, I submitted my MS thesis on Emotion Recognition in Dialog (ERC). The mannequin, EmoNet, achieved a Weighted F1 of 39.18 on EmoryNLP — aggressive with the general public PapersWithCode leaderboard on the time, sitting between TUCORE-GCN_RoBERTa (39.24) and S+PAGE (39.14), and enhancing over my chosen baseline, CoMPM, by +1.81 F1.
Two years later, I returned to take a look at the place the sphere is now. The leaderboard is unrecognizable. The highest entries are now not encoder-only fashions with intelligent consideration heads — they’re LLaMA-2–7B-based techniques with LoRA fine-tuning and retrieval-augmented prompting: InstructERC, CKERC, BiosERC, LaERC-S. The strategies are totally different. The compute is totally different. The mindset is totally different.
And but — once I learn these new papers fastidiously, the core concepts I proposed in EmoNet present up inside them, simply carried out at a special layer of the stack. That is the story of what I constructed, the place it positioned, and what I’d construct now if I had been beginning over.
What ERC is, and why text-only is difficult
Emotion Recognition in Dialog is the duty of assigning an emotion label to every utterance in a multi-turn dialogue. It’s distinct from sentiment evaluation on remoted sentences in a single vital approach: the emotion of an utterance is formed by what got here earlier than it, and by who’s talking.
Think about this alternate from the EmoryNLP dataset (sourced from the TV present Pals):
Monica: Wendy, we had a deal! Yeah, you promised! Wendy! Wendy! Wendy! [Mad]
Rachel: Who was that? [Neutral]
Monica: Wendy bailed. I’ve no waitress. [Mad]
In isolation, “Who was that?” is emotionally impartial. The label Impartial is just significant in context — it sits between two indignant utterances from a special speaker and ERC fashions should seize this conversational dynamic.
There’s a second wrinkle: multimodal info is lacking. In actual human dialog, tone of voice, facial expressions, and physique language carry an unlimited share of emotional sign. Textual content-only ERC strips all of that away. The identical phrases — “Oh, nice.” — may be honest or sarcastic, and the textual content alone usually can’t let you know which.
This info loss is the central problem. It’s important to extract emotion from a noisier sign than the human-grade benchmark.
The 2024 panorama
Once I began my thesis in late 2023, the EmoryNLP leaderboard was dominated by transformer-based architectures with varied intelligent modifications. A fast tour:
– KET (Zhong et al., 2019) — knowledge-enriched transformer with affective graph consideration, the primary paper to carry transformers to ERC.
– DialogueGCN (Ghosal et al., 2019) — graph convolutional community that transformed dialogues into node-classification issues.
– RGAT (Ishiwatari et al., 2020) — relation-aware graph consideration with relational place encoding for speaker dependencies.
– DialogXL (Shen et al., 2020) — tailored XLNet with utterance recurrence and dialogue self-attention.
– HiTrans (Li et al., 2020) — hierarchical transformer with pairwise utterance speaker verification as auxiliary activity.
– TUCORE-GCN (Lee & Choi, 2021) — heterogeneous dialogue graph with speaker-aware BERT.
– CoMPM (Lee & Lee, 2021) — mixed dialogue context with pre-trained reminiscence monitoring for the speaker.
I selected CoMPM as my base for 2 causes. First, it explicitly modeled the speaker’s pre-trained reminiscence as a separate module — which mapped to my instinct that who is talking issues as a lot as what they’re saying. Second, its structure was modular sufficient to increase with out rewriting from scratch. The CoMPM paper confirmed that including pre-trained reminiscence to the context mannequin gave a measurable increase — however their speaker id was nonetheless native to every dialogue. The second a brand new dialog started, all the things the mannequin had realized a few speaker was discarded.
That appeared like an issue value fixing.
Three contributions, with instinct
1. World Speaker Identification
The issue. In CoMPM and most prior work, speaker IDs are scoped to a single dialogue. Speaker A in scene 1 has no relationship to Speaker A in scene 14, even once they’re the identical particular person. Therefore, each dialogue begins chilly.
