
This resolution builds on open supply instruments together with PyTorch, Hugging Face Transformers, and Liger Kernels. The authors would additionally wish to thank Aiham Taleb, Arefeh Ghahvechi, Manav Choudhary, Rohit Thekkanal, Daz Akbarov, Jamila Jamilova, Ross Povelikin, Almas Moldakanov, Christelle Xu, and Ivan Khvostishkov for his or her contributions in making this undertaking attainable.
Azercell Telecom LLC, Azerbaijan’s main telecommunications supplier, wished to construct an Azerbaijani giant language mannequin (LLM) on Amazon SageMaker AI for telecom use circumstances and a customer-facing chatbot. The problem: adapting basis fashions (FMs) to a morphologically wealthy language with restricted coaching information and no current blueprint for environment friendly LLM coaching in Azerbaijani. In a six-week collaboration, Azercell labored with the AWS Generative AI Innovation Middle to determine a production-ready framework on Amazon SageMaker AI that delivered a 23% increased coaching throughput and 58% decrease peak GPU reminiscence utilization via kernel-level optimizations on an ml.p5.48xlarge occasion. The framework additionally achieved a 2× enchancment in tokens per phrase utilizing a customized tokenizer, successfully doubling the quantity of Azerbaijani textual content that matches inside the mannequin’s context window. In case you work with low-resource or morphologically complicated languages, this publish walks via the strategy so you may consider related methods.
Answer overview
The framework implements three sequential levels, every producing artifacts that feed the subsequent.
- Stage 1: Tokenizer growth builds an environment friendly tokenizer for Azerbaijani. We evaluated three approaches (baseline English-optimized tokenizers, vocabulary extension, and customized monolingual tokenizers) measuring encoding effectivity via standardized metrics. The customized monolingual tokenizer achieved the strongest outcomes, halving the tokens per phrase in comparison with the baseline.
- Stage 2: Continued pre-training (CPT) adapts an FM (Llama 3.2 1B) to grasp Azerbaijani utilizing distributed coaching and Liger Kernel optimizations on Amazon SageMaker AI coaching jobs. This enables for bigger batch sizes and better throughput on the identical {hardware}. Whereas distributed coaching wasn’t required for this 1B-scale proof-of-concept, it is going to be important as Azercell scales to bigger fashions.
- Stage 3: Supervised fine-tuning with Low-Rank Adaptation (LoRA) transforms the pre-trained mannequin right into a conversational assistant. After CPT, the mannequin can predict Azerbaijani tokens however can’t have interaction in dialogue. Stage 3 applies LoRA, a parameter-efficient fine-tuning methodology that considerably reduces trainable parameters.
The coaching levels (CPT and LoRA fine-tuning) had been run as Amazon SageMaker AI coaching jobs launched from Amazon SageMaker Unified Studio, every pointing to a customized coaching script. Every job provisions recent Amazon Elastic Compute Cloud (Amazon EC2) situations and terminates after completion, so that you pay just for precise compute time with no idle cluster price.
The next diagram illustrates the modular structure, the place every stage will be optimized independently. Tokenizer enhancements profit each subsequent coaching stage, and CPT configurations switch throughout fine-tuning duties.
