Trendy AI purposes demand quick, cost-effective responses from massive language fashions, particularly when dealing with lengthy paperwork or prolonged conversations. Nevertheless, LLM inference can develop into prohibitively gradual and costly as context size will increase, with latency rising exponentially and prices mounting with every interplay.
LLM inference requires recalculating consideration mechanisms for the earlier tokens when producing every new token. This creates important computational overhead and excessive latency for lengthy sequences. Key-value (KV) caching addresses this bottleneck by storing and reusing key-value vectors from earlier computations, decreasing inference latency and time-to-first-token (TTFT). Clever routing in LLMs is a method that sends requests with shared prompts to the identical inference occasion to maximise the effectivity of the KV cache. It routes a brand new request to an occasion that has already processed the identical prefix, permitting it to reuse the cached KV information to speed up processing and scale back latency. Nevertheless, clients have informed us that organising and configuring the correct framework for KV caching and clever routing at manufacturing scale is difficult and takes lengthy experimental cycles.
In the present day we’re excited to announce that Amazon SageMaker HyperPod now helps Managed Tiered KV Cache and Clever Routing capabilities by the HyperPod Inference Operator. These new capabilities can ship important efficiency enhancements for LLM inference workloads by decreasing time to first token (TTFT) by as much as 40%, growing throughput, and decreasing compute prices by as much as 25% when used for lengthy context prompts and multi-turn chat conversations utilizing our inside instruments. These capabilities can be found to be used with the HyperPod Inference Operator, which robotically manages the routing and distributed KV caching infrastructure, considerably decreasing operational overhead whereas delivering enterprise-grade efficiency for manufacturing LLM deployments. By utilizing the brand new Managed Tiered KV Cache characteristic you may effectively offload consideration caches to CPU reminiscence (L1 cache) and distribute L2 cache for cross-instance sharing by a tiered storage structure in HyperPod for optimum useful resource utilization and value effectivity at scale.
Environment friendly KV caching mixed with clever routing maximizes cache hits throughout employees so you may obtain increased throughput and decrease prices to your mannequin deployments. These options are significantly helpful in purposes which might be processing lengthy paperwork the place the identical context or prefix is referenced, or in multi-turn conversations the place context from earlier exchanges must be maintained effectively throughout a number of interactions.
For instance, authorized groups analyzing 200 web page contracts can now obtain prompt solutions to follow-up questions as an alternative of ready 5+ seconds per question, healthcare chatbots preserve pure dialog stream throughout 20+ flip affected person dialogues, and customer support programs course of hundreds of thousands of every day requests with each higher efficiency and decrease infrastructure prices. These optimizations make doc evaluation, multi-turn conversations, and high-throughput inference purposes economically viable at enterprise scale.
Optimizing LLM inference with Managed Tiered KV Cache and Clever Routing
Let’s break down the brand new options:
- Managed Tiered KV Cache: Automated administration of consideration states throughout CPU reminiscence (L1) and distributed tiered storage (L2) with configurable cache sizes and eviction insurance policies. SageMaker HyperPod handles the distributed cache infrastructure by the newly launched tiered storage, assuaging operational overhead for cross node cache sharing throughout clusters. KV cache entries are accessible cluster-wide (L2) so {that a} node can profit from computations carried out by different nodes.
- Clever Routing: Configurable request routing to maximise cache hits utilizing methods like prefix-aware, KV-aware, and round-robin routing.
- Observability: Constructed-in HyperPod Observability integration for observability of metrics and logs for Managed Tiered KV Cache and Clever Routing in Amazon Managed Grafana.
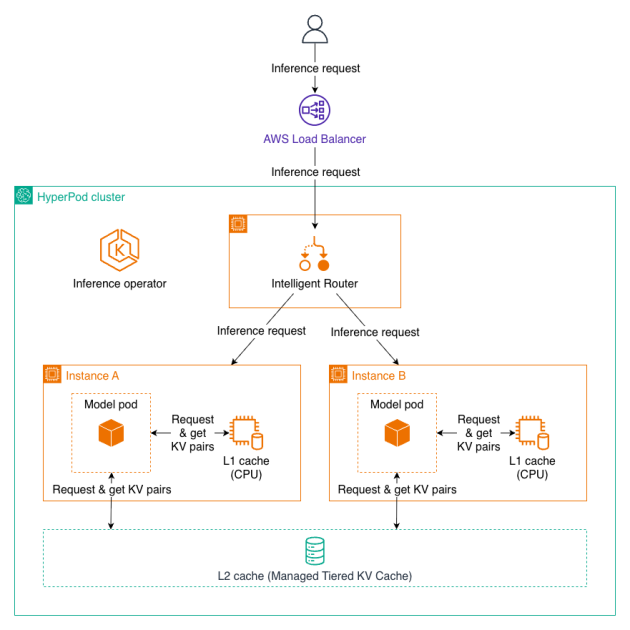
Pattern stream for inference requests with KV caching and Clever Routing
As a person sends an inference request to HyperPod Load Balancer, it forwards the request to the Clever Router throughout the HyperPod cluster. The Clever Router dynamically distributes requests to essentially the most acceptable mode pod (Occasion A or Occasion B) primarily based on the routing technique to maximise KV cache hit and decrease inference latency. Because the request reaches the mannequin pod, the pod first checks L1 cache (CPU) for ceaselessly used key-value pairs, then queries the shared L2 cache (Managed Tiered KV Cache) if wanted, earlier than performing full computation of the token. Newly generated KV pairs are saved in each cache tiers for future reuse. After computation completes, the inference outcome flows again by the Clever Router and Load Balancer to the person.
