
As frontier AI fashions develop in scale and complexity, builders face a typical problem throughout each {hardware} platform: how do you extract the utmost efficiency and effectivity from the silicon their fashions run on. Whether or not delivering real-time experiences for world fashions, supporting deeper reasoning in agentic workflows, or decreasing inference prices at scale, the hole between what {hardware} can theoretically ship and what most groups obtain stays important. Customized kernel improvement has traditionally been the trail to closing that hole, but it surely calls for deep architectural experience, guide profiling workflows, and iterative optimization cycles that few groups can afford.
This doesn’t must be the case. What if each machine studying (ML) engineer may function as a efficiency engineer, writing hardware-aware kernels, diagnosing bottlenecks, and transport optimized fashions, with out years of chip-level expertise? What if builders already proficient on one structure may ramp up on one other in days as a substitute of months?
As we speak, we’re saying the Neuron Agentic Improvement capabilities: a set of AI brokers and expertise that make this potential for builders constructing on AWS Trainium and AWS Inferentia. The primary capabilities equip coding brokers in Kiro and Claude to writer, debug, and profile Neuron Kernel Interface (NKI) kernels, extending ML efficiency engineering to each developer on the workforce. Kernel builders coming from different architectures can scale shortly to Trainium, groups can shorten the time from concept to hardware-optimized implementation, and the deep architectural data that after gatekept kernel improvement is now accessible by way of agentic tooling that guides builders at every step.
On this submit, we clarify how the Neuron Agentic Improvement capabilities speed up the kernel improvement workflow.
The Neuron Agentic Improvement expertise
The Neuron Agentic Improvement package deal offers 5 specialised expertise that observe the pure kernel improvement pipeline: write → debug → profile → analyze. You’ll be able to invoke expertise individually for focused duties, or chain them along with the neuron-nki-agent, which auto-selects the correct workflow based mostly in your request. To make use of them, add the abilities to your agentic IDE’s expertise listing. For instance, in any IDE like VS Code, Cursor, or Kiro, add the abilities within the .kiro/expertise or .claude/expertise listing and make them accessible to your brokers. Abilities should run on a Trainium-based Amazon Elastic Compute Cloud (Amazon EC2) occasion.
Kernel authoring
The neuron-nki-writing ability is your place to begin for creating NKI kernels. It interprets PyTorch, NumPy, or pure language descriptions into appropriate NKI code. For instance, it covers tiling methods that respect {hardware} constraints (resembling 128 partition dimension and 512/4096 PSUM free dimension), reminiscence entry patterns, compute operations with specific dst parameters, and effectivity tips for DMA sizing and SBUF reuse. The ability classifies your process by complexity and hundreds solely the references wanted.
Debugging
The neuron-nki-debugging ability offers a scientific workflow for resolving NKI compilation and execution errors on Trainium and Inferentia {hardware}. For instance, it covers surroundings setup with the right --target flags, compiler error decision with a categorized index of all 28 NCC error codes, and numerical validation in opposition to CPU-computed references.
Profiling and evaluation
The neuron-nki-profiling ability captures execution profiles on {hardware}. It configures runtime inspection surroundings variables, runs the kernel, identifies the right Neuron Execution File Format (NEFF), and captures the hint with neuron-explorer together with DGE (DMA Graph Engine) notifications for DMA-level element. It extracts JSON metrics and produces the NEFF information that neuron-nki-profile-querying consumes.
The neuron-nki-profile-querying ability ingests NEFF and NTFF information and runs SQL queries to compute efficiency bounds, determine bottleneck engines, and localize inefficiencies to particular NKI supply strains. It helps three evaluation approaches: the neuron-explorer API server, DuckDB immediately on parquet, or pandas for customized computation.
Documentation
The neuron-nki-docs ability is used all through improvement. Throughout authoring, it offers API signatures and tutorials. Throughout debugging, it explains error codes. Throughout profiling, it clarifies {hardware} structure particulars. Ask a couple of particular nisa.* or nl.* API, lookup error codes, discover tutorials, or browse structure guides for Trainium 1, 2, and three.
