mannequin fails not as a result of the algorithm is weak, however as a result of the variables weren’t ready in a approach the mannequin can correctly perceive?
In credit score danger modeling, we regularly concentrate on mannequin selection, efficiency metrics, function choice, or validation. However earlier than estimating any coefficient, one other query deserves consideration: how ought to every variable enter the mannequin?
A uncooked variable isn’t at all times the perfect illustration of danger.
A steady variable might have a non-linear relationship with default. A categorical variable might comprise too many modalities. Some variables might embody outliers, lacking values, unstable distributions, or classes with only a few observations. If these points are ignored, the mannequin might develop into unstable, tough to interpret, and fewer dependable in manufacturing.
That is the place categorization turns into essential.
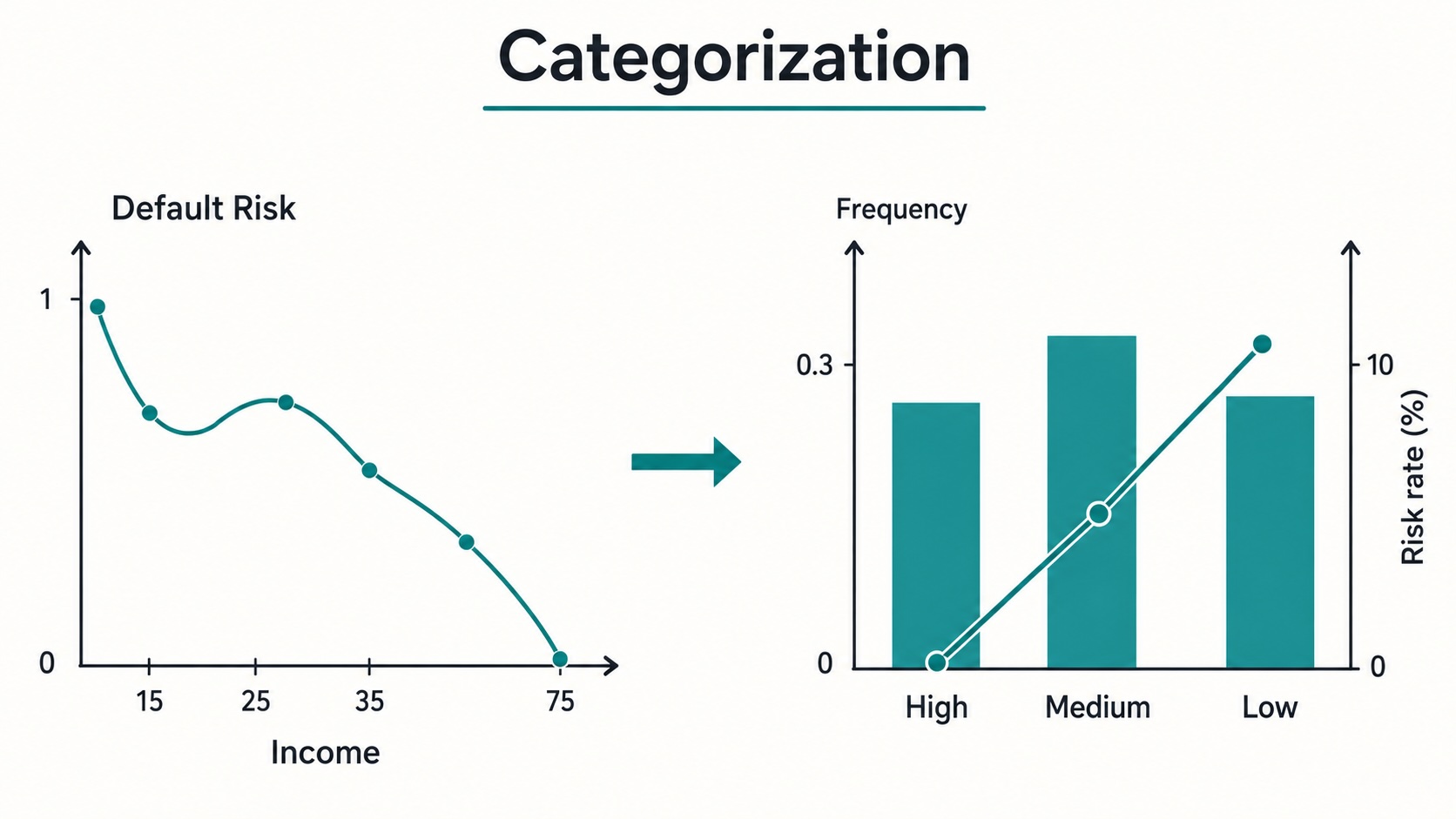
Categorization, additionally known as coarse classification, grouping, classing, or binning, consists of remodeling uncooked variable values right into a smaller variety of significant teams. In credit score scoring, these teams should not created just for comfort. They’re created to make the connection between the variable and default danger clearer, extra steady, and simpler to make use of in a mannequin.