The instinct. Individuals have attribute emotional patterns. Monica will get indignant about particular issues; Phoebe is reliably cheerful; Ross has predictable bouts of insecurity. If a mannequin can carry details about this particular speaker throughout dialogues, it ought to have the ability to make better-calibrated predictions when that speaker reappears.
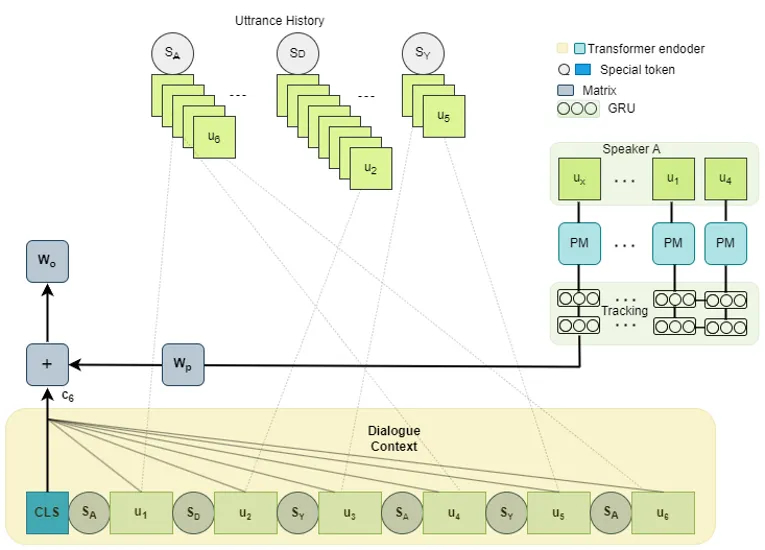
The implementation. Every distinctive speaker in the complete dataset will get a steady, dataset-wide ID. The primary time Monica Geller seems, she’s assigned an ID — say, ID 7 — that stays along with her. Each subsequent look — throughout episodes, seasons, scenes — she stays ID 7. The mannequin can now be taught speaker-specific patterns that persist.
This sounds apparent looking back. In 2024 it was not how the leaderboard fashions labored.
2. Speaker Behaviour Module
The issue. World Speaker Identification alone is only a label. To make it helpful, the mannequin must do one thing with the speaker’s amassed historical past. How do you give a transformer entry to “all the things Monica has ever stated on this dataset,” with out blowing out the context window or making coaching intractable?
The instinct. Recurrence. A GRU is a pure match for sequentially compressing a speaker’s historic utterances right into a single fixed-size illustration. Latest utterances contribute extra; older ones step by step dilute. A configurable sliding window bounds the GRU’s enter — say, the final N utterances by this speaker — retaining compute and reminiscence predictable.
The implementation. Every utterance is independently encoded by a pre-trained RoBERTa spine. The ensuing embeddings circulation by way of a unidirectional GRU. The GRU’s remaining hidden state — name it `kt` — represents the speaker’s behavioral sample on the present second. That is projected into the identical dimension because the dialogue context output and added in. The mixed sign feeds the ultimate classifier.
The structure is structurally much like CoMPM’s pre-trained reminiscence module, however with two key variations: the speaker-history pool is world (not native to the present dialogue), and the GRU explicitly fashions temporal decay.

3. Weighted Cross-Entropy Loss
The issue. EmoryNLP is imbalanced — Impartial outnumbers Unhappy by roughly 4.5:1. Most papers deal with this with knowledge augmentation or under-sampling. However conversational knowledge is sequential: dropping or duplicating utterances distorts the pure emotional circulation, which is precisely the sign the mannequin is attempting to be taught from.
The instinct. For those who can’t safely change the info, change the loss. Weight uncommon courses increased so a single misclassification of Unhappy prices the mannequin greater than a single misclassification of Impartial.
The implementation. Cross-entropy with per-class weights derived from inverse class frequency, then normalized. Nothing unique — however with the conversational-sequence argument as the specific motivation, this turns into a principled alternative fairly than an arbitrary one.
Outcomes: what labored, and what shocked me
Right here’s the ablation desk from the thesis:

The outcome that shocked me — and that I believe is probably the most sincere a part of this work — is the second row. Including World Speaker ID alone made the mannequin considerably worse (F1 dropped from 37.85 to 29.43). That seemed like a failure at first.
