
Amazon Bedrock is a completely managed service that provides a alternative of high-performing basis fashions (FMs) from main AI corporations by a single API, together with capabilities to construct generative AI functions with safety, privateness, and accountable AI.
Batch inference in Amazon Bedrock is for bigger workloads the place fast responses aren’t vital. With a batch processing method, organizations can analyze substantial datasets effectively, with vital price benefits: you’ll be able to profit from a 50% discount in pricing in comparison with the on-demand choice. This makes batch inference significantly helpful for dealing with in depth information to get inference from Amazon Bedrock FMs.
As organizations scale their use of Amazon Bedrock FMs for large-volume information processing, implementing efficient monitoring and administration practices for batch inference jobs turns into an vital focus space for optimization. This resolution demonstrates find out how to implement automated monitoring for Amazon Bedrock batch inference jobs utilizing AWS serverless companies akin to AWS Lambda, Amazon DynamoDB, and Amazon EventBridge, lowering operational overhead whereas sustaining dependable processing of large-scale batch inference workloads. By a sensible instance within the monetary companies sector, we present find out how to construct a production-ready system that mechanically tracks job standing, supplies real-time notifications, and maintains audit data of processing actions.
Resolution overview
Think about a situation the place a monetary companies firm manages thousands and thousands of buyer interactions and information factors, together with credit score histories, spending patterns, and monetary preferences. This firm acknowledged the potential of utilizing superior AI capabilities to ship personalised product suggestions at scale. Nevertheless, processing such huge datasets in actual time isn’t all the time obligatory or cost-effective.
The answer introduced on this submit makes use of batch inference in Amazon Bedrock with automated monitoring to course of massive volumes of buyer information effectively utilizing the next structure.
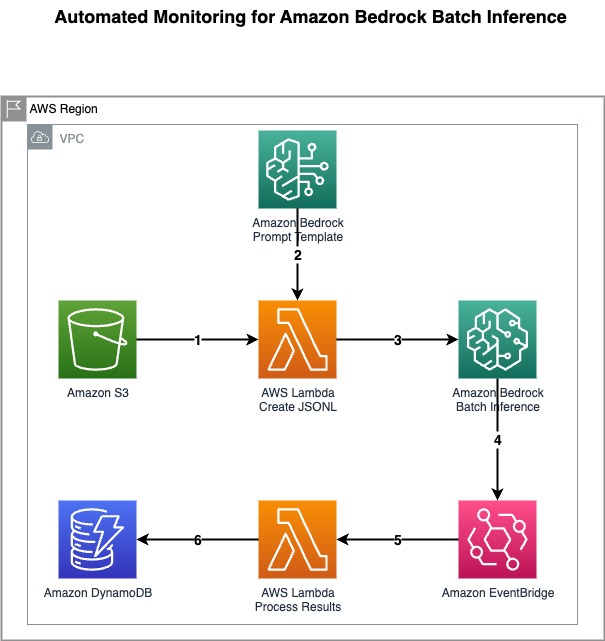
This structure workflow contains the next steps:
- The monetary companies firm uploads buyer credit score information and product information to be processed to an Amazon Easy Storage Service (Amazon S3) bucket.
- The primary Lambda perform reads the immediate template and information from the S3 bucket, and creates a JSONL file with prompts for the purchasers together with their credit score information and obtainable monetary merchandise.
- The identical Lambda perform triggers a brand new Amazon Bedrock batch inference job utilizing this JSONL file.
- Within the immediate template, the FM is given a job of professional in advice programs throughout the monetary companies business. This fashion, the mannequin understands the shopper and their credit score data to intelligently suggest most fitted merchandise.
- An EventBridge rule screens the state modifications of the batch inference job. When the job completes or fails, the rule triggers a second Lambda perform.
- The second Lambda perform creates an entry for the job with its standing in a DynamoDB desk.
- After a batch job is full, its output recordsdata (containing personalised product suggestions) can be obtainable within the S3 bucket’s
inference_resultsfolder.