This step is especially helpful when the ultimate mannequin is a logistic regression, which stays extensively utilized in credit score scoring as a result of it’s clear, interpretable, and simple to translate right into a scorecard.
For categorical variables, categorization helps scale back the variety of modalities. For steady variables, it helps seize non-linear danger patterns, scale back the affect of outliers, deal with lacking values, enhance interpretability, and put together the variables for Weight of Proof transformation.
On this article, we are going to examine why categorization is a necessary step in credit score scoring and the way it may be used to remodel uncooked variables into steady danger lessons.
In Part 1, we clarify why categorization is beneficial for each categorical and steady variables, particularly within the context of logistic regression.
In Part 2, we present the way to analyze the connection between steady variables and default danger utilizing graphical monotonicity evaluation.
In Part 3, we introduce the principle categorization strategies, together with equal-interval binning, equal-frequency binning, Chi-square-based grouping, and Weight of Proof-based grouping.
Lastly, in Part 4, we concentrate on the discretization of steady variables utilizing Weight of Proof and present how this method helps put together variables for an interpretable credit score scoring mannequin.
1. Why categorization is essential in credit score scoring
When constructing a credit score scoring mannequin, variables will be both categorical or steady.
Categorization will be helpful for each kinds of variables, however the motivation isn’t the identical.
For categorical variables, the principle goal is commonly to cut back the variety of modalities and group classes with comparable danger conduct.
For steady variables, the target is often to remodel a uncooked numerical scale right into a smaller variety of ordered danger lessons.
In each circumstances, the purpose is similar: create variables which are statistically significant, economically interpretable, and steady over time.
1.1 Categorization Reduces Dimensionality
Allow us to begin with categorical variables.
Suppose we now have a variable known asindustry_sector, and this variable has 50 completely different values.
If we use this variable immediately in a logistic regression mannequin, we have to create dummy variables.
Due to collinearity, one class should be used because the reference class. Due to this fact, for 50 classes, we’d like:
50−1=49 dummy variables.
Which means the mannequin should estimate 49 parameters for just one variable.
This could shortly develop into an issue.
A categorical variable with too many modalities might result in unstable coefficients, overfitting, poor robustness, problem in interpretation, and better complexity throughout monitoring.
By grouping comparable classes collectively, we scale back the variety of parameters that should be estimated.
For instance, as an alternative of holding 50 trade sectors, we might group them into 5 or 6 danger lessons. These teams could also be based mostly on noticed default charges, enterprise experience, pattern dimension constraints, or a mix of those standards.
The result’s a mannequin that’s extra compact, extra steady, and simpler to interpret.
So, one of many first advantages of categorization is dimension discount.
1. 2. Categorization Helps Seize Non-Linear Danger Patterns
For steady variables, categorization may also be very helpful.
However earlier than deciding whether or not to categorize a steady variable, we should always first perceive its relationship with default danger.
A quite simple approach to do that is to plot the default price in opposition to the variable.
For instance, if we now have a steady variable comparable toindividual revenue variable, we will divide it into a number of intervals and calculate the default price in every interval.
Then, we plot:
- the binned values of the variable on the x-axis,
- the default price on the y-axis.
This enables us to visually examine the chance sample.
If the connection is monotonic, then the variable already has a transparent danger path.
For instance:
- As revenue will increase, default price decreases.
- Because the mortgage rate of interest will increase, the default price will increase.
On this case, the connection is straightforward to know.
Nevertheless, if the connection is non-monotonic, the state of affairs turns into extra complicated.
Suppose default danger decreases for low to medium revenue ranges, however then will increase once more for very excessive revenue ranges. A easy logistic regression mannequin might not seize this sample correctly as a result of it estimates a linear impact between the variable and the log-odds of default.
The logistic regression mannequin has the next type:
the place Y=1 represents default, and X is an explanatory variable.
This equation implies that the mannequin assumes a linear relationship between X and the log-odds of default.
If the impact of X isn’t linear, the mannequin might miss an essential a part of the chance construction.
