [user filters]”
- “How has [specific metric] modified from [start time frame] to [end time frame]?”
- “Examine [metric A] to [metric B] for [time frame]”
- “What’s [specific metric] for [user filters]?”
These codecs persistently produce optimum leads to Amazon Q in QuickSight throughout our enterprise domains whereas preserving essential enterprise context—together with domain-specific terminology, time filters, dimensional constraints, and comparative components. For instance, after reviewing SQL outcomes for a decision index metric, a consumer would possibly ask the follow-up query “Now present me how this metric trended during the last 6 months,” which our system rephrases to “Present me how the decision index trended during the last 6 months” whereas deciding on solely Amazon Q matters associated to the Returns Processing enterprise area.
Embedding Amazon Q in QuickSight visualizations inside the chat interface
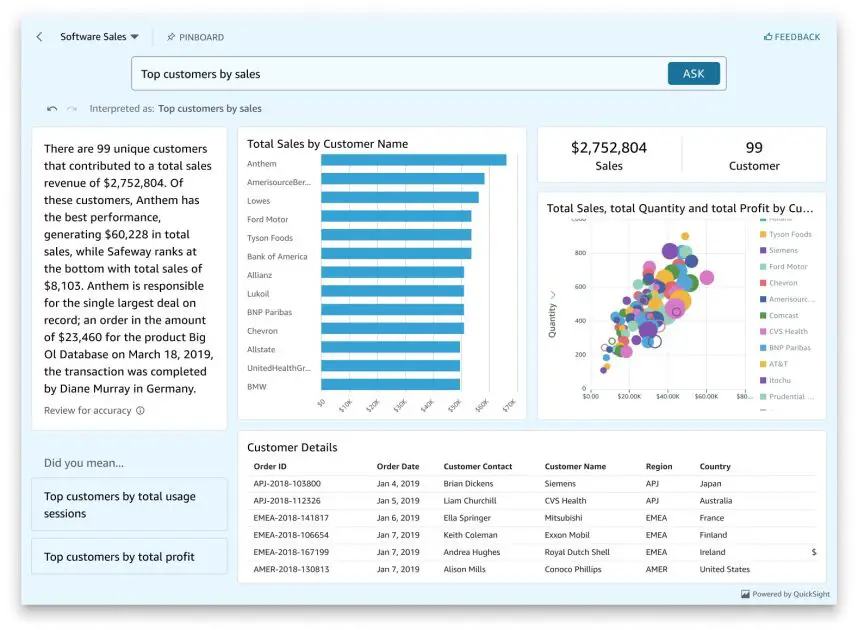
When customers ask to visualise information within the RRDA chat interface, the system seamlessly embeds Amazon Q in QuickSight instantly inside the dialog. Utilizing the QuickSight embedding performance, RRDA generates a safe embedding URL that renders interactive visualizations instantly within the chat window. Customers can view information visualizations with out leaving the dialog circulation. The system robotically selects the suitable Q matter and rephrases the consumer’s query for optimum outcomes, then passes this info to the embedded QuickSight part, which generates and shows the visualization. The next screenshot exhibits a view (with pattern information) of what this embedded expertise appears to be like like. For detailed details about the embedding capabilities used, see Embedding the Amazon Q in QuickSight Generative Q&A expertise.

Pattern Q Matter displaying embedded visualization capabilities inside RRDA’s chat interface, demonstrating how customers can seamlessly transition from pure language inquiries to interactive information visualizations.
Direct Q matter solutions for visualization requests
When customers ask visualization-oriented questions with the SHOW_METRIC intent (for instance, “Present me what number of objects had been returned over the previous 3 months”), RRDA presents related Q matters as interactive suggestion playing cards inside the dialog circulation. Every suggestion contains the subject title (like “Returns Processing – Pattern Matter”), together with an optimized query format that the consumer can select to instantly generate the visualization.

These solutions seem with a transparent heading: “Listed here are probably the most related questions and Amazon QuickSight Q matters:” so it’s easy for customers to establish which information supply will finest reply their query. The system codecs these solutions as clickable prompts that, when chosen, robotically set off the embedded Amazon QuickSight generative Q&A modal illustrated within the earlier part.
Contextual follow-up visualizations in conversations
RRDA proactively suggests related visualizations even when customers are engaged in common textual content conversations with the Amazon Bedrock agent described in Half 1. For instance, when a consumer asks for details about a particular metric (“What’s the decision index metric? Clarify it to me in 1-2 sentences”), the system gives a textual content clarification (which is blurred out within the following screenshot) but in addition robotically identifies alternatives for visible evaluation. These solutions seem as “Get associated insights from Amazon Q in QuickSight:” adopted by related questions like “What’s decision index for the final 3 months?” This creates a seamless bridge between studying about metrics and visualizing them—customers can begin with easy queries about metric definitions and rapidly transition to information exploration with out reformulating their requests. This contextual consciousness makes positive customers uncover worthwhile visualizations they may not have in any other case identified to request, enhancing the general analytics expertise.

