
Organizations deploying generative AI purposes want sturdy methods to guage their efficiency and reliability. Once we launched LLM-as-a-judge (LLMaJ) and Retrieval Augmented Era (RAG) analysis capabilities in public preview at AWS re:Invent 2024, clients used them to evaluate their basis fashions (FMs) and generative AI purposes, however requested for extra flexibility past Amazon Bedrock fashions and information bases. At present, we’re excited to announce the overall availability of those analysis options in Amazon Bedrock Evaluations, together with vital enhancements that make them totally environment-agnostic.
The overall availability launch introduces “convey your individual inference responses” capabilities for each RAG analysis and mannequin analysis. This implies now you can consider a RAG system or mannequin—whether or not working on Amazon Bedrock, different cloud suppliers, or on premises—so long as you present analysis information within the required format. You may even consider the ultimate responses of a completely constructed utility. We’ve additionally added new quotation metrics for the already-powerful RAG analysis suite, together with quotation precision and quotation protection, that will help you higher assess how precisely your RAG system makes use of retrieved data. These metrics present deeper insights into whether or not responses are correctly grounded within the supply paperwork and in the event that they’re utilizing probably the most related retrieved passages.
On this publish, we discover these new options intimately, displaying you find out how to consider each RAG methods and fashions with sensible examples. We display find out how to use the comparability capabilities to benchmark totally different implementations and make data-driven selections about your AI deployments. Whether or not you’re utilizing Amazon Bedrock or different environments to your generative AI purposes, these analysis instruments may also help you optimize efficiency and promote high quality throughout your whole generative AI portfolio.
What’s new: RAG analysis
On this part, we focus on what’s new with RAG analysis, together with the introduction of Carry Your Personal Inference responses for evaluating exterior RAG methods and new quotation metrics that measure precision and protection of RAG citations.
Carry Your Personal Inference responses
The RAG analysis capabilities have been considerably expanded to permit analysis of outputs from RAG methods hosted wherever by the analysis surroundings in Amazon Bedrock. With Carry Your Personal Inference (BYOI) responses, now you can consider retrieval and technology outcomes from a wide range of sources, together with different FM suppliers, custom-build RAG methods, or deployed open-weights options, by offering the outputs within the required format. Moreover, the introduction of recent quotation metrics with our beforehand launched high quality and accountable AI metrics additionally offers deeper insights into how nicely RAG methods use their information bases and supply paperwork.
When evaluating retrieval outcomes from a information base, we enable one information base to be evaluated per analysis job. For each dataset entry, you’ll be able to present an inventory of dialog turns. Every dialog flip at present has a immediate and referenceResponses. When utilizing BYOI, you could present your retrieval leads to a brand new discipline known as output (this discipline is required for BYOI jobs however optionally available and never wanted for non-BYOI jobs). You have to present a knowledgeBaseIdentifier for each output. Moreover, for each retrieval outcome you convey, you’ll be able to present a reputation and extra metadata within the type of key-value pairs. The next is the enter JSONL format for RAG analysis jobs (Retrieve). Fields marked with ? are optionally available.
Within the public preview interval that ended March 20, 2025, the next dataset format contained a key known as referenceContexts. This discipline has now been modified to referenceResponses to align with the Retrieve and Generate analysis. The content material of referenceResponses ought to be the anticipated floor reality reply that an end-to-end RAG system would have generated given the immediate, not the anticipated passages or chunks retrieved from the information base.
When evaluating retrieval and technology outcomes from a information base or RAG system, we enable one information base (RAG system) to be evaluated per analysis job. For each dataset entry, you’ll be able to present an inventory of dialog turns. Every dialog flip has a immediate and referenceResponses. When utilizing BYOI, you could present the generated textual content, retrieved passages (for instance, retrieval outcomes), and citations for the generated textual content in a brand new discipline known as output (this discipline is required for BYOI jobs however optionally available and never wanted for non-BYOI jobs). The citations discipline can be utilized by the quotation metrics. For those who don’t have citations, you’ll be able to enter dummy information in these fields and ensure to not choose the quotation precision or quotation protection metrics for the analysis job. You have to additionally present a knowledgeBaseIdentifier for each output you convey. This knowledgeBaseIdentifier ought to be the identical for all traces within the dataset and in addition on the job degree. The next is the enter JSONL format for RAG analysis jobs (Retrieve and Generate). Fields marked with ? are optionally available.
