
Monitoring and troubleshooting generative AI inference endpoints working at scale is difficult. When your massive language mannequin (LLM) endpoint’s P99 latency spikes, you need to decide in minutes whether or not the foundation trigger is GPU reminiscence stress, a saturated KV cache, unbalanced site visitors throughout Availability Zones, or an auto scaling coverage that hasn’t triggered. The shift from coaching to serving is reshaping how groups deploy LLMs and different generative AI fashions in manufacturing. Machine studying (ML) platform engineers, MLOps groups, and website reliability engineers (SREs) should hold inference endpoints wholesome, responsive, and cost-efficient, usually throughout dozens of fashions and tons of of GPU cases.
Amazon SageMaker AI offers absolutely managed real-time inference internet hosting for machine studying fashions. You deploy a mannequin to a SageMaker endpoint backed by a number of compute cases, and SageMaker handles provisioning and scaling. SageMaker helps a number of endpoint architectures. This publish focuses on the 2 most related to generative AI workloads with detailed observability:
- Single-model endpoints (SME) – Every endpoint hosts one mannequin on devoted cases. SMEs are easy to arrange and cause about, however every mannequin requires its personal fleet of GPU cases.
- Inference element (IC) endpoints – A number of fashions share the identical set of cases by way of inference parts. Every inference element defines a mannequin, its useful resource necessities (CPU, GPU, reminiscence), and its scaling coverage. IC endpoints are the advisable structure for manufacturing generative AI workloads as a result of they help multi-model internet hosting on shared GPU infrastructure, impartial scaling per mannequin, and excessive availability (HA) by way of copy distribution throughout AZs.
SageMaker endpoints emit metrics like invocation counts, mannequin latency, and overhead latency to Amazon CloudWatch. These combination metrics are helpful for understanding general endpoint well being. As a result of groups scale to multi-model deployments on GPU fleets, they want deeper alerts. Amazon SageMaker AI now emits over 100 detailed inference metrics. These cowl GPU well being, token-level latency, KV cache stress, site visitors distribution throughout AZs, inference element placement, and chilly begin diagnostics. These metrics circulate to a built-in SageMaker Insights dashboard in Amazon CloudWatch, a completely managed observability resolution that removes the necessity for customized Grafana dashboards and Prometheus configuration. The SageMaker Insights dashboard helps each endpoint varieties and mechanically reveals IC-specific panels when inference parts are detected.
For extra particulars on SageMaker inference, see Deploy fashions for real-time inference.
On this publish, you’ll discover ways to:
- Activate detailed observability metrics on new and current SageMaker inference endpoints.
- Navigate the SageMaker Insights dashboard to watch fleet well being throughout Efficiency, Capability, and Reliability views.
- Join the metrics to your personal observability device (Grafana, Datadog) by way of the PromQL-compatible endpoint.
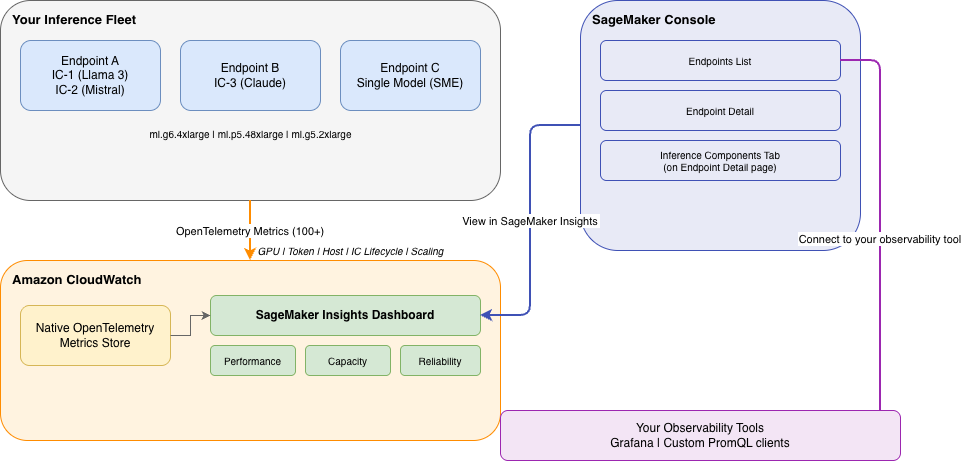
SageMaker inference observability overview
SageMaker inference endpoints emit native OpenTelemetry metrics to CloudWatch. The SageMaker Insights dashboard is situated within the CloudWatch console underneath Infrastructure Monitoring → SageMaker Insights. It queries these metrics utilizing PromQL and renders visualizations on the fleet, endpoint, and inference-component stage throughout three tabs: Efficiency, Capability, and Reliability.
- Efficiency – Fleet well being, token latency, throughput, errors, engine stress.
- Capability – GPU, CPU, and reminiscence utilization of the fleet.
- Reliability – Availability Zone distribution, scaling occasions, chilly begin anatomy, and inadequate capability errors.
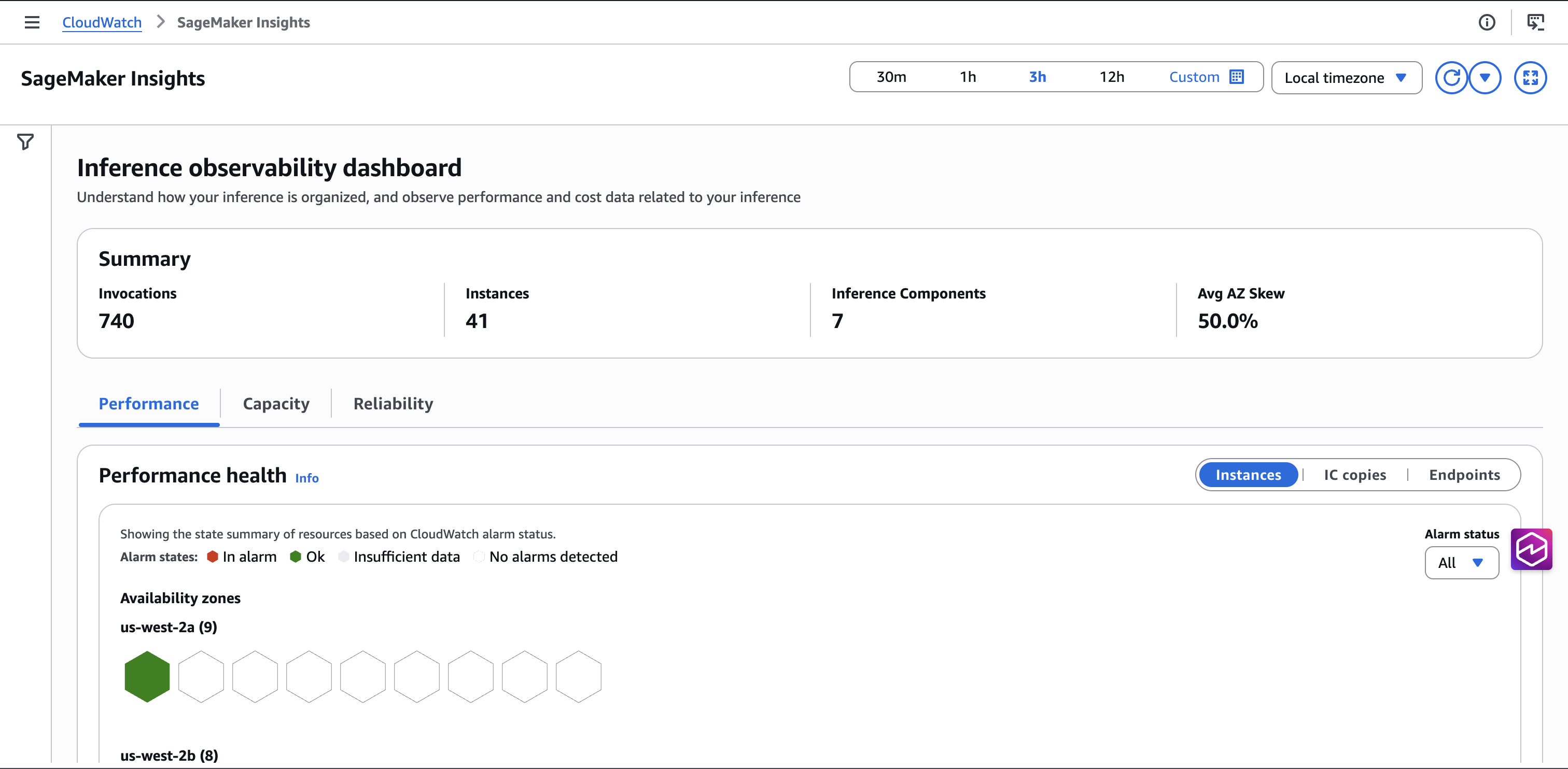
Key providers
- Amazon SageMaker AI – Managed inference with endpoints and inference parts.