Non-linear fashions comparable to neural networks, determination timber, gradient boosting, or help vector machines can naturally seize complicated relationships.
However in credit score scoring, logistic regression remains to be extensively used as a result of it’s easy, clear, and simple to clarify.
By categorizing steady variables into danger teams, we will introduce a part of the non-linearity right into a linear mannequin.
That is without doubt one of the most essential the explanation why binning is so widespread in scorecard modeling.
1.3. Categorization Reduces the Influence of Outliers
One other essential good thing about categorization is outlier administration.
Steady variables usually comprise excessive values.
For instance:
- very excessive revenue,
- extraordinarily massive mortgage quantities,
- uncommon employment size,
- irregular credit score utilization ratios.
If these values are used immediately in a logistic regression, they will have a powerful affect on the estimated coefficients.
Once we categorize the variable, outliers are assigned to a particular bin.
For instance, all revenue values above a sure threshold will be grouped into the identical class.
This reduces the affect of utmost observations and makes the mannequin extra strong.
As a substitute of permitting an excessive worth to strongly have an effect on the mannequin, we solely use the chance info contained in its group.
1.4. Categorization Helps Cope with Lacking Values
Lacking values are quite common in credit score scoring datasets.
A buyer might not present revenue info.
An employment size could also be lacking.
A credit score historical past variable will not be out there.
One approach to deal with lacking values is to create a devoted class for them.
This enables the mannequin to be taught the particular conduct of people with lacking values.
This is essential as a result of missingness isn’t at all times random.
In credit score scoring, a lacking worth might itself comprise danger info.
For instance, clients who don’t report their revenue might have a unique default conduct in contrast with clients who present it.
By making a lacking class, we permit the mannequin to seize this conduct.
1.5 Categorization Improves Interpretability
Interpretability is without doubt one of the most essential necessities in credit score scoring.
A credit score scoring mannequin isn’t just a black-box prediction engine.
It’s usually utilized by:
- danger analysts,
- credit score officers,
- mannequin validation groups,
- regulators,
- enterprise decision-makers.
When variables are categorized, the mannequin turns into a lot simpler to clarify.
For instance, as an alternative of claiming:
A one-unit improve in mortgage rate of interest will increase the log-odds of default by a specific amount.
We will say:
Prospects with an rate of interest above 15% have considerably increased default danger than clients with an rate of interest beneath 10%.
This interpretation is extra intuitive.
It is usually simpler to translate into scorecard factors.
1.6. Categorization Improves Mannequin Stability
credit score scoring mannequin mustn’t solely carry out nicely throughout improvement.
It must also stay steady in manufacturing.
Categorization helps make variables much less delicate to small adjustments within the information.
For instance, if a buyer’s revenue adjustments barely from 2990 to 3010, the uncooked numerical worth adjustments.
But when each values belong to the identical revenue band, the categorized worth stays the identical.
This makes the mannequin extra steady over time.
Categorization can be very helpful for monitoring.
As soon as variables are grouped into lessons, we will simply observe their distribution in manufacturing and evaluate it with the event pattern utilizing indicators such because the Inhabitants Stability Index.
To summarize this primary half, we categorize variables primarily to cut back dimensionality, seize non-linear danger patterns, deal with lacking values and outliers, enhance interpretability, and stability.
2. Graphical Monotonicity Evaluation Earlier than Binning
Earlier than categorizing a steady variable, we have to perceive its relationship with the default price.
This step is essential as a result of categorization shouldn’t be arbitrary.
The purpose isn’t solely to create bins. The purpose is to create bins that make sense from a danger perspective.
binning ought to reply the next questions:
- Does the variable have a transparent relationship with default danger?
- Is the connection rising or lowering?
- Is the connection monotonic or non-monotonic?
To reply these questions, we begin with a graphical monotonicity evaluation.
A variable is monotonic with respect to default danger if the default price strikes in a single path when the variable will increase.
For instance, if revenue will increase and default danger decreases, the connection is monotonic lowering.
If rate of interest will increase and default danger will increase, the connection is monotonic rising.
Monotonicity is essential in credit score scoring as a result of it makes the mannequin simpler to interpret.
A monotonic variable has a transparent danger which means.
For instance:
- Greater revenue means decrease danger.
- Greater mortgage burden means increased danger.
- The next rate of interest means increased danger.
- Longer employment size means decrease danger.
These relationships are simple to clarify and often in keeping with enterprise instinct.