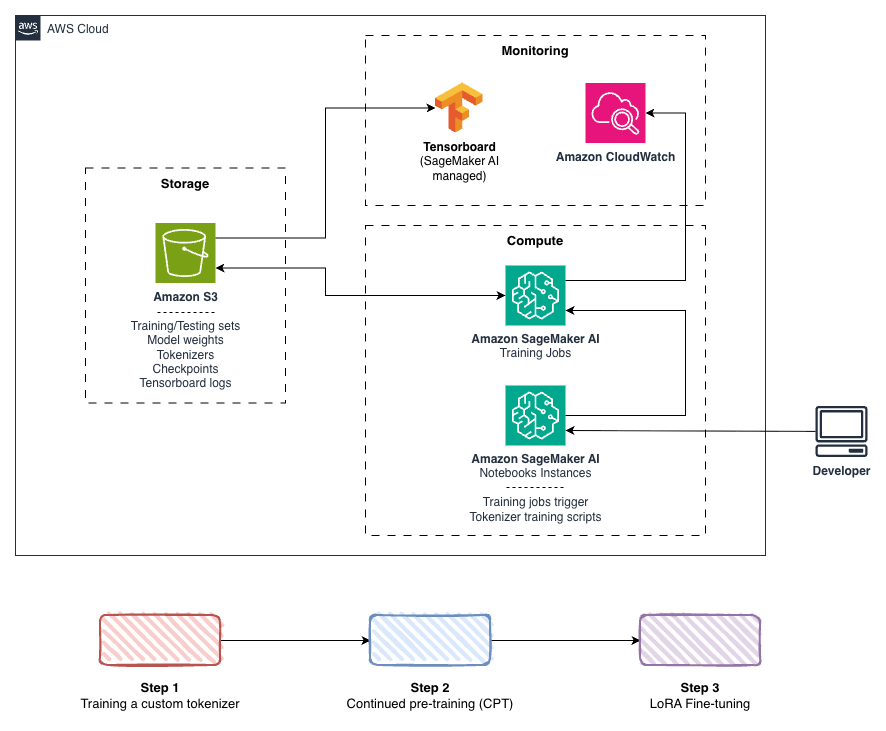
Determine 1. The coaching pipeline structure. Operators launch coaching jobs from Amazon SageMaker AI Pocket book Cases. Coaching information and mannequin artifacts are saved in Amazon Easy Storage Service (Amazon S3). Coaching metrics are tracked with TensorBoard in Amazon SageMaker AI, and system metrics are captured via Amazon CloudWatch.
Growing an Azerbaijani tokenizer
Languages like Azerbaijani are morphologically wealthy, with single phrases encoding grammatical which means via suffixes that English would specific utilizing a number of phrases. Nonetheless, customary English-optimized tokenizers fragment these complicated phrase types. For instance, splitting “kitablardan” (which means from the books) into a number of subword tokens as illustrated in Determine 2, which reduces the precise content material that matches inside a fixed-size context window.
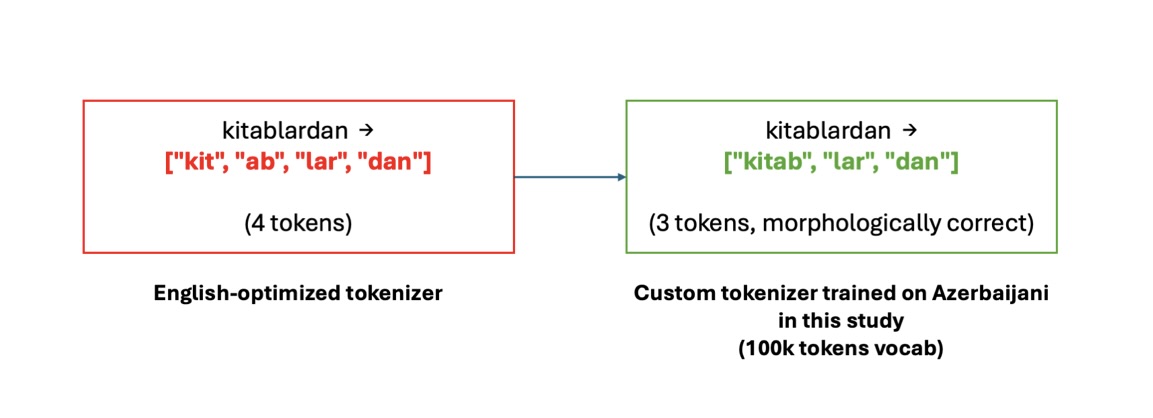
Determine 2. Comparability of baseline and customized tokenization for Azerbaijani textual content, displaying diminished token fragmentation.
To handle this, we skilled a customized tokenizer on Azerbaijani textual content utilizing a Byte-Degree Byte-Pair Encoding (BBPE) algorithm, which iteratively merges probably the most frequent byte pairs into vocabulary entries. Ranging from uncooked bytes relatively than predefined character units supplies full protection of Azerbaijani-specific characters with out requiring guide alphabet definitions. We experimented with vocabulary sizes starting from 50k–100k tokens to seek out the best stability: too small and the tokenizer over-fragments phrases, too giant and uncommon tokens lack ample coaching sign.