Quotation metrics
Quotation precision measures how precisely a RAG system cites its sources by evaluating whether or not the cited passages really include data used within the response. This metric helps determine when responses embody pointless or irrelevant citations—a typical subject the place fashions would possibly cite passages that weren’t really used to generate the response content material. The metric produces a rating between 0–1, the place 1 signifies good quotation precision (all cited passages have been related and used within the response), and 0 signifies full imprecision (not one of the cited passages ought to have been used). This helps groups determine and repair instances the place their RAG methods are citing passages indiscriminately somewhat than selectively citing solely the passages that contributed to the response.
Quotation protection evaluates how nicely a response’s content material is supported by its citations, specializing in whether or not all data derived from retrieved passages has been correctly cited. This metric works by evaluating the faithfulness of the response to each the cited passages and the complete set of retrieved passages, then calculating their ratio. In instances the place the response is totally untrue to the retrieved passages (for instance, hallucination), the metric signifies that quotation protection evaluation isn’t relevant. The metric offers a rating from 0–1, the place scores nearer to 0 point out that the mannequin did not cite related supporting passages, and scores nearer to 1 recommend correct quotation of knowledge from the retrieved passages. Importantly, an ideal rating of 1 doesn’t essentially imply all data within the response is cited—somewhat, it signifies that every one data that would have been cited (primarily based on the retrieved passages) was correctly cited. This helps groups determine when their RAG methods are lacking alternatives to quote related supply materials.
What’s new: Mannequin analysis
On this part, we focus on what’s new with mannequin analysis, together with expanded Carry Your Personal Inference capabilities that permit you to consider mannequin responses from exterior suppliers and deployed options by each LLMaaJ and human analysis workflows.
Carry Your Personal Inference responses
The mannequin analysis capabilities have been considerably expanded to permit analysis of outputs from the fashions accessible by the Amazon Bedrock analysis surroundings. With BYOI responses, now you can consider mannequin responses from different FM suppliers or deployed options by offering the outputs within the required format. BYOI is accessible for each LLMaJ and human analysis workflows.
You don’t must restrict these evaluations to basis fashions. As a result of BYOI analysis takes within the immediate and the output, it could possibly consider the ultimate response of a full utility in the event you select to convey that into your dataset.
When utilizing LLMaaJ, just one mannequin could be evaluated per analysis job. Consequently, you could present only a single entry within the modelResponses checklist for every analysis, although you’ll be able to run a number of analysis jobs to match totally different fashions. The modelResponses discipline is required for BYOI jobs, however not wanted for non-BYOI jobs. The next is the enter JSONL format for LLMaaJ with BYOI. Fields marked with ? are optionally available.
When utilizing human analysis, as much as two fashions could be evaluated per analysis job. Consequently, you’ll be able to present as much as two entries within the modelResponses checklist, with every response requiring a singular identifier. The modelResponses discipline is required for BYOI jobs however not wanted for non-BYOI jobs. The next is the enter JSONL format for human analysis with BYOI. Fields marked with ? are optionally available.
Function overview
The LLMaaJ analysis workflow with BYOI lets you systematically assess mannequin outputs out of your most popular supply utilizing Amazon Bedrock mannequin analysis capabilities. The method follows an easy move, beginning with deciding on an evaluator mannequin and configuring BYOI, then selecting acceptable metrics, importing your analysis datasets, working the evaluation, and at last analyzing the detailed outcomes. This complete analysis pipeline (as illustrated within the following diagram) helps present constant high quality throughout your AI implementations, no matter the place they’re deployed.