Nevertheless, if the connection isn’t monotonic, the variable might require extra cautious therapy.
A non-monotonic sample can point out:
- an actual non-linear danger impact,
- noisy information,
- sparse intervals,
- outliers,
- interactions with different variables,
- instability throughout datasets.
Because of this we should always at all times examine the default price curve earlier than deciding the way to bin a variable.
2.1 Equal-Interval Binning for Visible Prognosis
A easy first method consists of dividing the variable into intervals of equal width. That is known as equal-interval binning.
Suppose a variable takes the next values:
1000, 1200, 1300, 1400, 1800, 2000The minimal worth is 1000, and the utmost worth is 2000.
If we need to create two equal-width bins, the width is:
So we receive:
Bin 1: 1000 to 1500
Bin 2: 1500 to 2000Then, for every bin, we calculate the default price:

This offers us a desk like this:

Then we plot the default price by bin.
This plot offers a primary instinct in regards to the form of the connection.
Equal-interval binning is easy and simple to know. Nevertheless, it might create bins with very completely different numbers of observations, particularly when the variable is very skewed.
Because of this, equal-frequency binning is commonly most popular for exploratory monotonicity evaluation.
2.2 Equal-Frequency Binning for Danger Curves
Equal-frequency binning divides the variable into bins containing roughly the identical variety of observations.
For instance, decile binning divides the pattern into 10 teams, every containing round 10% of the observations.
This method is beneficial as a result of every bin has sufficient information to calculate a extra dependable default price.
In Python, this may be completed with pd.qcut.
Nevertheless, it is very important notice the distinction:
pd.lowerperforms equal-width binning;pd.qcutperforms equal-frequency binning.
This distinction issues as a result of the interpretation of the bins isn’t the identical.
In our case, we use equal-frequency binning to review the chance sample of steady variables.
2.3 Dataset and Chosen Variables
In earlier articles, we carried out a number of essential steps on the identical dataset.
We already lined:
- exploratory information evaluation,
- variable preselection,
- stability evaluation,
- monotonicity evaluation over time,
- Comparability between prepare, take a look at, and out-of-time datasets.
After these steps, we chosen probably the most related variables for modeling.
On this article, we concentrate on the categorization of steady variables. The qualitative variables already had a restricted variety of modalities, and based mostly on the earlier evaluation, their stability and monotonicity have been acceptable.
Due to this fact, our goal right here is to review the continual variables graphically, perceive their relationship with default danger, and outline an applicable discretization technique.
The chosen steady variables are:
- person_income
- person_emp_length
- loan_int_rate
- loan_percent_income
2.4 Python Code for Default Fee Curves
There isn’t any native Python perform in pandas or scikit-learn that performs a full credit-scoring monotonicity analysis precisely as required for scorecard modeling.
So we’d like both to code the process ourselves or use a specialised scorecard library.
Right here, we code it manually with pandas and matplotlib.
import pandas as pd
import matplotlib.pyplot as plt
def plot_default_rate_ax(information, variable, goal, bins=10, ax=None):
"""
Plot default price by binned numerical variable on a given matplotlib axis.
"""
df = information[[variable, target]].copy()
# Create bins
df[f"{variable}_bin"] = pd.qcut(
df[variable],
q=bins,
duplicates="drop"
)
# Compute default price by bin
abstract = (
df.groupby(f"{variable}_bin", noticed=True)[target]
.imply()
.reset_index()
)
# Convert intervals to strings for plotting
abstract[f"{variable}_bin"] = abstract[f"{variable}_bin"].astype(str)
# Plot
ax.plot(
abstract[f"{variable}_bin"],
abstract[target],
marker="o"
)
ax.set_title(f"Default price by {variable}")
ax.set_xlabel(variable)
ax.set_ylabel("Default price")
ax.tick_params(axis="x", rotation=45)
return ax
variables = [
"person_income",
"person_emp_length",
"loan_int_rate",
"loan_percent_income"
]
fig, axes = plt.subplots(2, 2, figsize=(16, 10))
axes = axes.flatten()
for ax, variable in zip(axes, variables):
plot_default_rate_ax(
train_imputed,
variable=variable,
goal="def",
bins=10,
ax=ax
)
plt.tight_layout()
plt.present()
After plotting the default price curves, we will analyze the chance path of every variable.
For person_income,we typically count on the default price to lower when revenue will increase.
This is smart as a result of clients with increased revenue often have extra reimbursement capability.
For person_emp_length, we additionally count on the default price to lower when employment size will increase.