We skilled customized tokenizers utilizing the Hugging Face tokenizers library with the identical configuration because the native Llama 3.2 tokenizer, various solely vocabulary dimension. After coaching and evaluating a number of tokenizers with completely different vocabulary sizes, we chosen a remaining vocabulary of 100k tokens. To confirm that the customized tokenizer didn’t sacrifice modeling high quality, we in contrast fashions after continued pre-training utilizing Bits-Per-Byte (BPB) relatively than perplexity, as a result of BPB normalizes for vocabulary variations by measuring prediction high quality on the byte stage. The mannequin utilizing the customized tokenizer achieved a BPB of 0.5795 on the validation set, in comparison with the baseline’s 0.6830, confirming that improved encoding effectivity got here with out a high quality trade-off.
Past preserving modeling high quality, the customized tokenizer delivers substantial sensible effectivity features. Encoding effectivity will be quantified via fertility rating—the common variety of tokens per phrase, the place decrease values point out extra environment friendly encoding. The baseline Llama 3.2 tokenizer averaged 3.22 tokens per Azerbaijani phrase, whereas the customized monolingual tokenizer achieved 1.59—a 2× enchancment in encoding effectivity. With Llama 3.2’s 128k-token context window, this interprets to actual capability variations: roughly 40k phrases with the baseline tokenizer versus 80k with the optimized one—successfully doubling the content material the mannequin considers without delay.
Continued pre-training
Continued pre-training adapts the FM (Llama 3.2 1B) to grasp Azerbaijani. The first bottleneck for this stage is GPU reminiscence: optimizing reminiscence utilization immediately determines how a lot of the {hardware} funding interprets into coaching throughput. We benchmarked on each ml.p4d.24xlarge (8× NVIDIA A100 GPUs) and ml.p5.48xlarge (8× NVIDIA H100 GPUs) situations. The next sections describe the 2 optimization approaches benchmarked: distributed coaching with PyTorch’s Absolutely Sharded Knowledge Parallel (FSDP) and Liger Kernel integration.
Distributed coaching with Absolutely Sharded Knowledge Parallel (FSDP)
A mannequin’s reminiscence footprint contains not simply weights, but additionally gradients, optimizer states, and activations. These elements can exceed 100 GB for bigger fashions like Llama 3.1 8B in blended precision. We developed and validated the distributed coaching setup on the 1B mannequin in order that scaling to bigger architectures requires solely a configuration change, not a re-architecture of the pipeline. Commonplace Distributed Knowledge Parallel (DDP) replicates the total mannequin on every GPU, which limits the batch dimension and mannequin scale you may obtain. FSDP shards parameters, gradients, and optimizer states throughout GPUs, dynamically gathering solely what is required throughout every computation step. This diminished per-GPU mannequin state reminiscence from 9.23 GB to 1.17 GB on ml.p4d.24xlarge, liberating headroom for bigger batch sizes.
Liger Kernel integration
Liger Kernels are memory-efficient, Triton-based implementations of frequent LLM operations that fuse a number of operations into single GPU kernel launches, decreasing intermediate reminiscence allocations whereas producing numerically equal outcomes. They help a number of in style mannequin architectures together with Llama. We advocate that you simply confirm compatibility along with your structure earlier than adoption.
Integration requires minimal code modifications: a single operate name patches the mannequin with optimized kernels earlier than instantiation, and Liger Kernels work with PyTorch FSDP with out modifications to the distributed coaching setup. We validated right execution with PyTorch Profiler, confirming fused operations within the hint. The next desk summarizes the cumulative influence of every optimization step throughout each occasion varieties. Observe that DDP reminiscence and throughput on p5 situations weren’t benchmarked as a result of FSDP was the goal configuration.
| Metric | DDP | FSDP | FSDP + Liger |
| Max batch dimension per GPU on ml.p4d.24xlarge (8× NVIDIA A100 GPUs) | 2 | 4 | 14 |
| Max batch dimension per GPU on ml.p5.48xlarge (8× NVIDIA H100 GPUs) | 4 | 10 | 18 |
| Peak GPU reminiscence incl. activations (GB) on ml.p5.48xlarge | — | 64 | 27 |
| Coaching throughput per GPU (tokens/s) on ml.p5.48xlarge | — | 63,771 | 78,319 |
On ml.p4d.24xlarge, the total optimization stack delivered a 7× improve in most batch dimension over DDP. On ml.p5.48xlarge, peak GPU reminiscence dropped 58% and per-GPU throughput elevated 23% when including Liger Kernels to FSDP.