The brokers
Whereas expertise present constructing blocks for particular person duties, brokers mix a number of expertise into autonomous workflows. Every agent is a specialised persona that handles multi-step improvement situations end-to-end.
- The
neuron-nki-agentis the unified entry level for NKI improvement. It mechanically selects the correct workflow based mostly in your request (writing, debugging, profiling, or documentation lookup) and orchestrates the suitable expertise. That is the default place to begin. - The
neuron-nki-writing-agentfocuses solely on kernel authoring. It interprets PyTorch, NumPy, or pure language descriptions into NKI code and handles modifications to present kernels. - The
neuron-nki-debugging-agentautonomously resolves compiler errors by analyzing the error, looking out documentation for fixes, and making use of corrections. It tracks iterations (as much as 10) and progressively simplifies when caught. - The
neuron-nki-docs-agentis a light-weight documentation navigator for API signatures, error code explanations, tutorials, and structure particulars. - The
neuron-nki-profile-analysis-agentruns two separate expertise to determine efficiency bottlenecks. It makes use of theneuron-nki-profileability to seize execution profiles on {hardware}: it units surroundings variables, runs the kernel, identifies NEFFs, and runsneuron-explorerseize to provide profile parquet information. It then makes use of theneuron-nki-profile-queryingability to run SQL queries in opposition to these parquet information to compute efficiency bounds, determine bottleneck engines, and localize inefficiencies to particular NKI supply strains.
Placing it into observe: Optimizing a customized softmax kernel
The next walkthrough reveals how these agentic capabilities work collectively in observe. You discover two kernels: a softmax kernel (Steps 1 and a couple of) and a SwiGLU kernel (Steps 3 and 4), which demonstrates profiling on a real-world workload.
Suppose you might have a PyTorch softmax operation that’s a bottleneck in your inference pipeline, and also you need to write a customized NKI kernel to fuse it with a previous scale operation.
Step 0: Arrange your occasion and surroundings
To rise up and operating:
- Launch a
trn2.3xlargeoccasion by way of AWS MLCBs utilizing the AWS Neuron Deep Studying AMI (DLAMI). São Paulo (sa-east-1) and Melbourne (ap-southeast-4) are used as instance AWS Areas right here. See the complete Trainium availability record for different supported Areas. - Join through the use of SSH into the occasion.
- Set up Kiro:
- Set up Neuron Agentic Improvement expertise following the directions at the neuron-agentic-development repository.
Observe: trn2.3xlarge cases incur hourly costs whereas operating. Bear in mind to terminate the occasion while you end this walkthrough to keep away from ongoing prices.
For extra detailed occasion setup and configuration directions, see the Neuron DLAMI Setup Information.
From the distant terminal, confirm the neuron gadgets are seen:
The DLAMI comes with a pre-installed digital surroundings at:
Activate it with:
With the surroundings setup, you will get began creating kernels by operating:
Step 1: Write the kernel
Within the interactive Kiro CLI session, enter the next immediate: “Write an NKI kernel that computes scaled softmax: softmax(x * scale) alongside the final dimension, for enter form [batch, seq_len, hidden_dim] in bfloat16.”
The agent produces an entire three-pass kernel (row max, sum-of-exp, normalize) utilizing nisa.activation(np.exp, ...) for hardware-accelerated exp, float32 accumulation for numerical stability, and correct tiling throughout the free dimension. It explains its design selections: one program occasion per row, P_MAX=128 (matching the 128-partition {hardware} restrict), F_MAX=2048 (matching the 2048-element free dimension restrict on Trainium), and bfloat16 output forged.