This automated monitoring resolution for Amazon Bedrock batch inference gives a number of key advantages:
- Actual-time visibility – Integration of DynamoDB and EventBridge supplies real-time visibility into the standing of batch inference jobs, enabling proactive monitoring and well timed decision-making
- Streamlined operations – Automated job monitoring and administration minimizes handbook overhead, lowering operational complexities so groups can deal with higher-value duties like analyzing advice outcomes
- Optimized useful resource allocation – Metrics and insights about token depend and latency saved in DynamoDB assist organizations optimize useful resource allocation, facilitating environment friendly utilization of batch inference capabilities and cost-effectiveness
Conditions
To implement this resolution, you could have the next:
- An energetic AWS account with applicable permissions to create assets, together with S3 buckets, Lambda features, and Amazon Bedrock assets.
- Entry to your chosen fashions hosted on Amazon Bedrock. Make certain the chosen mannequin has been enabled in Amazon Bedrock.
Moreover, be sure that to deploy the answer in an AWS Area that helps batch inference.
Deploy resolution
For this resolution, we offer an AWS CloudFormation template that units up the companies included within the structure, to allow repeatable deployments. This template creates the next assets:
To deploy the CloudFormation template, full the next steps:
- Sign up to the AWS Administration Console.
- Open the template straight on the Create stack web page of the CloudFormation console.
- Select Subsequent and supply the next particulars:
- For Stack identify, enter a novel identify.
- For ModelId, enter the mannequin ID that you just want your batch job to run with. Solely Anthropic Claude household fashions can be utilized with the CloudFormation template supplied on this submit.
- Add non-compulsory tags, permissions, and different superior settings if wanted.
- Evaluate the stack particulars, choose I acknowledge that AWS CloudFormation would possibly create AWS IAM assets, and select Subsequent.
- Select Submit to provoke the deployment in your AWS account.
The stack would possibly take a number of minutes to finish.
- Select the Assets tab to search out the newly created S3 bucket after the deployment succeeds.
- Open the S3 bucket and ensure that there are two CSV recordsdata in your information folder.
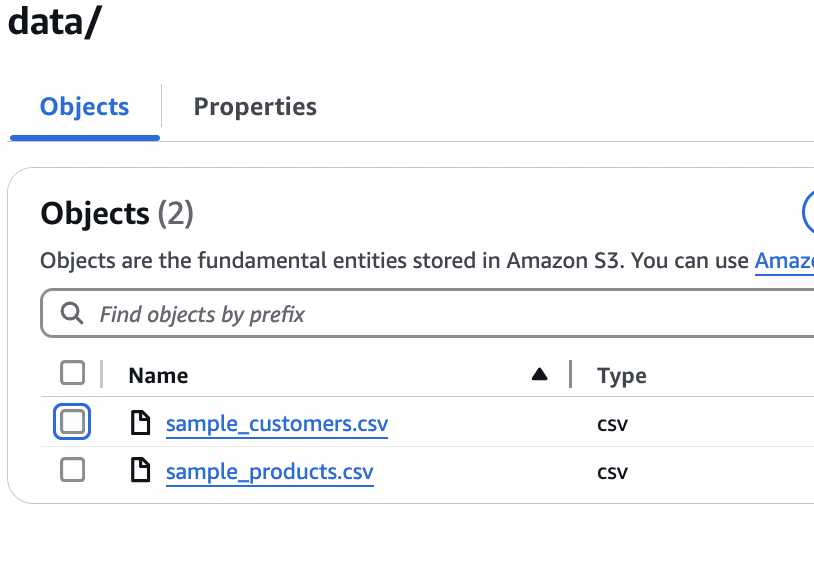
- On the Amazon S3 console, go to the information folder and create two extra folders manually. This may put together your S3 bucket to retailer the prompts and batch inference job outcomes.
- On the Lambda console, select Features within the navigation pane.
- Select the perform that has
create-jsonl-filein its identify.
- On the Check tab, select Check to run the Lambda perform.