Pre-training setup
Every tokenizer configuration from Stage 1 was carried via CPT end-to-end to match convergence conduct and downstream high quality. With the customized Azerbaijani tokenizer (100k vocabulary), the coaching corpus quantities to roughly 2.5B tokens.
The customized coaching script helps configurable context home windows, BFloat16 blended precision, cosine studying fee scheduling with AdamW, and computerized checkpointing to Amazon S3 for fault tolerance. We set the context window to 2,048 tokens as a result of over 90% of coaching samples fell beneath this size after tokenization, although the configuration helps as much as the mannequin’s native 128k-token restrict.
When new tokens are added to the vocabulary, CPT follows a two-phase strategy. Within the first section, the mannequin spine is frozen and solely the embedding layer is skilled. This adapts the brand new token representations to the mannequin’s current inside area with out disrupting pre-trained data. Within the second section, the parameters are unfrozen for full coaching, permitting the mannequin to deeply be taught Azerbaijani language patterns. The next desk exhibits the coaching configuration utilizing the Azerbaijani customized tokenizer (100k vocabulary). Coaching used two ml.p4d.24xlarge situations (16 NVIDIA A100 GPUs complete) with FSDP and Liger Kernel optimizations.
| Parameter | Section 1: Embedding Adaptation | Section 2: Full Coaching |
| Frozen spine | Sure | No |
| Studying fee | 0.0032 | 0.0024 |
| Batch dimension per GPU | 14 | 14 |
| Steps | 5,000 | 15,000 |
| Coaching time | ~11,400 seconds (~3.2 hours) | ~43,000 seconds (~11.9 hours) |
A decrease studying fee within the full-training section preserves the data acquired throughout embedding adaptation. With an efficient batch dimension of 224 (14 per GPU × 16 GPUs) and a 2,048-token context window, every coaching step processes roughly 450k tokens, yielding an estimated per-epoch time of roughly 4.3 hours on this configuration. On ml.p5.48xlarge, increased per-GPU throughput and bigger batch sizes would scale back per-epoch time additional.
Supervised fine-tuning with LoRA
After CPT, the mannequin can fluently predict the subsequent Azerbaijani token, however it has no idea of conversational construction. Given a query, it generates believable continuations relatively than useful solutions. LoRA bridges this hole effectively by freezing the pre-trained weights and coaching small low-rank decomposition matrices injected into the mannequin’s consideration and feed-forward layers. As an alternative of updating a full weight matrix, LoRA trains two smaller matrices whose product approximates the total replace—decreasing trainable parameters to a small fraction of the whole. The next desk summarizes the LoRA fine-tuning configuration.
| Parameter | Rank | Alpha | Dropout | Goal modules | Max sequence size |
| Worth | 64 | 28 | 0.05 | q, ok, v, o projections; gate, up, down projections | 1,024 |
This compact footprint meant fine-tuning ran on a single ml.g5.8xlarge occasion (1× NVIDIA A10G GPU), finishing in minutes. Effective-tuning used roughly 2,000 single-turn Azerbaijani question-answer pairs utilizing Hugging Face’s SFTTrainer with a studying fee of 1e-4—increased than CPT’s studying charges as a result of LoRA adapters are randomly initialized and profit from stronger gradient updates.
Coaching used a Llama-style chat template with assistant-only loss masking: the mannequin is penalized just for predicting the assistant’s response tokens and the end-of-turn token (<|eot_id|>), whereas person prompts and template delimiters are excluded from the loss. In consequence, the mannequin focuses its studying capability on producing acceptable responses relatively than memorizing person enter patterns.
