
If you analyze paperwork that span thousands and thousands of characters, you hit the context window barrier and even the biggest context home windows fall brief. Your mannequin both rejects the enter or produces solutions based mostly on incomplete data. How do you purpose over paperwork that don’t match?
On this put up, you’ll discover ways to implement Recursive Language Fashions (RLM) utilizing Amazon Bedrock AgentCore Code Interpreter and the Strands Brokers SDK. By the tip, you’ll know the way to:
- Course of paperwork of various lengths, with no higher certain on context dimension.
- Use Bedrock AgentCore Code Interpreter as persistent working reminiscence for iterative doc evaluation.
- Orchestrate sub-large language mannequin (sub-LLM) calls from inside a sandboxed Python setting to research particular doc sections.
Why context home windows aren’t sufficient
Think about a typical monetary evaluation process of evaluating metrics throughout two years of annual studies from a single firm. Every report runs 300–500 pages. Add analyst studies, SEC filings, and supplementary supplies, and the entire reaches thousands and thousands of characters.
If you ship these paperwork on to a mannequin, both the enter exceeds the mannequin’s context window restrict and the request fails, or the enter suits however the mannequin has issue attending to data in the midst of lengthy inputs, also known as the “misplaced within the center” drawback.
Each failure modes exist as a result of context window dimension is a tough restrict that immediate engineering alone can’t clear up. You want an method that decouples doc dimension from the mannequin’s context window.
RLMs: Treating context as an setting
RLMs, launched by Zhang et al. in arXiv:2512.24601, reframe the issue. As an alternative of feeding a complete doc into the mannequin’s context window, an RLM treats the enter as an exterior setting that the mannequin interacts with programmatically.
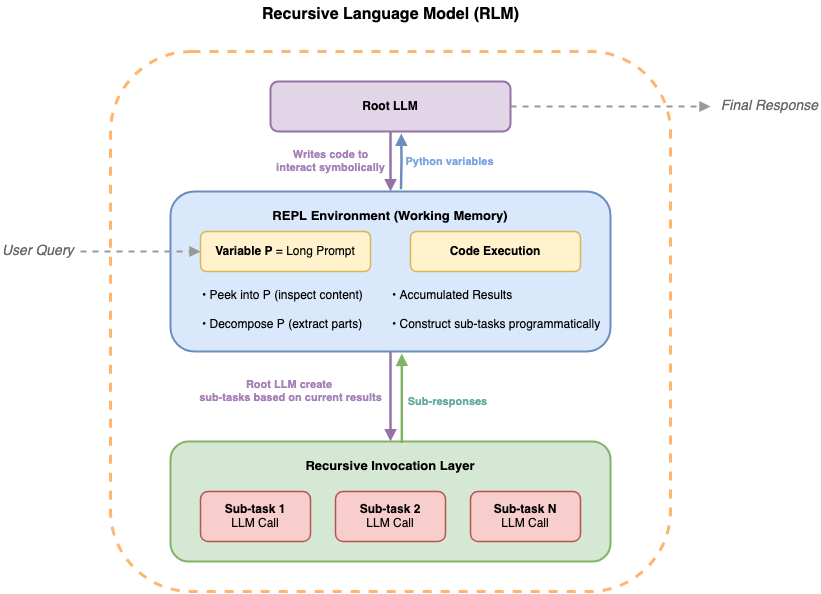
Determine 1. Recursive language fashions function as an iterative loop: the basis LLM generates code to discover the doc setting, delegates semantic evaluation to sub-LLMs on chosen chunks, and accumulates leads to working reminiscence earlier than refining the subsequent step.
The mannequin receives solely the question and an outline of the out there setting. It then writes code to look, slice, and analyze the doc iteratively. When the mannequin wants semantic understanding of a particular part, it delegates that evaluation to a sub-LLM name, protecting the leads to working reminiscence as Python variables fairly than consuming context window area.
This creates a recursive construction: the basis LLM orchestrates the evaluation by means of code, calling sub-LLMs as wanted for semantic duties, whereas the total doc by no means enters the mannequin’s context window.
Structure
Right here, we present the way to implement RLM utilizing Amazon Bedrock AgentCore Code Interpreter because the execution setting. Amazon Bedrock AgentCore Code Interpreter gives a sandboxed Python runtime with persistent state throughout executions. The structure has three parts working collectively.