An extended employment historical past might point out extra skilled stability.
For loan_int_rate, we count on the default price to extend when the rate of interest will increase.
That is coherent as a result of increased rates of interest are sometimes related to riskier debtors.
For loan_percent_income, we count on the default price to extend when the mortgage quantity turns into bigger relative to revenue.
This variable measures the burden of the mortgage in contrast with the borrower’s revenue. The next worth often means extra reimbursement stress.
If the noticed curves affirm these expectations, then the variables are coherent from a enterprise perspective.
In our case, the graphical evaluation reveals that the chosen variables have significant monotonic patterns.
The default price decreases when person_income and person_emp_length improve. Then again, the default price will increase when loan_int_rate and loan_percent_income improve.
That is precisely what we count on in credit score danger modeling.
3. Important Categorization Strategies
As soon as we perceive the connection between every steady variable and the default price, we will outline a categorization technique.
There are a lot of methods to categorize a variable.
Some strategies are easy and unsupervised. They don’t use the goal variable:
- equal-interval binning,
- equal-frequency binning,
Others are supervised. They use the default variable to create risk-based teams:
- Chi-square-based grouping,
- Weight of Proof-based grouping.
In credit score scoring, supervised strategies are sometimes most popular as a result of the purpose isn’t solely to divide the variable into intervals. The purpose is to create intervals which are significant when it comes to default danger.
On this part, we current in additional element the 2 supervised strategies.
3.1 Chi-Sq.-Primarily based Grouping
It’s a supervised binning technique. The concept is easy. We begin with many preliminary bins. Then we evaluate adjoining bins. If two adjoining bins have comparable default conduct, we merge them.
For 2 adjoining bins i and j, we construct a contingency desk:

Then we apply a Chi-square take a look at.
The Chi-square statistic is:
the place:
- O is the noticed frequency,
- E is the anticipated frequency beneath independence.
The null speculation is:
H0:The 2 bins have the identical default distribution.
The choice speculation is:
H1:The 2 bins have completely different default distributions.
If the 2 bins have comparable default conduct, we will merge them.
The process is repeated till fewer steady lessons are obtained.
The benefit of this technique is that it makes use of the default variable immediately.
The ultimate teams are due to this fact extra aligned with danger.
Nevertheless, the strategy should be used fastidiously.
With very massive samples, small variations might develop into statistically important. With very small samples, the take a look at will not be dependable.
Because of this statistical binning should at all times be mixed with enterprise judgment.
3.2 Weight of Proof-Primarily based Grouping
One other quite common technique in credit score scoring relies on Weight of Proof, additionally known as WoE. WoE measures the relative distribution of occasions and non-events in every class.
On this article, we outline:
- Dangerous = default (def = 1) = Occasions
- Good = non-default (def = 0) = Non Occasions
For a given class i, the WoE is outlined as:
With this conference:
- Optimistic WoE means increased occasion/default focus;
- Unfavorable WoE means increased non-event/good focus.
- WoE near zero, the bin has a danger stage near the typical inhabitants.
WoE-based grouping consists of merging adjoining bins with comparable WoE values. The target is to create steady teams with a transparent danger order.
In follow, the process often begins by chopping steady variables into preliminary tremendous bins, usually utilizing equal-frequency intervals. Then, adjoining intervals are progressively merged when their WoE values are shut or when certainly one of them doesn’t carry sufficient danger differentiation.
The concept isn’t solely to cut back the variety of lessons. The concept is to create lessons that carry helpful danger info.
For instance, if a bin has a WoE very near zero, it might not present sturdy discrimination. In that case, it will probably generally be merged with an adjoining bin, supplied that the merge stays coherent from a enterprise and danger perspective.
To maximise danger differentiation between closing lessons, it is usually helpful to verify that the default charges are sufficiently separated. A sensible rule is to maintain a relative distinction of at the very least 30% in danger between adjoining lessons, whereas guaranteeing that every closing class comprises at the very least 1% of the inhabitants.
These thresholds shouldn’t be utilized mechanically, however they supply helpful safeguards:
- keep away from creating lessons which are too small;
- keep away from holding lessons with nearly equivalent danger ranges;
- keep away from overfitting the event pattern;
- maintain the ultimate grouping interpretable and steady.
This technique is very helpful when the ultimate mannequin is a logistic regression, as a result of WoE-transformed variables are nicely aligned with the log-odds construction of the mannequin.
4. Python Implementation of WoE-Primarily based Categorization
We now transfer to the Python implementation.