Managed Tiered KV Cache
Managed Tiered KV Cache and Clever Routing are configurable opt-in options. When enabling Managed KV Cache, L1 cache is enabled by default, whereas each L1 and L2 cache could be configured to be enabled or disabled. The L1 cache resides domestically on every inference node using CPU reminiscence. This native cache offers considerably quick entry, making it superb for ceaselessly accessed information inside a single mannequin occasion. The cache robotically manages reminiscence allocation and eviction insurance policies to optimize for essentially the most invaluable cached content material. The L2 cache operates as a distributed cache layer spanning the complete cluster, enabling cache sharing throughout a number of mannequin situations. We assist two backend choices for L2 cache, every with the next advantages:
- Managed Tiered KV Cache (Really helpful): A HyperPod disaggregated reminiscence resolution that provides glorious scalability to Terabyte swimming pools, low latency, AWS community optimized, GPU-aware design with zero-copy assist, and value effectivity at scale.
- Redis: Easy to arrange, works properly for small to medium workloads, and gives a wealthy setting of instruments and integrations.
The 2-tier structure works collectively seamlessly. When a request arrives, the system first checks the L1 cache for the required KV pairs. If discovered, they’re used instantly with minimal latency. If not present in L1, the system queries the L2 cache. If discovered there, the information is retrieved and optionally promoted to L1 for quicker future entry. Provided that the information will not be current in both cache does the system carry out the complete computation, storing the leads to each L1 and L2 for future reuse.
Clever Routing
Our Clever Routing system gives 4 configurable methods to optimize request distribution primarily based in your workload traits, with the routing technique being user-configurable at deployment time to match your software’s particular necessities.
- Prefix-aware routing serves because the default technique, sustaining a tree construction to trace which prefixes are cached on which endpoints, delivering robust general-purpose efficiency for purposes with widespread immediate templates comparable to multi-turn conversations, customer support bots with customary greetings, and code era with widespread imports.
- KV-aware routing offers essentially the most refined cache administration by a centralized controller that tracks cache places and handles eviction occasions in real-time, excelling at lengthy dialog threads, doc processing workflows, and prolonged coding classes the place most cache effectivity is vital.
- Spherical-robin routing gives essentially the most simple method, distributing requests evenly throughout the obtainable employees, finest suited to eventualities the place requests are impartial, comparable to batch inference jobs, stateless API calls, and cargo testing eventualities.
| Technique | Greatest for |
| Prefix-aware routing (default) | Multi-turn conversations, customer support bots, code era with widespread headers |
| KV-aware routing | Lengthy conversations, doc processing, prolonged coding classes |
| Spherical-robin routing | Batch inference, stateless API calls, load testing |
Deploying the Managed Tiered KV Cache and Clever Routing resolution
Conditions
Create a HyperPod cluster with Amazon EKS as an orchestrator.
- In Amazon SageMaker AI console, navigate to HyperPod Clusters, then Cluster Administration.
- On the Cluster Administration web page, choose Create HyperPod cluster, then Orchestrated by Amazon EKS.

- You need to use one-click deployment from the SageMaker AI console. For cluster arrange particulars see Making a SageMaker HyperPod cluster with Amazon EKS orchestration.
- Confirm that the HyperPod cluster standing is InService.

- Confirm that the inference operator is up and operating. The Inference add-on is put in as a default possibility if you create the HyperPod cluster from the console. If you wish to use an present EKS cluster, see Establishing your HyperPod clusters for mannequin deployment to manually set up the inference operator.
From the command line, run the next command:
Output:

Or, confirm that the operator is operating from console. Navigate to EKS cluster, Assets, Pods, Choose namespace, hyperpod-inference-system.