A root LLM agent, constructed with the Strands Brokers SDK, receives the person’s question and decides what code to execute. An Amazon Bedrock AgentCore Code Interpreter session runs in PUBLIC community mode, with the total doc loaded as a Python variable. A llm_query() operate injected into the sandbox calls Amazon Bedrock instantly from throughout the Code Interpreter, so sub-LLM outcomes keep in Python variables and don’t move again into the basis LLM’s context window.

Determine 2. RLM structure utilizing Amazon Bedrock AgentCore Code Interpreter. The foundation LLM agent iteratively writes and executes Python code in a sandboxed setting the place the total enter knowledge is pre-loaded. From throughout the sandbox, the agent can name sub-LLMs by way of Amazon Bedrock for semantic evaluation of particular sections. Intermediate outcomes stay as Python variables within the sandbox, protecting the basis LLM’s context window centered on orchestration.
Amazon Bedrock AgentCore Code Interpreter’s PUBLIC community mode helps this by permitting the sandbox to make outbound API calls to Amazon Bedrock. The persistent session state means variables, intermediate outcomes, and extracted knowledge accumulate throughout a number of code executions, giving the mannequin working reminiscence that persists all through the evaluation.
Implementation
Observe these steps to arrange and run RLM with Amazon Bedrock AgentCore Code Interpreter.
Stipulations
To observe together with this put up, you want:
- An AWS account with entry to Amazon Bedrock basis fashions (FMs).
- Python 3.10 or later.
- The AWS Command Line Interface (AWS CLI) configured with applicable credentials.
- Familiarity with Python and primary AWS SDK (Boto3) utilization.
- An Amazon Bedrock AgentCore Code Interpreter configured with PUBLIC community mode.
- IAM permissions for
bedrock:InvokeModel,bedrock-agentcore:StartCodeInterpreterSession,bedrock-agentcore:InvokeCodeInterpreter, andbedrock-agentcore:StopCodeInterpreterSession.
1: Begin a Code Interpreter session and cargo the doc
Create an Amazon Bedrock AgentCore Code Interpreter session and write the doc into the sandbox:
2: Initialize the doc and outline the llm_query() helper contained in the sandbox
Contained in the sandbox, load the doc and outline the llm_query() operate that sub-LLM calls will use:
3: Create the Strands Agent and run your question
Create a Strands Agent with a single execute_python device that runs code within the session, then submit your query:
The agent iteratively writes and executes Python code to discover the doc, extract related sections, and name llm_query() when it wants semantic evaluation of particular chunks.
Analysis
In our analysis, we evaluate RLM in opposition to two baselines, specifically Base and Lengthy Context. Within the Base method, the total doc is distributed on to the mannequin in a single API name with 200K token context window. That is essentially the most simple technique however fails when paperwork exceed the mannequin’s context window. Within the Lengthy Context method, we use Claude’s prolonged 1 million token context window, which handles bigger inputs however nonetheless has an higher certain and might endure from issues like “misplaced within the center”.
We evaluated this method on the Monetary Multi-Doc QA subset of LongBench v2, a benchmark designed to check LLM efficiency on duties requiring reasoning throughout lengthy contexts. This subset accommodates 15 multiple-choice questions, every requiring evaluation throughout a number of monetary studies with context lengths as much as roughly 2 million characters.
We report two metrics: success charge, the proportion of questions that the mannequin can course of with out exceeding enter limits or encountering errors, and accuracy, the proportion of appropriate solutions out of the entire questions requested (unanswered questions depend as incorrect).
We in contrast three approaches as described earlier: Base, Lengthy Context, and RLM. We evaluated RLM throughout 4 Claude fashions serving as the basis LLM, the place the sub-LLM was configured as both the identical mannequin or Haiku 4.5 to stability efficiency and effectivity. We use Claude Haiku 4.5 because the sub-LLM as a result of it gives considerably decrease latency and price for localized chunk-level evaluation, whereas the basis mannequin retains accountability for world reasoning and orchestration.