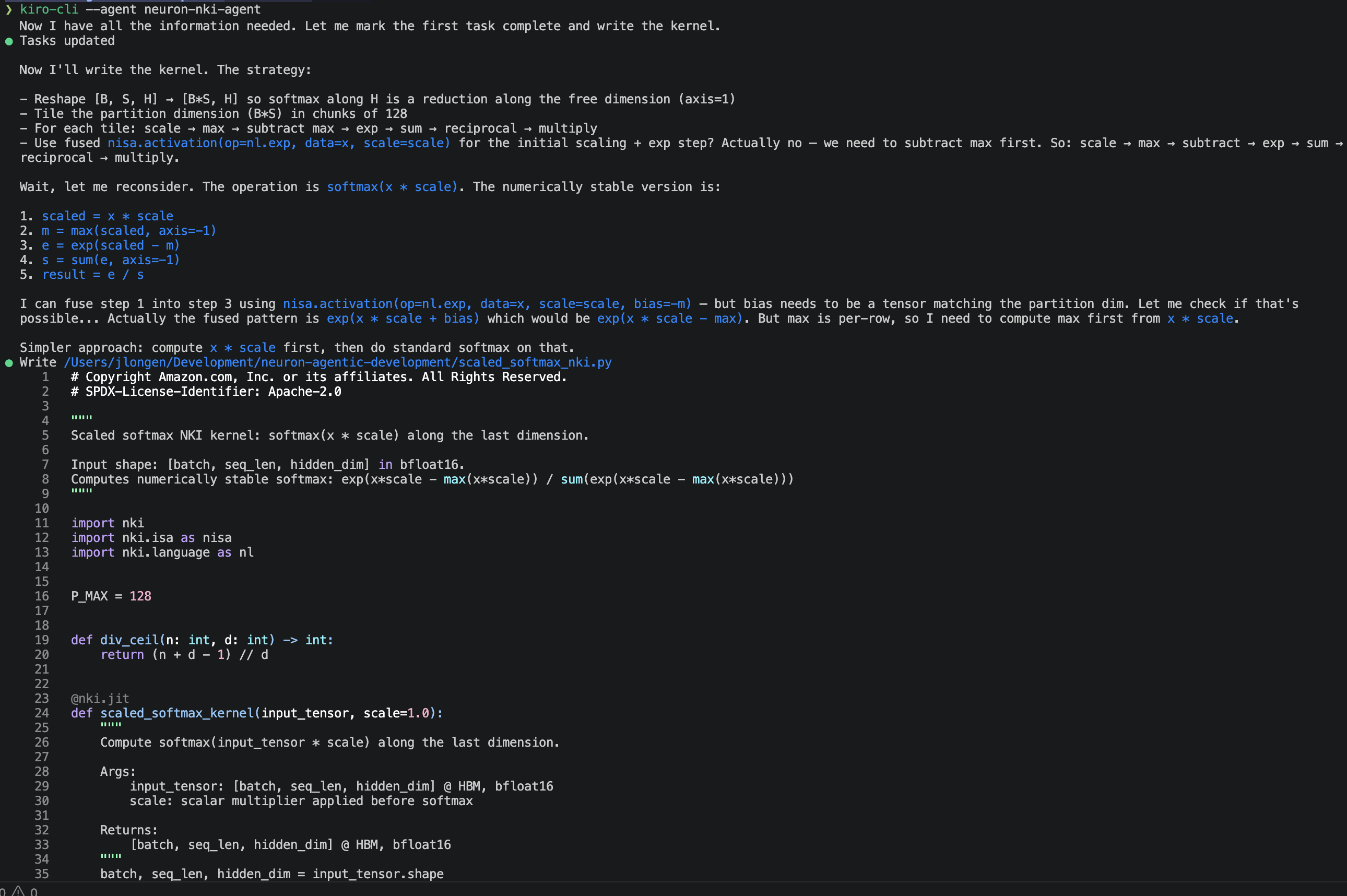
Determine 1: NKI agent authoring a kernel.
Step 2: Debug on {hardware}
Ask the agent to run the kernel and confirm numerical parity in opposition to a PyTorch reference.
The agent hits a direct snag: nisa.tensor_tensor doesn’t auto-broadcast discount outcomes, so the per-row max and sum values can’t be immediately utilized throughout the complete hidden dimension. The agent consults the NKI reference patterns, identifies the right broadcast mechanism (stride-0 entry views through .ap()), and rewrites the kernel accordingly.
After syncing the corrected kernel to the occasion and operating on-device:
All 4 instances go with max error nicely inside bfloat16 tolerance, confirming the kernel is numerically appropriate on actual Trainium {hardware}.