- Amazon CloudWatch – Native help for OpenTelemetry metrics and PromQL queries by way of SageMaker Insights.
For background on the OpenTelemetry and PromQL help in CloudWatch, see Introducing OpenTelemetry PromQL help in Amazon CloudWatch.
Conditions
You will need to have the next to comply with together with this publish.
- An AWS account with at the very least one SageMaker real-time inference endpoint.
- AWS Identification and Entry Administration (IAM) permissions:
sagemaker:CreateEndpointConfig,sagemaker:UpdateEndpoint, andcloudwatch:GetMetricData. - vLLM or SGLang container framework (required for token-level metrics like TTFT and ITL).
GPU cases obtain per-accelerator utilization metrics along with the CPU and reminiscence metrics out there on all occasion varieties. For the total setup information, see Getting began with detailed observability.
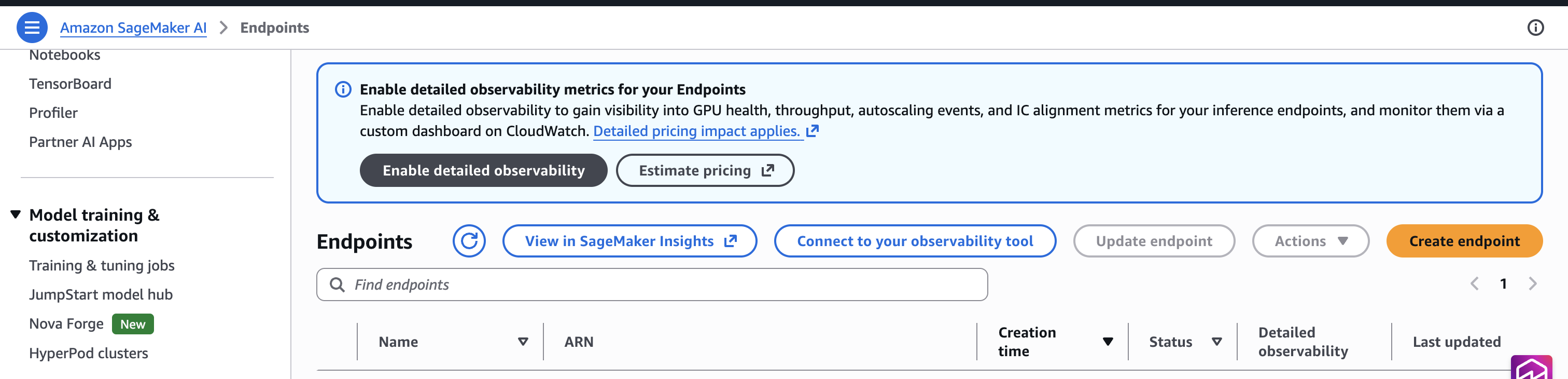
Activate detailed metrics in your endpoints
New endpoints: Computerized (default-on)
For any new endpoint configurations you create, detailed metrics are turned on by default. The EnableDetailedObservability parameter in your endpoint configuration defaults to true. No extra code is required.
The EnableDetailedObservability flag in your endpoint configuration defaults to true, so no extra configuration is required. You can even explicitly set the publishing frequency utilizing MetricsPublishFrequencyInSeconds in MetricsConfig. The default is 60 seconds. For workloads that want close to real-time monitoring, you’ll be able to set it to lower than a minute.
Inside 2 minutes of the endpoint reaching InService, the OpenTelemetry format metrics start flowing to CloudWatch.
Current endpoints: Decide-in
Current endpoints require an specific opt-in. Create a brand new endpoint configuration with the MetricsConfig flag, then replace your endpoint. This follows the identical sample as any endpoint configuration change.
The SageMaker console additionally offers a guided three-step wizard after you select Allow detailed observability: be taught in regards to the metrics, activate OTel enrichment, and choose which endpoints to decide in.
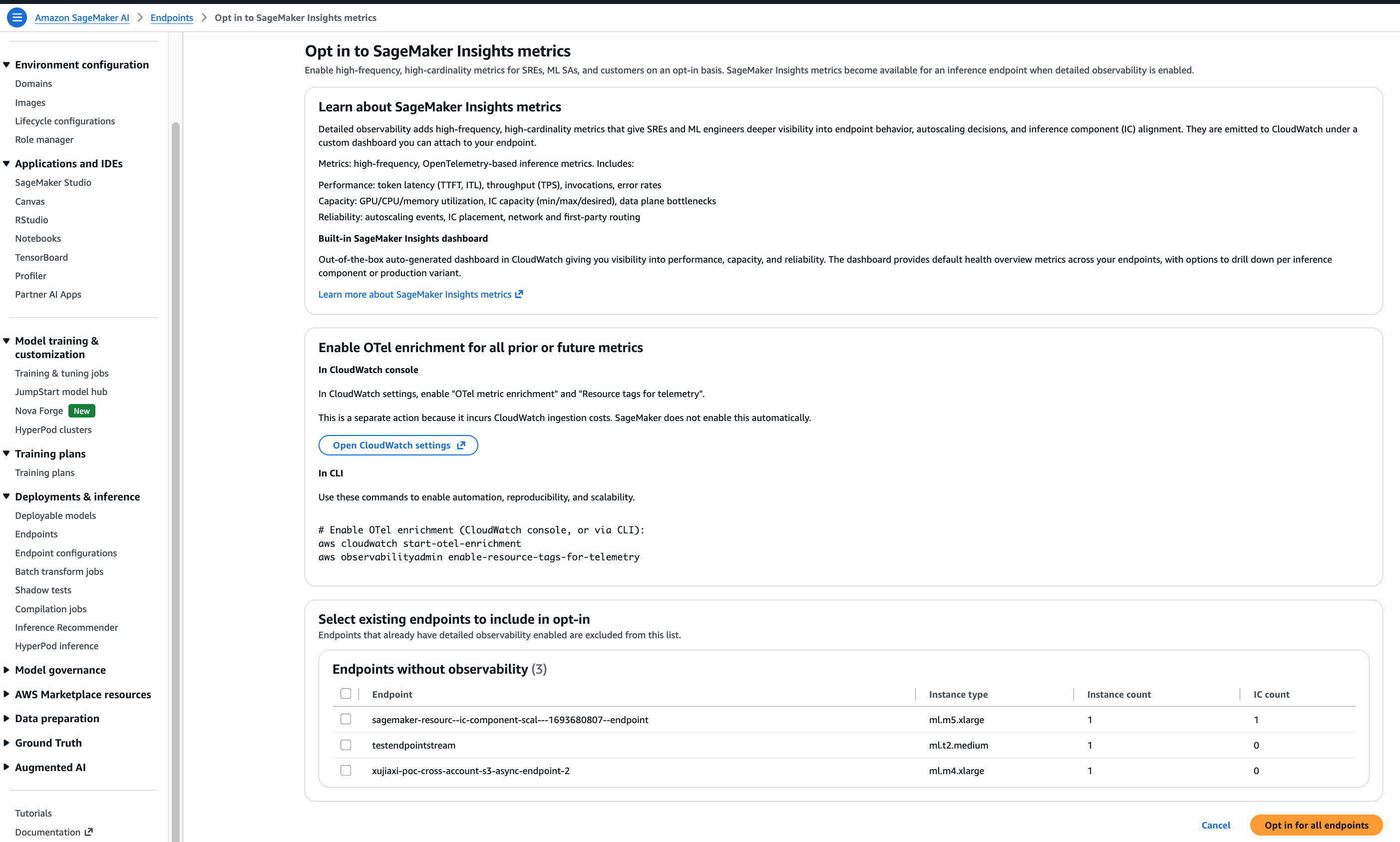
Allow OTel enrichment for traditional CloudWatch metrics
