
Earlier than you possibly can extract info from paperwork utilizing clever doc processing (IDP) methods, you want a schema for every doc class that defines what to extract. However how do you create schemas when you may have hundreds of paperwork and don’t know what lessons exist? Doing this at scale can take substantial guide effort, making downstream IDP initiatives troublesome to justify.
On this put up, we’ll present you the way our multi-document discovery characteristic solves this downside. It serves as an automatic pre-processing step, analyzing unknown paperwork, clustering them by sort, and producing schemas prepared for the IDP Accelerator. You’ll learn the way the brand new functionality makes use of visible embeddings for automated clustering and brokers for schema technology. We’ll additionally stroll you thru operating the answer by yourself doc collections.
IDP Accelerator
The IDP Accelerator is a scalable, serverless, open-source resolution for automated doc processing and knowledge extraction. To customise the answer to your particular doc varieties, it requires a configuration file the place you specify the lessons and fields. For a minimal configuration instance, see the IDP Accelerator GitHub repo.
With out a good understanding of your doc varieties, creating this schema may be troublesome. The IDP Accelerator features a Discovery Module that may bootstrap a category configuration from a single instance doc. Nevertheless, you could already know your doc lessons and be capable of determine a consultant instance doc for every class. The multi-document discovery characteristic launched on this put up removes that prerequisite, accelerating your path to making use of the IDP Accelerator to a set of unlabeled paperwork.
Resolution overview
The next video exhibits the answer within the IDP Accelerator Console.
The multi-document discovery characteristic automates the transformation of unclassified doc collections into structured schemas prepared for downstream IDP initiatives. This resolution is built-in into the IDP accelerator’s current Discovery Module. It’s a brand new “A number of Doc” functionality alongside the “Single Doc” discovery characteristic. An AWS Step Capabilities state machine and AWS Lambda operate present orchestration and serverless compute. The answer processes paperwork from an Amazon Easy Storage Service (Amazon S3) bucket or Zip file add. Fashions obtainable by means of Amazon Bedrock generate schemas that routinely combine into the IDP Accelerator configuration file. The next diagram exhibits the total workflow.