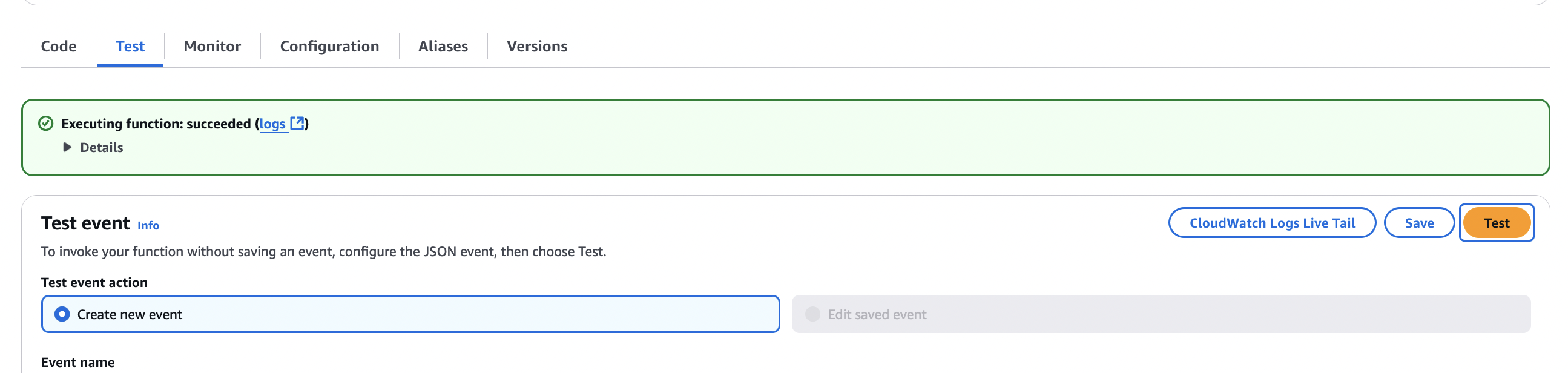
The perform reads the CSV recordsdata from the S3 bucket and the immediate template, and creates a JSONL file with prompts for the purchasers beneath the prompts folder of your S3 bucket. The JSONL file has 100 prompts utilizing the purchasers and merchandise information. Lastly, the perform submits a batch inference job with the CreateModelInvocationJob API name utilizing the JSONL file. - On the Amazon Bedrock console, select Immediate Administration beneath Builder instruments within the navigation pane.
- Select the
finance-product-recommender-v1immediate to see the immediate template enter for the FM. - Select Batch inference within the navigation pane beneath Inference and Evaluation to search out the submitted job.
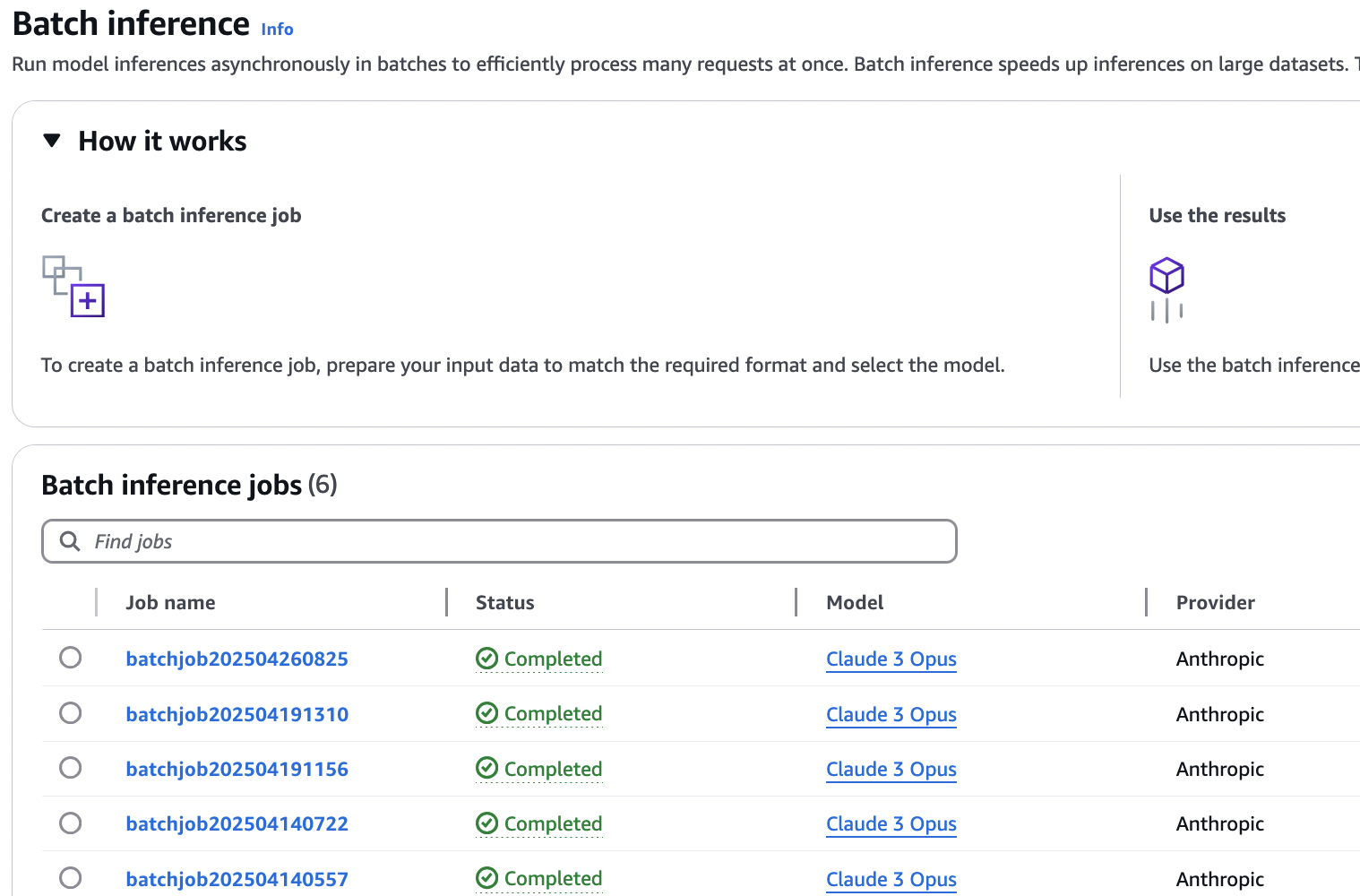
The job progresses by totally different statuses: Submitted, Validating, In Progress, and lastly Accomplished, or Failed. You possibly can go away this web page and test the standing after just a few hours.