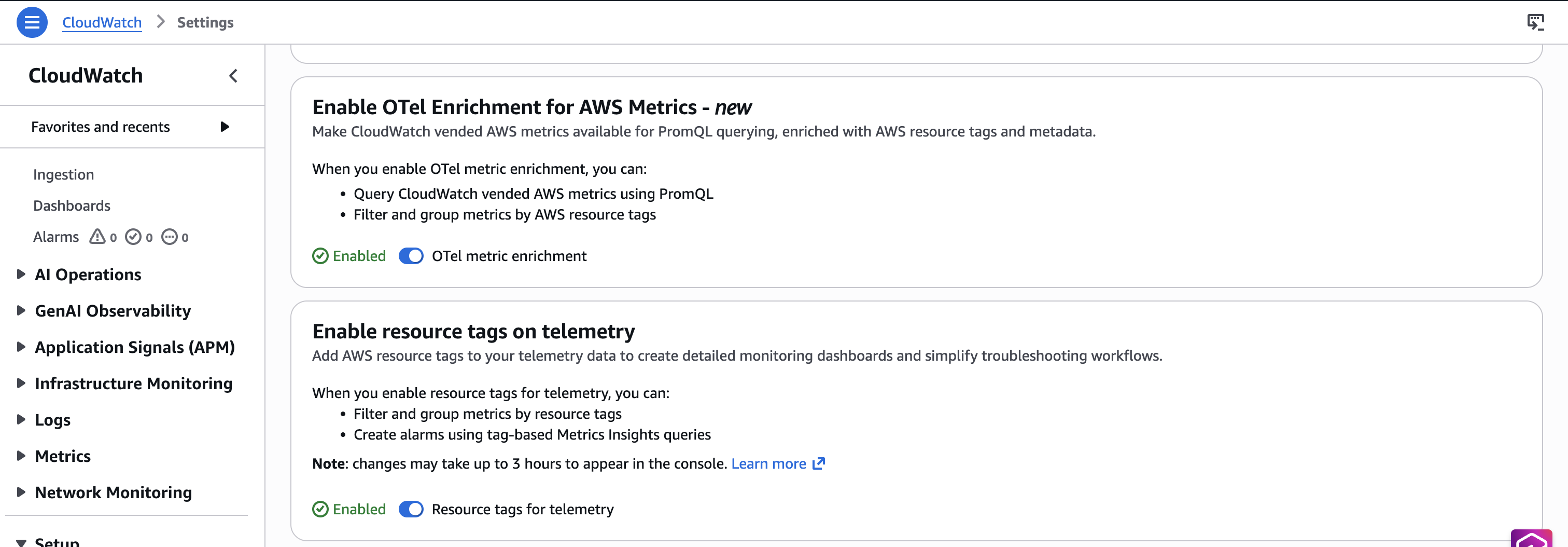
Native OpenTelemetry metrics circulate mechanically to CloudWatch after enablement. Nevertheless, current traditional metrics (Invocations, ModelLatency, OverheadLatency) require OTel enrichment to be seen within the SageMaker Insights dashboard and queryable with PromQL.
Navigate to CloudWatch Console then Settings and activate OTel metric enrichment and Useful resource tags for telemetry. It is a one-time, account-level and AWS Area-level setting.
Navigate to the SageMaker Insights dashboard from the SageMaker console
You may entry the SageMaker Insights dashboard by way of both the SageMaker console or the CloudWatch console. Inside SageMaker, there are three entry factors, every pre-filtered to their context:
| # | Entry Level | Filter Utilized | Use Case |
| 1 | Endpoints listing web page → “Open SageMaker Insights” | Fleet-level (all endpoints) | “Give me the massive image” |
| 2 | Endpoint element web page → “View in SageMaker Insights” | Filtered to that endpoint | “Drill into this particular endpoint” |
| 3 | IC tab → per-IC “Metrics” hyperlink | Filtered to endpoint + IC | “Debug this inference element” |
Each path deep-links with pre-applied filters, so that you received’t land on a clean dashboard looking for your assets.

Efficiency tab: Monitoring fleet well being and debugging latency
The Efficiency tab is the place most prospects spend their time. It solutions questions like “Is all the things working nicely?” and “If not, which element is the issue?” The Efficiency tab consists of a number of time-series panels that work collectively to pinpoint latency points.
Efficiency well being and occasion efficiency desk
Shade-coded hexagons visualize each useful resource in your fleet. Toggle between Situations, IC Copies, and Endpoints views. The hexagon shade signifies state:
- Inexperienced for OK.
- White for no alarms detected.
- Crimson for in alarm.
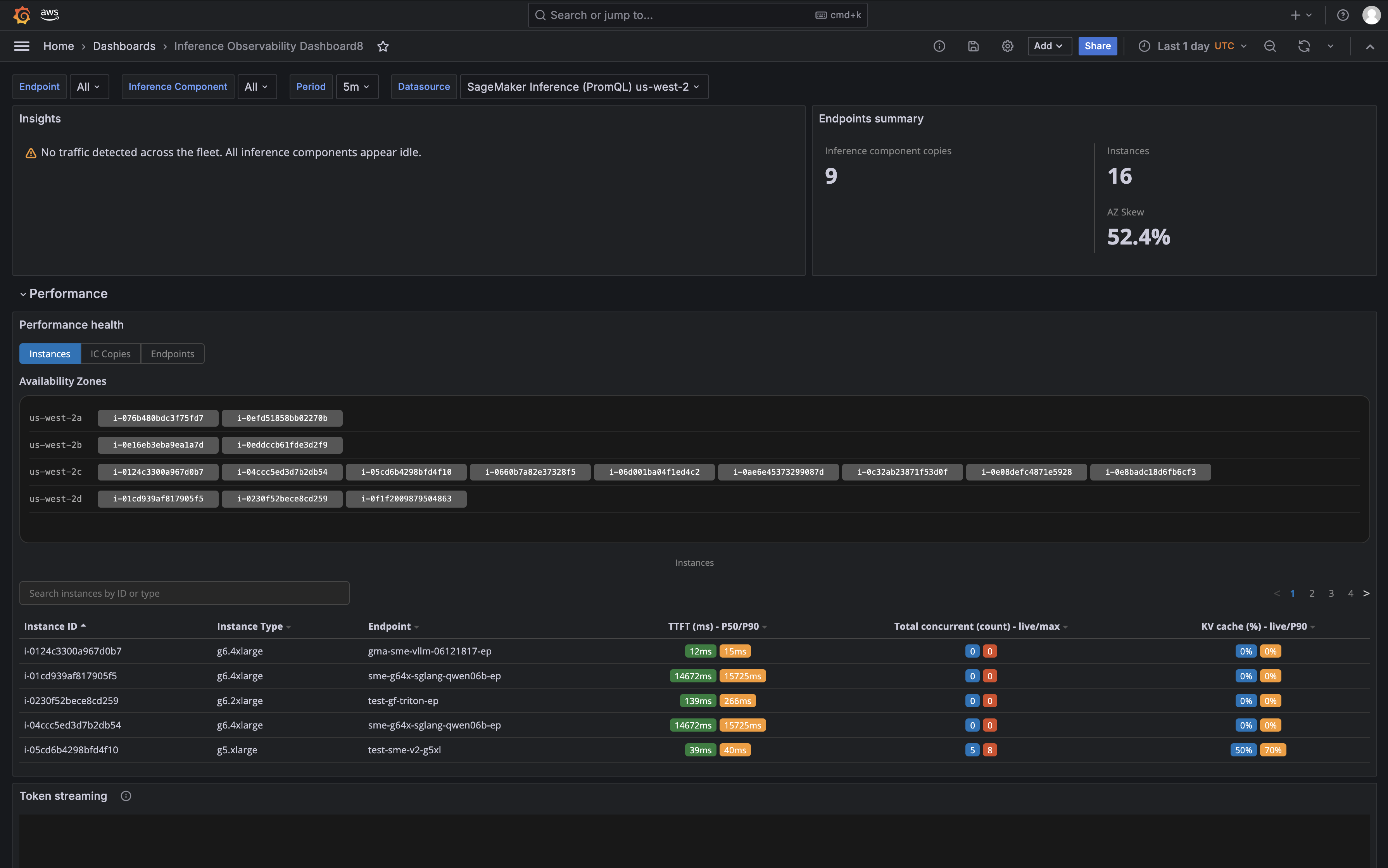
Hover over any hexagon to see occasion sort, TTFT, output TPS, concurrent requests, KV cache utilization, and CloudWatch alarm standing. Select Filter by this occasion to drill down. Each panel on the web page updates to indicate solely that occasion’s information.