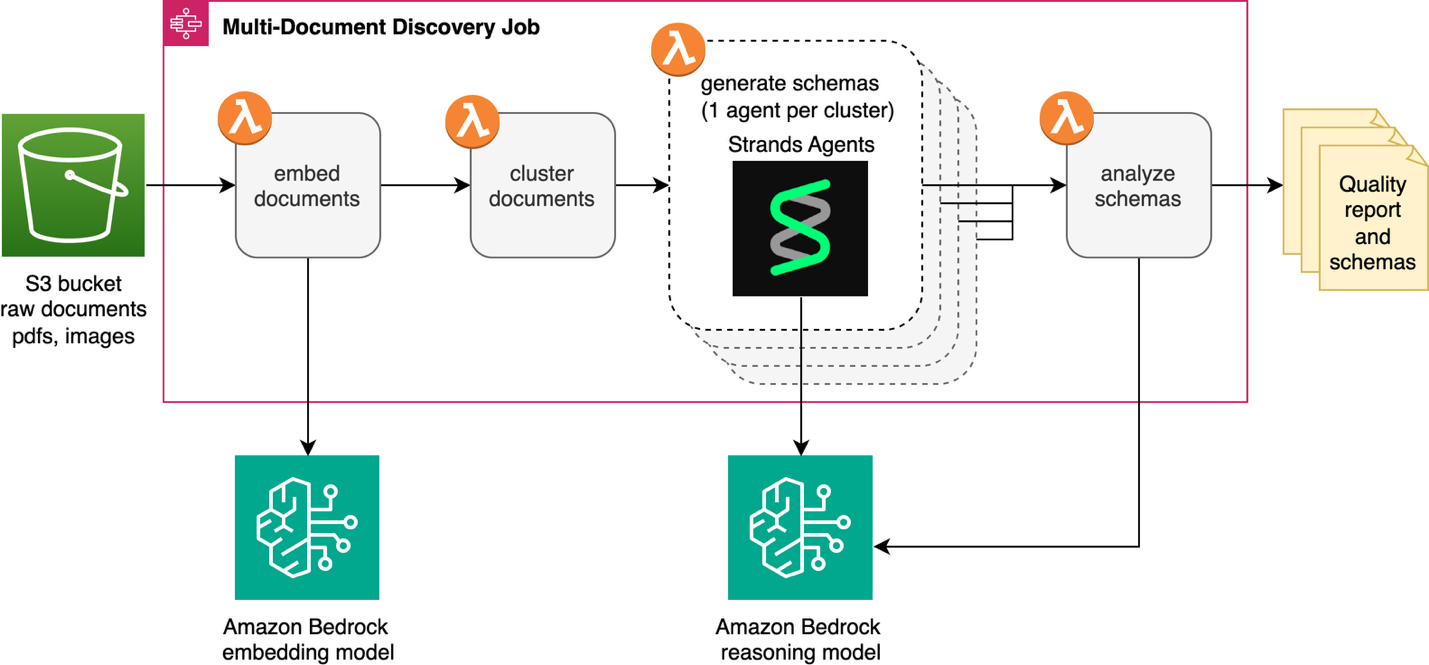
The invention job begins by changing every doc in Amazon S3 right into a vector embedding utilizing an embedding mannequin obtainable on Amazon Bedrock, then teams related paperwork into clusters. An agent constructed with Strands Brokers and an Amazon Bedrock LLM analyzes every cluster to determine the doc sort and generate a schema. Lastly, a mirrored image step critiques schemas collectively to catch overlaps and inconsistencies earlier than your last evaluation.
Technical particulars
We’ll stroll by means of every step of the method, highlighting key selections and implementation particulars.
Embedding technology
The workflow creates an embedding for every doc, changing visible options into numerical representations. For multi-page paperwork, solely the primary web page is used. Presently, the workflow makes use of visible embeddings slightly than OCR-based textual content as a result of visible embeddings seize structure, formatting, and structural cues that distinguish doc varieties, even when the textual content content material is comparable. The answer makes use of Cohere Embed v4 by means of Amazon Bedrock because the default embedding mannequin for the invention job. The embedding step routinely handles widespread ache factors and obstacles like picture compression, retry logic, and fee limiting.
Doc clustering
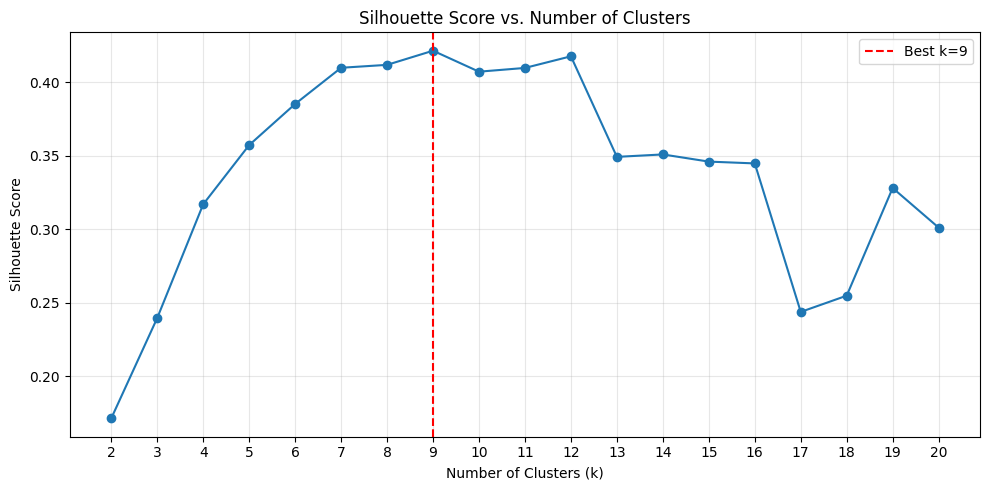
The multi-document discovery characteristic learns what number of doc varieties are in your assortment utilizing the silhouette rating. On this context, the silhouette rating supplies a measure of how well-separated the clusters are from each other and the way compact paperwork are inside every cluster. Utilizing k-means clustering, the agent assessments okay values from 2 to twenty by default and selects the grouping with the very best silhouette rating. Right here okay represents the variety of distinct doc varieties in your assortment. To create significant clusters, every should comprise no less than two paperwork. If essential, the higher okay sure is decreased under 20 to fulfill this constraint.