For RAG system analysis, the workflow incorporates extra elements and metrics particular to context retrieval evaluation. The method begins with selecting an evaluator mannequin, then deciding on between retrieval-only or retrieve-and-generate analysis modes. With BYOI assist, you’ll be able to consider RAG outputs from any supply whereas utilizing {powerful} LLMaaJ metrics to evaluate the standard of your retrievals or full end-to-end retrieve-and-generate move of your RAG system. This end-to-end analysis framework (see the next diagram) offers deep insights into how successfully your RAG system makes use of its retrieved context and generates correct, well-supported responses.

Conditions
To make use of the LLMaaJ mannequin analysis and RAG analysis options with BYOI, you could have the next stipulations:
Dataset description and preparation
For demonstrating an LLMaaJ analysis job with BYOI, we created a purchasing math issues dataset with a third-party mannequin. The dataset incorporates 30 low cost calculation issues, every with a immediate, reference reply, and mannequin response following the required BYOI format. Every file makes use of the "third-party-model" identifier within the modelResponses array, enabling the LLMaaJ evaluator to evaluate response high quality in opposition to your chosen metrics.
The dataset we used for a RAG analysis job with BYOI was created utilizing Amazon’s 10-Ok SEC submitting data. Every file within the dataset incorporates questions on Amazon’s company data (akin to SEC file numbers, working segments, and monetary 12 months reporting), reference responses, and third-party model-generated solutions with their corresponding retrieved passages and citations. The dataset follows the required BYOI format, with every file utilizing "third-party-RAG" because the information base identifier. This construction permits analysis of each retrieve and generate high quality metrics and quotation accuracy, demonstrating how organizations can assess RAG methods no matter the place they’re deployed.
Begin an LLMaaJ analysis job with BYOI utilizing the Amazon Bedrock console
On this first instance, we use the immediate and inference responses dataset printed in our amazon-bedrock-samples repository. You should utilize LLMaaJ with BYOI responses on Amazon Bedrock mannequin analysis to evaluate mannequin efficiency by a user-friendly AWS Administration Console interface. Observe these steps to begin an analysis job:
- On the Amazon Bedrock console, select Inference and Evaluation within the navigation pane after which select Evaluations.
- On the Evaluations web page, select the Fashions
- Within the Mannequin evaluations part, select Create and select Computerized: Mannequin as a decide.

- On the Create computerized analysis web page, enter a reputation and outline and underneath Analysis mannequin, choose a mannequin. This mannequin can be used as a decide to guage your inference responses.

- Optionally, select Tags, and create your individual tags.
- Below Inference supply, select Carry your individual inference responses because the inference supply.
- For Supply title, enter a reputation that’s the similar because the
modelIdentifierin your immediate and inference response dataset.
- Below Metrics, choose the metrics you wish to use to guage the mannequin response (akin to helpfulness, correctness, faithfulness, relevance, and harmfulness).

- Below Datasets, for Select a immediate dataset and Analysis outcomes, enter or select the Browse S3 choice to enter the S3 URI.
- Below Amazon Bedrock IAM position – Permissions, choose or create an IAM service position with the correct permissions. This consists of service entry to Amazon Bedrock, the S3 buckets within the analysis job, and the fashions getting used within the job. For those who create a brand new IAM position within the analysis setup, the service will robotically give the position the correct permissions for the job.
- Specify the folder within the S3 bucket the place the outcomes of the mannequin analysis can be saved and select Create.
There’s an enter dataset validator that validates that the format of the enter immediate dataset is appropriate while you select Create. It’s going to make it easier to appropriate any formatting errors.

It is possible for you to to see the analysis job is In Progress. Watch for the job standing to alter to Full. This may occasionally take minutes or hours relying on how lengthy your prompts and responses are and in the event you used just a few prompts or tons of of prompts.
- When the job is full, select the job to see its particulars and metrics abstract.

- To view technology metrics particulars, scroll down within the mannequin analysis report and select one of many particular person metrics (like helpfulness or correctness) to see its detailed breakdown.

- To see every file’s immediate enter, technology output (from convey your individual inference responses), floor reality (which is optionally available), and particular person scores, select a metric and select Immediate particulars.
- Hover over a person rating to view its detailed rationalization.