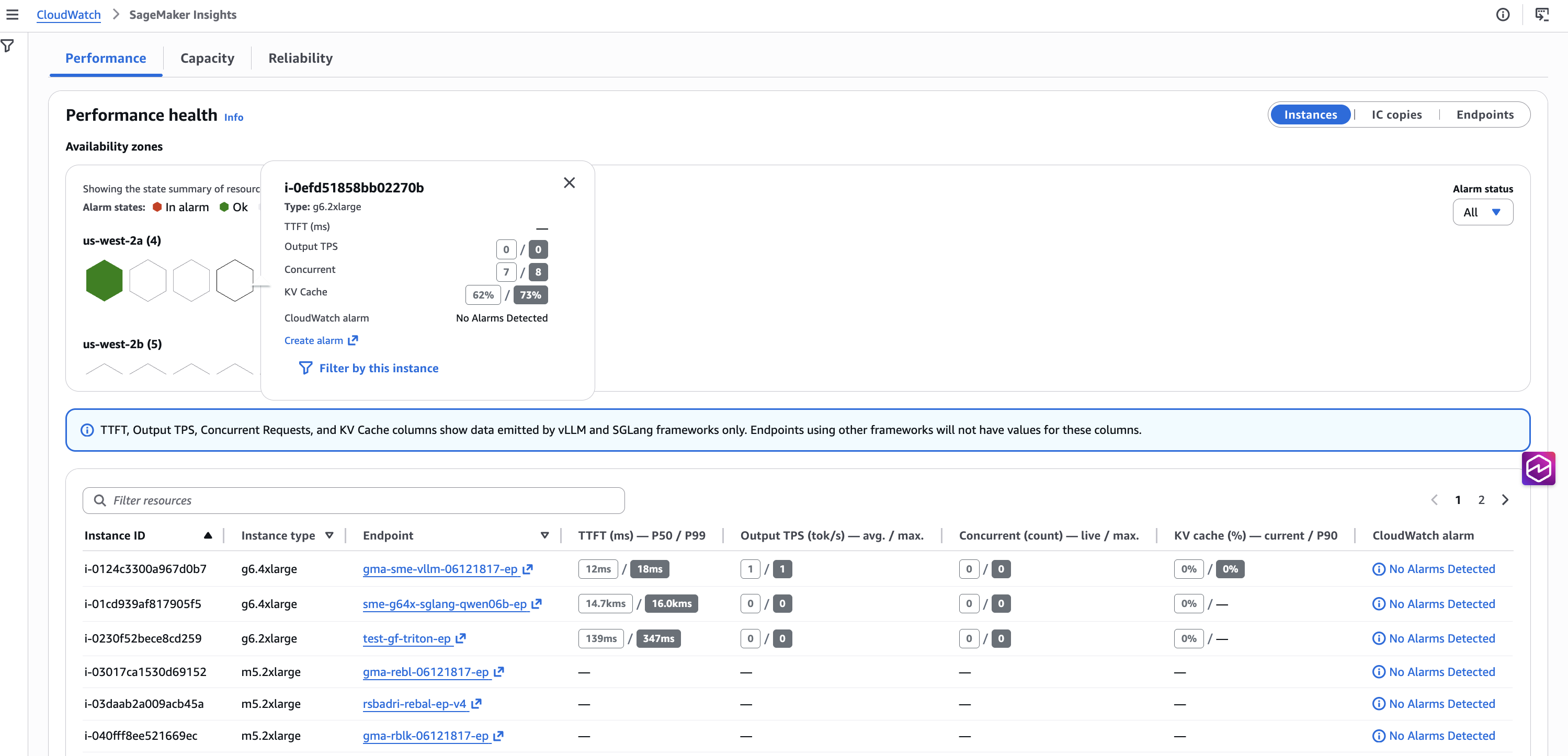
The desk reveals each occasion with efficiency metrics side-by-side. Use this desk to identify outliers in TTFT, output TPS, and concurrent requests. The TTFT, Output TPS, Concurrent Requests, and KV Cache columns present information emitted by the vLLM and SGLang frameworks solely.
The Token streaming panel plots Time to First Token (TTFT) and Inter-Token Latency (ITL) over time with a P50/P99 toggle. TTFT measures how lengthy customers wait earlier than seeing the primary response character. ITL measures time between consecutive tokens, which instantly impacts streaming smoothness. You may filter by endpoint, inference element title, or mannequin to isolate which element contributes to latency.
Whenever you determine a TTFT spike, the Latency breakdown panel helps you attribute it. This panel separates complete latency into Mannequin Latency (time the mannequin spends processing) and Overhead Latency (time the platform spends routing and scheduling). An Invoke tab reveals the total request path, and a Streaming tab reveals time-to-first-chunk particularly. If each Mannequin Latency and Overhead Latency are regular however TTFT continues to be elevated, the mannequin’s inference engine may be holding requests in its inner queue, for instance, ready for KV cache slots. Verify the Engine and request stress panel to substantiate.
The Site visitors distribution panel reveals per-instance or per-inference-component request circulate with Availability Zone filtering. Toggle the AZ dropdown to isolate site visitors by zone. If one AZ reveals zero site visitors whereas others are loaded, that signifies a routing or placement difficulty. You should use the occasion/IC toggle to modify between “Which machines deal with site visitors?” and “Which fashions deal with site visitors?” views.
Lastly, the Token throughput panel measures precise tokens processed per second, damaged down by enter/output, percentiles, or by occasion. This instantly measures inference effectivity. For instance, in case your ml.g6.4xlarge delivers 150 tokens per second output when the mannequin benchmark reveals 500, that signifies a useful resource constraint, configuration difficulty, or KV cache stress. The multi-framework legend (SGLang, vLLM, DJL) lets multi-model endpoints evaluate throughput throughout inference engines.
Engine and request stress
The Engine and request stress panel is your early warning system for stopping outages.