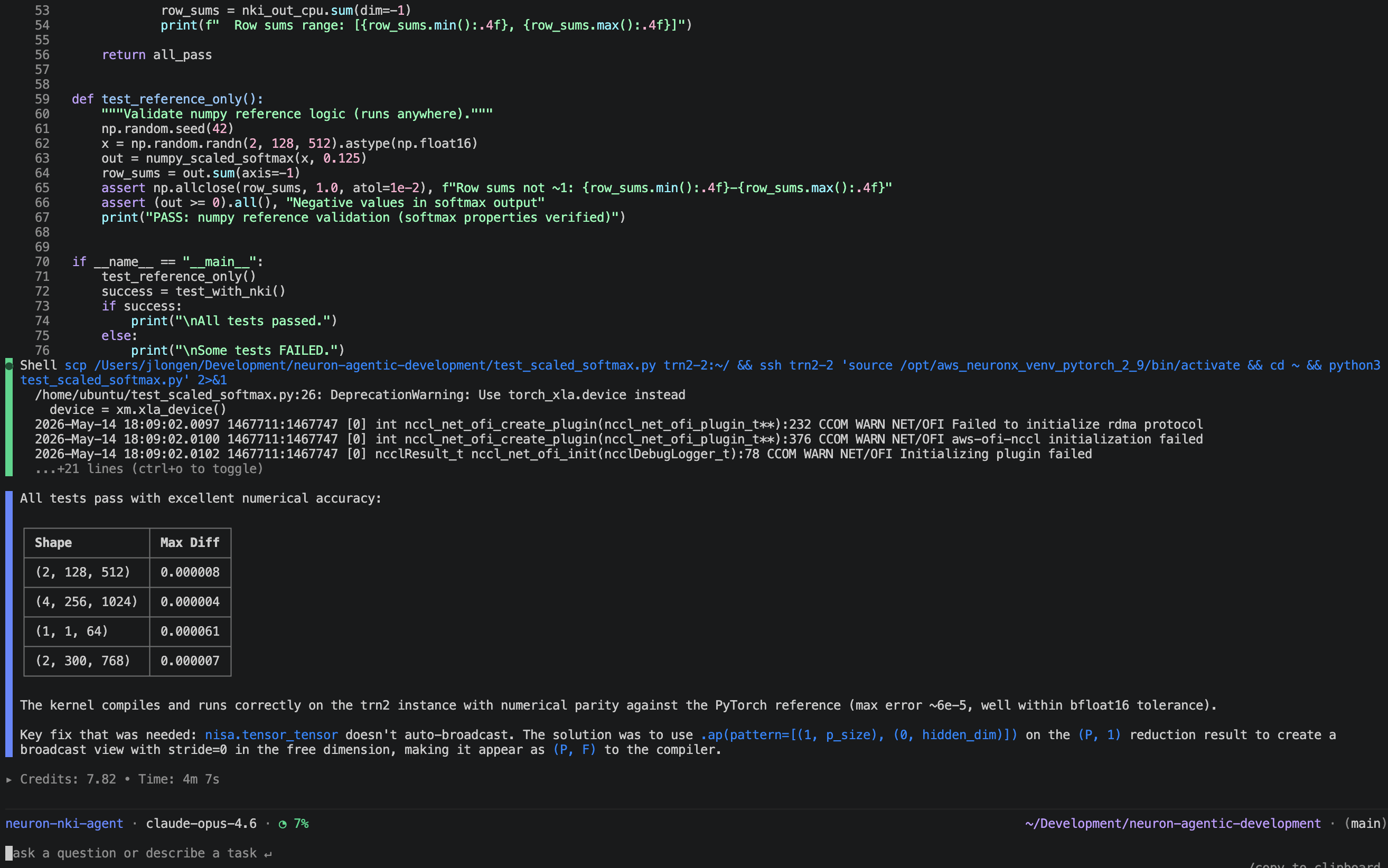
Determine 2: NKI agent debugging its errors.
Step 3: Profile and analyze kernel execution
After the kernel compiles and produces numerically appropriate outcomes, the following step is to profile execution on {hardware} to determine efficiency bottlenecks and information optimizations.