Desk 1. LongBench v2 Monetary Multi-Doc QA (15 questions). Human professional accuracy from the LongBench v2 paper. Base outcomes for Claude Sonnet 4.6 and Opus 4.6 are omitted as a result of these fashions have a default 1 million token context window, making the Base and Lengthy Context approaches equal.
| Mannequin | Strategy | Success charge | Accuracy |
| Claude Haiku 4.5 | Base | 46.7% | 33.3% |
| Claude Haiku 4.5 + Haiku 4.5 | RLM | 100.0% | 66.7% |
| Claude Sonnet 4.5 | Base | 46.7% | 26.7% |
| Claude Sonnet 4.5 | Lengthy Context | 93.3% | 66.7% |
| Claude Sonnet 4.5 + Haiku 4.5 | RLM | 100.0% | 66.7% |
| Claude Sonnet 4.6 | Lengthy Context | 93.3% | 60.0% |
| Claude Sonnet 4.6 + Haiku 4.5 | RLM | 100.0% | 73.3% |
| Claude Opus 4.6 | Lengthy Context | 93.3% | 66.7% |
| Claude Opus 4.6 + Haiku 4.5 | RLM | 100.0% | 80.0% |
| Human Knowledgeable | – | – | 40% |
The outcomes reveal three key findings:
- RLM alleviates context size failures. Base and Lengthy Context approaches fail to course of some inputs because of context limitations. The Base method achieves a hit charge of 46.7 % (7/15 questions), whereas Lengthy Context achieves 93.3 % (14/15 questions). In distinction, RLM achieves a one hundred pc success charge throughout all evaluated configurations by decoupling doc dimension from context window dimension totally. As doc scale will increase, this reliability benefit turns into more and more essential for sensible deployment.
- RLM improves accuracy throughout most fashions. RLM will increase accuracy for Claude Sonnet 4.6 and Opus 4.6 from 60.0 % and 66.7 % (Lengthy Context) to 73.3 % and 80.0 %, respectively, and for Claude Haiku 4.5 from 33.3 % (Base) to 66.7 %. The most important enchancment is noticed for Claude Haiku 4.5, whereas stronger fashions (Sonnet 4.6, Opus 4.6) present constant however smaller features. Claude Sonnet 4.5 reveals no enchancment over the Lengthy Context baseline, attaining 66.7 % in each settings. This implies that RLM features depend upon how successfully the basis mannequin decomposes the duty into sub-queries, which could restrict enhancements for Sonnet 4.5 on this setting.
- Sub-LLM alternative has restricted influence on this setting. In extra experiments, we evaluate utilizing Claude Haiku 4.5 because the sub-LLM in comparison with utilizing the identical mannequin for each root and sub-LLM, and observe no vital distinction in accuracy throughout configurations. This implies that, for this process, efficiency is primarily pushed by the basis mannequin’s capacity to generate efficient sub-queries fairly than the aptitude of the sub-LLM executing them.
Scaling to code repository understanding: LongBench v2 CodeQA
The Monetary QA analysis focuses on long-form doc reasoning. We subsequent look at generalization to a distinct area: code repository understanding, which requires navigating giant codebases, resolving operate dependencies, and tracing logic throughout recordsdata. This setting is especially effectively suited to programmatic exploration by means of code execution.
To check this, we evaluated on the Code Repository Understanding subset of LongBench v2, which accommodates 50 multiple-choice questions. Every query gives a complete code repository as context (starting from ~ round 100K to over 16M characters) and asks about implementation particulars, API conduct, or architectural selections that require navigating and understanding the codebase.
The structure is identical as for Monetary QA the place the total repository is loaded into the Code Interpreter sandbox as a single context variable. The mannequin writes Python code to seek for related recordsdata, extract operate definitions, hint name chains, and use llm_query() to research particular code sections.
We evaluated all 50 questions utilizing 4 Claude fashions with the identical approaches. Based mostly on the Monetary QA discovering that sub-LLM alternative has restricted influence for stronger fashions, we repair the sub-LLM to Claude Haiku 4.5 throughout RLM runs.
