
Groups constructing AI brokers usually consider them the way in which they consider some other software program: by checking whether or not the output matches expectations. However brokers that autonomously select instruments and sequence operations throughout a number of sources produce habits that output-level testing can’t absolutely characterize.
An agent may ship a well-structured, actionable response whereas hallucinating, fabricating info as a result of its instruments returned empty outcomes. It may also attain the right conclusion whereas skipping the verification steps {that a} dependable course of requires. As a result of these failures sit under the floor of the ultimate response, catching them requires analysis that traces the agent’s full execution path: which instruments the agent known as, what knowledge these instruments returned, and whether or not the response faithfully displays that knowledge.
Closing this hole requires infrastructure that the majority agent groups will not be staffed to construct from scratch. You want take a look at instances with floor fact outcomes, observability instrumentation for capturing software calls and intermediate state, and metrics that assess faithfulness and power utilization alongside floor accuracy.
Agent-EvalKit is an open-source toolkit (Apache 2.0) that makes this analysis infrastructure obtainable by integrating with AI coding assistants, together with Claude Code, Kiro CLI, and Kilo Code. It brings all the workflow into your improvement setting as an alternative of treating analysis as a separate post-deployment effort. You describe your analysis objectives in pure language, and the toolkit handles every section, from studying your agent’s supply code and producing focused take a look at instances by way of operating evaluations and producing a report with enchancment suggestions that reference particular areas in your code base. The sections that observe stroll by way of how Agent-EvalKit works throughout its six analysis phases, utilizing a journey analysis agent constructed with the Strands Brokers SDK and Amazon Bedrock as a operating instance.
What agent analysis requires
Past the infrastructure itself, selecting what to measure is equally demanding. Agent high quality spans dimensions that no single metric captures: whether or not responses are grounded in what the instruments really returned, whether or not the agent known as the best instruments with the best parameters, and whether or not the ultimate output is coherent and helpful to the individual asking. A response can learn properly whereas quietly hallucinating over empty software outcomes, and an agent can arrive at a believable reply by way of a damaged sequence of software calls, so every dimension needs to be checked by itself relatively than inferred from the one subsequent to it.
No single evaluator model handles all three properly. Code-based evaluators supply quick, reproducible outcomes however penalize legitimate variations in method. Giant language mannequin (LLM) as decide evaluators present nuanced evaluation at the price of extra inference and cautious immediate design. Handiest analysis methods mix each approaches. Translating analysis scores into concrete code modifications is the place many efforts in the end stall, which is why an analysis workflow wants to finish in particular, code-level suggestions relatively than a dashboard of numbers.
How Agent-EvalKit works
Agent-EvalKit works by way of your current AI coding assistant as an alternative of operating as a separate analysis platform. Your assistant, whether or not Claude Code, Kiro CLI, or Kilo Code, turns into the analysis engine by making use of its potential to learn code and purpose about agent habits at every section of the analysis course of. You drive this workflow by way of slash instructions like /evalkit.plan and /evalkit.knowledge, appending pure language steering that tells the assistant what high quality dimensions matter most in your agent. This design retains analysis inside your improvement setting, so the identical assistant that helps you construct your agent additionally helps you consider it.
The method begins along with your agent’s supply code, the place the assistant reads software definitions, the system immediate, and framework configuration to construct an in depth mannequin of what your agent does, which instruments it could name, and the place its habits may break down. Each artifact the toolkit produces in subsequent phases, from the analysis plan by way of the ultimate report, builds on this code-level understanding.
From that basis, the assistant designs a customized analysis plan with metrics focused to your agent’s capabilities and threat areas, then works by way of subsequent phases to generate take a look at instances, instrument your agent with OpenTelemetry-compatible tracing, run every take a look at case whereas gathering structured traces, and consider the outcomes towards your standards. The method culminates in a report whose prioritized suggestions reference particular areas in your code, connecting analysis findings on to actionable fixes. In the event you direct the system to give attention to hallucinations triggered by empty software outcomes, for instance, that steering shapes take a look at case era, metric choice, and the patterns the report in the end highlights.