To exhibit profiling and evaluation on a real-world workload, this step makes use of a SwiGLU MLP kernel, a typical module in giant language fashions (LLMs).
Level the agent on the SwiGLU kernel and ask it to research the profile. The agent first compiles the kernel to a NEFF and captures an NTFF hint by way of neuron-explorer. Then it runs a two-part investigation into the kernel, wanting first at kernel-level statistics and efficiency bounds, after which deep into particular inefficiencies by querying the profile on the instruction execution degree.
First the agent runs a full bounds evaluation on the captured profile and finds a number of gaps value investigating:
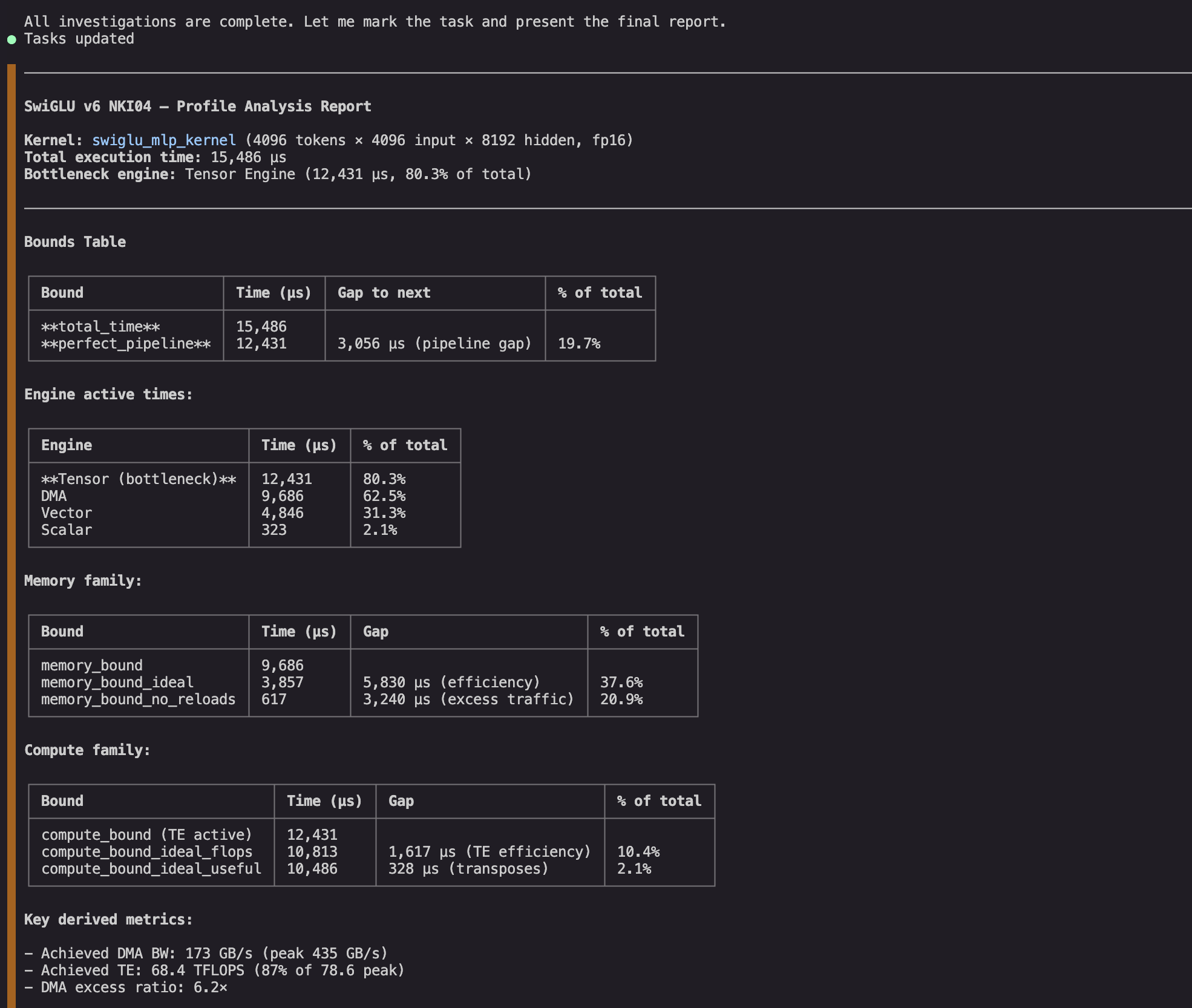
Determine 3: NKI agent extracts abstract statistics and calculates efficiency bounds on the kernel.