The EventBridge rule will mechanically set off the second Lambda perform with event-bridge-trigger in its identify on completion of the job. This perform will add an entry within the DynamoDB desk named bedrock_batch_job_status with particulars of the execution, as proven within the following screenshot.
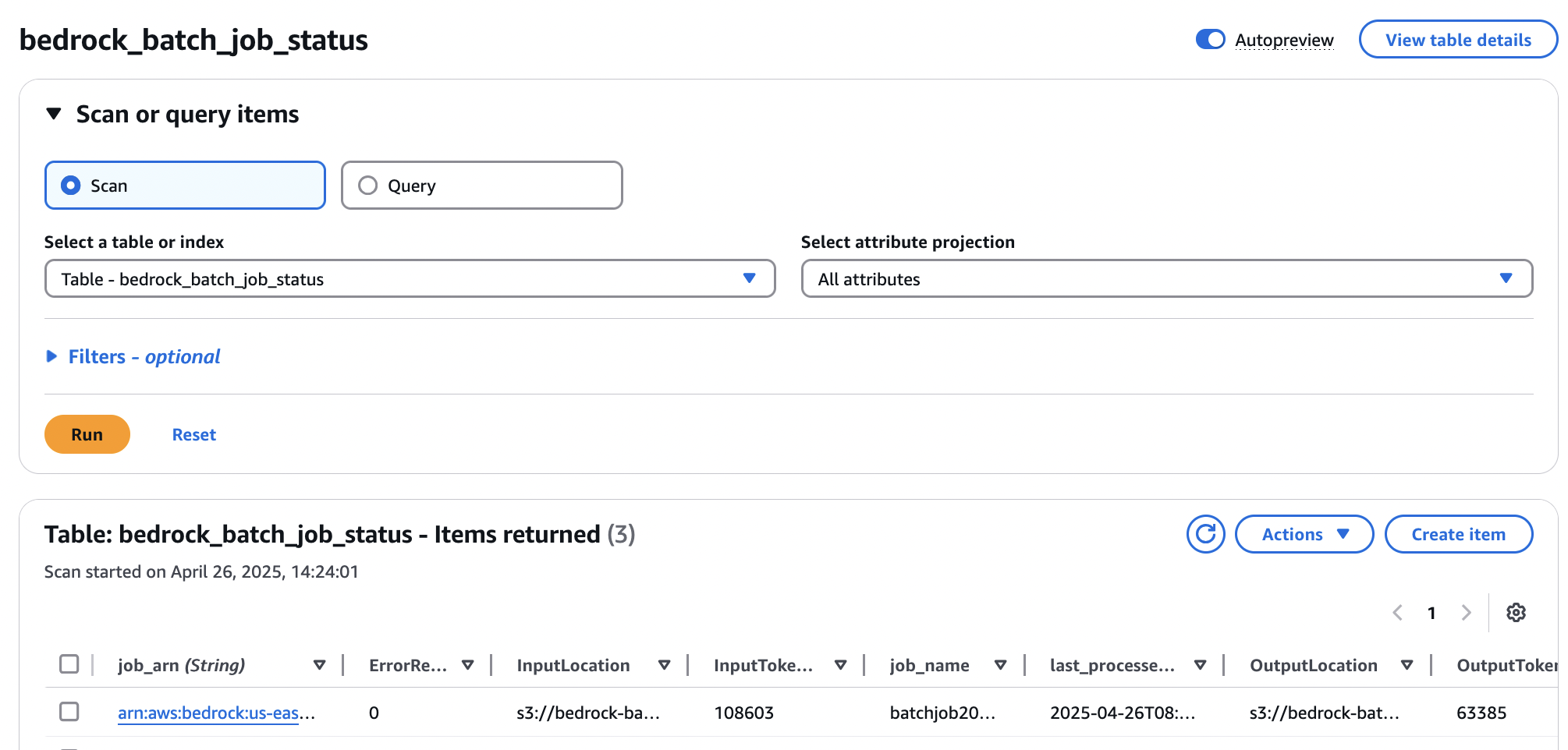
This DynamoDB desk features as a state supervisor for Amazon Bedrock batch inference jobs, monitoring the lifecycle of every request. The columns of the desk are logically divided into the next classes:
- Job identification and core attributes (
job_arn,job_name) – These columns present the distinctive identifier and a human-readable identify for every batch inference request, serving as the first keys or core attributes for monitoring. - Execution and lifecycle administration (
StartTime,EndTime,last_processed_timestamp,TotalDuration) – This class captures the temporal elements and the general development of the job, permitting for monitoring of its present state, begin/finish instances, and complete processing length.last_processed_timestampis essential for understanding the newest exercise or checkpoint. - Processing statistics and efficiency (
TotalRecordCount,ProcessedRecordCount,SuccessRecordCount,ErrorRecordCount) – These metrics present granular insights into the processing effectivity and final result of the batch job, highlighting information quantity, profitable processing charges, and error occurrences. - Price and useful resource utilization metrics (
InputTokenCount,OutputTokenCount) – Particularly designed for price evaluation, these columns observe the consumption of tokens, which is a direct think about Amazon Bedrock pricing, enabling correct useful resource utilization evaluation. - Information and site administration (
InputLocation,OutputLocation) – These columns hyperlink the inference job to its supply and vacation spot information inside Amazon S3, sustaining traceability of the information concerned within the batch processing.
View product suggestions
Full the next steps to open the output file and examine the suggestions for every buyer generated by the FM:
- On the Amazon Bedrock console, open the finished batch inference job.