Benchmarking embeddings and clustering
To validate the embedding and clustering method, we ran experiments with Cohere Embed v4 on the subset of the OCR-benchmark dataset obtainable within the check set bucket deployed with the IDP Accelerator CloudFormation stack. To seek out your bucket identify, go to the CloudFormation console, choose your IDP Accelerator stack, open the Outputs tab, and search for the important thing S3TestSetBucketName.
This dataset consists of single-page doc varieties. The deployed subset incorporates 293 paperwork throughout 9 doc varieties: financial institution examine, industrial lease settlement, bank card assertion, supply be aware, tools inspection, glossary, petition kind, actual property, and shift schedule.
To judge if k-means clustering can accurately determine these groupings utilizing the Cohere embedding mannequin, we examined the silhouette rating as a metric for choosing the optimum okay worth. We ran the primary two phases of the pipeline (embedding and clustering) and analyzed the silhouette rating throughout okay values starting from 2 to twenty. The next plot exhibits the silhouette rating distribution throughout these okay values. The very best silhouette rating happens at okay=9, which matches the bottom reality variety of doc varieties within the dataset.
The TSNE-plot (t-distributed Stochastic Neighbor Embedding plot, a visualization method that reduces high-dimensional knowledge to 2D house whereas preserving relationships between knowledge factors) exhibits the visualization of those embeddings in 2-dimensional house, with the cluster classification proven within the legend.
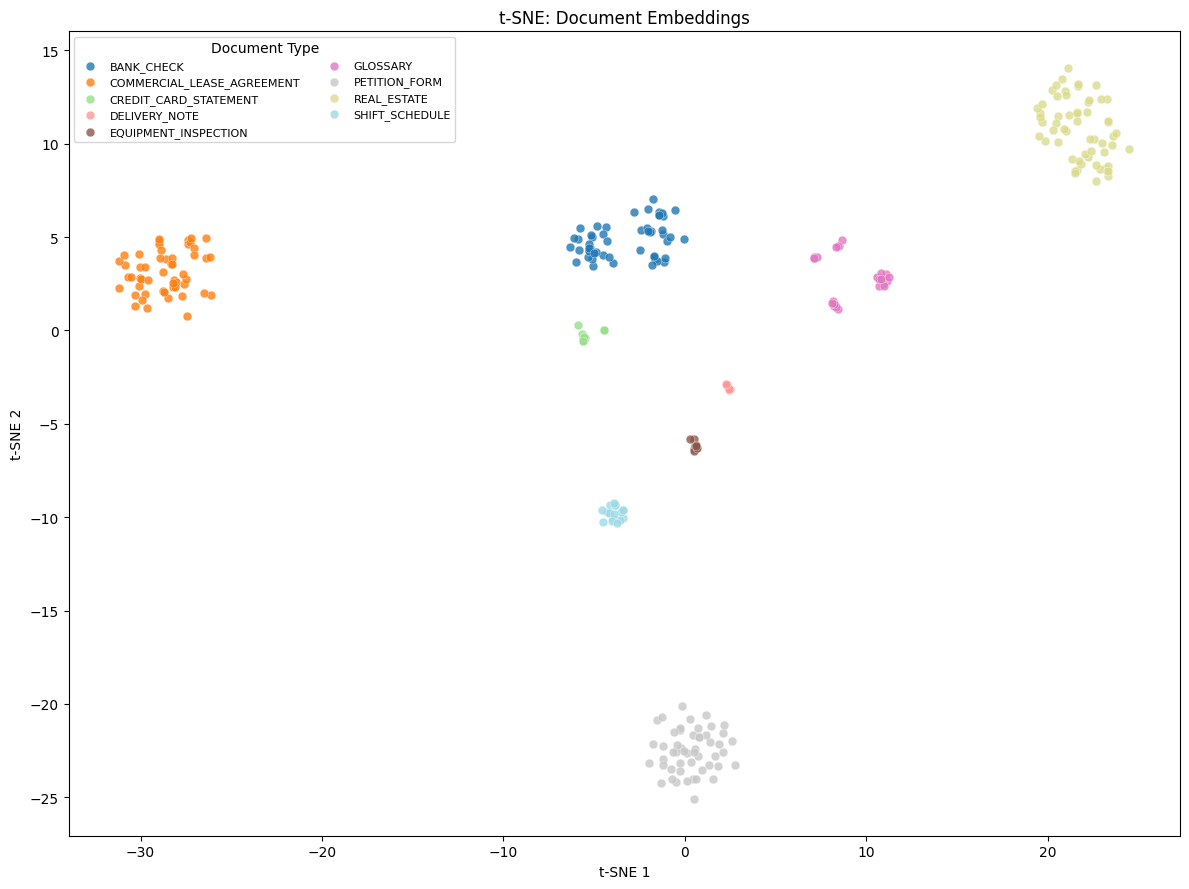
The clustering achieved an ideal Adjusted Rand Index (ARI) and Normalized Mutual Info (NMI) of 1.0. ARI measures how effectively the clustering matches the true groupings, whereas NMI quantifies the quantity of data shared between the expected and precise clusters. Each cluster maps one-to-one to a floor reality doc class at 100% purity. These outcomes exhibit that high-quality multimodal embeddings can allow totally unsupervised doc classification. The embeddings precisely separate various doc varieties, akin to financial institution checks, actual property types, and bank card statements, with out labeled coaching knowledge.
Be aware: Efficiency on this benchmark dataset doesn’t assure related outcomes in your particular doc knowledge as a result of the traits of your dataset straight affect the standard of the outcomes.
Agentic schema technology