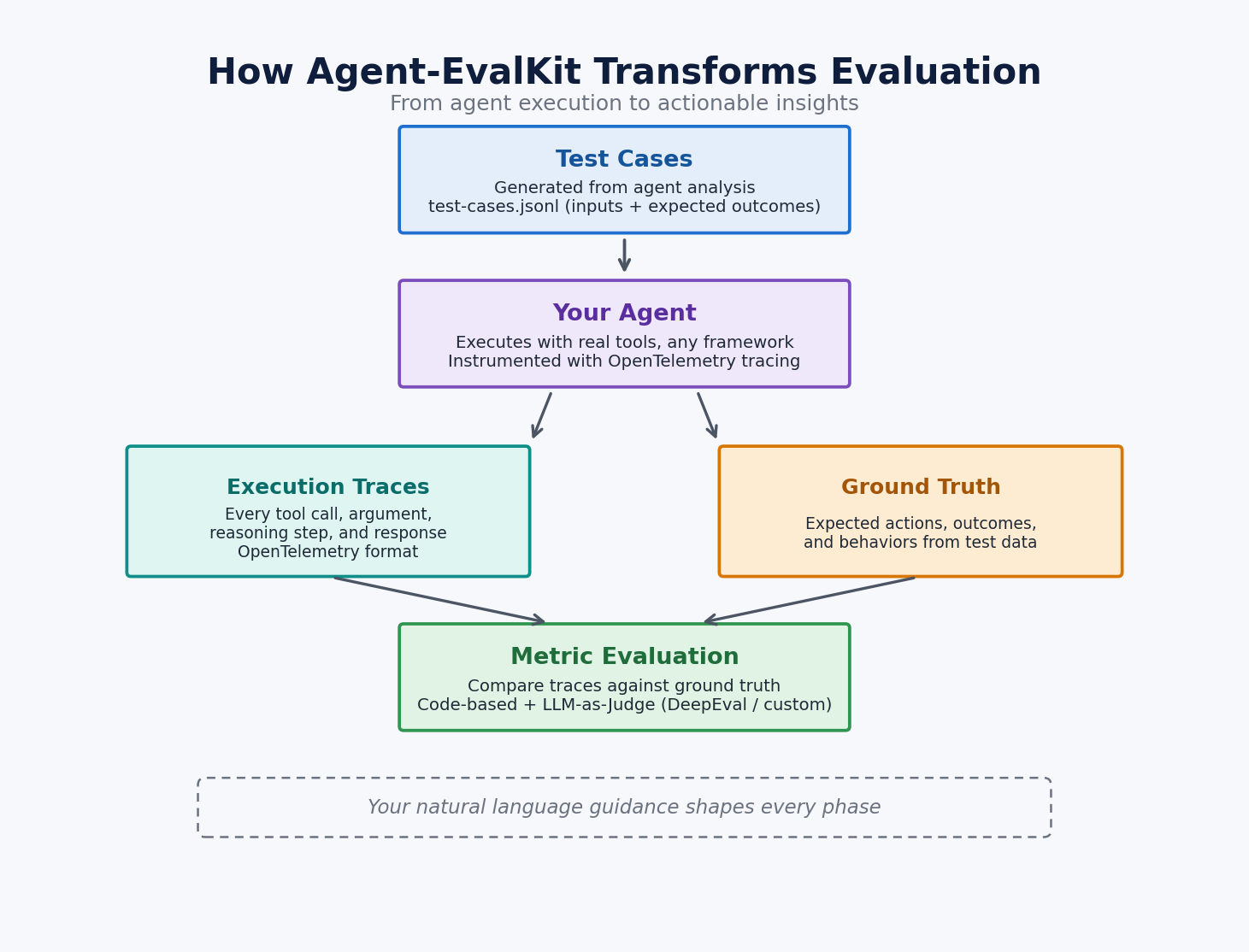
The next diagram illustrates this movement from take a look at instances by way of metric analysis.

The toolkit organizes this work into six phases, every producing artifacts within the eval/listing that feed into the subsequent section. You invoke every section by way of your AI assistant as a slash command, and the textual content after the command serves as your pure language steering for that section. As soon as the preliminary artifacts are in place, you may re-invoke any section with completely different steering to shift focus or deepen the evaluation with out rebuilding from scratch.