Getting ready your mannequin deployment manifest information
You possibly can allow these options by including configurations to your InferenceEndpointConfig customized CRD file.
For the entire instance, go to the AWS samples GitHub repository.
Observability
You possibly can monitor Managed KV Cache and Clever Routing metrics by the SageMaker HyperPod Observability options. For extra data, see Speed up basis mannequin growth with one-click observability in Amazon SageMaker HyperPod.
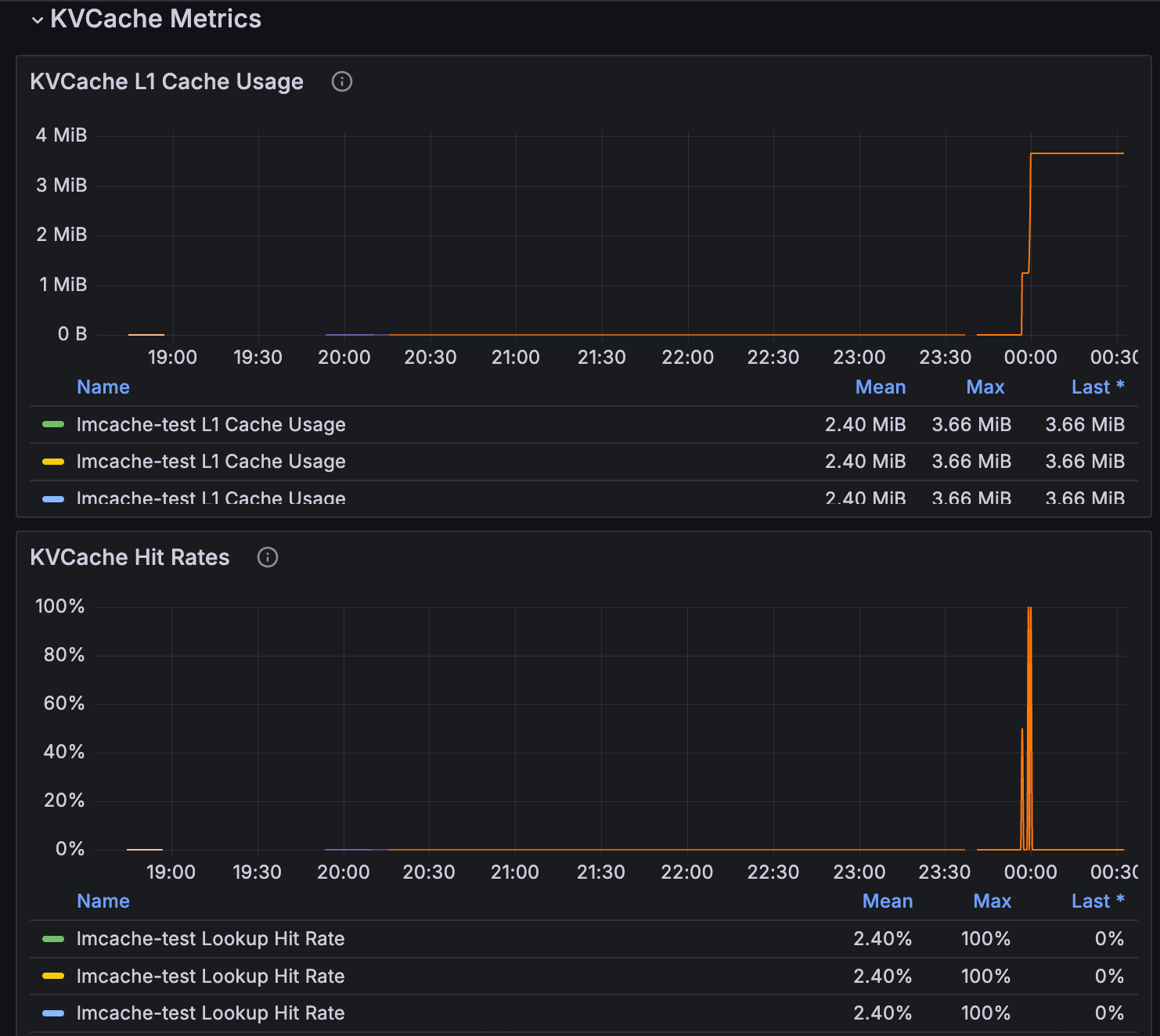
KV Cache Metrics can be found within the Inference dashboard.