- Discover the job Amazon Useful resource Title (ARN) and duplicate the textual content after
model-invocation-job/, as illustrated within the following screenshot.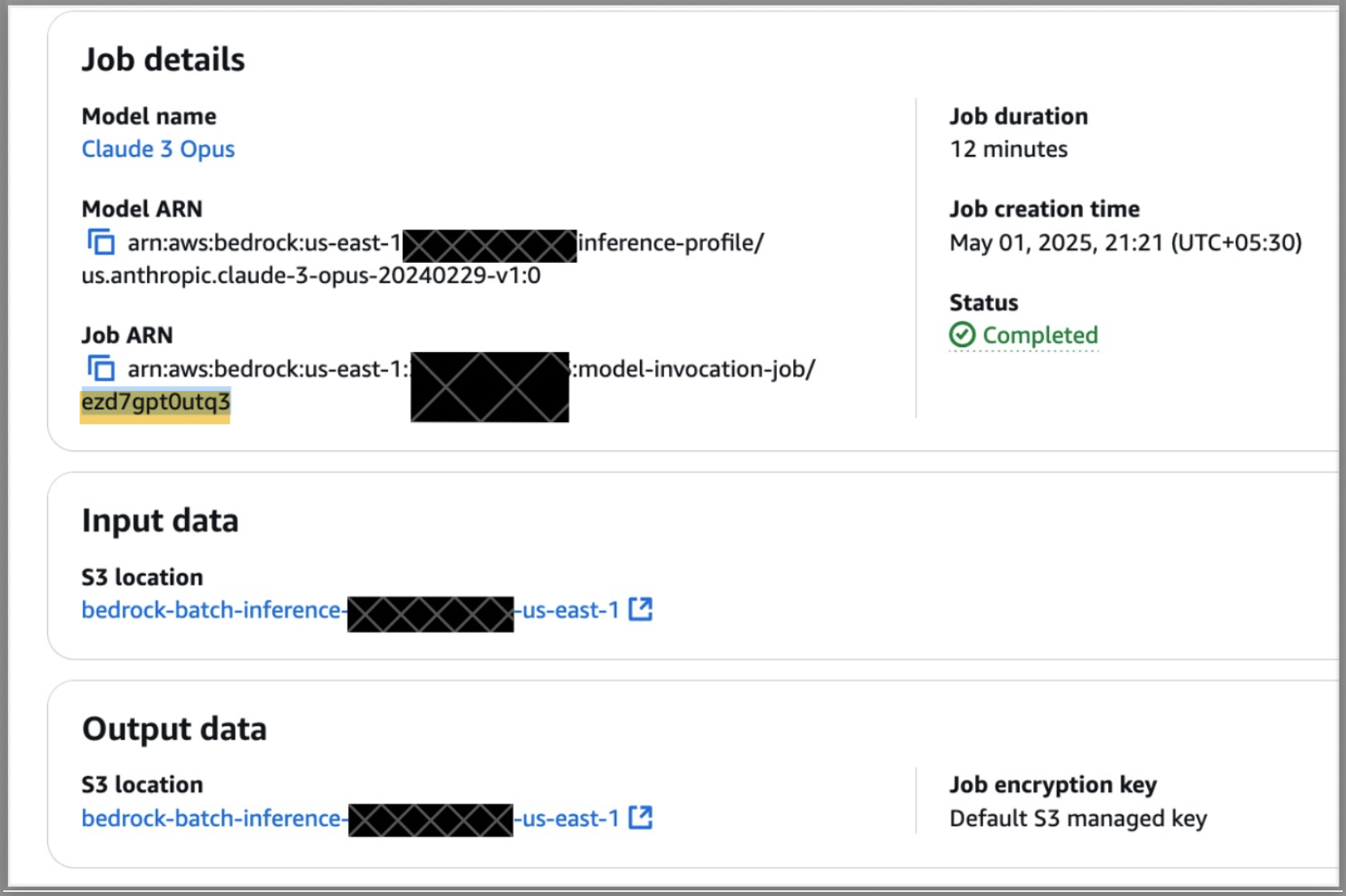
- Select the hyperlink for S3 location beneath Output information.
A brand new tab opens with the inference_results folder of the S3 bucket.