Begin an LLMaaJ analysis job with BYOI utilizing the Python SDK and APIs
To make use of the Python SDK for creating an LLMaaJ mannequin analysis job with your individual inference responses, use the next steps.
- Arrange the required configurations:
- Use the next operate to create an LLMaaJ mannequin analysis job with your individual inference responses. The
precomputedInferenceSourceparameter is used while you’re bringing your individual pre-generated inference responses. TheinferenceSourceIdentifierworth should match the mannequin identifier you utilized in your analysis dataset. This identifier represents the mannequin that generated the responses you wish to consider. - Use the next code to create an LLMaaJ analysis job, specifying the evaluator mannequin and configuring all obligatory parameters akin to enter dataset location, output path, and job kind. The job configuration creates an analysis job that can assess your mannequin inference responses, with outcomes being saved within the designated S3 bucket for later evaluation.
- Monitor the progress of your analysis job:
Begin a RAG analysis job with BYOI utilizing the Amazon Bedrock console
When coping with RAG methods, it’s vital to guage the standard of retrieval and retrieval and technology collectively. We already present a number of vital metrics for these workflows, and now it’s also possible to consider the quotation high quality of your RAG methods. You may embody citations when utilizing Amazon Bedrock Information Bases. On this part, we discover how you should use a RAG analysis job to floor two vital quotation metrics. In case your {custom} RAG system makes use of citations, it’s also possible to plug your quotation data into your enter dataset with BYOI and use the quotation precision and quotation protection metrics:
Greatest observe is to make use of each quotation metrics, quotation precision and quotation protection, collectively to present a whole view of the quotation high quality.

To get began utilizing the console, full the next steps:
- On the Amazon Bedrock console, underneath Inference and Assessments within the navigation pane, select Evaluations.
- Select the RAG.
- Select Create. It will take you to a brand new web page the place you’ll be able to arrange your RAG analysis job.

- Below Analysis particulars, enter a reputation and outline and select an Evaluator mannequin. Within the instance, we selected Claude 3 Haiku for demonstration, however we offer a selection of a number of decide fashions for flexibility. This mannequin can be used as a decide to guage your inference responses.

- Below Inference supply, select Carry your individual inference responses because the inference supply.
- For Supply title, enter a reputation that’s the similar because the
modelIdentifierin your immediate and inference response dataset. For instance, the next is a snippet of 1 file in our analysis dataset:
Due to this fact, we use the supply title third-party-RAG.
- Below Metrics, choose the quotation metrics Quotation precision and Quotation protection. You may also choose different metrics.

- Below Dataset and analysis outcomes S3 location, select Browse S3 to enter the S3 URI for the analysis enter file, and specify the output location.
- Below Amazon Bedrock IAM position – Permissions, create a brand new service position or use an present one.
- Select Create.

For those who see an error within the S3 URI, akin to, “Your S3 bucket doesn’t have the required CORS settings,” then you definitely would possibly have to edit your CORS setting on the bucket that has your information. For extra data, see Required Cross Origin Useful resource Sharing (CORS) permissions on S3 buckets.

You may monitor your job; the standing can be In progress whereas the job is working.

- When the job standing is Accomplished, you’ll be able to observe the hyperlink on a accomplished job to overview outcomes.