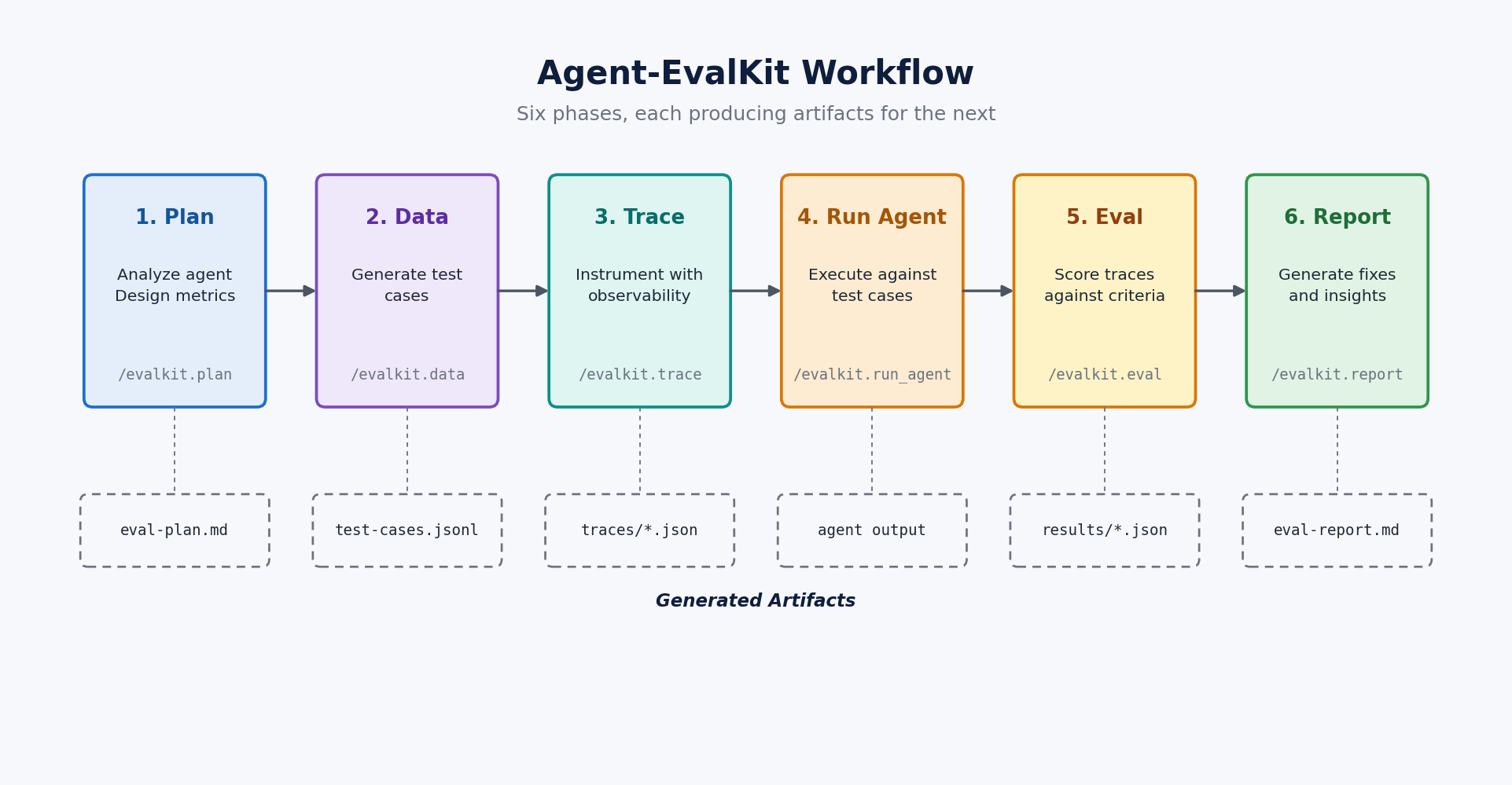
These six phases cowl the complete analysis lifecycle, from understanding your agent’s capabilities by way of recommending particular code enhancements.