Desk 2. LongBench v2 Code Repository Understanding (50 questions).
| Mannequin | Strategy | Success Charge | Accuracy |
| Claude Haiku 4.5 | Base | 30.0% | 20.0% |
| Claude Haiku 4.5 + Haiku 4.5 | RLM | 100.0% | 64.0% |
| Claude Sonnet 4.5 | Base | 30.0% | 20.0% |
| Claude Sonnet 4.5 | Lengthy Context | 60.0% | 46.0% |
| Claude Sonnet 4.5 + Haiku 4.5 | RLM | 100.0% | 76.0% |
| Claude Sonnet 4.6 | Lengthy Context | 60.0% | 42.0% |
| Claude Sonnet 4.6 + Haiku 4.5 | RLM | 100.0% | 66.0% |
| Claude Opus 4.6 | Lengthy Context | 60.0% | 44.0% |
| Claude Opus 4.6 + Haiku 4.5 | RLM | 100.0% | 74.0% |
The outcomes mirror the Monetary QA findings: RLM achieves one hundred pc success charge throughout all fashions, in comparison with 30–60 % for Base and Lengthy Context. Accuracy improves considerably throughout fashions beneath RLM, with each mannequin attaining between 64 % and 76 %—up from 20–46 % beneath Base and Lengthy Context.
How the mannequin works by means of an issue
For instance how RLM operates in apply, the next is a consultant sequence from one of many analysis questions. The mannequin is requested to check monetary metrics throughout two annual studies totaling roughly 1.5 million characters.
First, the mannequin searches the context for structural markers to grasp the doc format:
Subsequent, it slices into particular sections to seek out income tables:
For semantic evaluation, it delegates to the sub-LLM:
Lastly, it aggregates findings throughout a number of sections and arrives at a closing reply.
Concerns
When adopting RLM on your doc evaluation workloads, hold the next sensible tradeoffs in thoughts.
- Latency. RLM trades latency for functionality. Based mostly on our analysis of the 2 LongBench v2 datasets, particular person RLM runs vary from about 10 seconds for simple inquiries to a number of minutes for complicated questions with giant contexts, with most finishing inside a couple of minutes. For batch processing or offline evaluation, this tradeoff is effectively justified. For real-time functions, contemplate whether or not the duty really requires processing paperwork past the mannequin’s context window.
- Value. Every RLM run entails a number of mannequin invocations, each the basis LLM’s iterative reasoning and the sub-LLM calls from throughout the sandbox. For cost-sensitive workloads, you need to use a smaller mannequin (resembling Haiku 4.5) because the sub-model whereas protecting a bigger mannequin as the basis to cut back prices whereas sustaining accuracy.
- Immediate engineering. The system immediate impacts how effectively the mannequin makes use of its instruments. With out steering, fashions are likely to make pointless sub-LLM calls to validate their very own reasoning or print verbose intermediate summaries by means of code execution. Clear directions about when to make use of code execution in comparison with when to purpose instantly scale back wasted device calls and enhance end-to-end latency.
Cleansing up
To keep away from ongoing prices, cease the Amazon Bedrock AgentCore Code Interpreter session when the evaluation is full:
Should you created a devoted Code Interpreter useful resource for this walkthrough and not want it, you possibly can delete it by means of the Amazon Bedrock AgentCore console or the AWS CLI.
Conclusion
Recursive language fashions provide a sensible path to processing paperwork that exceed mannequin context home windows. By combining Amazon Bedrock AgentCore Code Interpreter with the Strands Brokers SDK, you possibly can implement RLM to purpose over arbitrarily lengthy enter knowledge by means of iterative code execution and sub-LLM calls.
Throughout our evaluations, the outcomes are vital: Claude Opus 4.6 with RLM achieves 80.0 % accuracy on LongBench v2 Monetary QA (in comparison with 66.7 % for Lengthy Context with 1 million token context window and 40 % for human specialists), and Claude Sonnet 4.5 with RLM achieves 76.0 % on LongBench v2 Code Repository QA (in comparison with 20.0 % for Base prompting with 200K token context window, 46.0 % for Lengthy Context).
Duties that require reasoning over lengthy contexts or giant reference libraries can profit from this sample, whether or not it’s monetary evaluation, code repository understanding, healthcare and life sciences analysis, authorized assessment, or compliance auditing. Should you do this method by yourself doc evaluation workloads, we need to hear what you construct. Share your expertise within the feedback.
To get began with the method described on this put up, discover the next sources:
References
- Zhang, A. L., Kraska, T., & Khattab, O. (2025). Recursive Language Fashions. arXiv:2512.24601
- Bai, Y., Tu, S., Zhang, J., Peng, H., Wang, X., Lv, X., Cao, S., Xu, J., Hou, L., Dong, Y., Tang, J., & Li, J. (2024). LongBench v2: In the direction of Deeper Understanding and Reasoning on Real looking Lengthy-context Multitasks. arXiv:2412.15204
Concerning the authors



{kind=link}