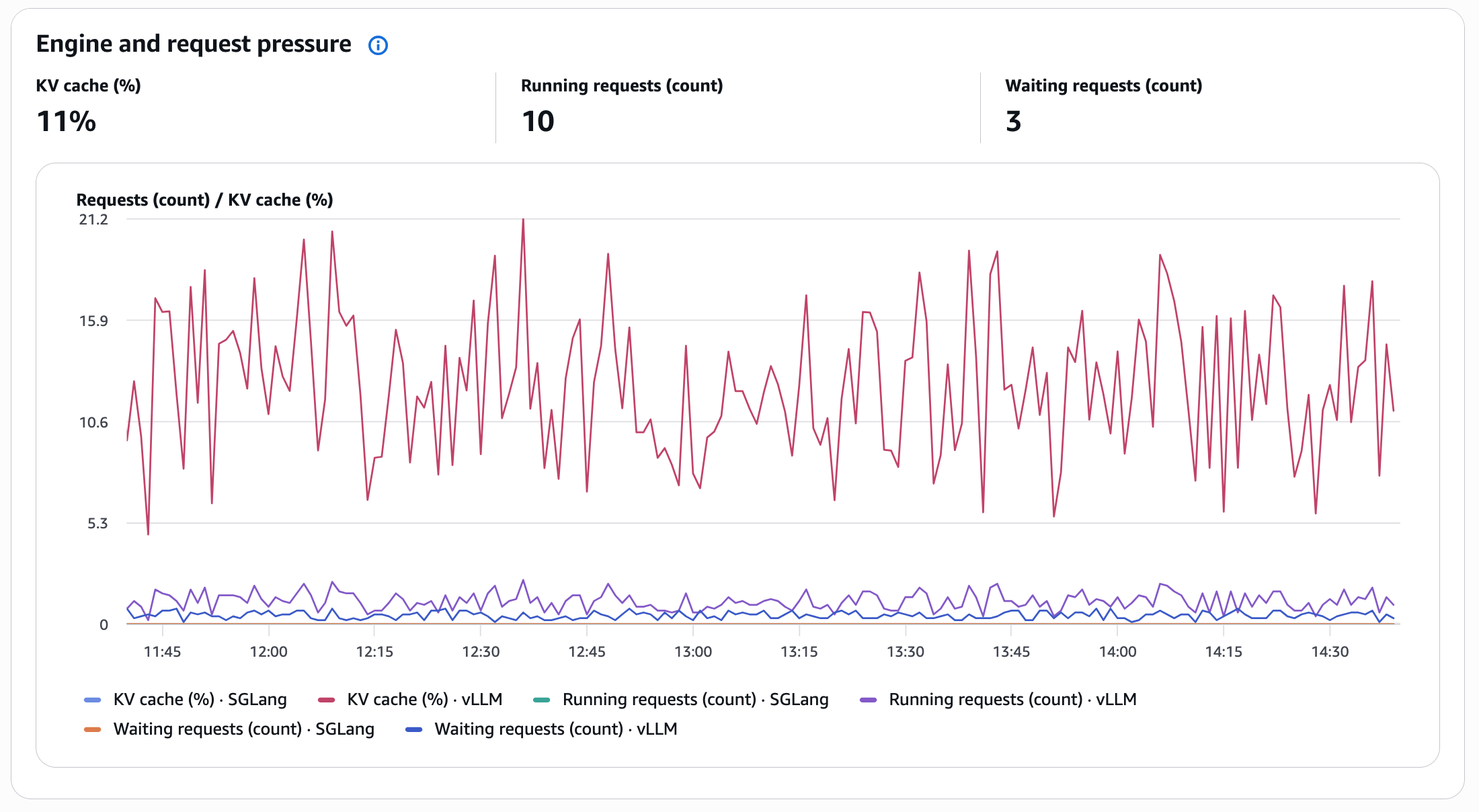
The time-series view reveals the per-framework breakdown, with tooltips that present precise values at any timestamp. When you see KV cache repeatedly climbing to 40–50 % throughout enterprise hours, configure autoscaling to set off at a threshold worth earlier than prospects really feel the affect.
Capability tab: Planning deployments and useful resource administration
The Capability tab solutions questions like “Do I’ve sufficient assets?”, “The place is there headroom?”, and “Can I match one other mannequin?”
Capability well being
The identical honeycomb visualization from Efficiency reappears right here, with useful resource utilization percentages within the hover card: GPU, GPU reminiscence, CPU, CPU reminiscence, and Disk.
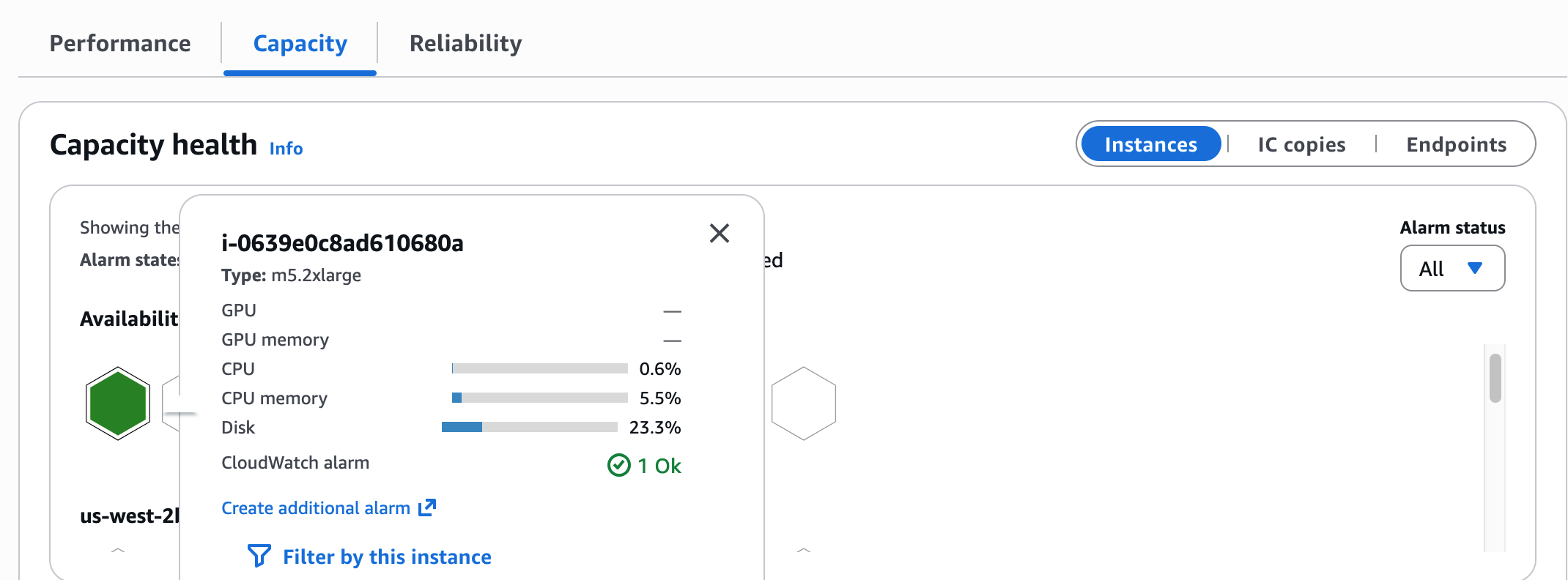
Earlier than you deploy a brand new mannequin or scale copies, hover over cases in your goal endpoint. If GPU reminiscence is at 89 %, there’s restricted VRAM headroom for extra mannequin weights.