- Plan (
/evalkit.plan) reads your agent’s code to grasp its instruments and framework, then produces an analysis plan pairing each metric with a concrete analysis methodology. Your steering shapes which high quality dimensions the plan prioritizes, and people priorities carry by way of to working analysis code in later phases. - Information (
/evalkit.knowledge) generates take a look at instances grounded within the analysis plan, every with inputs and anticipated outcomes concentrating on the particular behaviors and failure modes your agent must deal with. If you have already got take a look at knowledge from manufacturing logs or handbook testing, you may level this section at your current dataset as an alternative. - Hint (
/evalkit.hint) makes the complete execution path seen by including OpenTelemetry-compatible tracing to your agent. For supported frameworks, together with Strands, LangGraph, and CrewAI, it detects the framework and applies the suitable instrumentation. See the Agent-EvalKit repository for the present help matrix. - Run agent (
/evalkit.run_agent) executes your agent towards every take a look at case, producing a structured hint file for each run that captures the complete historical past of software calls, mannequin responses, and intermediate state. - Eval (
/evalkit.eval) implements the metrics out of your plan as executable analysis code, runs it towards the collected traces, and saves structured outcomes. It helps analysis libraries together with DeepEval and the Strands Evals SDK, choosing the method that most closely fits your agent and metrics. - Report (
/evalkit.report) analyzes patterns throughout take a look at instances and generates prioritized suggestions that reference particular areas in your agent’s code, with every advice together with its anticipated influence so you may direct enchancment effort the place it should take advantage of distinction.
Throughout these phases, imprecise high quality considerations turn out to be a structured physique of proof: take a look at instances, execution traces, metric scores, and prioritized suggestions that each one tie again to particular areas in your code.
Demonstration research: evaluating a journey analysis agent
Throughout improvement of a journey analysis agent constructed with the Strands Brokers SDK and Amazon Bedrock, we observed the agent generally supplied suspiciously exact numbers in its responses. The agent helps customers plan journeys utilizing instruments for net search, flight info, local weather knowledge, foreign money conversion, and finances calculation, however we couldn’t decide how widespread the precision subject was or which queries triggered it.