The target is to construct a easy and clear framework to investigate binned variables and help the ultimate categorization determination.
We want three foremost instruments.
The primary instrument computes the WoE for a variable given a predefined variety of bins.
The second instrument summarizes the variety of observations and the default price for every discretized class.
The third instrument analyzes the evolution of the default price by class over time. This may assist us assess each monotonicity and stability.
That is essential as a result of a binning isn’t good solely as a result of it really works on the coaching pattern. It should additionally stay steady over time and throughout modeling datasets comparable to prepare, take a look at, and out-of-time samples.
In different phrases, a very good categorization should fulfill three circumstances:
- It should be statistically significant;
- It should be coherent from a credit score danger perspective.
- It should be steady over time.
def iv_woe(information, goal, bins=5, show_woe=False, epsilon=1e-16):
"""
Compute the Info Worth (IV) and Weight of Proof (WoE)
for all explanatory variables in a dataset.
Numerical variables with greater than 10 distinctive values are first discretized
into quantile-based bins. Categorical variables and numerical variables
with few distinctive values are used as they're.
Parameters
----------
information : pandas DataFrame
Enter dataset containing the explanatory variables and the goal.
goal : str
Identify of the binary goal variable.
The goal ought to be coded as 1 for occasion/default and 0 for non-event/non-default.
bins : int, default=5
Variety of quantile bins used to discretize steady variables.
show_woe : bool, default=False
If True, show the detailed WoE desk for every variable.
epsilon : float, default=1e-16
Small worth used to keep away from division by zero and log(0).
Returns
-------
newDF : pandas DataFrame
Abstract desk containing the Info Worth of every variable.
woeDF : pandas DataFrame
Detailed WoE desk for all variables and all teams.
"""
# Initialize output DataFrames
newDF = pd.DataFrame()
woeDF = pd.DataFrame()
# Get all column names
cols = information.columns
# Run WoE and IV calculation on all explanatory variables
for ivars in cols[~cols.isin([target])]:
# If the variable is numerical and has many distinctive values,
# discretize it into quantile-based bins
if (information[ivars].dtype.form in "bifc") and (len(np.distinctive(information[ivars].dropna())) > 10):
binned_x = pd.qcut(
information[ivars],
bins,
duplicates="drop"
)
d0 = pd.DataFrame({
"x": binned_x,
"y": information[target]
})
# In any other case, use the variable as it's
else:
d0 = pd.DataFrame({
"x": information[ivars],
"y": information[target]
})
# Compute the variety of observations and occasions in every group
d = (
d0.groupby("x", as_index=False, noticed=True)
.agg({"y": ["count", "sum"]})
)
# Rename columns
d.columns = ["Cutoff", "N", "Events"]
# Compute the proportion of occasions in every group
d["% of Events"] = (
np.most(d["Events"], epsilon)
/ (d["Events"].sum() + epsilon)
)
# Compute the variety of non-events in every group
d["Non-Events"] = d["N"] - d["Events"]
# Compute the proportion of non-events in every group
d["% of Non-Events"] = (
np.most(d["Non-Events"], epsilon)
/ (d["Non-Events"].sum() + epsilon)
)
# Compute Weight of Proof
# Right here, WoE is outlined as log(%Occasions / %Non-Occasions)
# With this conference, constructive WoE signifies increased default/occasion danger
d["WoE"] = np.log(
d["% of Events"] / d["% of Non-Events"]
)
# Compute the IV contribution of every group
d["IV"] = d["WoE"] * (
d["% of Events"] - d["% of Non-Events"]
)
# Add the variable identify to the detailed desk
d.insert(
loc=0,
column="Variable",
worth=ivars
)
# Print the worldwide Info Worth of the variable
print("=" * 30 + "n")
print(
"Info Worth of variable "
+ ivars
+ " is "
+ str(spherical(d["IV"].sum(), 6))
)
# Retailer the worldwide IV of the variable
temp = pd.DataFrame(
{
"Variable": [ivars],
"IV": [d["IV"].sum()]
},
columns=["Variable", "IV"]
)
newDF = pd.concat([newDF, temp], axis=0)
woeDF = pd.concat([woeDF, d], axis=0)
# Show the detailed WoE desk if requested
if show_woe:
print(d)
return newDF, woeDF
def tx_rsq_par_var(df, categ_vars, date, goal, cols=2, sharey=False):
"""
Generate a grid of line charts displaying the typical occasion price by class over time
for a listing of categorical variables.