- Seek for the job outcomes folder utilizing the textual content copied from the earlier step.
- Open the folder to search out two output recordsdata:
- The file named
manifestaccommodates data like variety of tokens, variety of profitable data, and variety of errors. - The second output file accommodates the suggestions.
- The file named
- Obtain the second output file and open it in a textual content editor like Visible Studio Code to search out the suggestions in opposition to every buyer.
The instance within the following screenshot reveals a number of beneficial merchandise and why the FM selected this product for the precise buyer.

Greatest practices
To optimize or improve your monitoring resolution, contemplate the next finest practices:
- Arrange Amazon CloudWatch alarms for failed jobs to facilitate immediate consideration to points. For extra particulars, see Amazon CloudWatch alarms.
- Use applicable DynamoDB capability modes based mostly in your workload patterns.
- Configure related metrics and logging of batch job efficiency for operational visibility. Consult with Publish customized metrics for extra particulars. The next are some helpful metrics:
- Common job length
- Token throughput fee (
inputTokenCount+outputTokenCount) /jobDuration) - Error charges and kinds
Estimated prices
The fee estimate of working this resolution one time is lower than $1. The estimate for batch inference jobs considers Anthropic’s Claude 3.5 sonnet V2 mannequin. Consult with Mannequin pricing particulars for batch job pricing of different fashions on Amazon Bedrock.
Clear up
In the event you now not want this automated monitoring resolution, comply with these steps to delete the assets it created to keep away from further prices:
- On the Amazon S3 console, select Buckets within the navigation pane.
- Choose the bucket you created and select Empty to delete its contents.
- On the AWS CloudFormation console, select Stacks within the navigation pane.
- Choose the created stack and select Delete.
This mechanically deletes the deployed stack and the assets created.
Conclusion
On this submit, we demonstrated how a monetary companies firm can use an FM to course of massive volumes of buyer data and get particular data-driven product suggestions. We additionally confirmed find out how to implement an automatic monitoring resolution for Amazon Bedrock batch inference jobs. Through the use of EventBridge, Lambda, and DynamoDB, you’ll be able to achieve real-time visibility into batch processing operations, so you’ll be able to effectively generate personalised product suggestions based mostly on buyer credit score information. The answer addresses key challenges in managing batch inference operations:
- Alleviates the necessity for handbook standing checking or steady polling
- Offers fast notifications when jobs full or fail
- Maintains a centralized file of job statuses
This automated monitoring method considerably enhances the power to course of massive quantities of monetary information utilizing batch inference for Amazon Bedrock. This resolution gives a scalable, environment friendly, and cost-effective method to do batch inference for quite a lot of use circumstances, akin to producing product suggestions, figuring out fraud patterns, or analyzing monetary traits in bulk, with the additional benefit of real-time operational visibility.
In regards to the authors
 Durga Prasad is a Senior Guide at AWS, specializing within the Information and AI/ML. He has over 17 years of business expertise and is keen about serving to clients design, prototype, and scale Large Information and Generative AI functions utilizing AWS native and open-source tech stacks.
Durga Prasad is a Senior Guide at AWS, specializing within the Information and AI/ML. He has over 17 years of business expertise and is keen about serving to clients design, prototype, and scale Large Information and Generative AI functions utilizing AWS native and open-source tech stacks.
 Chanpreet Singh is a Senior Guide at AWS with 18+ years of business expertise, specializing in Information Analytics and AI/ML options. He companions with enterprise clients to architect and implement cutting-edge options in Large Information, Machine Studying, and Generative AI utilizing AWS native companies, associate options and open-source applied sciences. A passionate technologist and drawback solver, he balances his skilled life with nature exploration, studying, and high quality household time.
Chanpreet Singh is a Senior Guide at AWS with 18+ years of business expertise, specializing in Information Analytics and AI/ML options. He companions with enterprise clients to architect and implement cutting-edge options in Large Information, Machine Studying, and Generative AI utilizing AWS native companies, associate options and open-source applied sciences. A passionate technologist and drawback solver, he balances his skilled life with nature exploration, studying, and high quality household time.



{kind=link}