It finds a number of gaps value investigating additional. The TE engine dominates execution and is inefficient. It additionally has giant idle gaps, which suggests it could be value investigating its most definitely dependency (DMA engine), the place we will see work that’s each redundant and inefficient.
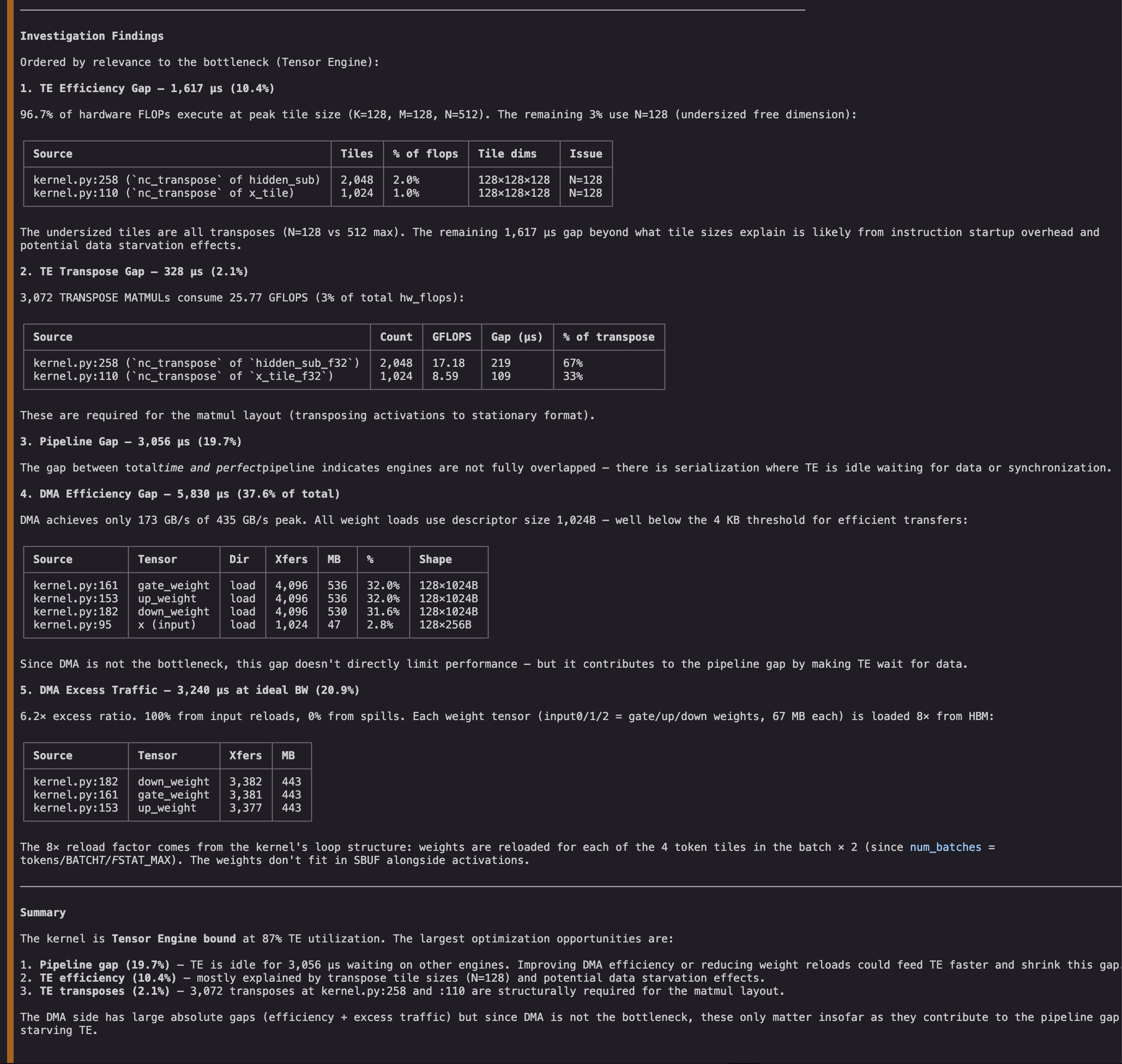
Determine 4: NKI agent investigates inefficiencies within the profile and offers an evaluation.