Automating Q matter metadata administration
Behind RRDA’s capability to counsel related visualizations is a information base of over 50 Q matters and their metadata. To maintain this information base up-to-date as our analytics panorama grows, we’ve applied an automatic metadata administration workflow utilizing AWS Step Capabilities that refreshes each day, pictured within the following diagram.

Automated Q matter metadata administration workflow utilizing AWS Step Capabilities that refreshes each day to maintain the information base present with the newest QuickSight Q matter configurations and validated questions.
The workflow begins with our FetchQTopicMetadata AWS Lambda perform, which connects to QuickSight and gathers important details about every Q matter—what metrics it tracks, what filters customers can apply, and importantly, what questions it has efficiently answered prior to now. We particularly use the DescribeTopic and ListTopicReviewedAnswers APIs, and retailer the ensuing metadata in Amazon DynamoDB, a NoSQL key-value database. This creates a strong suggestions loop—when Q matter authors evaluation and validate questions from customers, these validated questions are robotically integrated into our information base, ensuring the system constantly learns from consumer interactions and skilled curation.
For the following step within the workflow, the BatchSummarizeQTopics perform generates a concise abstract of this collected metadata utilizing Amazon Bedrock FMs. This step is important as a result of uncooked Q matter configurations usually exceed token limits for context home windows in FMs. The perform extracts important info—metrics, measures, dimensions, and instance questions—into compact summaries that may be successfully processed throughout vector retrieval and query formulation.
The ultimate step in our workflow is the SyncQTopicsKnowledgeBase perform, which transforms this enriched metadata into vector-searchable paperwork, one for every Q matter with express enterprise area tags that allow domain-filtered retrieval. The perform triggers Amazon Bedrock information base ingestion to rebuild vector embeddings (numerical representations that seize semantic that means), finishing the cycle from Q matter configuration to searchable information property. This pipeline makes positive RRDA persistently has entry to present, complete Q matter metadata with out requiring handbook updates, considerably decreasing operational overhead whereas bettering the standard of Q matter suggestions.
Greatest practices
Based mostly on our expertise extending RRDA with visualization capabilities via Amazon Q in QuickSight, the next are some finest practices for implementing generative BI options within the enterprise:
- Anticipate analytical wants with clever solutions – Use AI to foretell what visualizations customers doubtlessly count on, robotically surfacing related charts throughout conversations about metrics or SQL. This alleviates discovery limitations and empowers customers with insights they may not have thought initially, seamlessly bridging the hole between understanding information and visualizing traits.
- Construct an computerized translation layer when connecting disparate AI techniques – Use AI to robotically reformat pure language queries into the structured patterns that techniques count on, moderately than requiring customers to be taught exact system-specific phrasing. Protect the consumer’s unique intent and context whereas ensuring every system receives enter in its most popular format.
- Design suggestions loops – Create automated techniques that acquire validated content material from consumer interactions and feed it again into your information bases. By harvesting human-reviewed questions from instruments like Amazon Q in QuickSight, your system constantly improves via higher retrieval information with out requiring mannequin retraining.
- Implement retrieval earlier than era – Use vector search with area filtering to slim down related visualization sources earlier than using generative AI to pick and formulate the optimum query, dramatically bettering response high quality and decreasing latency.
- Keep area context throughout modalities – Guarantee that enterprise area context carries via the complete consumer journey, whether or not customers are receiving SQL code or visualizations, to keep up consistency in metric definitions and information interpretation.
For complete steerage on constructing production-ready generative AI options, seek advice from the AWS Nicely-Architected Framework Generative AI Lens for finest practices throughout safety, reliability, efficiency effectivity, price optimization, operational excellence, and sustainability.
Conclusion
On this two-part collection, we explored how Amazon’s Worldwide Returns & ReCommerce group constructed RRDA, a conversational information assistant that transforms pure language into each SQL queries and information visualizations. By combining Amazon Bedrock Brokers for orchestration and SQL era with Amazon Q in QuickSight for visible analytics, our resolution democratizes information entry throughout the group. The domain-aware structure, clever query rephrasing, and automatic metadata administration alleviate limitations between enterprise questions and information insights, considerably decreasing the time required to make data-driven selections. As we proceed enhancing RRDA with extra capabilities primarily based on consumer suggestions and developments in FMs, we stay centered on our mission of making a seamless bridge between pure language questions and actionable enterprise insights.
In regards to the authors
 Dheer Toprani is a System Improvement Engineer inside the Amazon Worldwide Returns and ReCommerce Knowledge Companies workforce. He makes a speciality of massive language fashions, cloud infrastructure, and scalable information techniques, specializing in constructing clever options that improve automation and information accessibility throughout Amazon’s operations. Beforehand, he was a Knowledge & Machine Studying Engineer at AWS, the place he labored intently with prospects to develop enterprise-scale information infrastructure, together with information lakes, analytics dashboards, and ETL pipelines.
