
Constructing multi-tenant AI purposes presents new architectural challenges. You want full tenant isolation between prospects, completely different service tiers with completely different capabilities, granular price monitoring, and observability per tenant. With out these, you would danger exposing buyer information, not offering applicable high quality of service to your prospects or operating up unexpected prices.
On this publish, you’ll study patterns for implementing production-ready multi-tenant methods utilizing Amazon Bedrock AgentCore. You will note these patterns demonstrated by means of healthcare AI brokers that serve a number of clinics and hospitals. Whereas the publish makes use of healthcare as the instance area, the architectural patterns and implementation methods apply broadly to numerous multi-tenant AI purposes. Whether or not you’re constructing SaaS platforms, enterprise options serving a number of enterprise models, or managed companies for various buyer organizations, you should use these architectural patterns to construct your resolution.
What you’ll study
- Easy methods to implement full tenant isolation in agentic purposes utilizing native AWS capabilities.
- Patterns for service tier differentiation with minimal customized code.
- Strategies for granular price attribution per tenant.
- Finest practices for scalable multi-tenant AI architectures.
This weblog publish is a component 2 of the sequence, Constructing multi-tenant brokers with Amazon Bedrock AgentCore. Half 1 explores design concerns for architecting multi-tenant agentic purposes and the framework wanted to deal with SaaS structure challenges with Amazon Bedrock AgentCore.
GitHub repo for the pattern code: https://github.com/aws-samples/sample-agentcore-and-multitenancy-blog
Answer overview
This resolution demonstrates the way to use native capabilities of Amazon Bedrock AgentCore to attain full tenant isolation utilizing AWS-managed companies. The structure implements a three-level hierarchy: Tier → Tenant → Consumer, the place you implement isolation at each layer by means of paperwork in data base, reminiscence, mannequin entry, and price monitoring. A tiering technique is a typical sample in SaaS purposes the place tenants are grouped into distinct service tiers primarily based on their wants – reminiscent of Primary and Premium, utilization patterns, or pricing plans. Every tier defines a set of options and high quality of service obtainable to tenants inside that group. This method permits SaaS suppliers to serve a various buyer base with differentiated experiences whereas sustaining operational effectivity.
Healthcare AI assistant instance
To see how this works in follow, the instance resolution implements two service tiers for tier-based differentiation:
- Primary Tier: Designed for small clinics and practices that primarily want easy doc search and retrieval. As a result of these duties are well-suited to a smaller, cost-effective mannequin, this tier makes use of Mistral Ministral 3 8B Instruct, conserving prices low whereas nonetheless delivering correct outcomes for easy queries.
- Premium Tier: Designed for hospitals and specialty facilities that require advanced scientific evaluation. This tier makes use of OpenAI GPT OSS 120B with superior reasoning capabilities for correct instrument choice, together with the net search instrument which is simply obtainable to premium tier prospects.