After the clusters are recognized, the pipeline enters the agentic section. For every cluster, a Strands Agent is invoked to find out the doc sort and generate a schema. We selected Strands Brokers for its model-driven method. It offers the mannequin the flexibleness to purpose by means of every schema autonomously. The agent must strategically visualize paperwork at varied areas throughout the cluster to seize the total selection earlier than producing a schema. For instance, it examines one doc close to the middle, one on the periphery, and one at a center distance. A extra deterministic, mounted sampling method wouldn’t work right here as a result of clustering high quality relies upon closely in your particular paperwork. To do that, the agent is supplied with two specialised instruments:
- Cluster Evaluation Device – Retrieves doc IDs ordered by distance from the cluster centroid, enabling the agent to pattern strategically throughout the vary of variation throughout the cluster.
- Doc Viewer Device – Fetches and compresses doc pictures for visible inspection, routinely dealing with measurement constraints for the mannequin’s context window.
The agent’s system immediate encodes area experience about JSON Schema conventions and IDP Accelerator configuration necessities. It instructs the agent to:
- Pattern paperwork strategically, stopping early if assured it has ample protection.
- Generate JSON Schemas with correct metadata, sort definitions, and descriptions.
- Embody IDP Accelerator-specific annotations akin to
x-aws-idp-document-typeandx-aws-idp-evaluation-method.x-aws-idp-evaluation-methodis utilized by the Stickler-based analysis extension. - Create reusable
$defsfor widespread constructions like addresses, line gadgets, and tax info. - Apply acceptable analysis strategies based mostly on discipline sort:
EXACTfor strings,NUMERIC_EXACTfor numbers,LLMfor complicated or nested objects.
The instruments, immediate, and mannequin equip the agent with capabilities to purpose about its personal sampling technique. These brokers run in parallel, so that you’re not ready for every cluster to complete earlier than the subsequent one begins.
Schema evaluation
After every agent independently generates a schema, the schema evaluation step evaluates the holistic differentiation between the output. It assesses whether or not the found doc groupings are well-separated or overlapping, and whether or not the generated schemas are full and constant. It appears to be like for redundancies or duplication throughout doc varieties. Primarily based on these findings, it surfaces concrete suggestions akin to merging clusters or refining discipline definitions. It produces a abstract report together with a human-readable overview of your lessons. This high quality report is seen to you within the Discovery Job particulars of the IDP Accelerator.