The outcomes embody a Metric abstract part. On this specific instance, each quotation precision and quotation protection are excessive.
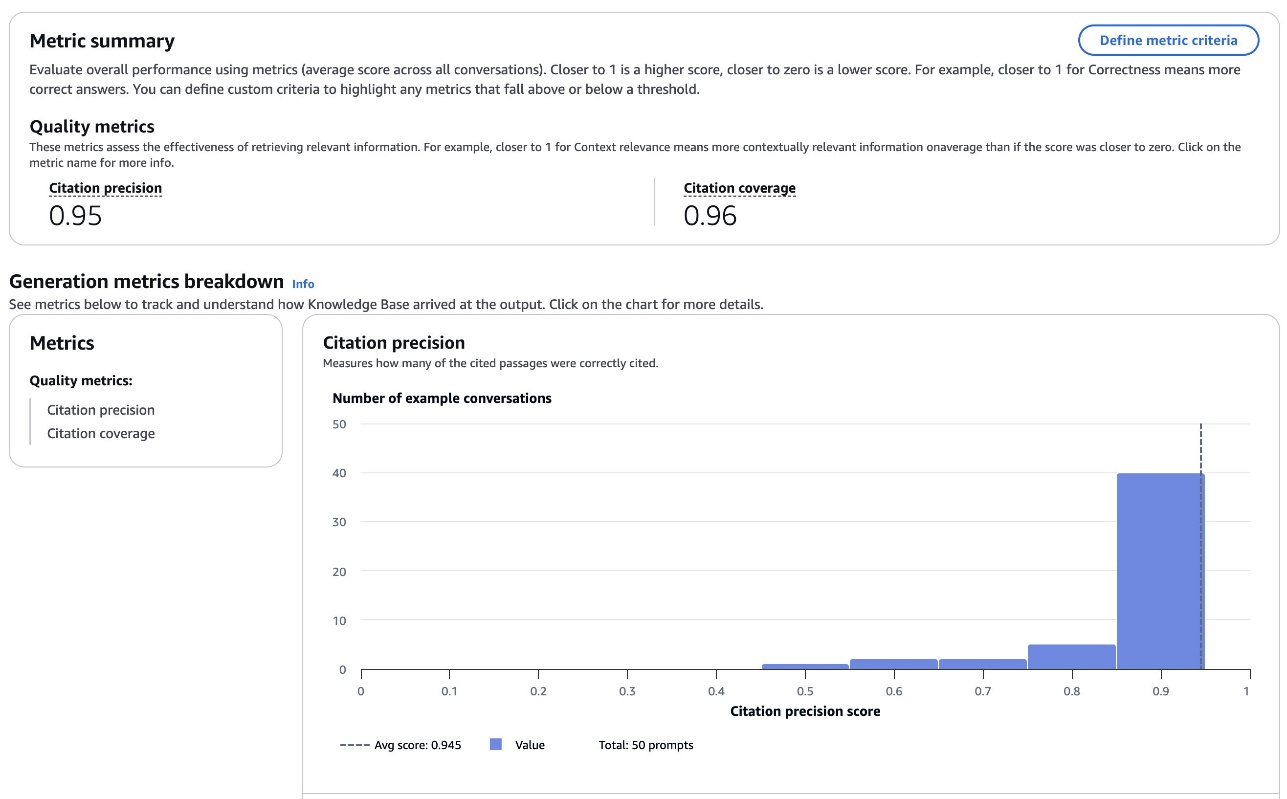
You may also set metric standards to ensure the RAG system is performing as much as your requirements, and consider instance conversations as proven under every metric.