Inside every tier, this resolution makes use of a pool isolation mannequin, the place tenants share the identical underlying infrastructure and compute sources somewhat than having devoted, siloed sources per tenant. The pool mannequin maximizes useful resource utilization and simplifies operations, whereas tenant isolation is enforced by means of logical separation mechanisms reminiscent of scoped identifiers, entry insurance policies, and information partitioning. Combining a tiering technique with a pool mannequin lets you stability price effectivity with the flexibleness to supply differentiated service ranges.
Structure
Let’s have a look at how primitives from AgentCore come collectively to resolve these multi-tenancy challenges. The next diagram illustrates the multi-tenant structure for the answer, exhibiting how requests movement from authenticated customers by means of tier-specific brokers to remoted doc storage:
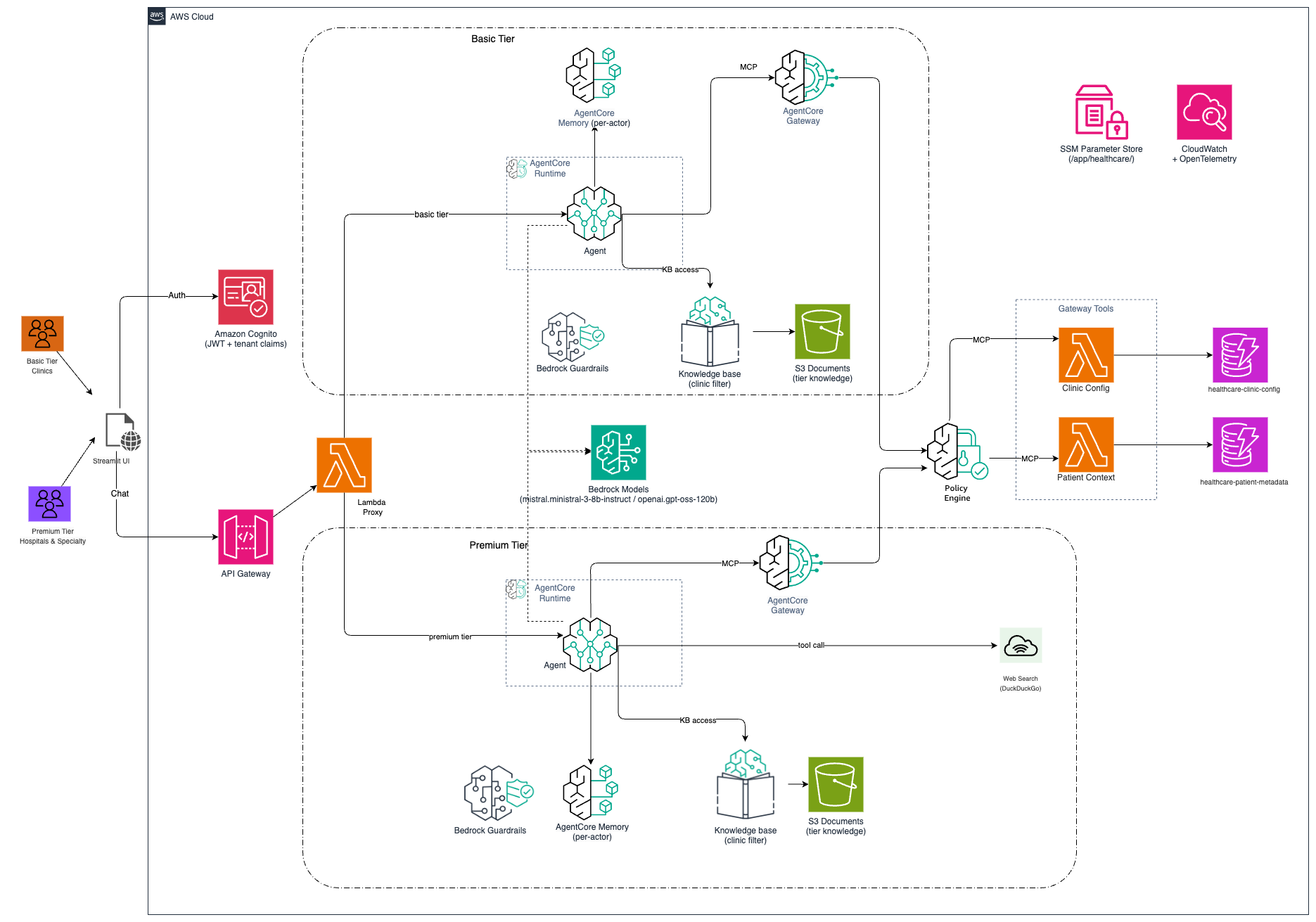
Determine 1: Multi-tenant structure with hierarchical isolation (Tier → Tenant → Consumer).
The answer consists of those key parts:
- Amazon Cognito: Manages consumer authentication and shops tenant metadata (tier, clinic_id, function) in JSON Internet Token (JWT) claims. These claims are extracted and propagated as tenant context by means of the request payload, enabling every downstream part to scope its operations to the right tenant.
- Amazon API Gateway: Routes requests and enforces tier-based price limiting by way of utilization plans
- AWS Lambda: Extracts tenant context and invokes the corresponding Amazon Bedrock AgentCore agent
- AgentCore parts: Runtime (agent execution), Reminiscence (dialog state), Id (agent id administration), Gateway (instrument server), and Coverage (agent motion boundary)
- Amazon Easy Storage Service (Amazon S3): Shops scientific paperwork in tier-separated buckets with hierarchical prefix construction for tenant isolation
- Amazon Bedrock Data Bases: Offers semantic search with metadata filtering to scope queries to the requesting tenant’s paperwork
- Amazon Bedrock challenge: Permits per-tier price monitoring by way of price allocation tags
Answer walkthrough
This part describes the important thing points of the answer. You run the deploy script to arrange the infrastructure and software for the answer. The code excerpts on this part are solely used to explain how the important thing points of the structure are being addressed by parts of the answer. There isn’t any must run any instructions or execute any code snippets proven right here.
Amazon Bedrock AgentCore parts
The structure leverages six core Bedrock AgentCore capabilities to implement multi-tenancy:
AgentCore Runtime: AgentCore Runtime supplies the compute for the brokers on this resolution, with every agent session execution in an remoted micro-VM for tenant-level compute isolation. It hosts separate agent cases per tier, every configured with tier-appropriate fashions and capabilities.
AgentCore Id: AgentCore Id secures the multi-tenant structure with a unified JWT-based authentication mannequin. The Cognito ID token validates the consumer at each the Runtime and Gateway boundaries, whereas instrument Lambdas mint their very own scoped credentials for downstream information entry.