Operating a job in your paperwork
To run the multi-document discovery workflow by yourself paperwork, comply with these steps within the IDP Accelerator Console.
Step 1: Create a brand new configuration
Begin by making a contemporary configuration within the IDP Accelerator Console:
- Navigate to the Configuration part and choose View/Edit Configuration.
- Select Doc Schema > Wipe All to create a brand new empty configuration.
- Choose Save as Model, present a descriptive Model Title, then select Save as Model.
Step 2: Run multi-document discovery
Along with your configuration prepared, provoke the invention course of:
- Navigate to the Discovery part and choose the A number of Paperwork choice.
- Select the configuration model you simply created.
- Configure your doc supply:
- Choose both S3 Path or Zip Add.
- Select your supply bucket.
- Specify the S3 prefix the place your paperwork are saved.
Be aware: Your paperwork should be added to one of many IDP Accelerator’s current buckets (Discovery Bucket, Check Bucket, or Enter Bucket) to make use of the Supply Bucket choice.
- Select Begin Discovery to set off the state machine.
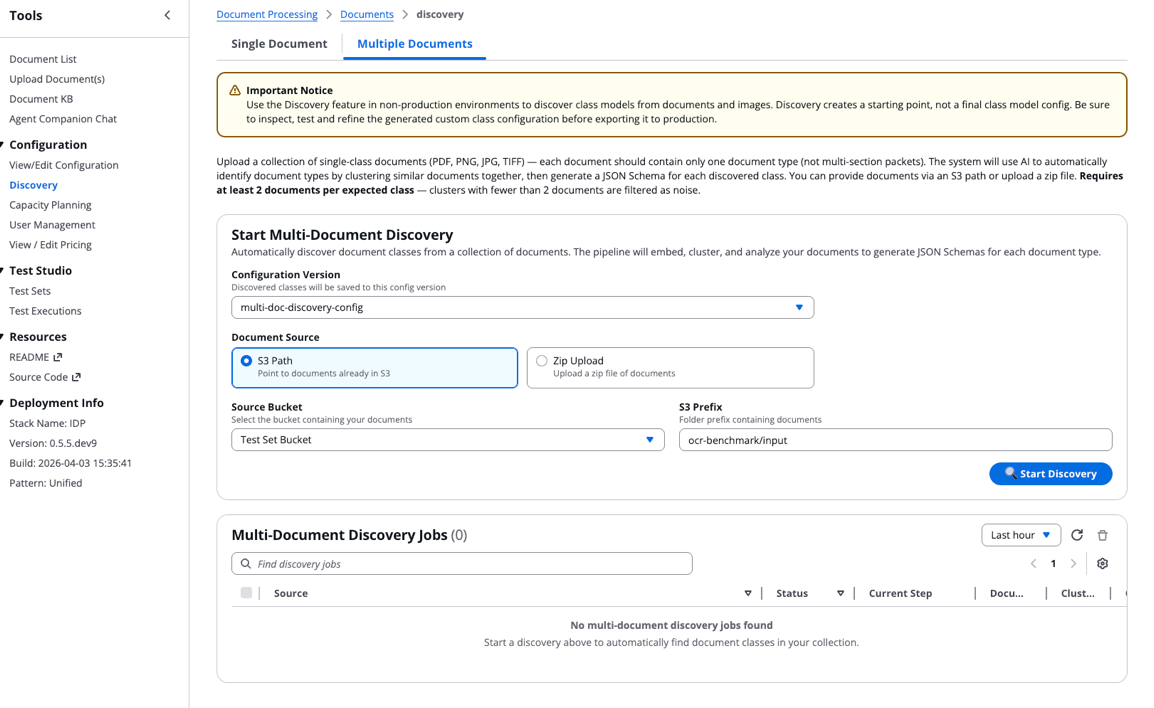
Step 3: Monitor discovery job and look at outcomes
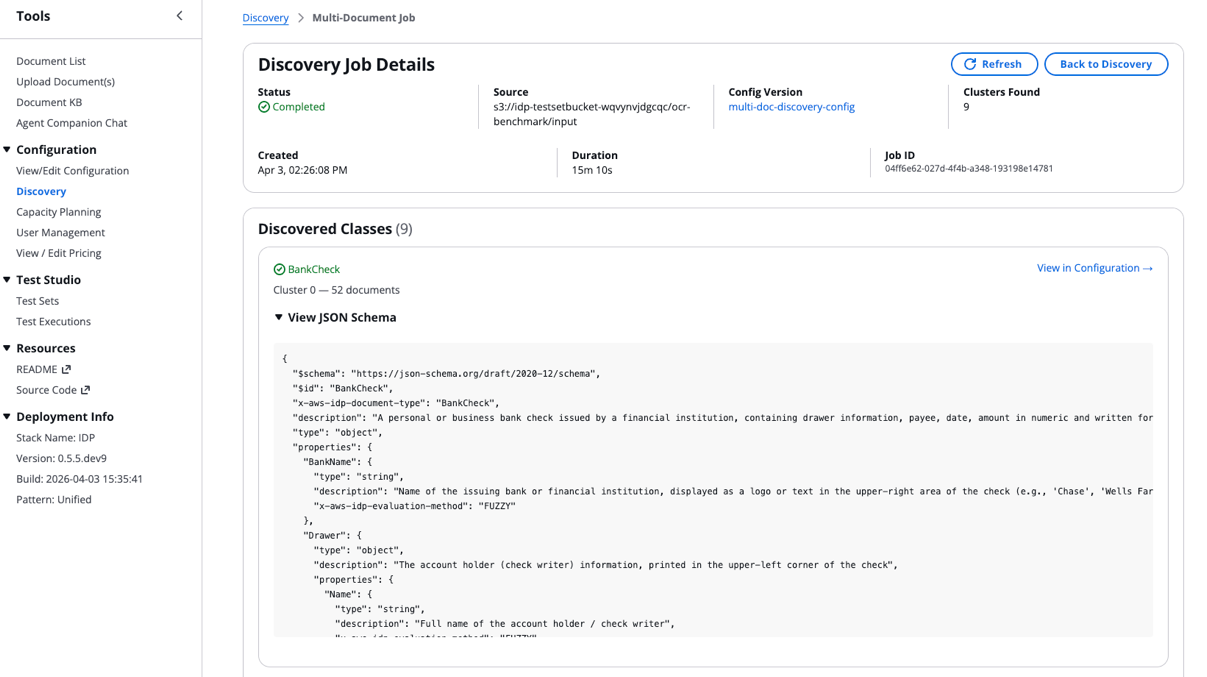
Observe your discovery job progress:
- A brand new entry will seem within the Multi-Doc Discovery Jobs desk displaying execution standing, present step, and metadata.