Parameters
----------
df : pandas DataFrame
Enter dataset.
categ_vars : listing of str
Listing of categorical variables to investigate.
date : str
Identify of the date or time-period column.
goal : str
Identify of the binary goal variable.
The goal ought to be coded as 1 for occasion/default and 0 in any other case.
cols : int, default=2
Variety of columns within the subplot grid.
sharey : bool, default=False
Whether or not all subplots ought to share the identical y-axis scale.
Returns
-------
None
The perform shows the plots immediately.
"""
# Work on a duplicate to keep away from modifying the unique DataFrame
df = df.copy()
# Verify whether or not all required columns are current within the DataFrame
missing_cols = [col for col in [date] + categ_vars if col not in df.columns]
if missing_cols:
elevate KeyError(
f"The next columns are lacking from the DataFrame: {missing_cols}"
)
# Take away rows with lacking values within the date column or categorical variables
df = df.dropna(subset=[date] + categ_vars)
# Decide the variety of variables and the required variety of subplot rows
num_vars = len(categ_vars)
rows = math.ceil(num_vars / cols)
# Create the subplot grid
fig, axes = plt.subplots(
rows,
cols,
figsize=(cols * 6, rows * 4),
sharex=False,
sharey=sharey
)
# Flatten the axes array to make iteration simpler
axes = axes.flatten()
# Loop over every categorical variable and create one plot per variable
for i, categ_var in enumerate(categ_vars):
# Compute the typical goal worth by date and class
df_times_series = (
df.groupby([date, categ_var])[target]
.imply()
.reset_index()
)
# Reshape the information so that every class turns into one line within the plot
df_pivot = df_times_series.pivot(
index=date,
columns=categ_var,
values=goal
)
# Choose the axis akin to the present variable
ax = axes[i]
# Plot one line per class
for class in df_pivot.columns:
ax.plot(
df_pivot.index,
df_pivotData Science,
label=str(class).strip()
)
# Set chart title and axis labels
ax.set_title(f"{categ_var.strip()}")
ax.set_xlabel("Date")
ax.set_ylabel("Default price (%)")
# Alter the legend relying on the variety of classes
if len(df_pivot.columns) > 10:
ax.legend(
title="Classes",
fontsize="x-small",
loc="higher left",
ncol=2
)
else:
ax.legend(
title="Classes",
fontsize="small",
loc="higher left"
)
# Take away unused subplot axes when the grid is bigger than the variety of variables
for j in vary(i + 1, len(axes)):
fig.delaxes(axes[j])
# Add a world title to the determine
fig.suptitle(
"Default Fee by Categorical Variable",
fontsize=10,
x=0.5,
y=1.02,
ha="middle"
)
# Alter structure to keep away from overlapping parts
plt.tight_layout()
# Show the ultimate determine
plt.present()
def combined_barplot_lineplot(df, cat_vars, cible, cols=2):
"""
Generate a grid of mixed bar plots and line plots for a listing of categorical variables.
For every categorical variable:
- the bar plot reveals the relative frequency of every class;
- the road plot reveals the typical goal price for every class.
Parameters
----------
df : pandas DataFrame
Enter dataset.
cat_vars : listing of str
Listing of categorical variables to investigate.
cible : str
Identify of the binary goal variable.
The goal ought to be coded as 1 for occasion/default and 0 in any other case.
cols : int, default=2
Variety of columns within the subplot grid.
Returns
-------
None
The perform shows the plots immediately.