Benchmarking
We performed complete benchmarking to validate real-world efficiency enhancements for manufacturing LLM deployments. Our benchmarks have been run with Managed Tiered KV Cache and Clever Routing characteristic utilizing the Llama-3.1-70B-Instruct mannequin deployed throughout 7 replicas on p5.48xlarge situations (every outfitted with eight NVIDIA GPUs), beneath a steady-load site visitors sample. The benchmark setting used a devoted consumer node group—with one c5.12xlarge occasion per 100 concurrent requests to generate a managed load, and a devoted server node group, ensuring mannequin servers operated in isolation to assist stop useful resource competition beneath excessive concurrency.
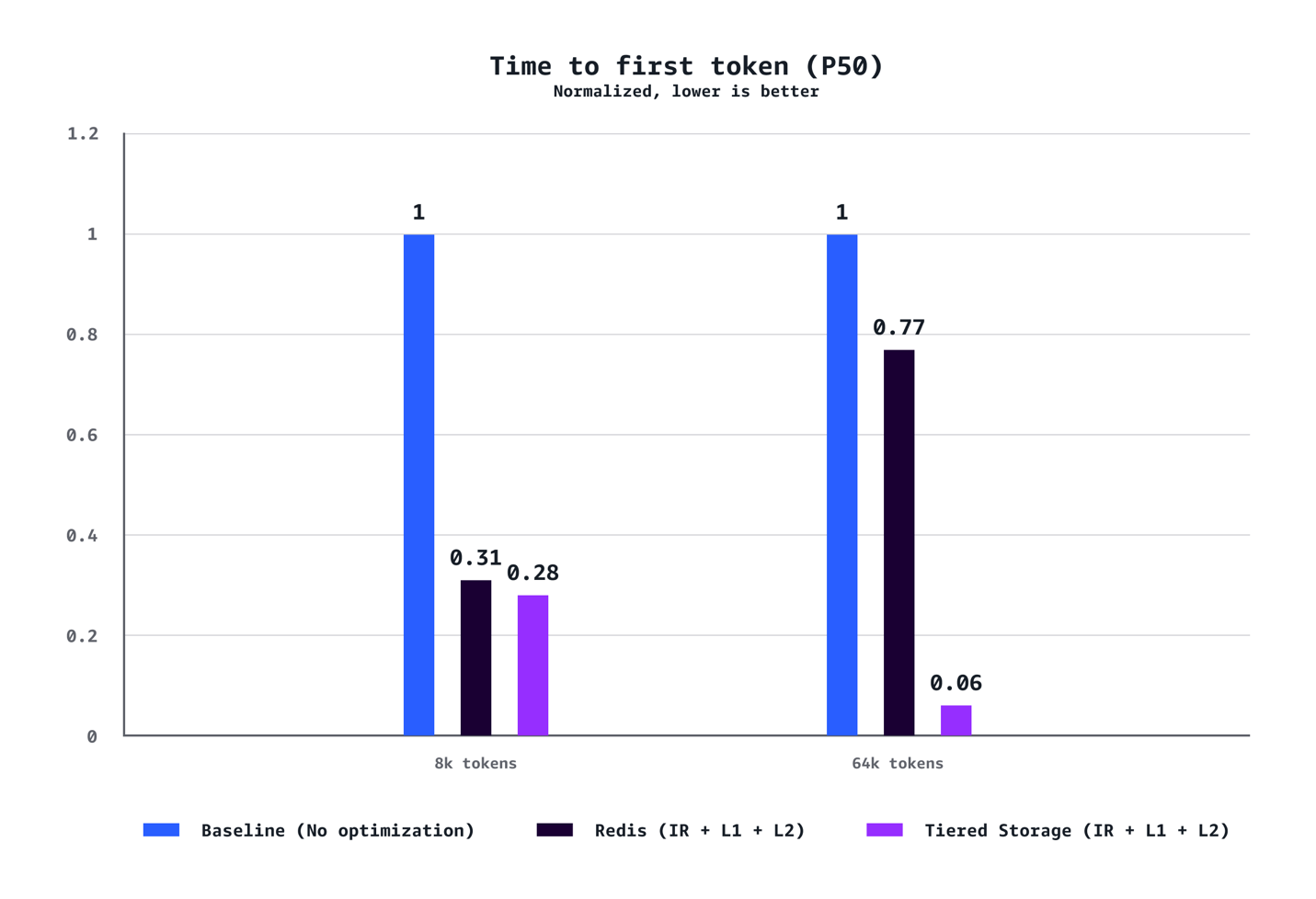
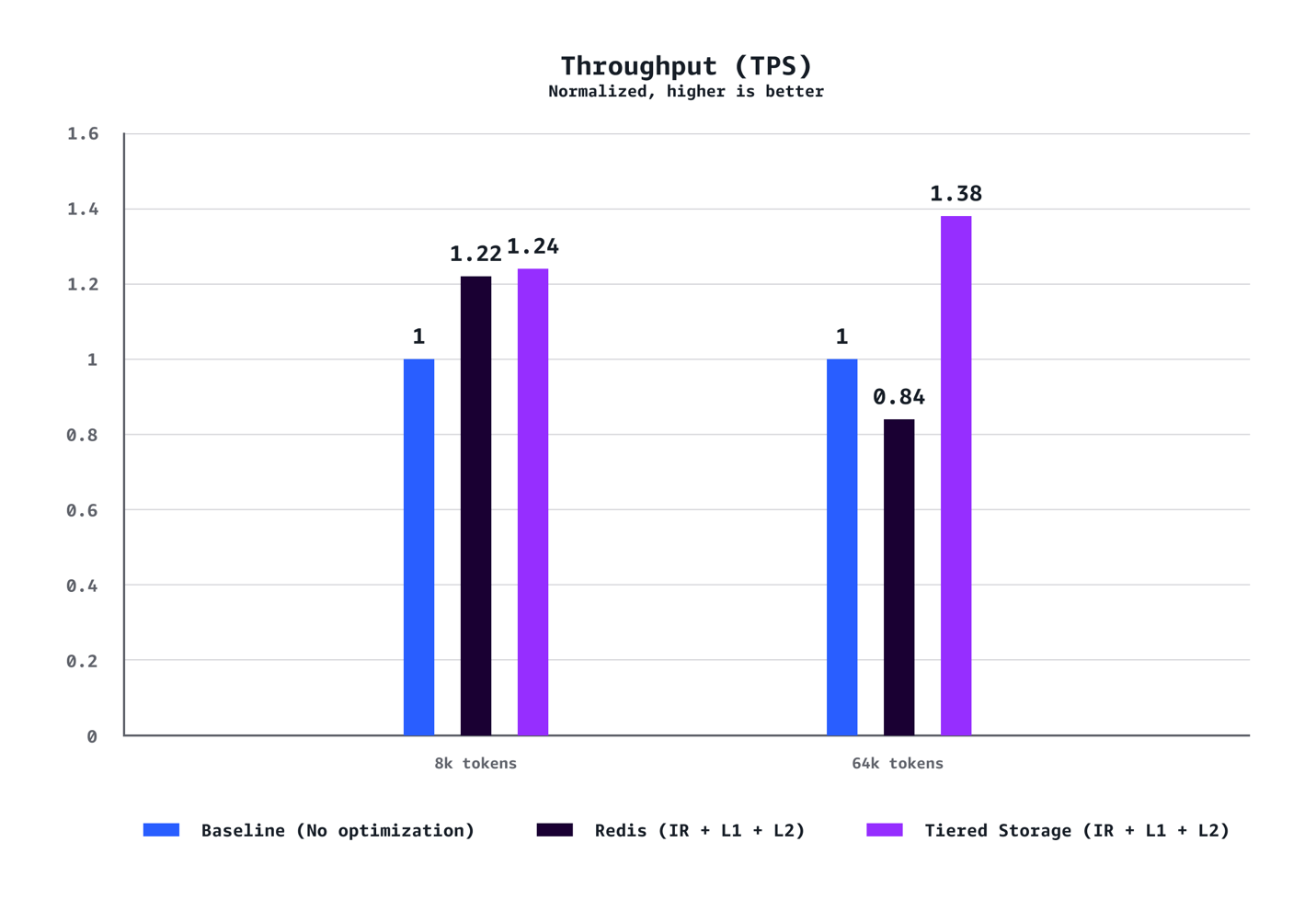
Our benchmarks show {that a} mixture of L1 and L2 Managed Tiered KV Cache and Clever Routing delivers substantial efficiency enhancements throughout a number of dimensions. For medium context eventualities (8k tokens), we noticed a 40% discount in time to first token (TTFT) at P90, 72% discount at P50, 24% enhance in throughput, and 21% value discount in comparison with baseline configurations with out optimization. The advantages are much more pronounced for lengthy context workloads (64K tokens), reaching a 35% discount in TTFT at P90, 94% discount at P50, 38% throughput enhance, and 28% value financial savings. The optimization advantages scale dramatically with context size. Whereas 8K token eventualities show stable enhancements throughout the metrics, 64K token workloads expertise transformative features that essentially change the person expertise. Our testing additionally confirmed that AWS-managed tiered storage constantly outperformed Redis-based L2 caching throughout the eventualities. The tiered storage backend delivered higher latency and throughput with out requiring the operational overhead of managing separate Redis infrastructure, making it the really useful alternative for many deployments. Lastly, not like conventional efficiency optimizations that require tradeoffs between value and velocity, this resolution delivers each concurrently.