Outcomes and validation
Continued pre-training used roughly 2.5B tokens with the customized Azerbaijani tokenizer, and fine-tuning used 2,000 question-answer pairs. The framework delivered measurable enhancements throughout 4 dimensions:
- 2× encoding effectivity via customized tokenization The customized monolingual tokenizer halved the fertility rating (from 3.22 to 1.59 tokens per phrase), successfully doubling the Azerbaijani content material that matches inside the mannequin’s 128k-token context window. A BPB rating of 0.5795 versus the baseline’s 0.6830 confirmed this achieve didn’t sacrifice modeling high quality.
- Vital reminiscence and throughput optimization Absolutely Sharded Knowledge Parallel (FSDP) sharding and Liger Kernel integration allowed bigger batch sizes on the identical {hardware}, as much as 7× on ml.p4d.24xlarge and 4.5× on ml.p5.48xlarge over their respective DDP baselines—whereas decreasing peak GPU reminiscence by 58% and rising per-GPU throughput by 23%.
- Manufacturing-ready, scalable infrastructure Validated configurations throughout ml.p4d.24xlarge and ml.p5.48xlarge situations give Azercell a versatile basis that scales as coaching necessities develop, with the distributed setup designed in order that shifting to bigger fashions requires solely a configuration change.
- Coherent Azerbaijani language era The off-the-shelf Llama 3.2 1B drifts into repetitive, incoherent output when prompted in Azerbaijani, a typical failure mode for underrepresented languages. The fine-tuned mannequin produces concise, semantically coherent responses that exhibit clear Azerbaijani language understanding. That is illustrated within the following desk for a pattern immediate offered by Azercell.
| Immediate | Azerbaijani output | English translation |
| Enter immediate | Yeni bir dil öyrənmək yalnız ünsiyyət imkanlarını genişləndirmir... | Studying a brand new language not solely expands communication alternatives… |
| Llama 3.2 1B |
Yeni bir dil öyrənmək yalnız ünsiyyət imkanlarını genişləndirmir. Bu, əksinə, dili öyrənən insanlara yeni bir dil öyrənmək üçün fərqli məqsədlərlə yanaşı, onların özü də yeni bir dil öyrənməyə başlayır. Dil öyrənməsi, həmçinin, yeni bir dil öyrənməyə olan istiqamətlərin və təcrübələrinin genişləndirilməsinə səbəb olur. Yeni bir dil öyrənməyə olan istiqamətləri və təcrübələrinin genişləndirilməsindən sonra, yeni bir dil öyrənməyə olan istiqamətlərin və təcrübələrinin genişləndirilməsi… |
Studying a brand new language not solely expands communication alternatives. Quite the opposite, it additionally leads individuals who be taught a language to strategy language studying with completely different objectives, they usually themselves start the method of studying a brand new language. Language studying additionally contributes to the enlargement of instructions and experiences associated to studying a brand new language. After increasing these instructions and experiences, the event of approaches and experiences in studying a brand new language continues… |
| Effective-tuned Llama 3.2 1B | Yeni bir dil öyrənmək yalnız ünsiyyət imkanlarını genişləndirmir, həm də yeni dostlar və əlaqələr yaradır. | Studying a brand new language not solely expands communication alternatives but additionally creates new friendships and connections. |
Conclusion
On this publish, we confirmed how Azercell and the AWS Generative AI Innovation Middle constructed a framework for coaching Azerbaijani language fashions on Amazon SageMaker AI. The three-stage pipeline (customized tokenization, continued pre-training with FSDP and Liger Kernel optimizations, and LoRA fine-tuning) transforms a general-purpose basis mannequin into an Azerbaijani conversational assistant whereas maximizing GPU utilization. Azercell now operates the framework independently, with a technique that helps bigger corpora, scaled architectures, and expanded use circumstances. To be taught extra, discover the next assets:
To discover implementing an analogous resolution, attain out to your AWS account crew or go to the AWS Generative AI Innovation Middle. In case you’re coaching LLMs for low-resource languages or optimizing GPU utilization on SageMaker AI, we’d love to listen to from you. Share your ideas and questions within the feedback.
In regards to the authors


{kind=link}