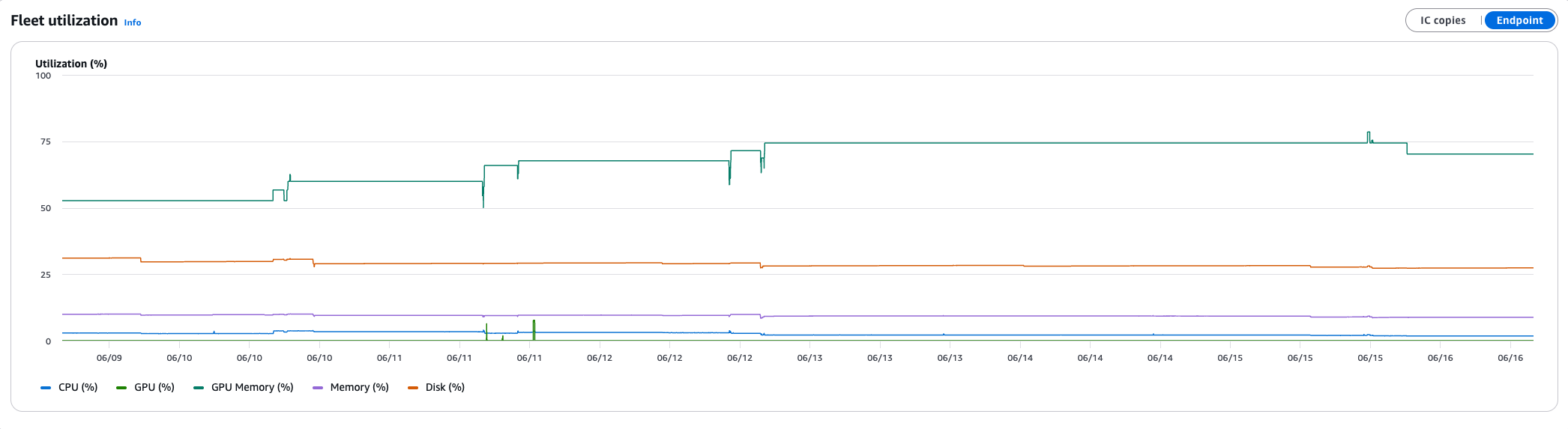
Fleet utilization over time
This panel reveals useful resource consumption traits with toggles for Occasion, IC copies, and Endpoint aggregation. Key alerts embody the next:
- GPU Reminiscence trending upward over days signifies that you just’re approaching capability limits. Add cases earlier than utilization reaches the restrict.
- GPU Reminiscence dropping instantly signifies {that a} mannequin crashed or was unloaded. Examine.
- Disk spikes that recur periodically correlate with mannequin downloads throughout chilly begins.
Reliability tab: Supporting excessive availability and resilience view
The Reliability tab solutions questions like “If an AZ goes down, will my inference fleet survive?”, “Are scaling occasions working?”, and “Why are chilly begins gradual?”
Availability Zone distribution
A bar chart reveals occasion and IC copy counts per AZ. This view reveals your excessive availability posture.
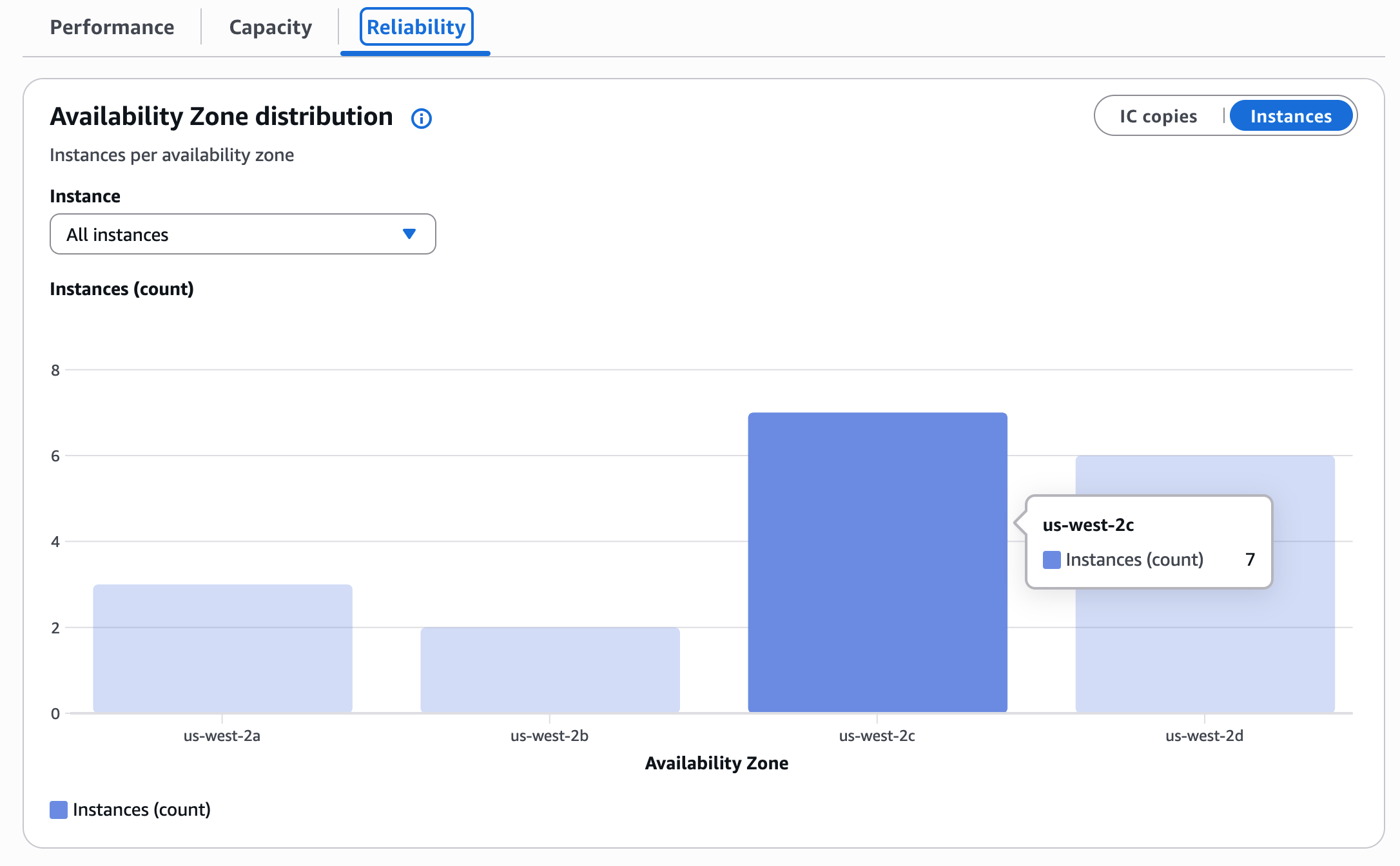
| Distribution | Threat | Motion |
| Even throughout over 3 AZs | Low | No motion |
| Concentrated in 1-2 AZs | Medium | Rebalance |
| 0 cases in any AZ | Excessive | Single AZ failure takes you offline |
Toggle between Situations and IC Copies. Situations may be balanced, however IC copies may very well be targeting just a few machines.