- After the job completes, select the Supply discipline to view outcomes:
- Scroll to the underside of the Discovery Job Particulars to entry the High quality Report:
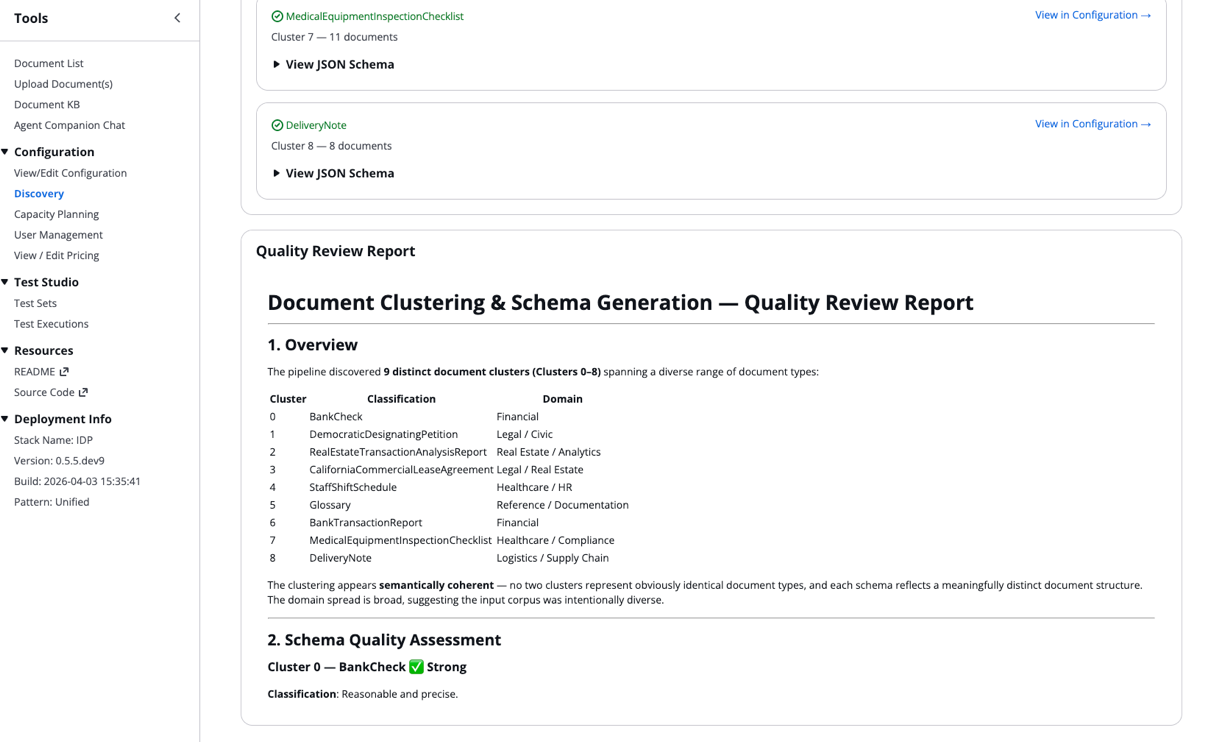
The found lessons and their JSON schemas routinely combine into your configuration file.
Greatest practices for optimum outcomes
Earlier than you run the multi-document discovery job at scale, there are a couple of finest practices price conserving in thoughts. As a result of the workflow presently processes solely the primary web page of every PDF, ensure that your enter information are single-document information. Multi-document packets aren’t but supported. After you may have preliminary outcomes, totally evaluation the standard report abstract to catch points like overlapping clusters or uneven doc distributions earlier than you finalize your schemas.
Subsequent steps
The place you go from right here will depend on what the workflow present in your paperwork:
- In case your schemas look clear and the standard report exhibits low overlap: You’re prepared to maneuver ahead with operating IDP at scale in your paperwork. The schemas are routinely added to the lessons discipline of the IDP Accelerator configuration.
- If the standard report flagged overlapping clusters, evaluation the suggestions and use them to refine the generated schemas. This may embody merging related schemas right into a single class or adjusting discipline definitions to scale back overlap.
- If schema high quality is inconsistent throughout clusters: Test whether or not your doc assortment has a extremely uneven distribution of doc varieties. Operating the invention job on a extra balanced subset will help the agent produce extra dependable clusters and schemas.
Conclusion
On this put up, we confirmed you the way the multi-document discovery characteristic solves the problem of needing schemas earlier than you possibly can course of paperwork however needing to course of paperwork earlier than you possibly can construct schemas. The answer combines visible embeddings, automated clustering, and agentic schema technology with multimodal LLMs. It transforms an opaque assortment of unknown paperwork into structured, review-ready doc lessons and schemas. You’ve seen how the workflow handles embedding technology, cluster tuning, and parallel classification and schema technology. You’ve additionally seen how the reflection step offers you a clear evaluation into the agent’s generated output for human evaluation.
We’d love to listen to how the multi-document discovery characteristic works in your doc collections. Share your outcomes, questions, or strategies within the feedback under. Should you run into points or need to contribute, open a problem or pull request within the GitHub repository.
Concerning the authors



{kind=link}