Dheer Toprani is a System Improvement Engineer inside the Amazon Worldwide Returns and ReCommerce Knowledge Companies workforce. He makes a speciality of massive language fashions, cloud infrastructure, and scalable information techniques, specializing in constructing clever options that improve automation and information accessibility throughout Amazon’s operations. Beforehand, he was a Knowledge & Machine Studying Engineer at AWS, the place he labored intently with prospects to develop enterprise-scale information infrastructure, together with information lakes, analytics dashboards, and ETL pipelines.
 Nicolas Alvarez is a Knowledge Engineer inside the Amazon Worldwide Returns and ReCommerce Knowledge Companies workforce, specializing in constructing and optimizing recommerce information techniques. He performs a key function in creating superior technical options, together with Apache Airflow implementations and front-end structure for the workforce’s net presence. His work is essential in enabling data-driven determination making for Amazon’s reverse logistics operations and bettering the effectivity of end-of-lifecycle product administration.
Nicolas Alvarez is a Knowledge Engineer inside the Amazon Worldwide Returns and ReCommerce Knowledge Companies workforce, specializing in constructing and optimizing recommerce information techniques. He performs a key function in creating superior technical options, together with Apache Airflow implementations and front-end structure for the workforce’s net presence. His work is essential in enabling data-driven determination making for Amazon’s reverse logistics operations and bettering the effectivity of end-of-lifecycle product administration.
 Lakshdeep Vatsa is a Senior Knowledge Engineer inside the Amazon Worldwide Returns and ReCommerce Knowledge Companies workforce. He makes a speciality of designing, constructing, and optimizing large-scale information and reporting options. At Amazon, he performs a key function in creating scalable information pipelines, bettering information high quality, and enabling actionable insights for Reverse Logistics and ReCommerce operations. He’s deeply keen about enhancing self-service experiences for customers and persistently seeks alternatives to make the most of generative BI capabilities to resolve complicated buyer challenges.
Lakshdeep Vatsa is a Senior Knowledge Engineer inside the Amazon Worldwide Returns and ReCommerce Knowledge Companies workforce. He makes a speciality of designing, constructing, and optimizing large-scale information and reporting options. At Amazon, he performs a key function in creating scalable information pipelines, bettering information high quality, and enabling actionable insights for Reverse Logistics and ReCommerce operations. He’s deeply keen about enhancing self-service experiences for customers and persistently seeks alternatives to make the most of generative BI capabilities to resolve complicated buyer challenges.
 Karam Muppidi is a Senior Engineering Supervisor at Amazon Retail, main information engineering, infrastructure, and analytics groups inside the Worldwide Returns and ReCommerce group. He makes a speciality of utilizing LLMs and multi-agent architectures to rework information analytics and drive organizational adoption of AI instruments. He has in depth expertise creating enterprise-scale information architectures, analytics providers, and governance methods utilizing AWS and third-party instruments. Previous to his present function, Karam developed petabyte-scale information and compliance options for Amazon’s Fintech and Service provider Applied sciences divisions.
Karam Muppidi is a Senior Engineering Supervisor at Amazon Retail, main information engineering, infrastructure, and analytics groups inside the Worldwide Returns and ReCommerce group. He makes a speciality of utilizing LLMs and multi-agent architectures to rework information analytics and drive organizational adoption of AI instruments. He has in depth expertise creating enterprise-scale information architectures, analytics providers, and governance methods utilizing AWS and third-party instruments. Previous to his present function, Karam developed petabyte-scale information and compliance options for Amazon’s Fintech and Service provider Applied sciences divisions.
 Sreeja Das is a Principal Engineer within the Returns and ReCommerce group at Amazon. In her 10+ years on the firm, she has labored on the intersection of high-scale distributed techniques in eCommerce and Funds, Enterprise providers, and Generative AI improvements. In her present function, Sreeja is specializing in system and information structure transformation to allow higher traceability and self-service in Returns and ReCommerce processes. Beforehand, she led structure and tech technique of a few of Amazon’s core techniques together with order and refund processing techniques and billing techniques that serve tens of trillions of buyer requests on a regular basis.
Sreeja Das is a Principal Engineer within the Returns and ReCommerce group at Amazon. In her 10+ years on the firm, she has labored on the intersection of high-scale distributed techniques in eCommerce and Funds, Enterprise providers, and Generative AI improvements. In her present function, Sreeja is specializing in system and information structure transformation to allow higher traceability and self-service in Returns and ReCommerce processes. Beforehand, she led structure and tech technique of a few of Amazon’s core techniques together with order and refund processing techniques and billing techniques that serve tens of trillions of buyer requests on a regular basis.



{kind=link}