Chilly begin anatomy
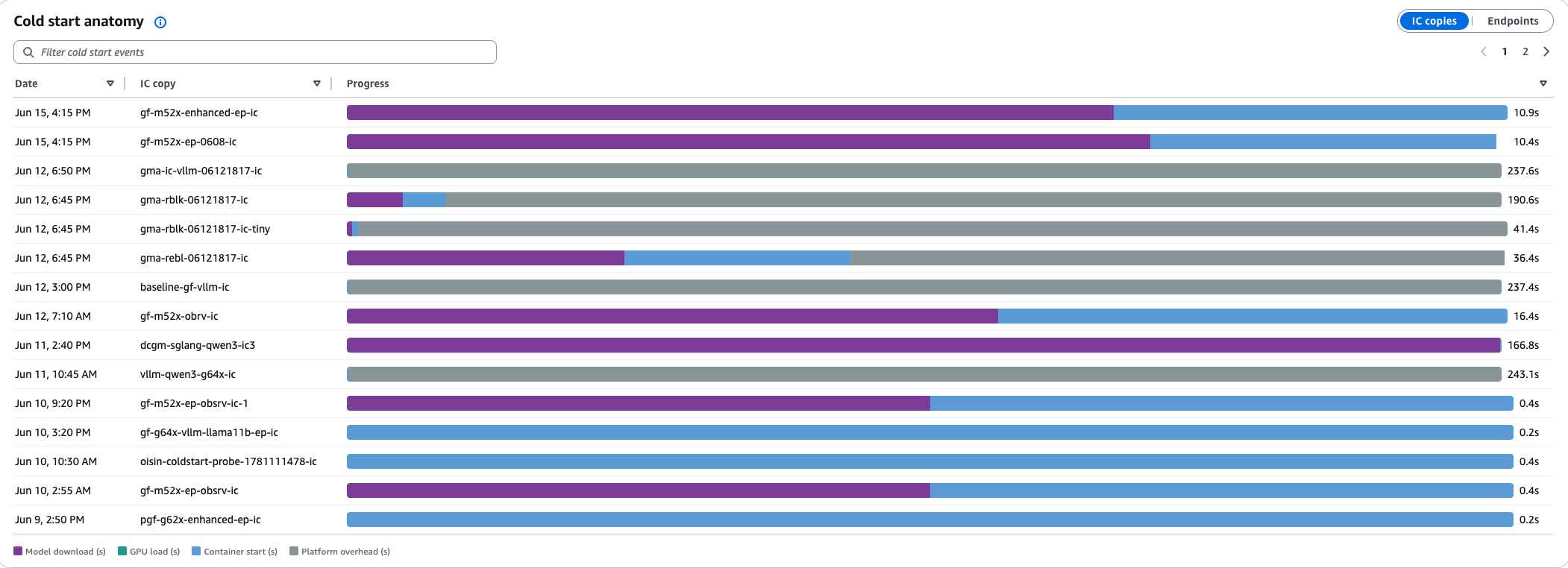
Each IC provisioning occasion displayed as a horizontal stacked bar with 4 phases:
| Section | Shade | What it measures | Optimization |
| Mannequin obtain | Blue | Pull mannequin weights from Amazon Easy Storage Service (Amazon S3) | Compress artifacts, use Amazon Elastic File System (Amazon EFS) caching |
| GPU load | Purple | Load weights onto GPU | Smaller quantization, pre-warming |
| Container begin | Orange | Container initialization | Cut back dependencies |
Within the screenshot, gma-ic-vllm took 237.6 seconds, with mannequin obtain dominating, whereas gma-rblk-ic-tiny was solely 41.4 seconds as a result of it’s a smaller mannequin. This view tells you which of them section to optimize for sooner scaling response occasions.
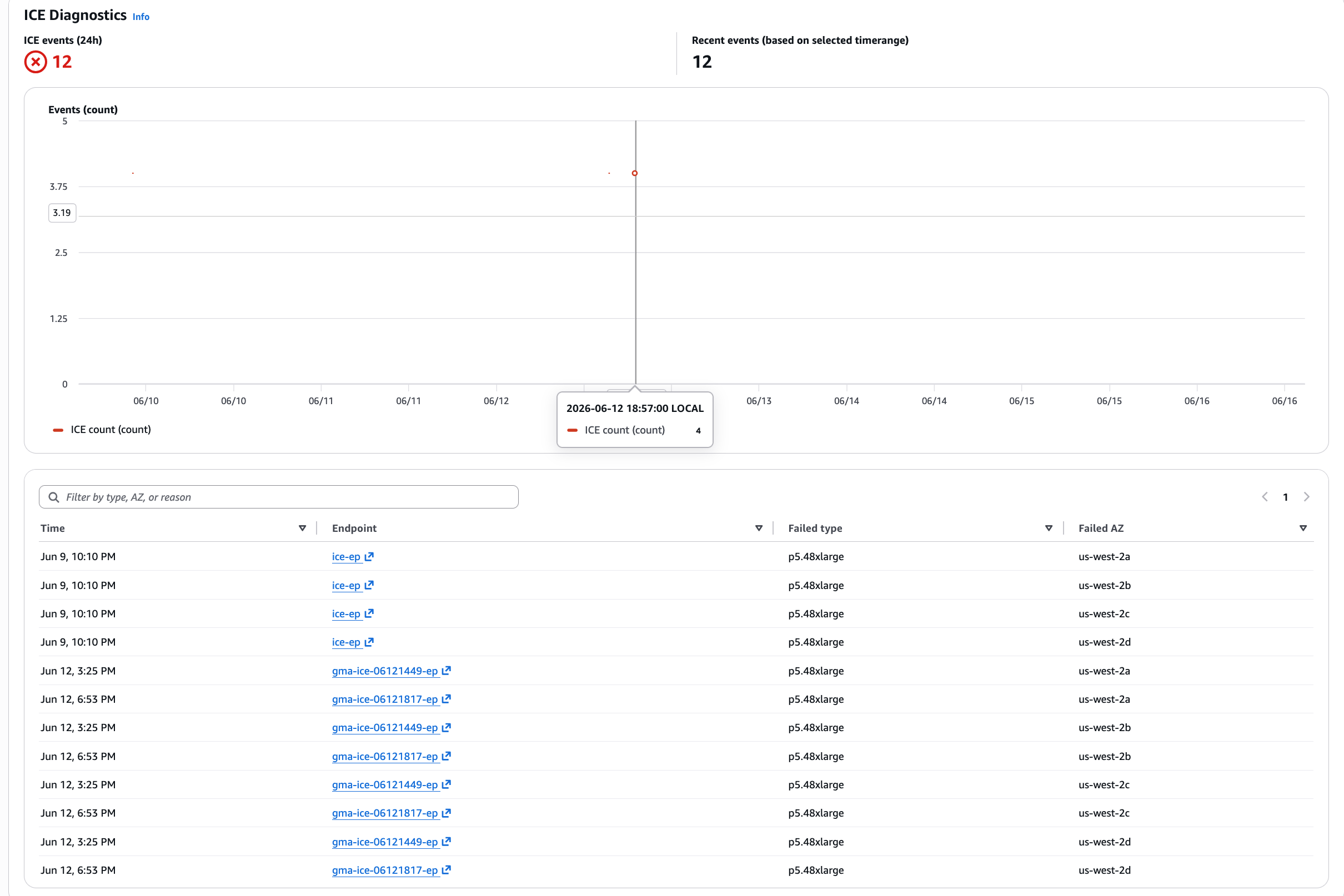
ICE diagnostics
The ICE diagnostics view tracks inadequate capability errors (ICE), which happen when SageMaker can’t provision requested cases. The desk reveals:
- When the failure occurred.
- Which endpoint was affected (deep-links to the console).
- Which occasion sort was unavailable.
- Which AZ had no capability.
Within the previous screenshot, all 12 ICE occasions are for p5.48xlarge throughout all 4 AZs, indicating full regional exhaustion for this occasion sort. You now know to modify to different occasion varieties as a fallback.
For groups with current Grafana or different PromQL-compatible instruments, you’ll be able to question SageMaker Insights metrics instantly out of your platform with out switching to the CloudWatch console. The next walkthrough demonstrates the setup utilizing Grafana. The identical steps apply to self-hosted Grafana or different appropriate instruments, with minor configuration variations.