Nevertheless it wasn’t. The World Speaker Identification is a functionality — it offers the mannequin the power to be taught long-range speaker patterns. By itself, that functionality creates a representational burden the remainder of the mannequin couldn’t take in. Solely as soon as the Speaker Behaviour module was added — giving the mannequin a structured strategy to use the worldwide identities — did the contribution floor. By the ultimate configuration, EmoNet had recovered and surpassed the CoMPM baseline by 1.81 F1.
That is the lesson I took from the ablation: a function isn’t worthwhile in isolation; it’s worthwhile together with the equipment that consumes it. Analysis papers that report “this addition gave us +X%” usually cover ablation rows the place the addition alone made issues worse. I selected to maintain that row in.

The total mannequin dealt with Impartial, Pleasure, and Scared properly. Highly effective remained the toughest class — partly as a result of it’s uncommon, and partly as a result of Highly effective and Pleasure are practically indistinguishable in textual dialog with out acoustic cues. This can be a multimodal downside masquerading as a textual content downside.
Reflection (2026): the sphere moved, and so ought to we
Two years on, the EmoryNLP leaderboard seems to be utterly totally different. The main techniques now are:
– InstructERC (Lei et al., 2023) — reformulates ERC as a generative LLM activity. It makes use of retrieval-augmented instruction templates and auxiliary duties corresponding to speaker identification and emotion prediction to raised mannequin dialogue roles and emotional dynamics.
– CKERC (Fu, 2024) — introduces commonsense-enhanced ERC. For every utterance, an LLM generates commonsense annotations about speaker intention and sure listener response, offering implicit social and emotional reasoning past specific dialogue context.
– BiosERC (Xue et al., 2024) — injects LLM-derived speaker biographical info into the ERC course of, permitting the mannequin to motive not solely over utterance context but in addition over speaker-specific traits.
– LaERC-S (Fu et al., 2025) — two-stage instruction tuning. Stage 1: equip the LLM with speaker-specific traits. Stage 2: use these traits throughout the ERC activity itself.
Take a look at these final two fastidiously.
BiosERC’s speaker biographical info is, in spirit, World Speaker Identification scaled up — as a substitute of an integer ID, it’s a textual profile the LLM can attend to. LaERC-S’s speaker traits are, in spirit, the Speaker Behaviour module — historic speaker patterns made out there to the mannequin — however folded into instruction tuning fairly than carried out as a separate GRU.
The architectural intuitions held up. The implementation layer modified.
That is the half I discover genuinely attention-grabbing. Once I was engaged on EmoNet in 2024, I used to be considering contained in the encoder-only-transformer paradigm: “how do I add one other module to the structure?” The 2024–2025 papers suppose contained in the LLM paradigm: “how do I encode this concept into instruction tuning or retrieval context?” The concepts are comparable; the leverage factors are totally different.
If I had been to rebuild EmoNet at the moment, I’d not begin from RoBERTa-large. I’d begin from a small open-source LLM — LLaMA-3.2–3B, Qwen-2.5–3B, or Phi-3.5 — and use LoRA to fine-tune it on EmoryNLP, following the InstructERC household of approaches. The World Speaker Identification turns into a textual speaker biography retrieved from a vector retailer. The Speaker Behaviour module turns into a few-shot immediate with the speaker’s most up-to-date emotional historical past. The Weighted Loss survives nearly unchanged — class imbalance doesn’t care what mannequin you’re utilizing.
The structure diagram would look utterly totally different. The conceptual debt to the 2024 thesis can be seen for those who knew the place to look.
It taught me that analysis debt has an extended half-life than I anticipated — concepts survive paradigm shifts even when their implementations don’t.
The place this leaves me
EmoNet is now publicly archived underneath DOI 10.5281/zenodo.20048006 with the complete thesis, protection slides, and PyTorch implementation on GitHub. I’m at the moment engaged on the modernized port — a LoRA-fine-tuned LLM with retrieval-based speaker context — as a follow-up challenge that I’ll write about quickly.
For those who’re engaged on conversational AI, utilized NLP, or LLM fine-tuning, I’d have an interest to listen to what you’re constructing.



{kind=link}