Every AgentCore Runtime is configured with an inbound JWT authorizer that validates Cognito ID tokens earlier than agent code execution. The ID token carries tenant metadata as customized claims:
| Declare | Instance Worth | Objective |
| sub | a4589458-8011-… | Distinctive consumer identifier (Cognito UUID) |
| iss | https://cognito-idp.us-east-1.amazonaws.com/us-east-1_AbCdEfG | Token issuer, validated by AgentCore Runtime |
| aud | 7rfbikfsm51j… | Internet shopper ID, validated by Runtime’s allowedAudience |
| token_use | id | Identifies this as an ID token (not entry token) |
| exp | 1745446200 | Expiration timestamp (default: 1 hour from subject) |
| cognito:username | dr.foster@hospital-a.com | Login username, used as user_id for reminiscence isolation |
| customized:tier | premium | Routes to appropriate mannequin, data base, and gateway |
| customized:clinic_id | hospital-a | That is tenant ID. Enforces information isolation throughout KB, reminiscence, and Amazon DynamoDB |
| customized:function | doctor | Function-based entry management (future extensibility) |
The authorizer is configured throughout agent deployment:
The AgentCore Gateway can also be configured with JWT authorization, utilizing the identical Cognito discovery URL and viewers. When the agent calls the gateway, it forwards the consumer’s authentic JWT as a Bearer token for validation, together with tenant context headers (X-Tier, X-Clinic-ID, X-S3-Prefix). The gateway validates the token, then propagates the tenant headers to the goal Lambda by way of metadataConfiguration.
The goal Lambda by no means receives or processes the consumer’s JWT straight. As a substitute, it reads the trusted tenant headers (trusted as a result of solely authenticated requests go the gateway’s CUSTOM_JWT authorizer) and assumes a TVM (Token Merchandising Machine) function with session tags derived from these headers. The TVM function’s ABAC coverage restricts DynamoDB entry utilizing dynamodb:LeadingKeys circumstances, making certain every tenant can solely question their very own clinic’s information on the IAM stage, not simply application-level filtering.
AgentCore Reminiscence: Dialog historical past can not leak between tenants or between a number of customers inside a tenant. The answer enforces reminiscence isolation at two layers: application-level scoping and IAM-backed Attribute-Primarily based Entry Management (ABAC).
On the software layer, AgentCore Reminiscence makes use of a hierarchical namespace construction with a composite actor_id to arrange dialog information per tenant:
Namespaces separate several types of reminiscence:
To implement isolation on the infrastructure stage, the answer makes use of a Token Merchandising Machine (TVM) sample with ABAC. At runtime, the agent assumes a TVM function with Tier, ClinicId, and UserId as session tags, receiving momentary credentials scoped to that tenant’s namespace:
The TVM function’s belief coverage ensures solely the agent execution function can assume it, and that each one three session tags are current:
AgentCore Gateway: AgentCore Gateway transforms static Lambda capabilities into dynamic, context-aware agent instruments utilizing the Mannequin Context Protocol (MCP). Mannequin Context Protocol is an open-source customary for connecting AI brokers to exterior instruments.
AgentCore Gateway eliminates the necessity to construct customized instrument orchestration logic. With out this, you would want to manually combine APIs into agent workflows. This entails writing customized code to parse API specs, deal with authentication, handle transformations, implement error dealing with, and propagate tenant context.
The Lambda perform exposes two instruments by means of the Gateway:
patient_context: Retrieve affected person demographics and medical historical past from the PatientMetadata DynamoDB desk.clinic_config: Get clinic configuration and supplier info from the ClinicConfig DynamoDB desk.
As talked about beforehand, tenant id is propagated all through every part. The agent initializes its MCP Gateway shopper with tenant-scoped headers (X-Tier, X-Clinic-ID, X-S3-Prefix), so each instrument name by means of the gateway mechanically carries tenant context, implementing information isolation on the gateway layer with out per-tool filtering logic. This hyperlink supplies extra details about gateway headers.
The gateway helps three authentication mechanisms:
- IAM function: For AWS service integrations.
- Customized JWT: For tenant-aware instruments (what we’re utilizing).
- OAuth: For third-party API integrations.
AgentCore Coverage: AgentCore Coverage enforces tier-specific motion boundaries on gateway instruments utilizing Cedar authorization insurance policies. The answer creates a shared coverage engine hooked up to each the fundamental and premium gateways in ENFORCE mode. For the fundamental tier, a Cedar coverage restricts the patient_context instrument to enterprise hours (8 AM–6 PM) by evaluating the request_hour discipline from the instrument’s enter. The agent should name current_time first and go the present hour, and the coverage engine denies the decision if the hour falls exterior the allowed window. For the premium tier, the coverage permits patient_context unconditionally, giving hospitals 24/7 entry. Each tiers get specific permits for the clinic_config instrument because it exposes non-sensitive configuration information. This method strikes entry management out of software code and into declarative Cedar insurance policies evaluated on the gateway layer, so tier differentiation is enforced earlier than the Lambda perform ever executes.