TTFT (P90)
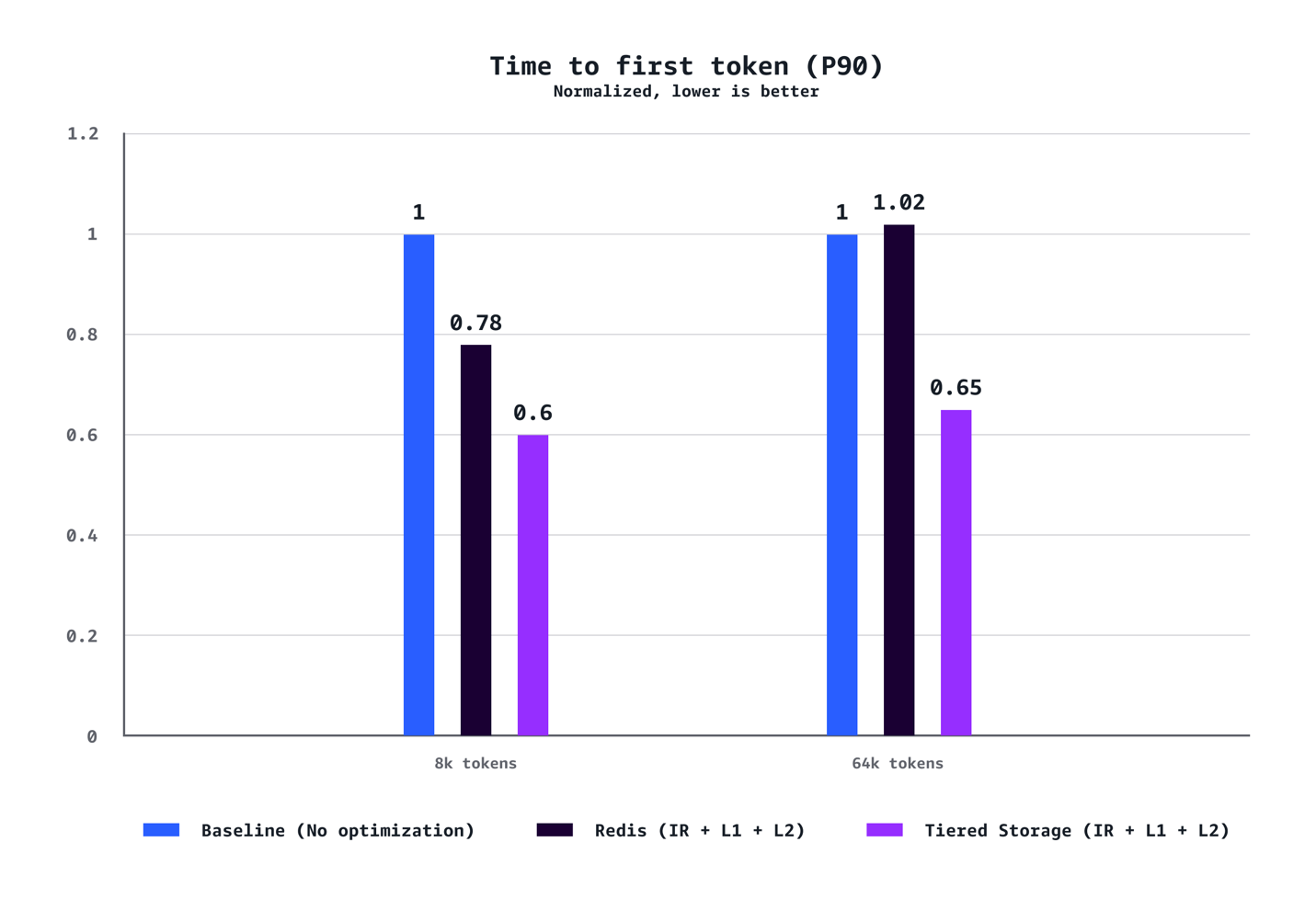
TTFT (P50)
Throughput (TPS)
Price/1000 token ($)

Conclusion
Managed Tiered KV Cache and Clever Routing in Amazon SageMaker HyperPod Mannequin Deployment make it easier to optimize LLM inference efficiency and prices by environment friendly reminiscence administration and sensible request routing. You will get began at present by including these configurations to your HyperPod mannequin deployments in the AWS Areas the place SageMaker HyperPod is offered.
To be taught extra, go to the Amazon SageMaker HyperPod documentation or observe the mannequin deployment getting began information.