Begin a RAG analysis job with BYOI utilizing the Python SDK and APIs
To make use of the Python SDK for creating an RAG analysis job with your individual inference responses, observe these steps (or seek advice from our instance pocket book):
- Arrange the required configurations, which ought to embody your mannequin identifier for the evaluator, IAM position with acceptable permissions, S3 paths for enter information containing your inference responses, and output location for outcomes:
- Use the next operate to create a RAG analysis job with your individual pre-generated retrieval and technology responses. The
precomputedRagSourceConfigparameter is used while you’re bringing your individual pre-generated RAG responses for analysis. TheragSourceIdentifierworth should match the identifier you utilized in your analysis dataset. This identifier represents the RAG system that produced the responses you wish to consider. The code units up an automatic analysis that can assess varied dimensions of your RAG system’s efficiency, together with correctness, completeness, helpfulness, logical coherence, faithfulness, and quotation high quality in opposition to the supplied dataset.
- After submitting the analysis job, you’ll be able to verify its standing utilizing the
get_evaluation_jobtechnique and retrieve the outcomes when the job is full. The output can be saved on the S3 location specified within theoutput_pathparameter, containing detailed metrics on how your RAG system carried out throughout the analysis dimensions.
Clear up
To keep away from incurring future fees, delete the S3 bucket, pocket book situations, and different assets that have been deployed as a part of the publish.
Conclusion
The overall availability launch of LLM-as-a-judge and RAG analysis on Amazon Bedrock brings environment-agnostic “convey your individual inference” capabilities, permitting organizations to guage RAG methods or fashions no matter the place it runs. New quotation metrics launched as a part of the RAG analysis metrics checklist improve data high quality evaluation by offering measurements of quotation precision and protection, enabling data-driven comparisons throughout totally different implementations.
As organizations deploy extra generative AI purposes, sturdy analysis turns into crucial to sustaining high quality, reliability, and accountable use. We encourage you to discover these new options by the Amazon Bedrock console and the examples supplied within the AWS Samples GitHub repository. By implementing common analysis workflows, you’ll be able to constantly enhance your fashions and RAG methods to ship the best high quality outputs to your particular use instances.
We encourage you to discover these capabilities of Amazon Bedrock Evaluations and uncover how systematic analysis can improve your generative AI purposes.
Concerning the authors
 Adewale Akinfaderin is a Sr. Knowledge Scientist–Generative AI, Amazon Bedrock, the place he contributes to innovative improvements in foundational fashions and generative AI purposes at AWS. His experience is in reproducible and end-to-end AI/ML strategies, sensible implementations, and serving to world clients formulate and develop scalable options to interdisciplinary issues. He has two graduate levels in physics and a doctorate in engineering.
Adewale Akinfaderin is a Sr. Knowledge Scientist–Generative AI, Amazon Bedrock, the place he contributes to innovative improvements in foundational fashions and generative AI purposes at AWS. His experience is in reproducible and end-to-end AI/ML strategies, sensible implementations, and serving to world clients formulate and develop scalable options to interdisciplinary issues. He has two graduate levels in physics and a doctorate in engineering.
 Shreyas Subramanian is a Principal Knowledge Scientist and helps clients by utilizing generative AI and deep studying to resolve their enterprise challenges utilizing AWS companies. Shreyas has a background in large-scale optimization and ML and in using ML and reinforcement studying for accelerating optimization duties.
Shreyas Subramanian is a Principal Knowledge Scientist and helps clients by utilizing generative AI and deep studying to resolve their enterprise challenges utilizing AWS companies. Shreyas has a background in large-scale optimization and ML and in using ML and reinforcement studying for accelerating optimization duties.
 Jesse Manders is a Senior Product Supervisor on Amazon Bedrock, the AWS Generative AI developer service. He works on the intersection of AI and human interplay with the purpose of making and bettering generative AI services and products to satisfy our wants. Beforehand, Jesse held engineering crew management roles at Apple and Lumileds, and was a senior scientist in a Silicon Valley startup. He has an M.S. and Ph.D. from the College of Florida, and an MBA from the College of California, Berkeley, Haas College of Enterprise.
Jesse Manders is a Senior Product Supervisor on Amazon Bedrock, the AWS Generative AI developer service. He works on the intersection of AI and human interplay with the purpose of making and bettering generative AI services and products to satisfy our wants. Beforehand, Jesse held engineering crew management roles at Apple and Lumileds, and was a senior scientist in a Silicon Valley startup. He has an M.S. and Ph.D. from the College of Florida, and an MBA from the College of California, Berkeley, Haas College of Enterprise.
 Ishan Singh is a Sr. Generative AI Knowledge Scientist at Amazon Internet Providers, the place he helps clients construct progressive and accountable generative AI options and merchandise. With a robust background in AI/ML, Ishan focuses on constructing Generative AI options that drive enterprise worth. Outdoors of labor, he enjoys enjoying volleyball, exploring native bike trails, and spending time together with his spouse and canine, Beau.
Ishan Singh is a Sr. Generative AI Knowledge Scientist at Amazon Internet Providers, the place he helps clients construct progressive and accountable generative AI options and merchandise. With a robust background in AI/ML, Ishan focuses on constructing Generative AI options that drive enterprise worth. Outdoors of labor, he enjoys enjoying volleyball, exploring native bike trails, and spending time together with his spouse and canine, Beau.



{kind=link}