"""
# Depend the variety of categorical variables to plot
num_vars = len(cat_vars)
# Compute the variety of rows wanted for the subplot grid
rows = math.ceil(num_vars / cols)
# Create the subplot grid
fig, axes = plt.subplots(
rows,
cols,
figsize=(cols * 6, rows * 4)
)
# Flatten the axes array to make iteration simpler
axes = axes.flatten()
# Loop over every categorical variable
for i, cat_col in enumerate(cat_vars):
# Choose the present subplot axis for the bar plot
ax1 = axes[i]
# Convert categorical dtype variables to string if wanted
# This avoids plotting points with categorical intervals or ordered classes
if pd.api.sorts.is_categorical_dtype(df[cat_col]):
df[cat_col] = df[cat_col].astype(str)
# Compute the typical goal price by class
tx_rsq = (
df.groupby([cat_col])[cible]
.imply()
.reset_index()
)
# Compute the relative frequency of every class
effectifs = (
df[cat_col]
.value_counts(normalize=True)
.reset_index()
)
# Rename columns for readability
effectifs.columns = [cat_col, "count"]
# Merge class frequencies with goal charges
merged_data = (
effectifs
.merge(tx_rsq, on=cat_col)
.sort_values(by=cible, ascending=True)
)
# Create a secondary y-axis for the road plot
ax2 = ax1.twinx()
# Plot class frequencies as bars
sns.barplot(
information=merged_data,
x=cat_col,
y="rely",
colour="gray",
ax=ax1
)
# Plot the typical goal price as a line
sns.lineplot(
information=merged_data,
x=cat_col,
y=cible,
colour="purple",
marker="o",
ax=ax2
)
# Set the subplot title and axis labels
ax1.set_title(f"{cat_col}")
ax1.set_xlabel("")
ax1.set_ylabel("Class frequency")
ax2.set_ylabel("Danger price (%)")
# Rotate x-axis labels for higher readability
ax1.tick_params(axis="x", rotation=45)
# Take away unused subplot axes if the grid is bigger than the variety of variables
for j in vary(i + 1, len(axes)):
fig.delaxes(axes[j])
# Add a world title for the complete determine
fig.suptitle(
"Mixed Bar Plots and Line Plots for Categorical Variables",
fontsize=10,
x=0.0,
y=1.02,
ha="left"
)
# Alter structure to cut back overlapping parts
plt.tight_layout()
# Show the ultimate determine
plt.present()
4.1 Instance with person_income
Allow us to apply this process to the variable person_income.
Step one consists of performing an preliminary discretization utilizing WoE. We determine to divide the variable into three lessons and calculate the WoE of every class.

The outcomes present that WoE is monotonic.
Debtors with decrease revenue, particularly these with revenue beneath roughly 45,000, have a constructive WoE. With our conference, which means that they’ve the next focus of defaults.
Debtors with increased revenue, particularly these with revenue above roughly 71,000, have the bottom WoE worth. This means a decrease focus of defaults.
This result’s coherent with credit score danger instinct: increased revenue is mostly related to increased reimbursement capability and due to this fact decrease default danger.
We will then apply this segmentation to create a discretized variable known as person_income_dis.
A binning is beneficial provided that it stays steady.
A variable might present a very good danger sample within the coaching pattern however develop into unstable over time.
Because of this we additionally analyze the evolution of the default price by class over time :

It is usually helpful to visualise, for every class:
- the inhabitants share;
- the default price.
This may be completed utilizing a mixed bar plot and line plot.

This chart is beneficial as a result of it offers two items of data on the identical time.
The bar plot tells us whether or not the class comprises sufficient observations.
The road plot tells us whether or not the class has a coherent default price.
closing binning ought to have each a enough inhabitants dimension and a significant danger sample.
The identical cut-off factors should then be utilized to the take a look at and out-of-time datasets.
This level is essential.
The binning should be outlined on the coaching pattern after which utilized unchanged to validation samples. In any other case, we introduce information leakage and make the validation much less dependable.
Conclusion
On this article, we studied why categorization is a key step in credit score scoring mannequin improvement.
Categorization applies to each categorical and steady variables.
For categorical variables, it helps scale back the variety of modalities and makes the mannequin simpler to estimate and interpret.
For steady variables, it helps seize non-linear danger patterns, scale back the affect of outliers, deal with lacking values, enhance stability, and put together variables for Weight of Proof transformation.
We additionally mentioned a number of categorization strategies, together with equal-interval binning, equal-frequency binning, Chi-square-based grouping, and Weight of Proof-based grouping.
In follow, categorization shouldn’t be handled as a mechanical preprocessing step. categorization should fulfill statistical, enterprise, and stability necessities.
It ought to create lessons which are sufficiently populated, clearly ordered when it comes to danger, steady over time, and simple to clarify.
That is particularly essential when the ultimate mannequin is a logistic regression scorecard. In that context, WoE-based categorization helps remodel uncooked variables into steady danger lessons which are naturally aligned with the log-odds construction of the mannequin.
The primary takeaway is that this:
A credit score scoring mannequin is barely as dependable because the variables that enter it.
If variables are noisy, unstable, poorly grouped, or tough to interpret, even a very good algorithm might produce a weak mannequin.
However when variables are fastidiously categorized, the mannequin turns into extra strong, extra interpretable, and simpler to observe in manufacturing.
What about you? In what conditions do you categorize variables, for what causes, and utilizing which strategies?



{kind=link}