Agent-EvalKit analyzed the agent’s code and, throughout the Plan section, designed a centered analysis round three metrics: Faithfulness measures whether or not responses are grounded in knowledge the instruments really returned, Device Parameter Accuracy checks whether or not the agent known as instruments with appropriate inputs, and Response High quality assesses how coherent and helpful the output is. The Information section then generated 100 multi-turn take a look at periods protecting vacation spot analysis, seasonal timing, itinerary constructing, comparability questions, and finances calculation, and subsequent phases ran every session whereas capturing detailed execution traces.
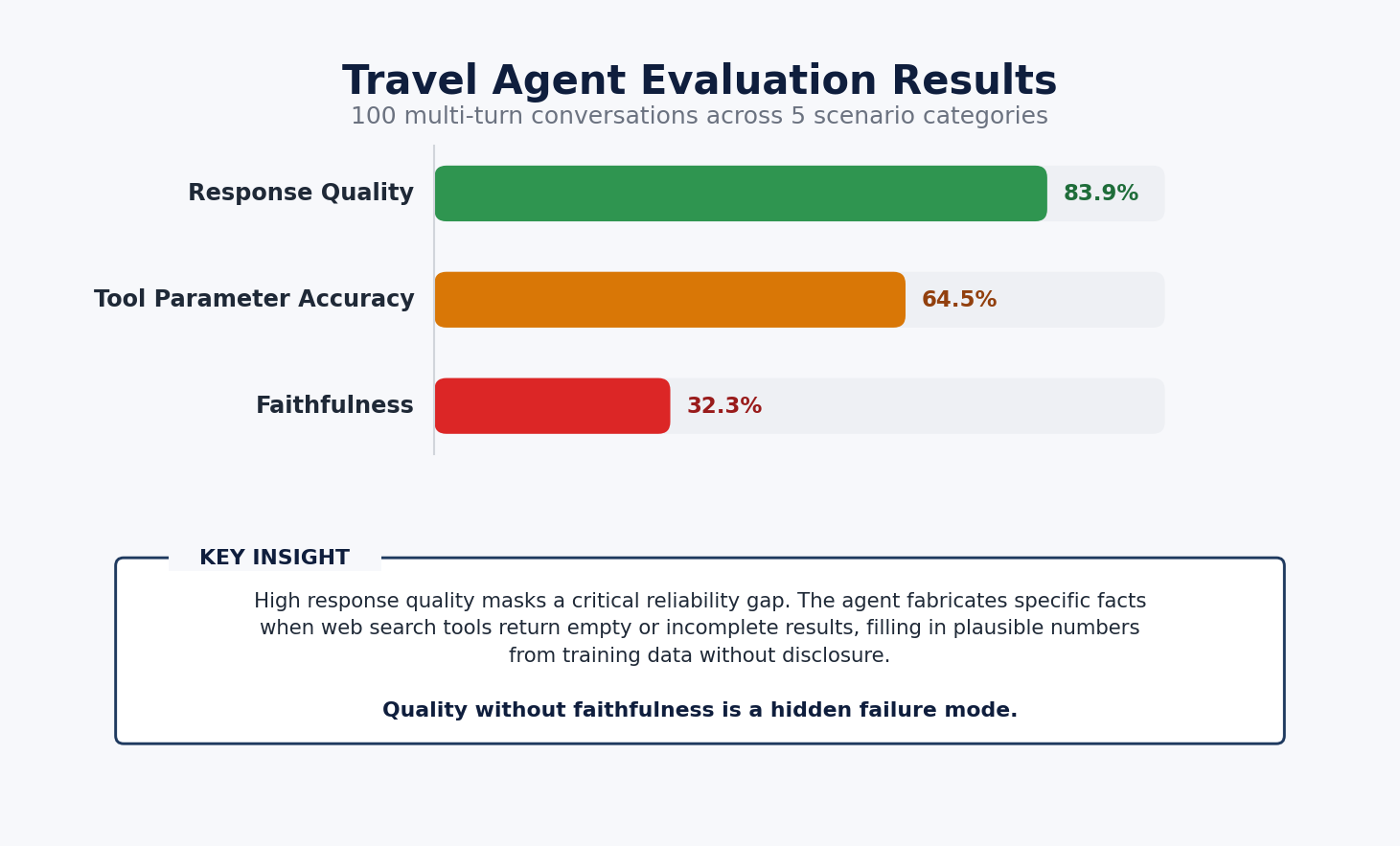
The outcomes uncovered a transparent divide between high quality and reliability. Response High quality scored 83.9%, confirming that the agent produced clear, actionable journey recommendation, and Device Parameter Accuracy reached 64.5%, displaying the agent typically chosen the best instruments however generally handed imprecise parameters. Faithfulness scored solely 32.3%, revealing that the agent was fabricating trade charges, temperatures, and attraction particulars at any time when its net search instruments returned empty or incomplete outcomes and presenting these innovations as in the event that they got here from its instruments.
The next diagram reveals what this hallucination sample seems to be like inside a single execution, the place the agent receives an empty software response and presents fabricated knowledge as if it got here from its instruments.
The report recognized hallucination guardrails as the very best precedence repair, recommending system immediate directions to reveal when instruments return empty outcomes and enhancements to software error dealing with throughout all code paths. Earlier than operating Agent-EvalKit, we knew the agent generally appeared unreliable. Afterward, we knew the basis trigger was empty software outputs triggering hallucination and had particular code modifications to handle it.
Walkthrough
The next sections stroll you thru the stipulations for Agent-EvalKit, set up the toolkit, and run an end-to-end analysis towards your agent.
Conditions
Working an Agent-EvalKit analysis requires cloud entry for basis mannequin inference and native tooling for the analysis workflow.
- An lively AWS account with basis fashions enabled within the Amazon Bedrock console. Agent-EvalKit makes use of LLM-as-judge metrics that require a basis mannequin for scoring, so affirm your fashions can be found on the Mannequin entry web page earlier than continuing.
- Python 3.11 or later and Git.
- The uv bundle supervisor. On macOS and Linux, set up it with
curl -LsSf https://astral.sh/uv/set up.sh | sh. - A supported AI coding assistant (Claude Code, Kiro CLI, or Kilo Code) put in and configured in your machine. The examples on this publish use Claude Code, however the workflow applies to all three. Refer to every assistant’s documentation for set up directions.