The investigations assist us audit the gaps and prioritize actionable optimization instructions. Whereas the bottleneck engine’s (Tensor Engine) inefficiency would have been the highest goal for optimization, the agent finds that the NKI matmul directions are already performing close to their peak effectivity. In distinction, we discover that DMA directions are nicely under their goal measurement (inefficient) and that we’re additionally reloading all inputs eight occasions (redundant). We even discover the three actual strains of NKI code chargeable for the suboptimal transfers. Addressing these strains may in flip cut back the TE’s idle hole and enhance kernel latency.
Issues to know
Maintain the next issues in thoughts when working with Neuron Agentic Improvement expertise and brokers.
- Profiling and debugging expertise require execution on precise Trainium or Inferentia-based cases.
- The writing and docs expertise work wherever.
- All expertise goal the present NKI Beta 3 API. Abilities assist Trainium1 (gen2), Trainium2 (gen3), and Trainium 3 (gen4) with acceptable
--targetflags. - The talents and brokers are designed to work collectively. The highest-level agent mechanically invokes profiling and debugging expertise as wanted.
Cleanup
To keep away from ongoing costs, terminate the trn2.3xlarge occasion you created in Step 0. You are able to do this by way of the AWS Administration Console (EC2 > Situations, choose the occasion, and select Occasion state > Terminate), or run:
Verify that the occasion state reveals “terminated” earlier than closing the console.
What’s subsequent
The kernel authoring and profiling expertise decrease the barrier to writing high-performance kernels on Trainium, however they’re solely the primary a part of a broader imaginative and prescient.
As we speak, builders use profiling insights to information their subsequent spherical of kernel edits. This iterative cycle (profile, diagnose, refactor, re-profile) is the place essentially the most time is spent. We need to make this loop absolutely agentic. For instance, brokers that autonomously iterate on a kernel till it meets its efficiency goal, with out requiring the developer to interpret every profiling end result and hand-craft the following repair.
We additionally hear from efficiency builders that customized kernels are just one half of a bigger problem. Builders need their fashions to run on Trainium with out having to fret about porting mannequin code and syntax, resolving operator gaps, making use of model-level optimizations, and validating correctness at scale. We need to convey the identical agentic method to this broader drawback.
In abstract, our imaginative and prescient is to assist the following wave of improvements for frontier fashions utilizing Trainium and the Neuron SDK, and to make use of the suite of Neuron Agentic Improvement capabilities to realize main cost-performance to be used instances starting from experimentation with new mannequin architectures to operating manufacturing fashions at scale.
We are going to share extra as these capabilities mature. To get began with what’s accessible immediately, go to the Neuron Agentic Improvement GitHub repository.
Come construct with us
The Neuron Agentic Improvement capabilities can be found immediately. Get began now: clone the neuron-agentic-development repository and write your first NKI kernel in minutes.
Right here’s how one can dive in:
- Begin with the
neuron-nki-agent. It selects the correct workflow based mostly in your request, supplying you with the complete autonomous expertise end-to-end. - Run the ability examples. Invoke particular person expertise immediately (for instance,
/neuron-nki-writing) for focused duties, or chain/neuron-nki-profilingand/neuron-nki-profile-queryingas soon as your kernel is producing appropriate outcomes. - Open a GitHub subject if you happen to run into an issue or have an concept. We’re actively creating alongside the neighborhood and can get again to you.
- Contribute again. Submit PRs, share kernels you’ve constructed, and assist us make these instruments higher for everybody.
We’re constructing these capabilities within the open as a result of the most effective developer instruments are formed by the builders who use them. Come construct with us.
In regards to the authors



{kind=link}