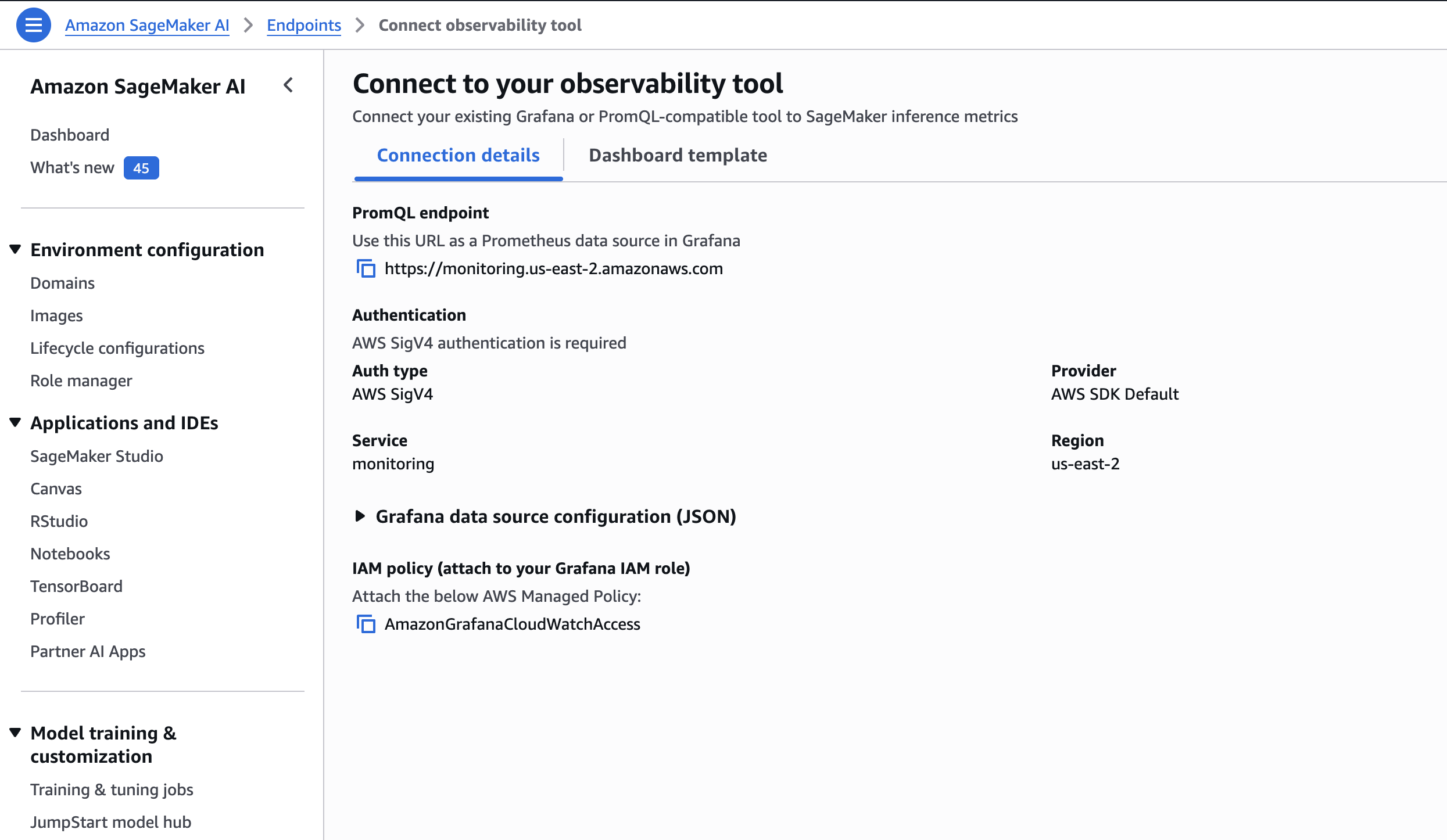
Step 1: Get the PromQL endpoint URL
Navigate to SageMaker Console, then choose Endpoints. From there, choose your endpoint after which select Connect with your observability device. Copy the displayed endpoint URL. It follows the format proven within the SageMaker console.
Step 2: Configure your Grafana information supply
In Amazon Managed Grafana (Traditional CloudWatch 2.4+) or self-hosted Grafana with the Amazon Managed Service for Prometheus plugin (v3.0.0+):
- Navigate to Configuration, Information Sources, then Add information supply. Choose Amazon Managed Service for Prometheus and set the URL to the PromQL endpoint URL from Step 1.
- Below Service Supplier, enter
monitoring. - Configure SigV4 authentication with an IAM position that has the
cloudwatch:GetMetricDataandcloudwatch:ListMetricspermissions. - Select Save & Take a look at. You must see Information supply is working.
Step 3: Import the pre-built dashboard template
Obtain the dashboard template JSON from the identical Connect with your observability device web page within the SageMaker console. Import the downloaded JSON template into Grafana (Dashboards → Import), choose the Prometheus information supply you configured in Step 2, and also you get pre-configured Efficiency, Capability, and Reliability panels matching the SageMaker Insights format.
Step 4: Question metrics with PromQL
With the information supply linked, you’ll be able to write customized PromQL queries. For instance:
KV cache
vllm:kv_cache_usage_perc{"aws.sagemaker.endpoint.title"="ep-prsn-ic","aws.sagemaker.inference_component.title"="ic-qwen3-4b"}
# Energetic requests
vllm:num_requests_running{"aws.sagemaker.endpoint.title"="ep-prsn-ic","aws.sagemaker.inference_component.title"="ic-qwen3-4b"}
# TTFT P99
histogram_quantile(0.99, charge(vllm:time_to_first_token_seconds{"aws.sagemaker.endpoint.title"="ep-prsn-ic","aws.sagemaker.inference_component.title"="ic-qwen3-4b"}[5m]))Pricing
SageMaker doesn’t cost individually for emitting detailed observability metrics. The metrics are revealed to Amazon CloudWatch in OpenTelemetry information format, and commonplace CloudWatch OpenTelemetry ingestion pricing applies. OpenTelemetry metrics ingested into CloudWatch are charged at $0.50 per GB ingested. When you activate OTel vended metric enrichment (required to view traditional CloudWatch metrics like Invocations and ModelLatency within the Insights dashboard), enriched metrics are additionally charged at $0.50 per GB. For detailed pricing examples and a price calculator, see the OpenTelemetry Metrics part on the Amazon CloudWatch pricing web page.
Clear up
To keep away from ongoing costs, delete check assets on this order:
GPU cases are billed per second whereas endpoints are InService. Delete promptly after testing.
Conclusion
On this publish, you enabled SageMaker detailed metrics on inference endpoints and used the built-in SageMaker Insights dashboard to watch fleet well being, debug latency utilizing token-level metrics, validate excessive availability, and plan capability for brand new deployments.
To get began, see the next assets:
Acknowledgments
The SageMaker Insights dashboard and detailed observability metrics are the results of shut collaboration between the Amazon SageMaker AI and Amazon CloudWatch groups. We thank the engineering, product, and options structure groups whose work made this launch attainable.
We additionally thank the next contributors for his or her evaluate and inputs on this weblog publish:
- Felipe Lopez – Principal GenAI/ML Architect, AWS
- Sandeep Raveesh-Babu – Sr. Worldwide Specialist SA, GenAI, AWS
- Johna Liu – Sr. Software program Growth Engineer, Amazon SageMaker
- Raviprakash Darbha – Sr. Software program Growth Engineer, Amazon SageMaker
- Prajwal Kammardi – Software program Growth Engineer, Amazon SageMaker
- Jiaxi Xu – Software program Growth Engineer, Amazon SageMaker
- Orcun Berkem – Principal Engineer, Observability, Amazon CloudWatch
- Steve McCurry – Principal Product Supervisor, Amazon CloudWatch
Concerning the writer


{kind=link}