Get began
Set up the toolkit utilizing uv, which pulls immediately from the Agent-EvalKit GitHub repository.
Initialize an analysis undertaking and replica your agent code into the undertaking listing. Your agent listing ought to comprise the supply code, software definitions, and any configuration wanted to run the agent. For particulars on supported agent frameworks and undertaking buildings, see the Agent-EvalKit repository.
Begin your AI assistant from throughout the analysis undertaking. For Claude Code, run the claude command.
For a guided first analysis, the fast command walks you thru all six phases step-by-step, explaining what every section does and which command to run subsequent.
For extra management, run every section individually.
The next video walks by way of the complete workflow, with Agent-EvalKit evaluating a journey analysis agent outfitted with net search and planning instruments throughout all six phases from code evaluation to a ultimate analysis report.
Finest practices
Agent analysis pays off most when it runs on each significant change relatively than as a pre-release checkpoint. The practices that observe mirror what we have now discovered most helpful when folding Agent-EvalKit into an ongoing improvement cycle.
- Begin slender and give attention to two or three metrics that concentrate on your agent’s most crucial high quality dimensions and develop the scope in later evaluations as you tackle preliminary findings and achieve confidence in your baseline.
- Information with area data and describe the particular inputs, edge instances, and failure modes you’ve got noticed in every section. The extra focused your pure language directions, the extra related the generated take a look at instances, metrics, and proposals.
- Evaluation take a look at instances earlier than execution as a result of the information section synthesizes instances from the analysis plan, however your understanding of actual consumer habits is irreplaceable. Add eventualities that mirror patterns you observe in manufacturing.
- Consider after every vital change to catch regressions early and measure the influence of every enchancment. Evaluating studies throughout agent variations makes progress seen and retains improvement centered on the highest-value fixes.
- Tackle suggestions incrementally by beginning with the highest-impact merchandise within the report. Implement the repair, re-evaluate to verify the development, after which transfer on to the subsequent discovering.
- Construct on earlier evaluations by re-invoking particular person phases to discover new high quality dimensions whereas reusing current take a look at instances and instrumentation. An preliminary analysis centered on faithfulness will be adopted by a deeper cross on software accuracy with out regenerating knowledge or re-instrumenting your agent.
- Monitor your agent constantly in manufacturing by capturing traces from actual visitors with Amazon Bedrock AgentCore Observability and operating high quality metrics towards these traces with AgentCore Analysis. Manufacturing monitoring surfaces regressions and new failure modes that pre-deployment analysis can’t anticipate.
- Hold your evaluators aligned with human consultants by periodically evaluating LLM-as-judge scores towards judgments out of your subject material consultants or human annotators. Replace evaluator prompts when the 2 drift aside in order that your automated metrics proceed to mirror the standard dimensions that matter to your customers.
Combine with CI/CD
For groups able to automate, the next diagram reveals how Agent-EvalKit integrates right into a steady integration and steady supply (CI/CD) pipeline the place code modifications set off evaluations, a high quality gate checks metric thresholds and regressions, and failures route again as flagged objects within the analysis report.