Concerning the authors
 Chaitanya Hazarey is the Software program Growth Supervisor for SageMaker HyperPod Inference at Amazon, bringing in depth experience in full-stack engineering, ML/AI, and information science. As a passionate advocate for accountable AI growth, he combines technical management with a deep dedication to advancing AI capabilities whereas sustaining moral concerns. His complete understanding of contemporary product growth drives innovation in machine studying infrastructure.
Chaitanya Hazarey is the Software program Growth Supervisor for SageMaker HyperPod Inference at Amazon, bringing in depth experience in full-stack engineering, ML/AI, and information science. As a passionate advocate for accountable AI growth, he combines technical management with a deep dedication to advancing AI capabilities whereas sustaining moral concerns. His complete understanding of contemporary product growth drives innovation in machine studying infrastructure.
 Pradeep Cruz is a Senior SDM at Amazon Net Companies (AWS), driving AI infrastructure and purposes at enterprise scale. Main cross-functional organizations at Amazon SageMaker AI, he has constructed and scaled a number of high-impact companies for enterprise clients together with SageMaker HyperPod-EKS Inference, Activity Governance, Characteristic Retailer, AIOps, and JumpStart Mannequin Hub at AWS, alongside enterprise AI platforms at T-Cellular and Ericsson. His technical depth spans distributed programs, GenAI/ML, Kubernetes, cloud computing, and full-stack software program growth.
Pradeep Cruz is a Senior SDM at Amazon Net Companies (AWS), driving AI infrastructure and purposes at enterprise scale. Main cross-functional organizations at Amazon SageMaker AI, he has constructed and scaled a number of high-impact companies for enterprise clients together with SageMaker HyperPod-EKS Inference, Activity Governance, Characteristic Retailer, AIOps, and JumpStart Mannequin Hub at AWS, alongside enterprise AI platforms at T-Cellular and Ericsson. His technical depth spans distributed programs, GenAI/ML, Kubernetes, cloud computing, and full-stack software program growth.
 Vinay Arora is a Specialist Answer Architect for Generative AI at AWS, the place he collaborates with clients in designing cutting-edge AI options leveraging AWS applied sciences. Previous to AWS, Vinay has over twenty years of expertise in finance—together with roles at banks and hedge funds—he has constructed threat fashions, buying and selling programs, and market information platforms. Vinay holds a grasp’s diploma in laptop science and enterprise administration.
Vinay Arora is a Specialist Answer Architect for Generative AI at AWS, the place he collaborates with clients in designing cutting-edge AI options leveraging AWS applied sciences. Previous to AWS, Vinay has over twenty years of expertise in finance—together with roles at banks and hedge funds—he has constructed threat fashions, buying and selling programs, and market information platforms. Vinay holds a grasp’s diploma in laptop science and enterprise administration.
 Piyush Daftary is a Senior Software program Engineer at AWS, engaged on Amazon SageMaker with a give attention to constructing performant, scalable inference programs for big language fashions. His technical pursuits span AI/ML, databases, and search applied sciences, the place he focuses on creating production-ready options that allow environment friendly mannequin deployment and inference at scale. His work includes optimizing system efficiency, implementing clever routing mechanisms, and designing architectures that assist each analysis and manufacturing workloads, with a ardour for fixing complicated distributed programs challenges and making superior AI capabilities extra accessible to builders and organizations. Outdoors of labor, he enjoys touring, mountain climbing, and spending time with household.
Piyush Daftary is a Senior Software program Engineer at AWS, engaged on Amazon SageMaker with a give attention to constructing performant, scalable inference programs for big language fashions. His technical pursuits span AI/ML, databases, and search applied sciences, the place he focuses on creating production-ready options that allow environment friendly mannequin deployment and inference at scale. His work includes optimizing system efficiency, implementing clever routing mechanisms, and designing architectures that assist each analysis and manufacturing workloads, with a ardour for fixing complicated distributed programs challenges and making superior AI capabilities extra accessible to builders and organizations. Outdoors of labor, he enjoys touring, mountain climbing, and spending time with household.
 Ziwen Ning is a Senior Software program Growth Engineer at AWS, presently engaged on SageMaker Hyperpod Inference with a give attention to constructing scalable infrastructure for large-scale AI mannequin inference. His technical experience spans container applied sciences, Kubernetes orchestration, and ML infrastructure, developed by in depth work throughout the AWS ecosystem. He has deep expertise in container registries and distribution, container runtime growth and open supply contributions, and containerizing ML workloads with customized useful resource administration and monitoring. Ziwen is keen about designing production-grade programs that make superior AI capabilities extra accessible. In his free time, he enjoys kickboxing, badminton, and immersing himself in music.