AgentCore Observability: AgentCore’s observability integration makes use of OpenTelemetry baggage to propagate tenant metadata by means of your complete request lifecycle. OpenTelemetry baggage is a key-value retailer which helps you to propagate further information alongside hint context. The answer units tenant identifiers as baggage on the AgentCore Runtime entrypoint, so each downstream span and log entry carries tenant attribution:
For instance, you should use Amazon CloudWatch Logs Insights to trace quantity of requests per clinic
Mixed with Bedrock Initiatives for per-tier price attribution and structured utilization logging for per-clinic token monitoring, this offers you tenant-level visibility throughout mannequin utilization, agent execution, and reminiscence operations.
Key multi-tenancy implementation patterns
This part describes how the answer achieves the core patterns for implementing multi-tenancy with Amazon Bedrock AgentCore.
1. Knowledge isolation by way of per-tier S3 buckets
Within the healthcare resolution instance, the system creates a separate S3 bucket per service tier, with tenant-specific prefixes inside every bucket. Every tier’s Data Base has its personal devoted S3 bucket, offering bucket-level isolation between tiers. Inside every bucket, hierarchical prefixes manage tenant information, enabling isolation by means of path-based entry management and Data Base metadata filtering:
Inside every bucket, the S3 prefix is constructed from tenant id extracted from Cognito JWT claims (customized:tier, customized:clinic_id). This prefix is then utilized in two methods: it’s handed as an X-S3-Prefix header on each MCP Gateway instrument name for gateway-level enforcement, and the doc retrieval instrument enforces isolation by means of Amazon Bedrock Data Base metadata filter on clinic_id:
2. Value attribution by way of Bedrock Initiatives and structured utilization logging
Value attribution operates at two ranges: per-tier by means of Bedrock Initiatives, and per-clinic by means of structured utilization logging.
Per-tier attribution with Bedrock Initiatives: Every tier has a devoted Bedrock Mission tagged with price allocation metadata (CostCenter, Tier, Software). The challenge ID is handed on each inference request by means of the Bedrock Mantle endpoint, so all mannequin invocation prices are mechanically segmented by tier in AWS Value Explorer.
At runtime, the agent passes the challenge ID on each inference request by means of the Bedrock Mantle (OpenAI-compatible) endpoint. This implies each mannequin invocation is mechanically tagged with the tier’s price metadata:
When you activate price allocation tags in AWS Billing (tags could take as much as 24 hours to propagate), you may filter and group inference prices by CostCenter, Tier, or Software in AWS Value Explorer. This offers you per-tier price visibility. For instance, evaluating the price of operating Ministral 3 8B Instruct for primary tier clinics towards GPT OSS 120B for premium tier hospitals.
Per-clinic attribution with structured utilization logging: Bedrock Initiatives have a restrict of 1,000 per account and are advisable for application-level boundaries. For per-clinic price granularity, the answer logs token utilization after every agent invocation as structured JSON with the tenant context already flowing by means of the system:
The Strands SDK mechanically tracks token consumption (enter, output, and cache metrics) on each agent invocation by means of the AgentResult.metrics object. By pairing this with the clinic_id from the tenant context, every log entry attributes token utilization to a particular clinic. These logs land in CloudWatch and may be queried with Logs Insights to compute per-clinic utilization:
To estimate prices, you may multiply the token counts by the revealed per-token pricing for every mannequin.
3. Charge limiting by way of API Gateway
The speed limiting for every tier is enforced utilizing API Gateway utilization plans. The answer makes use of separate utilization plans per tier with the next configuration:
Cleanup
To keep away from ongoing costs, you may delete the deployed sources once you not want them. A cleanup.sh helper script (underneath the scripts/ folder) is supplied to help with the cleanup of sources created for this resolution.
Conclusion
Constructing multi-tenant AI purposes requires cautious consideration to information isolation, service differentiation, price attribution, and scalability. Amazon Bedrock AgentCore supplies a strong basis for addressing these necessities by means of native platform capabilities. The important thing takeaway from this implementation is that multi-tenancy doesn’t require advanced application-level isolation logic. By combining AWS companies like Cognito for id, S3 prefixes for information isolation, API Gateway for price limiting, Bedrock Initiatives and structured logging for price attribution and Bedrock AgentCore for AI orchestration, you may construct safe, scalable, and cost-effective multi-tenant AI purposes with minimal customized code. You possibly can apply these patterns to any multi-tenant agentic purposes you’re constructing.
Additional studying
- View the entire supply code on GitHub
- Study extra about Amazon Bedrock AgentCore
- Constructing multi-tenant brokers with Amazon Bedrock AgentCore
Concerning the authors


{kind=link}