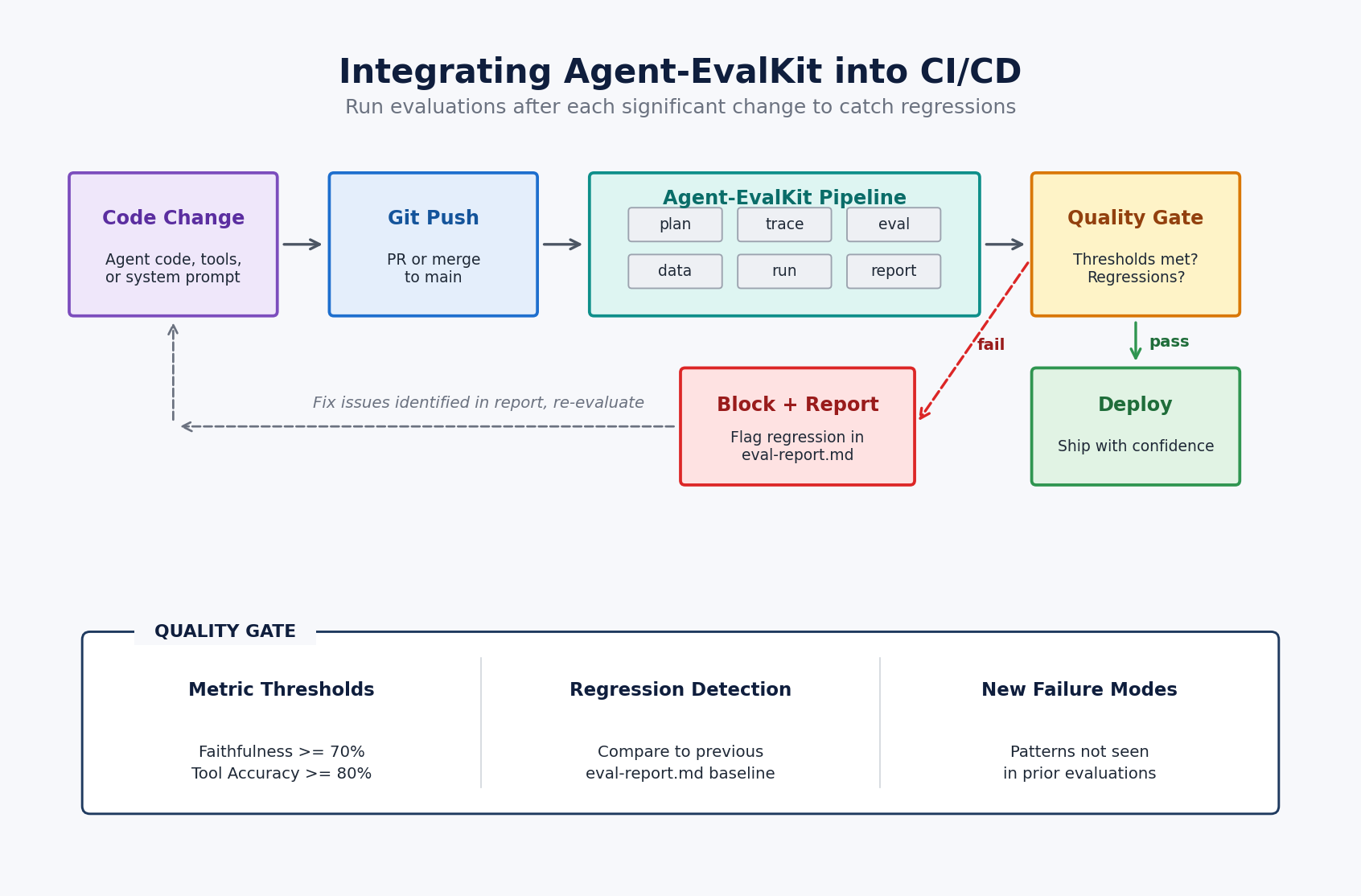
As soon as the pipeline is in place, every spherical of testing reuses the take a look at instances and instrumentation from the earlier spherical, so the price of operating a recent analysis drops because the undertaking matures.
Clear up
In the event you created an analysis undertaking to observe alongside, delete the undertaking listing when completed. In case your analysis used basis fashions by way of Amazon Bedrock, assessment your utilization on the Amazon Bedrock pricing web page on the AWS Administration Console to grasp any related prices.
Conclusion
Agent-EvalKit provides AI agent analysis a scientific form by delegating every step, from analysis design by way of metric computation and reporting, to the identical AI assistant you already use to put in writing code. The journey analysis agent case research confirmed what that appears like in follow, turning a diffuse high quality concern into a particular repair at a particular line with an anticipated influence connected.
As brokers tackle duties with increased stakes and wider attain, analysis that goes past output checking turns into a prerequisite for manufacturing readiness. Agent-EvalKit is designed to make that analysis a part of the identical improvement workflow you already use to put in writing and assessment agent code.
Go to the Agent-EvalKit GitHub repository for full documentation and instance evaluations, and use GitHub discussions to succeed in the crew with questions, suggestions, or contributions. Check with An Empirical Examine of Automating Agent Analysis for extra studying on this answer.
In regards to the authors



{kind=link}