Ziwen Ning is a Senior Software program Growth Engineer at AWS, presently engaged on SageMaker Hyperpod Inference with a give attention to constructing scalable infrastructure for large-scale AI mannequin inference. His technical experience spans container applied sciences, Kubernetes orchestration, and ML infrastructure, developed by in depth work throughout the AWS ecosystem. He has deep expertise in container registries and distribution, container runtime growth and open supply contributions, and containerizing ML workloads with customized useful resource administration and monitoring. Ziwen is keen about designing production-grade programs that make superior AI capabilities extra accessible. In his free time, he enjoys kickboxing, badminton, and immersing himself in music.
 Roman Blagovirnyy is a Sr. Person Expertise Designer on the SageMaker AI workforce with 19 years of numerous expertise in interactive, workflow, and UI design, engaged on enterprise and B2B purposes and options for the finance, healthcare, safety, and HR industries previous to becoming a member of Amazon. At AWS Roman was a key contributor to the design of SageMaker AI Studio, SageMaker Studio Lab, information and mannequin governance capabilities, and HyperPod. Roman’s presently works on new options and enhancements to the administrator expertise for HyperPod. Along with this, Roman has a eager curiosity in design operations and course of.
Roman Blagovirnyy is a Sr. Person Expertise Designer on the SageMaker AI workforce with 19 years of numerous expertise in interactive, workflow, and UI design, engaged on enterprise and B2B purposes and options for the finance, healthcare, safety, and HR industries previous to becoming a member of Amazon. At AWS Roman was a key contributor to the design of SageMaker AI Studio, SageMaker Studio Lab, information and mannequin governance capabilities, and HyperPod. Roman’s presently works on new options and enhancements to the administrator expertise for HyperPod. Along with this, Roman has a eager curiosity in design operations and course of.
 Caesar Chen is the Software program Growth Supervisor for SageMaker HyperPod at AWS, the place he leads the event of cutting-edge machine studying infrastructure. With in depth expertise in constructing production-grade ML programs, he drives technical innovation whereas fostering workforce excellence. His work in scalable mannequin internet hosting infrastructure empowers information scientists and ML engineers to deploy and handle fashions with higher effectivity and reliability.
Caesar Chen is the Software program Growth Supervisor for SageMaker HyperPod at AWS, the place he leads the event of cutting-edge machine studying infrastructure. With in depth expertise in constructing production-grade ML programs, he drives technical innovation whereas fostering workforce excellence. His work in scalable mannequin internet hosting infrastructure empowers information scientists and ML engineers to deploy and handle fashions with higher effectivity and reliability.
 Chandra Lohit Reddy Tekulapally is a Software program Growth Engineer with the Amazon SageMaker HyperPod workforce. He’s keen about designing and constructing dependable, high-performance distributed programs that energy large-scale AI workloads. Outdoors of labor, he enjoys touring and exploring new espresso spots.
Chandra Lohit Reddy Tekulapally is a Software program Growth Engineer with the Amazon SageMaker HyperPod workforce. He’s keen about designing and constructing dependable, high-performance distributed programs that energy large-scale AI workloads. Outdoors of labor, he enjoys touring and exploring new espresso spots.
 Kunal Jha is a Principal Product Supervisor at AWS. He’s targeted on constructing Amazon SageMaker Hyperpod because the best-in-class alternative for Generative AI mannequin’s coaching and inference. In his spare time, Kunal enjoys snowboarding and exploring the Pacific Northwest.
Kunal Jha is a Principal Product Supervisor at AWS. He’s targeted on constructing Amazon SageMaker Hyperpod because the best-in-class alternative for Generative AI mannequin’s coaching and inference. In his spare time, Kunal enjoys snowboarding and exploring the Pacific Northwest.
 Vivek Gangasani is a Worldwide Lead GenAI Specialist Options Architect for SageMaker Inference. He drives Go-to-Market (GTM) and Outbound Product technique for SageMaker Inference. He additionally helps enterprises and startups deploy, handle, and scale their GenAI fashions with SageMaker and GPUs. At present, he’s targeted on creating methods and content material for optimizing inference efficiency and GPU effectivity for internet hosting Massive Language Fashions. In his free time, Vivek enjoys mountain climbing, watching films, and attempting completely different cuisines.
Vivek Gangasani is a Worldwide Lead GenAI Specialist Options Architect for SageMaker Inference. He drives Go-to-Market (GTM) and Outbound Product technique for SageMaker Inference. He additionally helps enterprises and startups deploy, handle, and scale their GenAI fashions with SageMaker and GPUs. At present, he’s targeted on creating methods and content material for optimizing inference efficiency and GPU effectivity for internet hosting Massive Language Fashions. In his free time, Vivek enjoys mountain climbing, watching films, and attempting completely different cuisines.



{kind=link}